目录
[1、neo4j 安装 - mac brew版](#1、neo4j 安装 - mac brew版)
[2、neo4j 快速入门](#2、neo4j 快速入门)
[3、neo4j 基本操作](#3、neo4j 基本操作)
博主的数据集是用的自己的数据集,大家练习时可以在网上找一个数据量小的数据集练手。
一、Neo4j图数据库
Neo4j 是一个高性能的、原生的图数据库 。它不采用传统的行和列的表格结构,而是使用节点 和关系的图结构来存储和管理数据。

1、neo4j 安装 - mac brew版
(1)安装neo4j
安装了Homebrew直接在终端输入以下命令即可
bash# 1. 添加 Neo4j 的 Homebrew tap brew install neo4j # 2. 启动 Neo4j brew services start neo4j # 3. 停止 Neo4j brew services stop neo4j安装后,Neo4j 浏览器可通过 http://localhost:7474 访问。
(2)登录neo4j
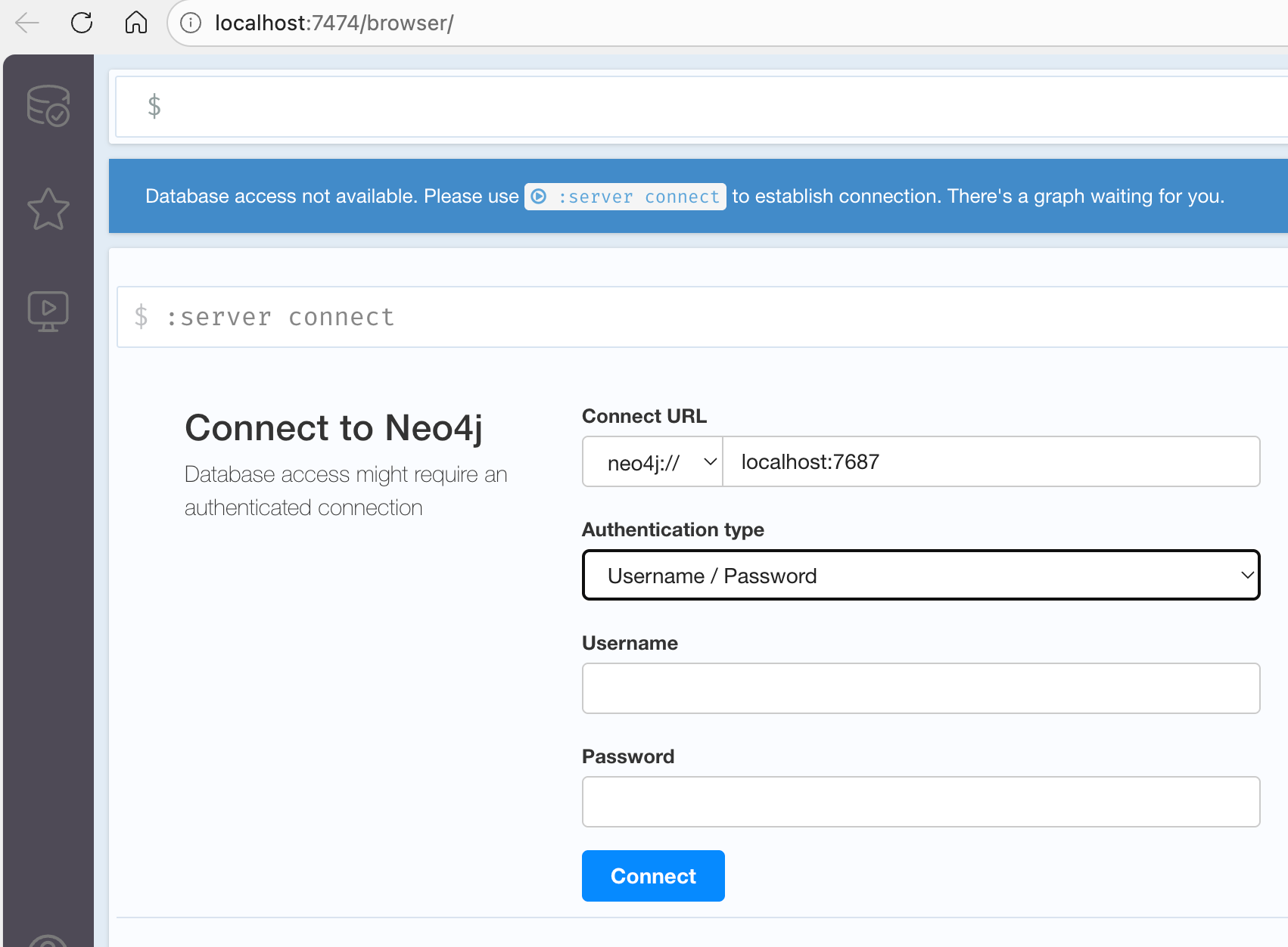
【1】在登录页面填写信息:
Connect URL :输入
neo4j://localhost:7687Authentication type:保持为 "Username / Password"
Username :输入
neo4jPassword :首次连接时输入默认密码
neo4j点击蓝色的 Connect 按钮
【2】首次连接成功后,系统会强制要求修改默认密码:
当前密码:
neo4j设置一个新的安全密码(请务必记住)
【3】测试连接
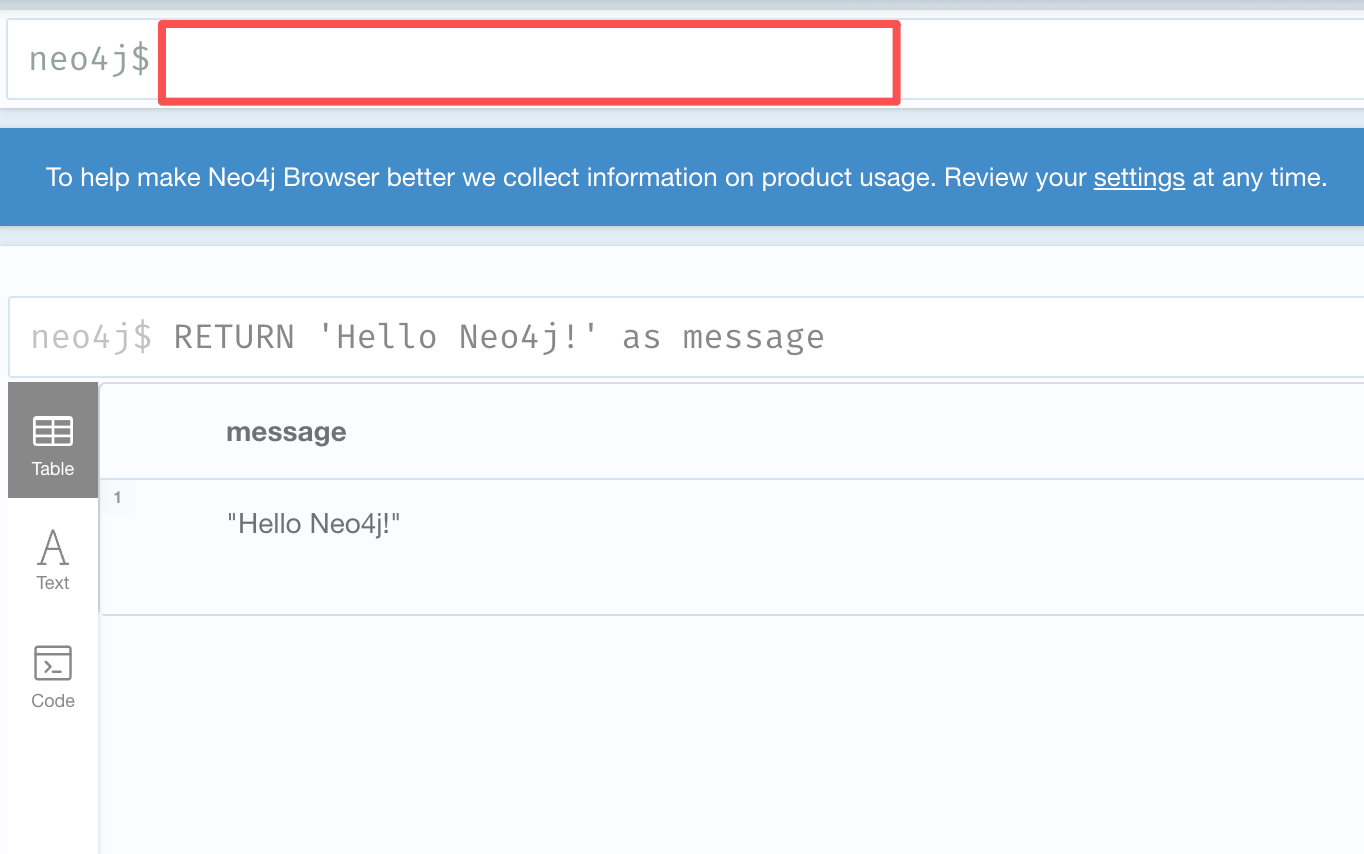
连接成功后,在顶部的命令行中输入 Cypher 查询语句,例如:
cpp// 测试连接 RETURN 'Hello Neo4j!' as message // 创建一个简单的图 CREATE (n:Person {name: 'Alice', age: 30}) RETURN n // 查询所有节点 MATCH (n) RETURN n
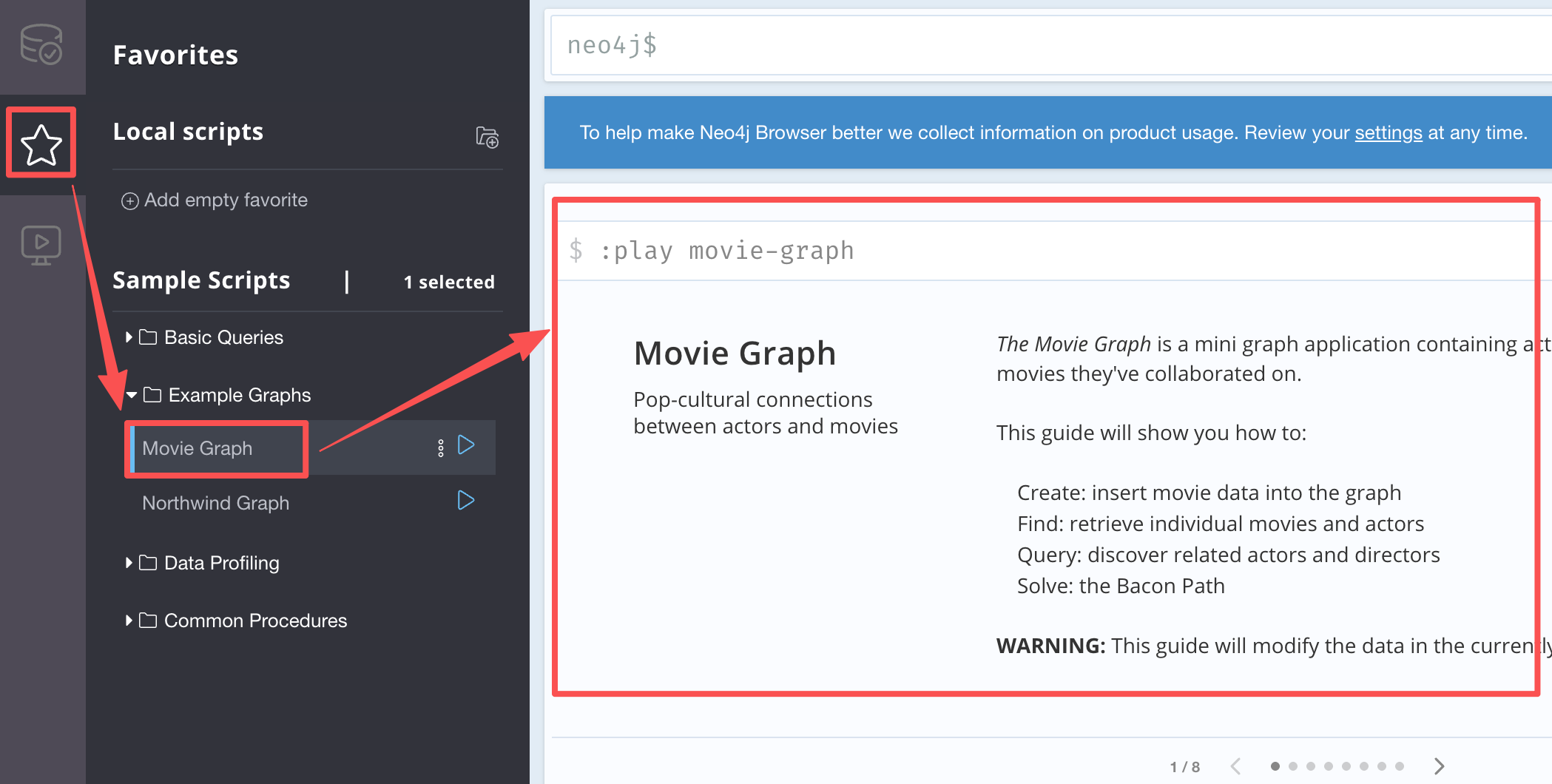
2、neo4j 快速入门
【1】我们点击左边栏的星星图标,在Example Graphs中选择Movie Graph,点击运行,就会弹出一个关于电影图谱的教程
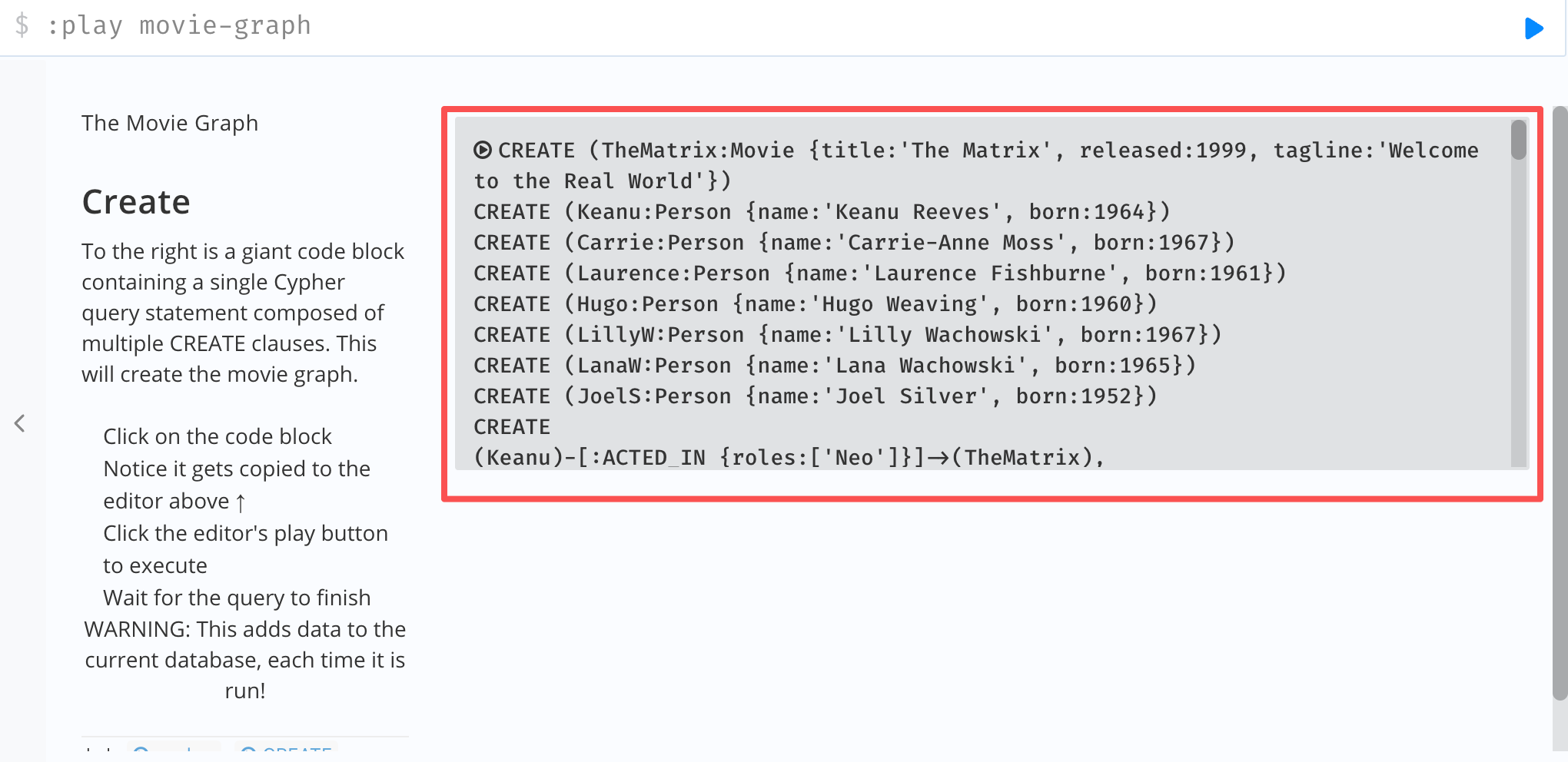
【2】创建图谱
点击灰色代码框,创建图谱的代码会自动复制到代码框
