机器学习之线性回归简单案例
一、写在前面
本项目适用于机器学习初学者用来了解机器学习模型工作的大致流程和基本原理十分合适。
整体代码附在最后。
二、以小见大
想要完成一个深度学习模型训练的大致流程是一致的,分为数据准备,训练,验证和测试 ,而项目最终的目的是对模型的参数进行调整,最终得到一个最接近真实的参数 ,也就是最接近真实的模型。
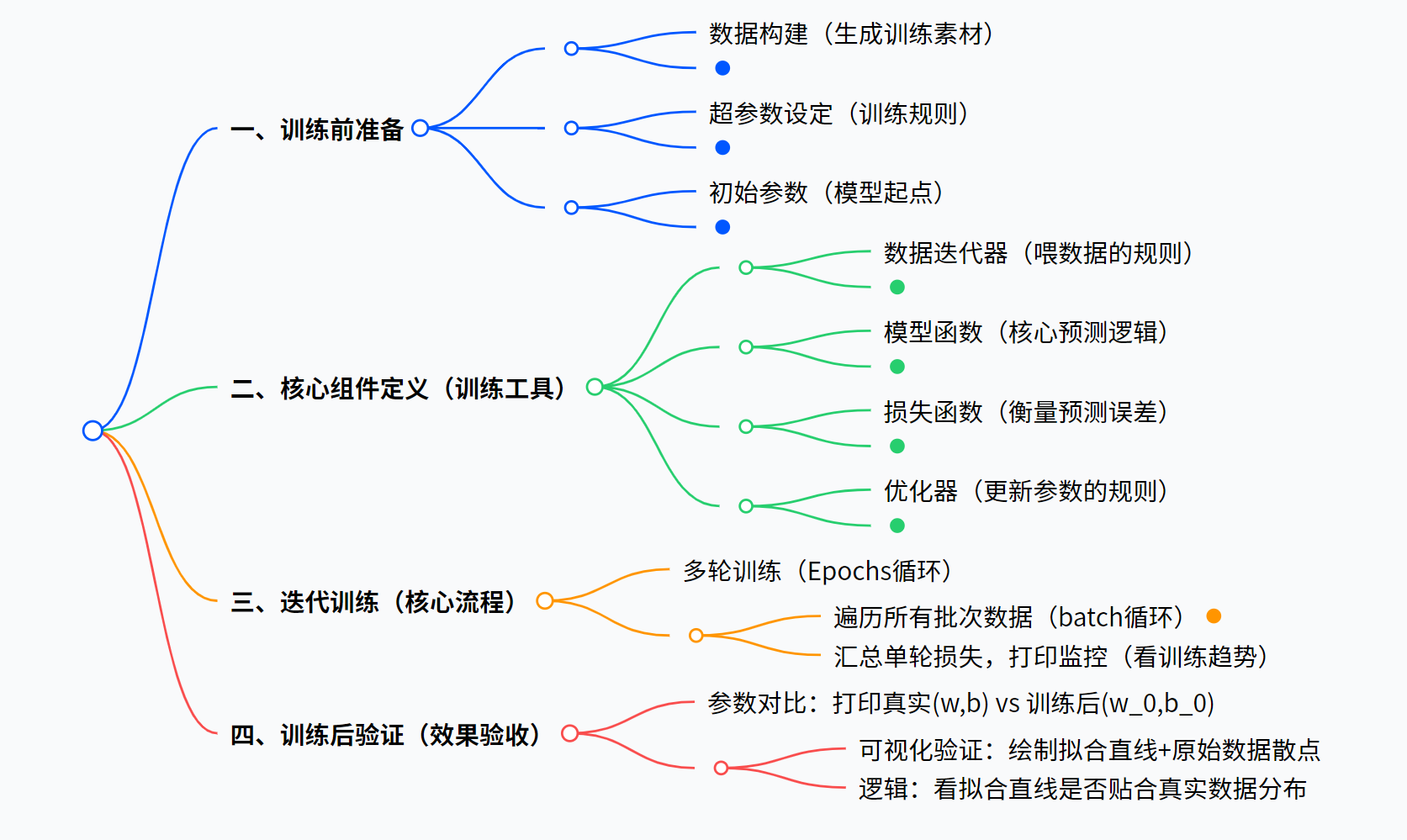
其中数据的处理是所有模型训练的难点和痛点,而今天我们只是为了了解机器学习的所以我们聚焦于训练工具的使用和实现,训练过程的探究和训练结果的验证。
1.数据构建
python
def create_data(w, b, data_num): #生成数据
x = torch.normal(0, 1, (data_num, len(w)))
y = torch.matmul(x, w) + b #matmul表示矩阵相乘
noise = torch.normal(0, 0.01, y.shape) #噪声要加到y上
y += noise
return x, y接下来对这段代码进行逐句解释
python
def create_data(w, b, data_num):声明一个创造数据的函数,其中参数w是真实的权重参数,也就是模型最终要学习的目标,参数b是真实的偏置参数,data_num则是给出数据的样本量。
python
x = torch.normal(0, 1, (data_num, len(w)))生成数据x,使用torch库中的正态分布函数生成数据,数据的内容是以0为均值,1为标准差,data_num和len(w)构成数据张量的形状。其中,因为回归模型进行的是矩阵运算,所以生成张量的列数要是len(w)列。
python
y = torch.matmul(x, w) + b #matmul表示矩阵相乘表示y=xw+b的矩阵运算。
python
noise = torch.normal(0, 0.01, y.shape) #噪声要加到y上真实获取的数据不可能是完全准确的,所以我们人为的给数据添加一些噪声。
2.数据获取
python
def data_provider(data, label, batchsize): #每次访问这个函数, 就能提供一批数据
length = len(label)
indices = list(range(length))
#我不能按顺序取 把数据打乱
random.shuffle(indices)
for each in range(0, length, batchsize):
get_indices = indices[each: each+batchsize]
get_data = data[get_indices]