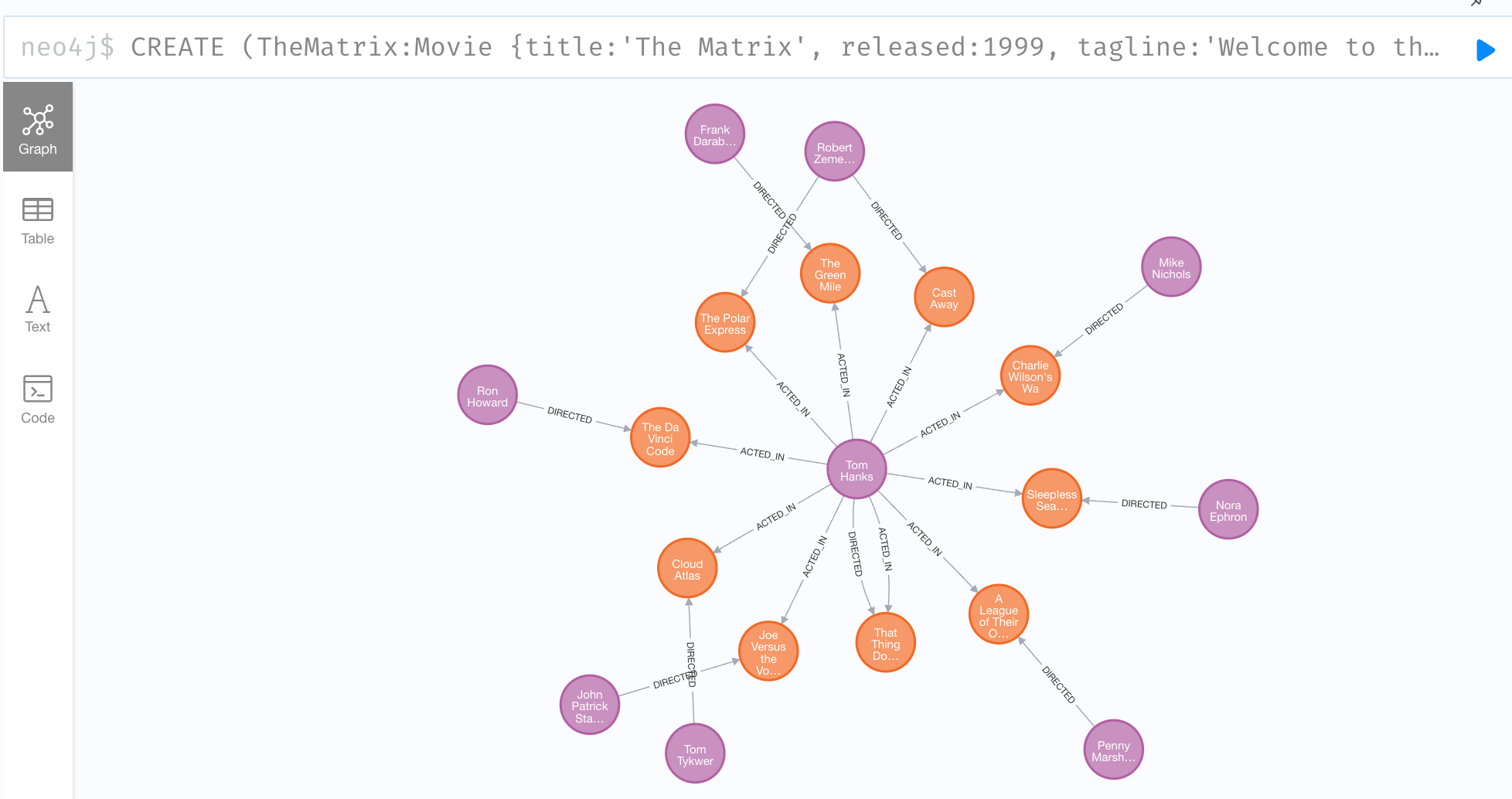
点击运行,即可看到创建的电影图谱
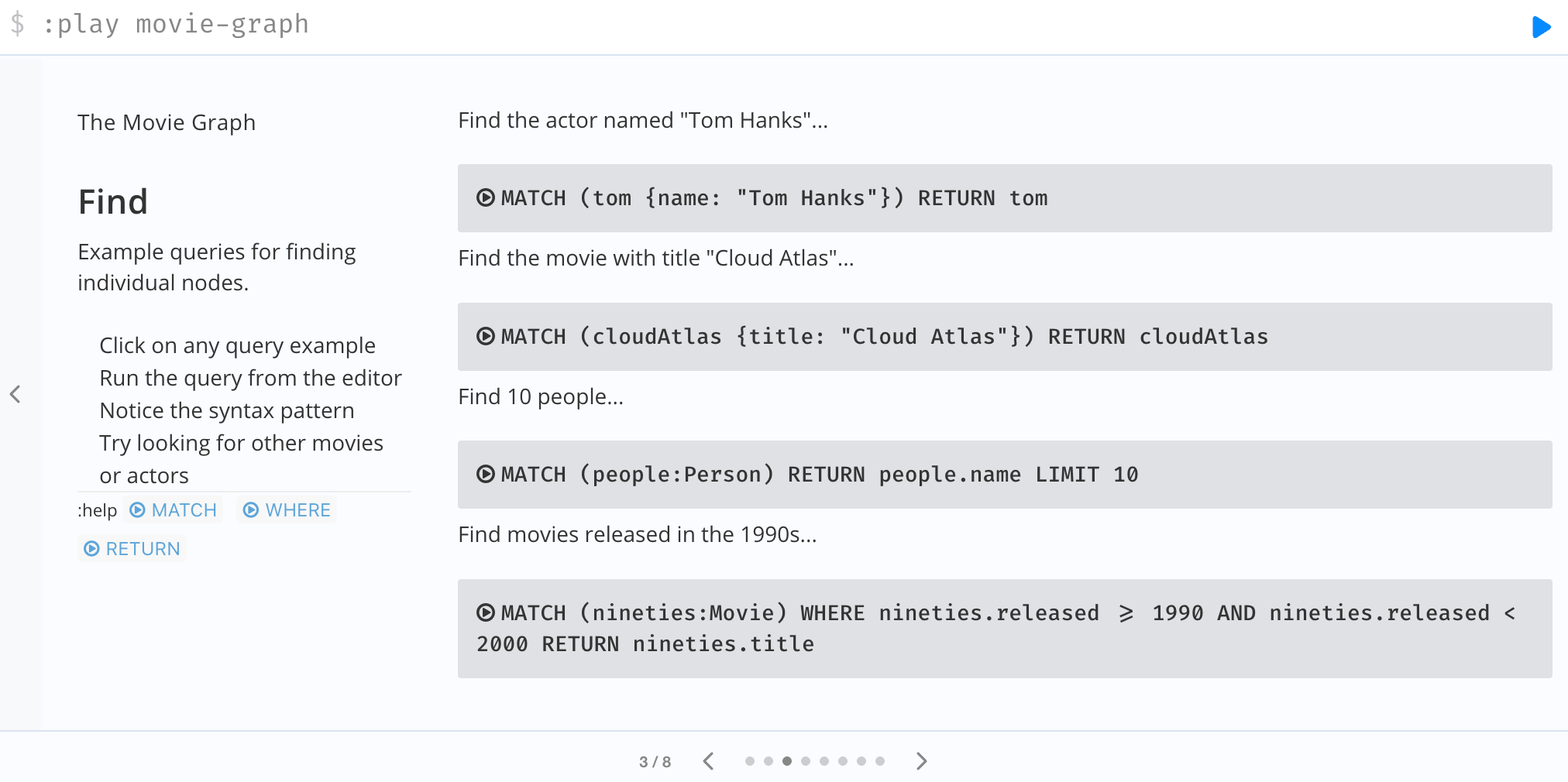
【3】查找
下面是一些关于查找的语句:
- 查找名叫Tom Hanks的演员
- 查找标题为Cloud Atlas的电影
- 查找10个人
- 查找在20世纪90年代上映的电影
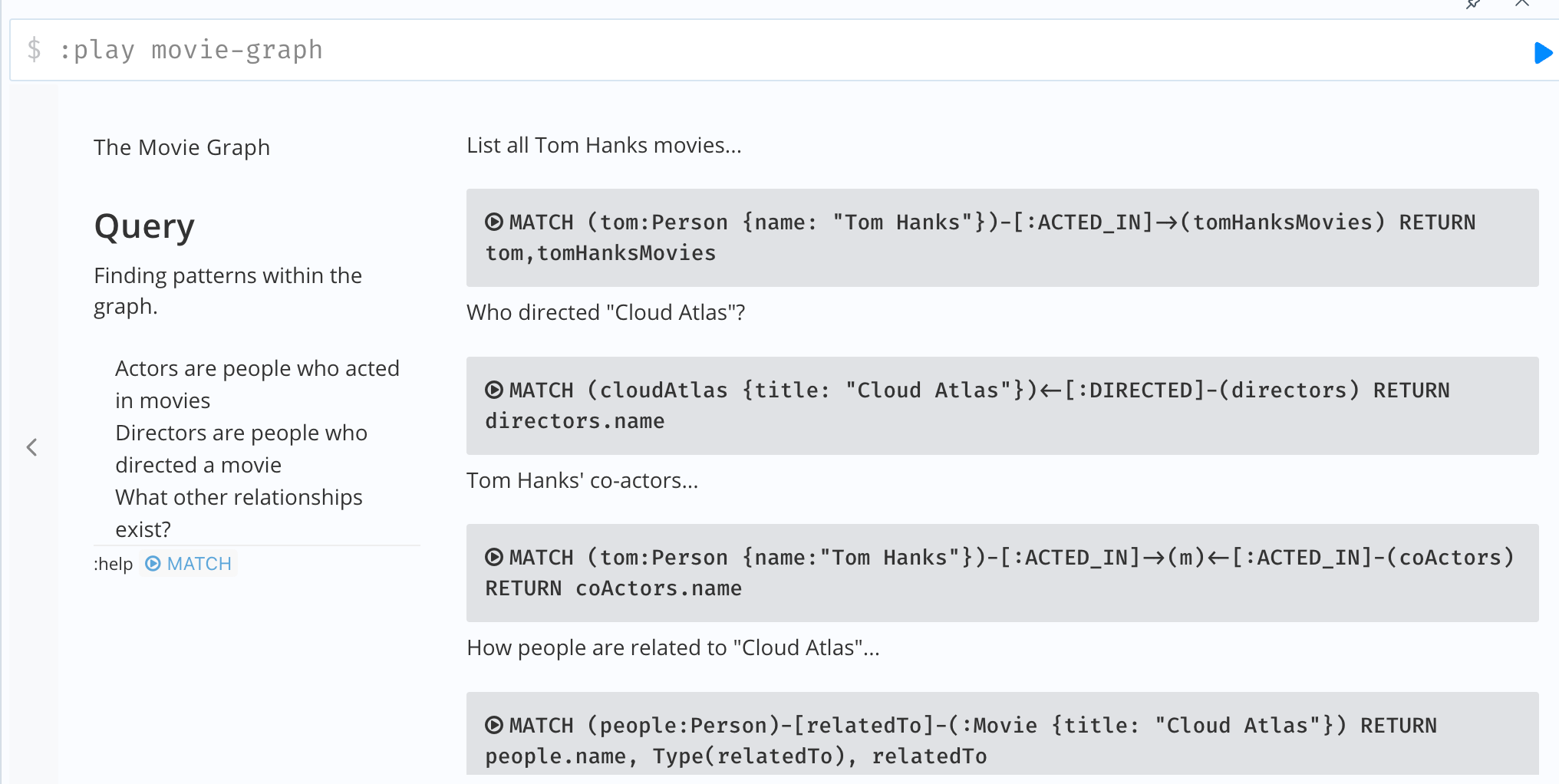
【4】询问
后续还有一些查询语句教程不一一列举了,感兴趣的同学可以自行运行。

3、neo4j 基本操作
接下来我们以【麦当劳】为背景,用Neo4j的Cypher查询语言演示基本增删改查操作。
下面我们建立一个简单的图谱,包含两种节点和一种关系:
-
节点类型1:
餐厅- 属性:
名称,地址,开业年份
- 属性:
-
节点类型2:
产品- 属性:
名称,价格,类别
- 属性:
-
关系类型:
供应- 属性:
自何时起供应
- 属性:
(1)增操作
【1】创建节点
bash-- 创建麦当劳餐厅节点 CREATE (:canteen {name: 'MC', address: 'Beijing', open: 2005}) CREATE (:canteen {name: 'MCpro', address: 'Tianjin', open: 2012}) -- 创建多个产品节点 CREATE (:product {name: 'burger', price: 25.0, type: 'dinner'}), (:product {name: 'chicken', price: 12.0, type: 'snacks'}), (:product {name: 'cola', price: 8.0, type: 'drink'})【2】创建关系
java// 1.分别创建 // MC --供应--> burger MATCH (store:canteen {name: 'MC'}) MATCH (product:product {name: 'burger'}) MERGE (store)-[r:support {when: 2005}]->(product) RETURN store, r, product // MCpro --供应--> cola MATCH (mcpro:canteen {name: 'MCpro'}) MATCH (cola:product {name: 'cola'}) CREATE (mcpro)-[:supply{when:2019}]->(cola)
java// 2.一次性创建 MATCH (mc:canteen {name: 'MC'}) MATCH (mcpro:canteen {name: 'MCpro'}) MATCH (burger:product {name: 'burger'}) MATCH (cola:product {name: 'cola'}) CREATE (mc)-[:supply{when:2005}]->(burger), (mcpro)-[:supply{when:2019}]->(cola)
(2)查操作
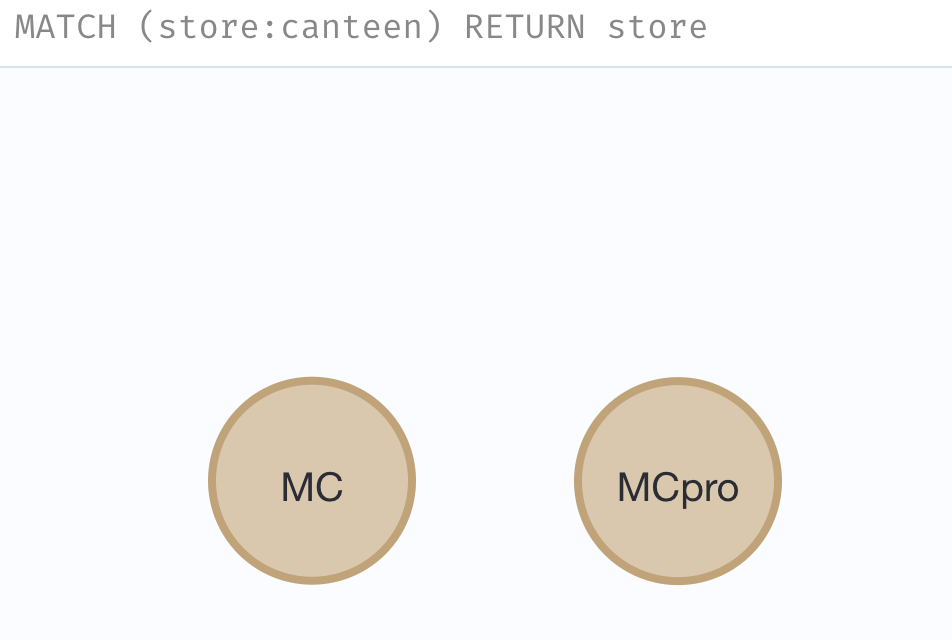
【1】查找所有餐厅
bashMATCH (store:canteen) RETURN store【2】查找特定餐厅供应的所有产品
bashMATCH (store:canteen {name: 'MC'})-[:supply]->(product:product) RETURN store.name, product.name, product.price【3】查找供应可乐的所有餐厅
bashMATCH (store:canteen)-[:supply]->(product:product {name: 'cola'}) RETURN store.name, product.name, store.address因为前面没有创建这么多关系,下面只做操作语法展示
【4】多跳查询 - 查找与MC销售同类产品的其他餐厅
因为前面没有创建这么多关系,这里只做操作语法展示
java// 1. 找到MC的所有产品 // 2. 找到也供应这些产品的其他餐厅(排除自己) MATCH (store1:canteen {name: 'MC'})-[:supply]->(product:product)<-[:supply]-(otherStore:canteen) WHERE store1 <> otherStore // 不等于,表示过滤掉store1和otherStore相同的记录 RETURN DISTINCT otherStore.name AS 兄弟餐厅, product.name AS 共同产品【5】路径查询 - 查找两家餐厅通过共同产品产生的关联
javaMATCH p=(:canteen {name: 'MC'})-[:supply*..2]-(:canteen {name: 'MCpro'}) /* 表示变长关系: *表示变长路径 ..2表示 1 到 2 跳 *..2表示:1跳 或 2跳 */ RETURN p(3)改操作
【1】更新节点属性
java// 将burger的价格更新为28元 MATCH (p:product {name: 'burger'}) SET p.price = 28.0 RETURN p【2】新增节点属性