get_label = label[get_indices]
yield get_data,get_label #有存档点的return接下来进行逐句解释
声明一个获取,提供数据的函数,参数data表示特征矩阵,也就是生成函数生成的x,参数label表示标签向量,也就是生成的y,是最终的结果,batchsize表示每次要取出来的数据的数量。
length表示label的总长度,也就是样本的总长度。
indices表示所有样本的下标范围,并且将其转化进list,方便后续随机取数据。
shuffle通过实现取数据下标的打乱来实现取数据的打乱,取数据不能按顺序取是因为有些数据可能存在关联数据扎堆出现的情况,比如一个调查病情的数据,可能相邻几百条数据都来自一个医院,但是我们要随机的取不同医院的数据,所以要打乱。
for循环从0开始到length结束,步长为batchsize。
将本次要取的数据的下标先读入get_indices 数组,通过get_data得到特征data,通过get_label得到label。
然后将得到的数据进行返回,并且使用yield保存该返回点,因为要保证取的数据组数不超。
3.预测模型构建
python
def fun(x, w, b):
pred_y = torch.matmul(x, w) + b
return pred_y函数需要数据参数x,以及初始的权重参数w和偏置参数b,预测模型通过torch库实现张量相乘,然后实现预测值的输出。
4.loss函数构建
loss函数通常是用来评价模型拟合效果的函数
python
def maeLoss(pre_y, y):
return torch.sum(abs(pre_y-y))/len(y)maeLoss通过实现真实和预测值之间的差值绝对值平均值来表示模型拟合的好坏。
5.随机梯度下降函数的构建
python
def sgd(paras, lr): #随机梯度下降,更新参数
with torch.no_grad(): #属于这句代码的部分,不计算梯度
for para in paras:
para -= para.grad * lr #不能写成 para = para - para.grad*lr
para.grad.zero_() #使用过的梯度,归0通过loss函数进行模型评测之后,我们使用梯度回传和随机梯度下降来对参数进行修改改善。
梯度回传的过程是一个loss反过来对各个参数求偏导的过程,所以各个参数仍然要进行计算,但是此时的计算不能算作梯度,所以有了第二行代码。
随后根据g=g-lr*g0来对参数进行更新,一次更新结束之后,对参数的梯度要清零否则会影响下一次梯度下降的调参。
6.训练过程
python
for epoch in range(epochs):#训练epochs次
data_loss = 0