java// 为所有餐厅增加一个"是否24小时"属性 MATCH (s:canteen) SET s.if24hours = 'yes' RETURN s【3】更新关系属性
java// 修改MC供应burger的开始时间 MATCH (:canteen {name: 'MC'})-[r:supply]->(:product {name: 'burger'}) SET r.when = 2006



(4)删操作
【1】删除关系
java-- MCpro不再供应cola MATCH (:canteen {name: 'MCpro'})-[r:supply]->(:product {name: 'cola'}) DELETE r【2】删除节点(必须先删除其所有关系)
java// 删除cola这个产品节点 MATCH (p:product {name: 'cola'}) DETACH DELETE p // DETACH 关键字会在删除节点前,自动删除与其连接的所有关系【3】删除所有节点
bashMATCH (n) DETACH DELETE n
通过以上麦当劳的例子,我们可以看到Neo4j的操作非常直观:
CREATE/MERGE: 对应SQL的INSERT,用于创建节点和关系。
MATCH: 对应SQL的SELECT ... FROM,是查询的起点,用于定位图形中的模式。
WHERE: 对应SQL的WHERE,用于过滤结果。
SET: 对应SQL的UPDATE,用于更新属性。
DELETE/DETACH DELETE: 对应SQL的DELETE,用于删除元素。Neo4j的核心优势在于通过
MATCH子句描述关联模式 ,例如(餐厅)-[供应]->(产品),这使得查询复杂的关系网络变得简单和高效。4、安装py2neo
py2neo 是 Python 连接和操作 Neo4j 图数据库的主要工具库,适用于需要处理复杂关系数据的应用场景。
二、数据预处理
数据预处理包括数据清洗、实体识别等步骤,目的是将原始数据转换为适合构建知识图谱的格式。
1、数据清洗
数据质量要求:
补全缺失值:对于明显缺失的信息(如设备型号),可以标记为【缺失】或根据上下文推断。
格式标准化:将日期统一为【YYYY-MM-DD】格式。
去除重复值:删除重复的条目
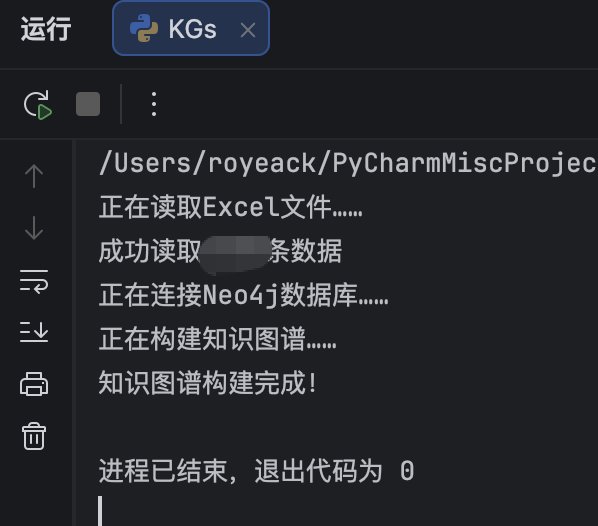
pythonimport pandas as pd import numpy as np import re # 1. 读取数据 def read_excel_data(file_path): """读取Excel文件数据""" try: df = pd.read_excel(file_path) print(f"数据读取成功,共{len(df)}行,{len(df.columns)}列") return df except Exception as e: print(f"读取文件失败: {e}") return None # 2. 数据质量检查 def check_data_quality(df): """检查数据质量""" print("\n======== 数据质量检查 ========") print(f"数据形状: {df.shape}") # 检查缺失值 missing_info = df.isnull().sum() print("\n缺失值统计:") for col, count in missing_info.items(): if count > 0: print(f" {col}: {count}个缺失值 ({count / len(df) * 100:.1f}%)") # 检查数据类型 print("\n数据类型:") print(df.dtypes) # 检查重复行 duplicates = df.duplicated().sum() print(f"\n重复行数: {duplicates}") return missing_info # 3. 数据清洗函数 def clean_data(df): """数据清洗主函数""" df_clean = df.copy() # 处理缺失值 print("\n======== 处理缺失值 ========") # 3.1 文本列用空字符串填充 text_columns = ['属性1', '属性2', ......文本列属性名称] for col in text_columns: if col in df_clean.columns: df_clean[col] = df_clean[col].fillna('未知') print(f"填充 {col} 的缺失值") # 3.2 数值列用0填充 numeric_columns = [数值列属性名称] for col in numeric_columns: if col in df_clean.columns: df_clean[col] = df_clean[col].fillna(0) print(f"填充 {col} 的缺失值") # 3.3 统一日期格式,空缺日期用1900-01-01替代 for col in df_clean.columns: if '时间' in col: # 只处理包含"时间"的列 