for batch_x, batch_y in data_provider(X, Y, batchsize):
pred_y = fun(batch_x,w_0, b_0)
loss = maeLoss(pred_y, batch_y)
loss.backward()
sgd([w_0, b_0], lr)
data_loss += lossbatch_x, batch_y 用来承接每次训练数据取出,pred_y 用来承接训练数据的预测值,loss 承接预测模型的偏差程度,然后进行随机梯度下降,最后使用data_loss 记录每轮训练的loss变化。
三、完整代码
python
import torch
import matplotlib.pyplot as plt # 画图的
import random #随机
def create_data(w, b, data_num): #生成数据
x = torch.normal(0, 1, (data_num, len(w)))
y = torch.matmul(x, w) + b #matmul表示矩阵相乘
noise = torch.normal(0, 0.01, y.shape) #噪声要加到y上
y += noise
return x, y
num = 500
true_w = torch.tensor([8.1,2,2,4])
true_b = torch.tensor(1.1)
X, Y = create_data(true_w, true_b, num)
plt.scatter(X[:, 3], Y, 1)
plt.show()
def data_provider(data, label, batchsize): #每次访问这个函数, 就能提供一批数据
length = len(label)
indices = list(range(length))
#我不能按顺序取 把数据打乱
random.shuffle(indices)
for each in range(0, length, batchsize):
get_indices = indices[each: each+batchsize]
get_data = data[get_indices]
get_label = label[get_indices]
yield get_data,get_label #有存档点的return
batchsize = 16
# for batch_x, batch_y in data_provider(X, Y, batchsize):
# print(batch_x, batch_y)
# break
def fun(x, w, b):
pred_y = torch.matmul(x, w) + b
return pred_y
def maeLoss(pre_y, y):