df_clean[col] = pd.to_datetime(df_clean[col], errors='coerce').dt.date # 转换为年月日 df_clean[col] = df_clean[col].fillna(pd.Timestamp("1900-01-01").date()) # 用特定日期填充缺失值 print(f"处理日期列 {col},填充缺失值") # 处理重复行 df_clean = df_clean.drop_duplicates() print(f"删除重复行,剩余{len(df_clean)}行") return df_clean # 4. 数据导出 def export_processed_data(df, output_path): """导出处理后的数据""" try: # 保存为Excel df.to_excel(output_path, index=False) print(f"\n处理后的数据已保存到: {output_path}") # 同时保存为CSV备份 csv_path = output_path.replace('.xlsx', '.csv') df.to_csv(csv_path, index=False, encoding='utf-8-sig') print(f"备份CSV文件已保存到: {csv_path}") except Exception as e: print(f"导出文件失败: {e}") # 主函数 def main(): # 文件路径 input_file = "project-issue-list.xlsx" output_file = "pytest_processed.xlsx" # 执行数据预处理流程 print("开始数据预处理流程...") # 1. 读取数据 df = read_excel_data(input_file) if df is None: return # 2. 初始数据质量检查 check_data_quality(df) # 3. 数据清洗 df_clean = clean_data(df) # 4.最终数据质量检查 check_data_quality(df_clean) # 5.导出数据表格 export_processed_data(df_clean, output_file) print("\n数据预处理完成!") if __name__ == "__main__": main()
2、知识建模
我们需要从业务角度理解数据,设计出合理的图谱结构。
(1)识别实体
实体是知识图谱中的【节点】。在我的数据集中,可以识别出以下主要实体类型:
订单记录:核心实体,每一笔订单就是一个销售事件。
产品:订单中的商品。例如,"生日蛋糕"、"马卡龙"、"手冲咖啡"。数据中【产品名称】和【产品类别】是其属性。
配方标准:制作产品的依据和标准。数据中【配方名称】、【配料序号】、【制作要点】等是其属性。
客户反馈:客户对订单或产品的评价与建议。
促销活动:与订单关联的营销方案。
门店:订单发生的背景。
(2)识别实体属性
属性是描述实体的键值对。
订单记录 的属性:下单时间、订单描述、订单金额、是否加急、订单状态、支付方式、配送地址。
产品 的属性:产品名称、产品类别、规格、单价、保质期、产品编号。
配方标准 的属性:配方名称、配料序号、制作步骤、所需时间、适用产品。
客户反馈 的属性:反馈内容、评分。
促销活动 的属性:活动名称、折扣力度、适用条件。
门店 的属性:门店地址、营业时间、联系电话。
(3)识别关系
关系是连接实体的边,是图谱价值的体现。
门店 -- 提供 --> 产品
订单记录 -- 产生于 --> 门店
订单记录 -- 包含 --> 产品
订单记录 -- 触发 --> 促销活动
订单记录 -- 收到 --> 客户反馈
产品 -- 依据 --> 配方标准
配方标准 -- 适用于 --> 产品
三、搭建知识图谱
下面代码为简化后的模板代码,需要根据自己的数据集进行修改后再运行。
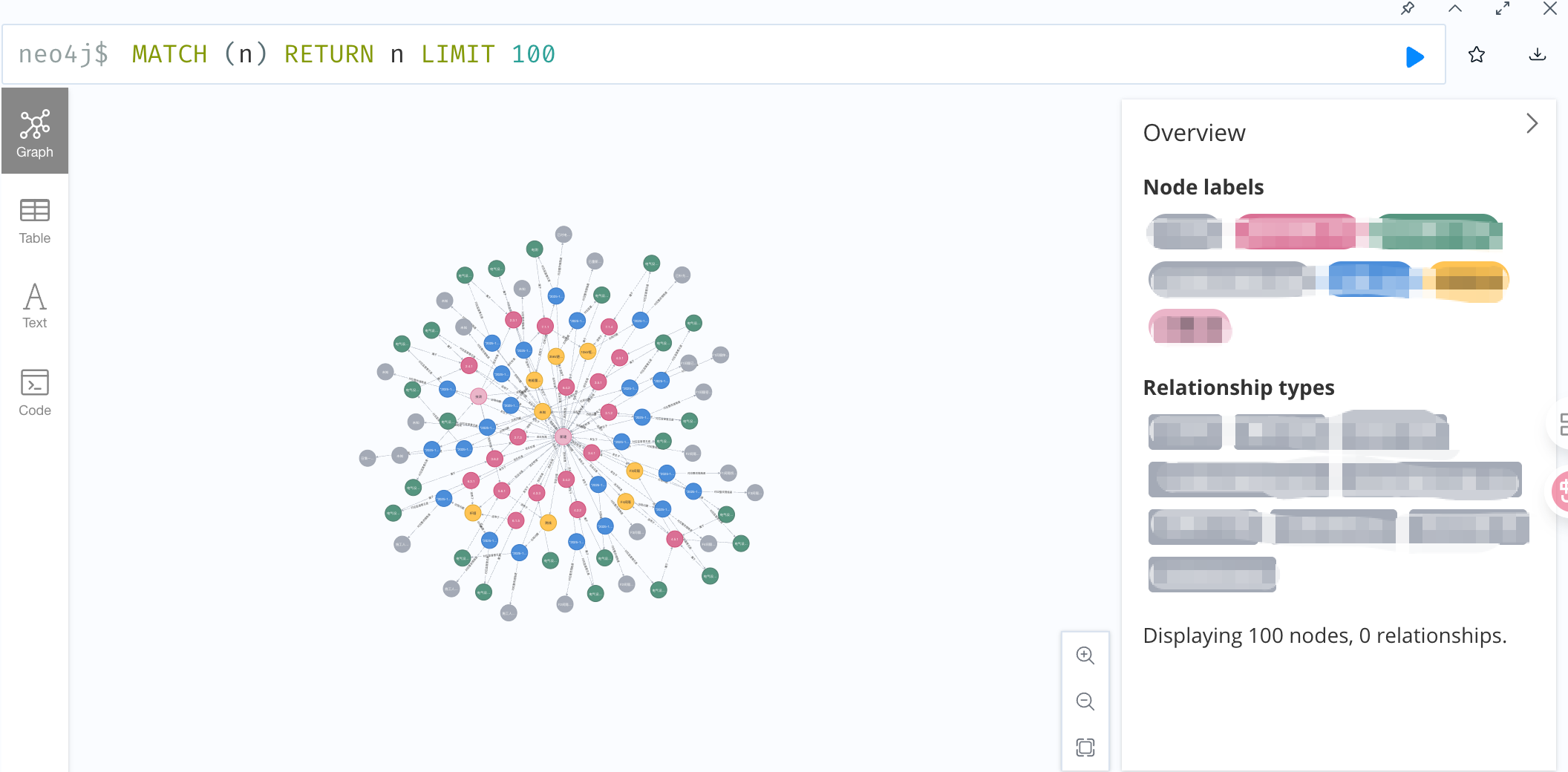
pythonimport pandas as pd from py2neo import Graph, Node, Relationship def read_excel(excel_path): """ 读取excel文件数据 """ df = pd.read_excel(excel_path, header=0) return df def connect_to_neo4j(): """连接Neo4j数据库""" graph = Graph("neo4j://localhost:7687", auth=("neo4j", "password")) return graph def clean_existing_data(graph): """清空现有知识图谱(可选)""" graph.run("MATCH (n) DETACH DELETE n") def build_knowledge_graph(graph, df): """构建知识图谱""" # 创建节点和关系的字典,避免重复创建 created_nodes = {} # 1.