return torch.sum(abs(pre_y-y))/len(y)
def sgd(paras, lr): #随机梯度下降,更新参数
with torch.no_grad(): #属于这句代码的部分,不计算梯度
for para in paras:
para -= para.grad * lr #不能写成 para = para - para.grad*lr
para.grad.zero_() #使用过的梯度,归0
lr = 0.03
w_0 = torch.normal(0, 0.01, true_w.shape, requires_grad=True) #这个w需要计算梯度
b_0 = torch.tensor(0.01, requires_grad=True)
print(w_0, b_0)
epochs = 50
for epoch in range(epochs):
data_loss = 0
for batch_x, batch_y in data_provider(X, Y, batchsize):
pred_y = fun(batch_x,w_0, b_0)
loss = maeLoss(pred_y, batch_y)
loss.backward()
sgd([w_0, b_0], lr)
data_loss += loss
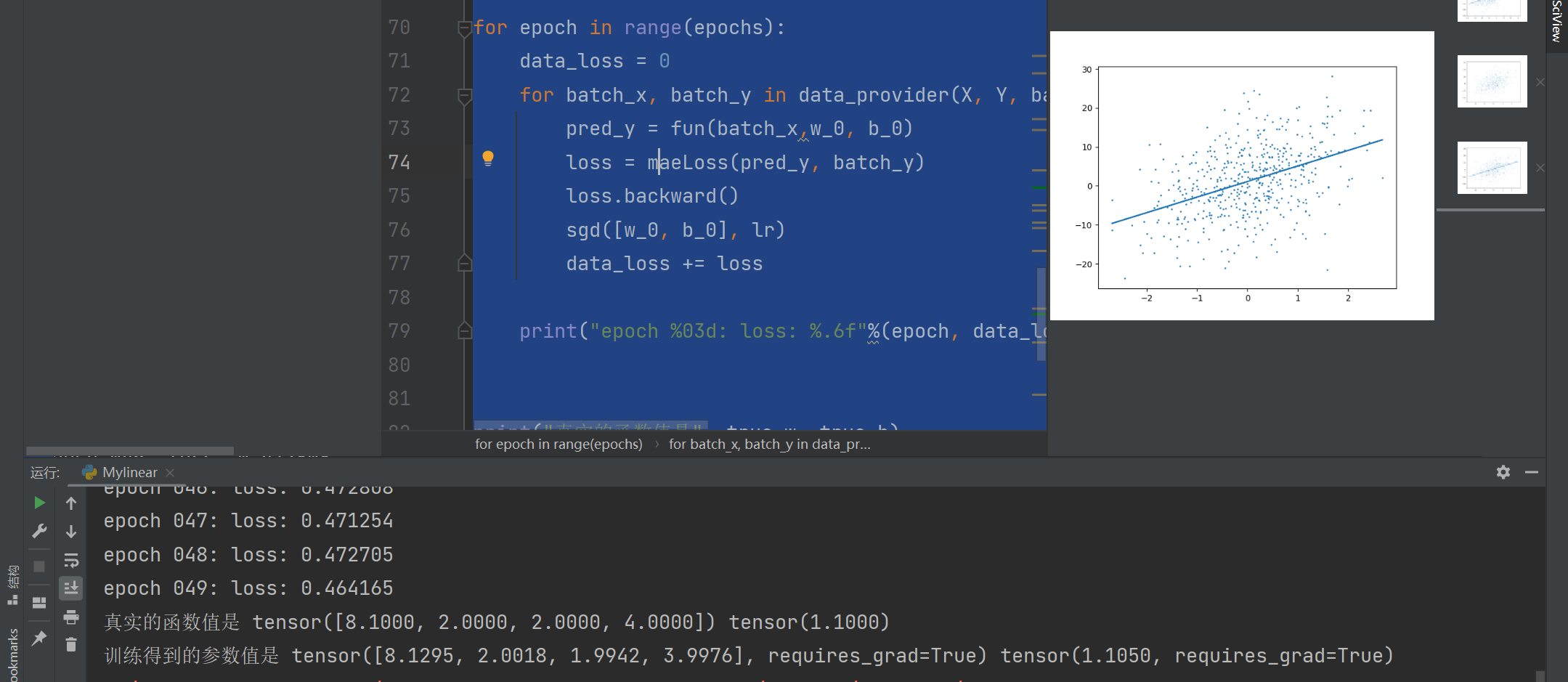
print("epoch %03d: loss: %.6f"%(epoch, data_loss))
print("真实的函数值是", true_w, true_b)
print("训练得到的参数值是", w_0, b_0)
idx = 3
plt.plot(X[:, idx].detach().numpy(), X[:, idx].detach().numpy()*w_0[idx].detach().numpy()+b_0.detach().numpy())
plt.scatter(X[:, idx], Y, 1)
plt.show()最终的输出
四、汲取通法
从这个项目中我们可以学习到一个关于机器学习模型训练的通法
- 数据一般都是包含噪声的,我们要学会处理数据,从中提取出关键可用的信息。
- 模型训练的目的就是对初始模型的参数进行不断的优化,从而得到最接近真实值的参数,而最开始我们就是要假设参数。
- loss函数是我们判定模型拟合的重要手段,指南针。sgd梯度下降是实现参数改善的重要手段,要自动梯度下降,并且及时停止。
- 针对取数据我们要随机的,成块的,可以使用batchsize和shuffle在过慢和受噪声干扰过大之间寻找到一个平衡。
- 使用epochs进行多次训练,并且记录和比较每轮训练的loss。
写作不易,感谢支持。