创建节点 for index, row in df.iterrows(): # df.iterrows - 每一行(索引,数据),index 索引,row 数据 # 创建节点1 p1_key = f"节点1_{index}" if p1_key not in created_nodes: p1_node = Node("节点1", 属性1=row['属性1']) # row[属性1]属性要和excel的列名一致 created_nodes[p1_key] = p1_node graph.create(p1_node) # 创建节点2 p2_key = f"节点2_{index}" if p2_key not in created_nodes: p2_node = Node("节点2", 属性1=row['属性1'], 属性2=row['属性2']) created_nodes[p2_key] = p2_node graph.create(p2_node) # 创建节点3 p3_key = f"节点3_{index}" if p3_key not in created_nodes: p3_node = Node("节点3", 属性1=row['属性1'], 属性2=row['属性2']) created_nodes[p3_key] = p3_node graph.create(p3_node) # 2.创建关系 # 2.1 节点1 包含 节点2 r1_rel = Relationship(created_nodes[p1_key],"包含",created_nodes[p2_key]) graph.create(r1_rel) # 2.2 节点2 出现 节点3 r2_rel = Relationship(created_nodes[p2_key],"出现",created_nodes[p3_key]) graph.create(r2_rel) def main(): file_path = "pytest.xlsx" try: print("正在读取Excel文件......") df = read_excel(file_path) print(f"成功读取{len(df)}条数据") print("正在连接Neo4j数据库......") graph = connect_to_neo4j() # 清空neo4j数据库现有数据 clean_existing_data(graph) # 构建知识图谱 print("正在构建知识图谱......") build_knowledge_graph(graph,df) print("知识图谱构建完成!") except Exception as e: print(f"发生错误:{e}") if __name__ == '__main__': main()运行后效果如下图: