本文深入解析MySQL高可用架构的核心解决方案------MHA(Master High Availability)的完整技术体系。全面介绍MHA的高可用原理、组件架构、部署配置、故障切换机制、数据补偿策略以及运维管理实践。详细阐述MHA如何实现0-30秒内自动完成数据库故障切换,并最大限度地保证数据一致性。涵盖从基础环境搭建、VIP透明切换、故障报警到高级维护操作的全流程,为构建生产级MySQL高可用架构提供完整解决方案。
1.高可用概述
数据库中的高可用功能,主要是用于避免数据库服务或数据信息的损坏问题,其中数据损坏的类型有:
- 数据物理损坏:磁盘、主机、程序实例、数据文件误删除
- 数据逻辑损坏:drop update ...
数据库高可用解决方案选型依据:(全年无故障率)
| 无故障率 | 故障时间 | 解决方案 |
|---|---|---|
| 99.9% | 0.1%(525.6min) | keepalived+双主架构,但需要人为干预 |
| 99.99% | 0.01%(52.56min) | MHA ORCH TMHA,具有自动监控,自动切换,自动数据补偿,但还是属于半自动化 比较适合非金融类互联网公司 eg: facebook taobao前端-TMHA-->polaradb |
| 99.999% | 0.001%(5.256min) | PXC MGR MGC,数据是高一致性 比较适合金融类互联网公司 |
| 99.9999% | 0.0001%(0.5256min) | 自动化、云计算化、平台化,仍然属于概念阶段 |
2.MHA概述
HA(Master High Availability)目前在MySQL高可用方面是一个相对成熟的解决方案,它由日本DeNA公司youshimaton研发,此人目前就职于Facebook公司,MHA是一套优秀的作为MySQL高可用性环境下故障切换和主从提升的高可用软件;
MySQL进行故障切换过程中,MHA能做到在0~30秒之内自动完成数据库的故障切换操作,并且在进行故障切换过程中;
MHA能在最大程度上保证数据的一致性,以达到真正意义上的高可用。
MHA Manager(管理节点)
MHA Manager 会定时探测集群中的master节点,当master出现故障时,它可以自动将最新数据的slave提升为新的master;
然后将所有其他的slave重新指向新的master,整个故障转移过程对应用程序是完全透明的;
MHA Node(数据节点)
运行在每台MySQL服务器上
| 节点信息 | 软件组件 | 作用介绍 |
|---|---|---|
| MHA Manager(管理节点) | masterha_manger | 用于启动MHA |
| masterha_check_ssh | 用于检查MHA的SSH配置互信状况 | |
| masterha_check_repl | 用于检查MySQL复制状态,以及配置信息 | |
| masterha_master_monitor | 用于检测master是否宕机 | |
| masterha_check_status | 用于检测当前MHA运行状态 | |
| masterha_master_switch | 用于控制故障转移(自动或者手动) | |
| masterha_conf_host | 添加或删除配置的server信息 | |
| MHA Node(数据节点) | save_binary_logs | 保存和复制master的二进制日志 |
| apply_diff_relay_logs | 识别差异的中继日志事件并将其差异的事件应用于其他slave | |
| purge_relay_logs | 清除中继日志(不会阻塞SQL线程) |
3.MHA高可用环境搭建
3.1 MHA高可用架构基础环境
db01、db02、db03
sh
#对原有数据库服务环境清理:(基于GTID环境构建)
#所有节点均进行清理操作
[root@db03 ~]# pkill mysqld
[root@db03 ~]# rm -rf /data/3306/*
[root@db03 ~]# chown -R mysql.mysql /data/*
# 主库db01配置文件编写
cat >/etc/my.cnf <<EOF
[mysqld]
basedir=/usr/local/mysql
datadir=/data/3306/data
socket=/tmp/mysql.sock
server_id=51
port=3306
secure-file-priv=/tmp
#log_bin=/data/binlog/mysql-bin
binlog_format=row
gtid-mode=on
enforce-gtid-consistency=true
log-slave-updates=1
[mysql]
prompt=db01 [\\d]>
EOF
# 从库db02配置文件编写
cat >/etc/my.cnf <<EOF
[mysqld]
basedir=/usr/local/mysql
datadir=/data/3306/data
socket=/tmp/mysql.sock
server_id=52
port=3306
secure-file-priv=/tmp
#log_bin=/data/binlog/mysql-bin
binlog_format=row
gtid-mode=on
enforce-gtid-consistency=true
log-slave-updates=1
[mysql]
prompt=db02 [\\d]>
EOF
# 从库db03配置文件编写
cat >/etc/my.cnf <<EOF
[mysqld]
basedir=/usr/local/mysql
datadir=/data/3306/data
socket=/tmp/mysql.sock
server_id=53
port=3306
secure-file-priv=/tmp
#log_bin=/data/binlog/mysql-bin
binlog_format=row
gtid-mode=on
enforce-gtid-consistency=true
log-slave-updates=1
[mysql]
prompt=db03 [\\d]>
EOF
# 所有节点初始化数据库操作
[root@db02 ~]# mysqld --initialize-insecure --user=mysql --basedir=/usr/local/mysql --datadir=/data/3306/data
[root@db03 ~]# /etc/init.d/mysqld start
# 重构主从关系-主库操作(db01)
db01 [(none)]>create user repl@'10.0.0.%' identified with mysql_native_password by '12366';
db01 [(none)]>grant replication slave on *.* to repl@'10.0.0.%';
-- 主库上创建主从复制用户信息
# 重构主从关系-从库操作(db01、db02)
db02 [(none)]>change master to
master_host='10.0.0.51',
master_user='repl',
master_password='12366',
master_auto_position=1;
-- 表示让从库自己找寻复制同步数据的起点;
-- 在第一次启动gtid功能时,会读取从库中的binlog日志信息,根据主库uuid信息,获取从库中执行过的主库gtid信息
-- 从从库中没有执行过的主库gtid信息之后进行进行数据同步操作
db02 [(none)]> start slave;3.2 MHA高可用软件安装部署
sh
1. 创建命令软连接(所有节点)
#MHA程序加载数据库命令,会默认在/usr/bin下面进行加载(会影响数据补偿和监控功能)
[root@db01 ~]# ln -s /usr/local/mysql/bin/mysqlbinlog /usr/bin/mysqlbinlog
[root@db01 ~]# ln -s /usr/local/mysql/bin/mysql /usr/bin/mysql
2. 配置各节点互信
[root@db01 ~]# rm -rf /root/.ssh
[root@db01 ~]# ssh-keygen
[root@db01 ~]# cd /root/.ssh
[root@db01 .ssh]# mv id_rsa.pub authorized_keys
[root@db01 .ssh]# scp -r /root/.ssh 10.0.0.52:/root
[root@db01 .ssh]# scp -r /root/.ssh 10.0.0.53:/root
3. 安装mha软件程序
#安装包下载
https://github.com/yoshinorim/mha4mysql-node/releases/download/v0.58/mha4mysql-node-0.58-0.el7.centos.noarch.rpm
#所有节点安装
[root@db01 ~]# yum install perl-DBD-MySQL -y
[root@db01 ~]# rpm -ivh mha4mysql-node-0.58-0.el7.centos.noarch.rpm
#Manager软件安装(db03)
安装包下载:https://github.com/yoshinorim/mha4mysql-manager/releases/download/v0.58/mha4mysql-manager-0.58-0.el7.centos.noarch.rpm
[root@db03 ~]# yum install -y perl-Config-Tiny epel-release perl-Log-Dispatch perl-Parallel-ForkManager perl-Time-HiRes
[root@db03 ~]# yum install -y mha4mysql-manager-0.58-0.el7.centos.noarch.rpm
4.创建mha用户(db01)
# 在db01主库中创建mha需要的用户
db01 [(none)]>create user mha@'10.0.0.%' identified with mysql_native_password by 'mha';
db01 [(none)]>grant all privileges on *.* to mha@'10.0.0.%';
-- 在主库创建完毕后,主从复制功能,核实所有从库也都有mha用户信息
db03 [(none)]>select user,host from mysql.user;
5. Manager配置文件准备(db03)
#创建配置文件目录
[root@db03 ~]# mkdir -p /etc/mha
# 创建日志目录
[root@db03 ~]# mkdir -p /var/log/mha/app1
#编辑配置文件
[root@db03 ~]# cat > /etc/mha/app1.cnf <<EOF
[server default]
manager_log=/var/log/mha/app1/manager
-- MHA的工作日志设置
manager_workdir=/var/log/mha/app1
-- MHA的工作目录
master_binlog_dir=/data/binlog
-- 主库的binlog目录
user=mha
-- 监控用户,利用此用户连接各个节点,做心跳检测(主要是检测主库的状态)
password=mha
-- 监控密码
ping_interval=2
-- 心跳检测的间隔时间
repl_password=12366
-- 复制密码
repl_user=repl
-- 复制用户(用于告知从节点通过新主同步数据信息的用户信息)
ssh_user=root
-- ssh互信的用户(可以利用互信用户从主库scp获取binlog日志信息,便于从库进行数据信息补偿)
[server1]
-- 节点信息....
hostname=10.0.0.51
port=3306
[server2]
hostname=10.0.0.52
port=3306
candidate_master=1
[server3]
hostname=10.0.0.53
port=3306
EOF
6. MHA状态检查(db03)
#在MHA管理节点,进行ssh互信功能检查,并且显示成功表示检查通过
[root@db03 ~]# masterha_check_ssh --conf=/etc/mha/app1.cnf
...
Thu Oct 12 21:31:21 2023 - [info] All SSH connection tests passed successfully.
#在MHA管理节点,检查主从关系与配置文件信息是否正确
[root@db03 ~]# masterha_check_repl --conf=/etc/mha/app1.cnf
...
MySQL Replication Health is OK.
7.开启MHA-manager、查看MHA状态
[root@db03 ~]# nohup masterha_manager --conf=/etc/mha/app1.cnf --remove_dead_master_conf --ignore_last_failover < /dev/null> /var/log/mha/app1/manager.log 2>&1 &
[1] 3003
#查看MHA状态
[root@db03 ~]# masterha_check_status --conf=/etc/mha/app1.cnf
app1 (pid:3003) is running(0:PING_OK), master:10.0.0.51
--显示以上提示信息,表示MHA基础环境搭建成功了,但还不能在生产环境使用,还需要有后续的操作配置4.数据库高可用工作原理
4.1 高可用架构作用
- 实现高可用的监控需求
- 实现高可用的选主功能(并且选择数据量越接近主库的从库成为新主)
- 实现高可用的数据补偿
- 实现高可用的应用透明(VIP)
- 实现高可用的报警功能
- 实现高可用的额外补偿
- 实现高可用的自愈功能
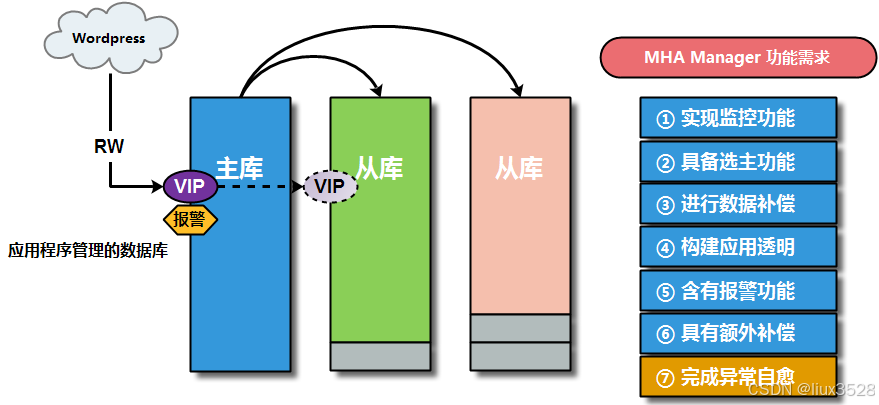
4.2 MHA的设计原理分析(Failover 过程)
01 MHA软件启动
根据启动命令,分析MHA软件启动原理:
sh
nohup masterha_manager --conf=/etc/mha/app1.cnf --remove_dead_master_conf --ignore_last_failover < /dev/null> /var/log/mha/app1/manager.log 2>&1 &
< 输入重定向 将有交互的脚本输入到/dev/null,不至于卡住-
启动时,先调取MHA启动脚本文件
masterha_manager,然后再调取加载MHA软件的配置文件--conf=.../app1.cnf -
根据加载的MHA的配置文件不同,实现管理多个高可用架构环境,进行高可用业务的架构环境的区分;
-
--remove_dead_master_conf参数表示在主节点出现宕机情况时,将会从集群中被踢出,即从配置文件中删除掉故障节点; -
--ignore_last_failover默认MHA服务是不能频繁进行故障切换的,需要有一定的间隔时间,加此参数表示忽略切换的间隔时间; -
最后将MHA启动运行的信息放入到日志文件中即可
/var/log/mha/app1/manager.log 2>&1
02 MHA实现监控
- 利用MHA启动脚本文件
masterha_manager会自动调用监控脚本文件masterha_master_monitor,可以实现连接数据库执行SQL语句,并且每隔配置文件指定时间; ping_interval=2进行脚本监控一次,从而判断主节点是否处于存活状态,连续4次还没有主库心跳,即说明主库宕机;
sh
# 监控脚本验证主节点存活方法
[root@db03 ~]# mysql -umha -pmha -h10.0.0.51 -e "select user();"
+---------------+
| user() |
+---------------+
| mha@10.0.0.53 |
+---------------+03 MHA从库选主过程
利用masterha_master_switch实现选主和切换;
利用四个数组(存活、数据量最接近、备选数组-candidate_master、不选数组)获取从节点信息
根据一定选举原则,进行主节点的选举
-
在MHA中进行选主时,根据选主源码文件信息分析,主要会利用到四个数组:alive latest pref bad,并且会识别节点编号信息;
-
在进行选主时,主要会关注竞选新主节点的日志量、以及是否设置candidate_master参数配置信息;
| 数组信息 | 简述 | 作用说明 |
|---|---|---|
| alive | 存活数组 | 主要用于探测存活的节点状态;当主库宕机后,探测的就是两个从库节点 |
| latest | 最新数组 | 表示获取日志最新的从库信息,即数据量最接近主库的从库(根据GTID信息 或 position信息) |
| pref | 备选数组 | 在数组中具有candidate_master参数判断条件,此参数可以放入配置文件节点中,便于节点优先选择为新主 |
| bad | 不选数组 | 如果设定了参数:no_master=1,表示相应节点不参与竞选主; 如果设定了参数:log_bin=0(二进制日志没开),表示相应节点不参与竞选主; 如何设定了参数:check_slave_delay,检查从库延迟主库100M数据信息日志量,表示节点不参与竞选主 |
MHA选主判断总结(利用if判断选主的情况)
-
循环对比latest数组和pref数组的slave,如果存在相同的slave,并且这个slave不在bad数组当中,该slave会被推选为新的master
DB02节点即满足latest数组信息,又满足perf数组信息,但不满足bad数据信息,即会被选为新主,有多个按照号码顺序选举;
-
如果pref和bad数组当中的个数为0,则选择latest数组当中的第一个slave为master;
DB02节点没有candidate_master参数配置,又没有不选数组里的三种情况配置,即db02恰好是latest,为新主;
-
循环对比alive数组和pref数组当中的slaves,如果有一个slave相同,并且不在bad数组当中,该节点就会成为新的master;
DB02节点即不满足latest,也不满足bad,但是满足pref,也会被选择作为新主;
-
循环latest数组,如果又循环到slave不在bad数组当中,这个slave就会成为master,就算添加了candidate_master=1参数;
该slave也不一定会成为主库;
DB02节点即满足latest数组,不是bad数组,也会成为新的主;
-
从活着的slave当中进行循环,如果循环到slave不在bad数组当中,那么这个slave就会成为主库;
DB02节点是活着的,不满足bad,也可以成为新的主;
-
如果进行了多次选择都找不到主库,那么主库选择失败,failover失败;
选主策略简述表:
| 优先级 | alive数组 | latest数组 | pref数组 | bad数组 | 选主策略 | 多个选择情况 |
|---|---|---|---|---|---|---|
| 01 | 满足 |
满足 |
满足 |
不满足 | 优选选择 | 按照节点号码顺序选择 |
| 02 | 满足 |
满足 |
不满足 | 不满足 | 优选选择 | 按照节点号码顺序选择 |
| 03 | 满足 |
不满足 | 满足 |
不满足 | 优选选择 | 按照节点号码顺序选择 |
| 04 | 满足 |
不满足 | 不满足 | 不满足 | 优选活着节点 | 按照节点号码顺序选择 |
说明:在进行手工指定切换新主时,即应用了prio_new_master_host参数信息时,会最优先选择相应节点为新主;
04 MHA数据补偿
在进行数据补偿之前,需要让新主库与原有宕机主库进行对比,获悉需要补偿的数据量情况,即对比差的数据日志量信息;
然后可以从binlog日志中,进行补充数据信息的截取,随之进行数据信息补偿,但是有种特殊情况,原有主库无法访问了;
所以进行数据补偿操作,也需要分各种情景进行处理:
-
原主库SSH连接正常:
各个从节点自动调用主节点:
save_binary_logs脚本文件,立即保存缺失部分的bin_log,到各节点/var/tmp/目录; -
原主库SSH连接异常:
各个从节点相互自动调用:
apply_diff_relay_logs脚本文件,进行relay_log日志差异信息补偿; -
额外特殊数据补充:(利用主库日志冗余机制)
MHA提供了binlog_server功能,可以实时拉取主库的binlog日志到备份节点,从而进行数据额外补偿;
05 MHA应用透明(VIP)
实现MHA的VIP功能,利用脚本实现,上传mha_script.tar文件到/usr/local/bin目录中,然后进行解压处理。
sh
1. 上传MHA脚本
[root@db03 ~]# cd /usr/local/bin/
[root@db03 bin]# chmod +x /usr/local/bin/*
[root@db03 bin]# dos2unix /usr/local/bin/*
[root@db03 bin]# ll
total 28
-rwxr-xr-x 1 root root 581 Aug 23 22:21 app1.cnf
-rwxr-xr-x 1 root root 2230 Aug 23 22:21 master_ip_failover
-rwxr-xr-x 1 root root 10312 Aug 23 22:21 master_ip_online_change
-rwxr-xr-x 1 root root 789 Aug 23 22:21 mha_check.sh
-rwxr-xr-x 1 root root 2238 Aug 23 22:21 send_report
2. 修改脚本信息
#MHA脚本文件的信息 VIP漂移信息
[root@db03 bin]# vim master_ip_failover
my $vip = '10.0.0.50/24';
my $key = '1';
my $ssh_start_vip = "/sbin/ifconfig eth0:$key $vip";
my $ssh_stop_vip = "/sbin/ifconfig eth0:$key down";
my $ssh_Bcast_arp= "/sbin/arping -I eth0 -c 3 -A 10.0.0.50";
3. 修改配置文件
#配置文件中添加VIP漂移参数
[root@db03 bin]# vim /etc/mha/app1.cnf
master_ip_failover_script=/usr/local/bin/master_ip_failover
4 .重启MHA服务
[root@db03 ~]# masterha_stop --conf=/etc/mha/app1.cnf
[root@db03 ~]# nohup masterha_manager --conf=/etc/mha/app1.cnf --remove_dead_master_conf --ignore_last_failover < /dev/null> /var/log/mha/app1/manager.log 2>&1 &
5. 手工在主库上添加VIP(第一次启动需要手工添加)
#核实此时的MHA的主库节点
[root@db03 ~]# masterha_check_status --conf=/etc/mha/app1.cnf
app1 (pid:5946) is running(0:PING_OK), master:10.0.0.51
#在主库节点手工添加vip地址信息
[root@db01 ~]# ifconfig eth0:1 10.0.0.50/24
[root@db01 ~]# ip a
#进行VIP地址连接测试
[root@db02 ~]# mysql -urepl -p12366 -h10.0.0.50说明:进行MHA的VIP地址漂移时,只能在局域网环境进行漂移,不能实现跨网段的VIP地址漂移;
06 MHA故障报警
实现MHA的报警功能,利用脚本实现
sh
1. 编写脚本
[root@db03 bin]# vim send_report
my $smtp='smtp.qq.com';
my $mail_from='1573374330@qq.com';
my $mail_user='1573374330';
my $mail_pass='xppiwvswtotnhggf';
#my $mail_to=['to1@qq.com','to2@qq.com'];
my $mail_to='1573374330@qq.com';
2. 修改配置文件
#发送邮件配置到mha中
[root@db03 bin]# vim /etc/mha/app1.cnf
report_script=/usr/local/bin/send_report
3 .重启MHA服务
[root@db03 ~]# masterha_stop --conf=/etc/mha/app1.cnf
[root@db03 ~]# nohup masterha_manager --conf=/etc/mha/app1.cnf --remove_dead_master_conf --ignore_last_failover < /dev/null> /var/log/mha/app1/manager.log 2>&1 &07 MHA额外补偿
利用binlog_server作为额外的日志补偿的冗余方案,即实时保存主库的bin_log日志文件到特定节点目录中;
sh
1. 创建日志存放目录
[root@db03 ~]# mkdir -p /data/binlog_server/
[root@db03 ~]# chown -R mysql.mysql /data/*
[root@db03 ~]# cd /data/binlog_server
[root@db03 binlog_server]# mysql -e "show slave status\G"|grep "Master_Log"
Master_Log_File: binlog.000001
Read_Master_Log_Pos: 1185
Relay_Master_Log_File: binlog.000001
Exec_Master_Log_Pos: 1185
2. 将主节点日志实时保存到db03服务器中的binlog_server目录
[root@db03 binlog_server]# mysqlbinlog -R --host=10.0.0.51 --user=mha --password=mha --raw --stop-never binlog.000001 &
[2] 6669
[root@db03 binlog_server]# ps -ef |grep mysqlbinlog
root 6669 5720 0 23:10 pts/2 00:00:00 mysqlbinlog -R --host=10.0.0.51 --user=mha --password=x x --raw --stop-never binlog.000001
[root@db03 binlog_server]# ll
total 4
-rw-r----- 1 root root 1185 Oct 12 23:10 binlog.000001
3. 编写配置文件信息
[root@db03 ~]# vim /etc/mha/app1.cnf
[binlog1]
no_master=1
hostname=10.0.0.53
master_binlog_dir=/data/binlog_server/
[binlog1]
no_master=1 #不存于竞选
hostname=10.0.0.53 #将日志额外补偿到哪个主机上
master_binlog_dir=/data/binlog_server/ #日志额外补偿的存储目录
4 .重启MHA服务
[root@db03 ~]# masterha_stop --conf=/etc/mha/app1.cnf
[root@db03 ~]# nohup masterha_manager --conf=/etc/mha/app1.cnf --remove_dead_master_conf --ignore_last_failover < /dev/null> /var/log/mha/app1/manager.log 2>&1 &5.数据库高可用故障切换
5.1 故障模拟
模拟进行指定主库节点故障情况,检查核实MHA相应功能脚本是否能够正确运行
sh
# 确认目前的MHA的状态是良好的
[root@db03 ~]# masterha_check_status --conf=/etc/mha/app1.cnf
app1 (pid:6828) is running(0:PING_OK), master:10.0.0.51
# 模拟DB01数据库节点宕机
[root@db01 ~]# /etc/init.d/mysqld stop
Shutting down MySQL........... SUCCESS!
# 监控DB03日志信息的变化
[root@db03 ~]# tail -f /var/log/mha/app1/manager5.2 实现MHA高可用切换
01 健康检查异常
MHA健康检查报错,显示主数据库节点无法正常连接
sh
# 日志信息分析
[waring] Got error on MySQL connect: 2003 (Can't connect to MySQL server on '10.0.0.51' (111))
[waring] Connection failed 2 time(s)..
[waring] Got error on MySQL connect: 2003 (Can't connect to MySQL server on '10.0.0.51' (111))
[waring] Connection failed 3 time(s)..
[waring] Got error on MySQL connect: 2003 (Can't connect to MySQL server on '10.0.0.51' (111))
[waring] Connection failed 4 time(s)..
[waring] Master is not reachable from health checker!
[waring] Master 10.0.0.51(10.0.0.51:3306) is not reachable!
-- 对故障主节点进行4次健康检查,主节点数据库服务仍旧无法连接,即判定主节点故障02 MHA重新选主
MHA进行重新选主,根据数组信息选择合适的备用新主节点
sh
[info] Connecting to a master server failed. Reading configuration file /etc/masterha_default.cnf and /etc/mha/app1.cnf again, and trying to connect to all servers to check server status..
[info] Reading application default configuration from /etc/mha/app1.cnf
....
[info] Starting master failover
....
[info] ** Phase 1: Configuration Check Phase completed.03 MHA节点关闭
MHA进行节点关闭,选择完新的主节点后会将原有主节点的VIP地址消除
tiki
[info] * Phase 2: Dead Master Shutdown Phase..
[info] Forcing shutdown so that applications never connect to the current master..
Disabling the VIP on old master: 10.0.0.5104 MHA节点切换
MHA进行节点切换,在新的主节点上进行非同步数据信息的补偿,
sh
[info] * Phase 3: Master Recovery Phase..
[info] * Phase 3.1: Getting Latest Slaves Phase..
....
[info] * Phase 3.3: Determining New Master Phase..
[info] New master is 10.0.0.52(10.0.0.52:3306)
[info] Starting master failover..
[info] * Phase 3.3: New Master Recovery Phase..
[info] Executing binlog save command: save_binary_logs --command=save --start_file=mysql-bin.000002 --start_pos=1201 --output_file=/var/tmp/saved_binlog_binlog1_20230102153233.binlog --handle_raw_binlog=0 --skip_filter=1 --disable_log_bin=0 --manager_version=0.58 --oldest_version=8.0.26 --binlog_dir=/data/binlog_server/
[info] Additional events were not found from the binlog server. No need to save.
Enabling the VIP - 10.0.0.50/24 on the new master - 10.0.0.52
Mon Jan 2 15:32:36 2023 - [info] OK.
Mon Jan 2 15:32:36 2023 - [info] ** Finished master recovery successfully.
[info] * Phase 3: Master Recovery Phase completed.05 主从重构
MHA进行主从重构,将从库连接到新的主库上
sh
[info] * Phase 4: Slaves Recovery Phase..
[info] * Phase 4.1: Starting Slaves in parallel..
[info] Resetting slave 10.0.0.53(10.0.0.53:3306) and starting replication from the new master 10.0.0.52(10.0.0.52:3306)..
[info] Executed CHANGE MASTER.
[info] Slave started.
[info] All new slave servers recovered successfully.06 MHA切换完毕
MHA切换完毕过程,架构故障转移切换完毕后做清理阶段,并进行最终汇报
sh
[info] * Phase 5: New master cleanup phase..
----- Failover Report -----
Master failover to 10.0.0.52(10.0.0.52:3306) completed successfully.
Mon Jan 2 15:32:37 2023 - [info] Sending mail..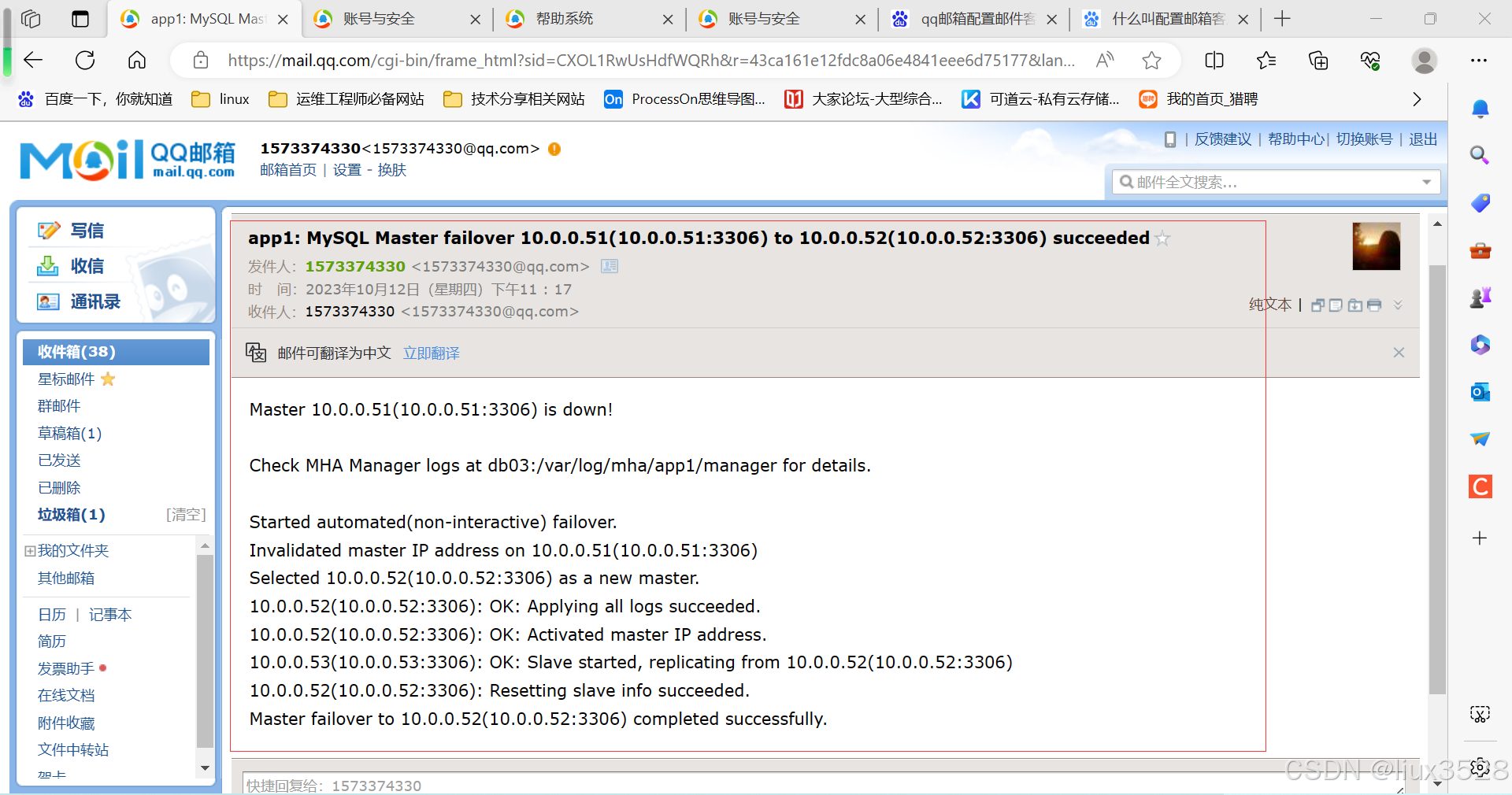
07 切换完成结果查看
sh
1. VIP已成功漂移到db02
[root@db01 ~]# ip a |grep 10.0.0.50
[root@db01 ~]#
[root@db02 ~]# ip a |grep 10.0.0.50
inet 10.0.0.50/24 brd 10.0.0.255 scope global secondary eth0:1
2. 核实主从关系
[root@db03 ~]# mysql -e "show slave status\G"
*************************** 1. row ***************************
Slave_IO_State: Waiting for source to send event
Master_Host: 10.0.0.52
Master_User: repl
Master_Port: 3306
3. 查看MHA配置文件信息
[root@db03 ~]# cat /etc/mha/app1.cnf
[binlog1]
hostname=10.0.0.53
master_binlog_dir=/data/binlog_server/
no_master=1
[server default]
manager_log=/var/log/mha/app1/manager
manager_workdir=/var/log/mha/app1
master_binlog_dir=/data/binlog
master_ip_failover_script=/usr/local/bin/master_ip_failover
password=mha
ping_interval=2
repl_password=12366
repl_user=repl
report_script=/usr/local/bin/send_report
ssh_user=root
user=mha
[server2]
candidate_master=1
hostname=10.0.0.52
port=3306
[server3]
hostname=10.0.0.53
port=3306
--故障节点db01信息已从配置文件中清理
4. MHA程序已终止
[root@db03 ~]# ps -ef|grep mha
root 6994 5720 0 23:35 pts/2 00:00:00 grep --color=auto mha
[root@db03 ~]# masterha_check_status --conf=/etc/mha/app1.cnf
app1 is stopped(2:NOT_RUNNING).6.数据库高可用修复方法
MHA故障通用修复方法步骤:(前提是MHA进行正常故障切换,通过日志可以检查是否进行正常的故障转移)
6.1 检查节点状态
sh
# 检查节点数据库运行状态
[root@db01 ~]# /etc/init.d/mysqld status
ERROR! MySQL is not running
[root@db01 ~]# /etc/init.d/mysqld start
Starting MySQL.. SUCCESS!
-- 恢复DB01异常数据库服务节点在实际生产环境中,如果主库异常无法实现重新启动修复,可能就需要准备一台新的节点主机,重新构建1主2从的架构;
但是如果使用新的节点主机,进行主从架构重构,修复高可用环境,就需要考虑新主机的在恢复数据的时间损耗;
总之,需要将新节点的数据信息进行同步后,再将新节点变为新的从库,从而修复高可用主从关系,具体如何修复数据需要考虑实际情况
6.2 检查、修复主从关系
sh
1. 确认切换后的新主库信息
[root@db03 ~]# mysql -e "show slave status\G"|grep "Master_Host"
Master_Host: 10.0.0.52
2. db01上修复主从
db01 [(none)]>change master to
master_host='10.0.0.52',
master_user='repl',
master_password='12366',
master_auto_position=1;
db01 [(none)]>start slave;
db01 [(none)]>show slave status\G;
3. 核实主从关系
[root@db01 ~]# mysql -e "show slave status\G"|grep "Master_Host"
Master_Host: 10.0.0.526.3 master节点检查VIP漂移地址
sh
[root@db02 ~]# ip a |grep 10.0.0.50
inet 10.0.0.50/24 brd 10.0.0.255 scope global secondary eth0:1
--若漂移VIP失败,则可以手工设置
ifconfig eth0:1 10.0.0.50/246.4 恢复日志同步
sh
[root@db03 ~]# ps -ef|grep mysqlbinlog
-- binlog_server日志同步进程消失
#修复binlog_server状态
[root@db03 ~]# rm -rf /data/binlog_server/*
[root@db03 ~]# cd /data/binlog_server/
[root@db03 binlog_server]# mysql -e "show slave status\G"|grep "Master_Log"
Master_Log_File: binlog.000001
Read_Master_Log_Pos: 1213
Relay_Master_Log_File: binlog.000001
Exec_Master_Log_Pos: 1213
[root@db03 binlog_server]# mysqlbinlog -R --host=10.0.0.52 --user=mha --password=mha --raw --stop-never binlog.000001 &
[1] 7031
[root@db03 binlog_server]# ll
total 4
-rw-r----- 1 root root 1213 Oct 12 23:53 binlog.0000016.5 调整配置文件
sh
1.添加DB01故障节点到配置文件中
[root@db03 binlog_server]# masterha_conf_host --command=add --conf=/etc/mha/app1.cnf --hostname=10.0.0.51 --block=server1 --params="port=3306"
[root@db03 binlog_server]# cat /etc/mha/app1.cnf
...
[server1]
hostname=10.0.0.51
port=3306
...
#利用命令脚本删除指定的节点信息
[root@liux-03 ~]# masterha_conf_host --command=delete --conf=/etc/mha/app1.cnf --block=server1 6.6 核实互信情况
sh
[root@db03 binlog_server]# masterha_check_ssh --conf=/etc/mha/app1.cnf
[root@db03 binlog_server]# masterha_check_repl --conf=/etc/mha/app1.cnf6.7 恢复启动MHA
sh
[root@db03 binlog_server]# nohup masterha_manager --conf=/etc/mha/app1.cnf --remove_dead_master_conf --ignore_last_failover < /dev/null> /var/log/mha/app1/manager.log 2>&1 &
[2] 7152
[root@db03 binlog_server]# masterha_check_status --conf=/etc/mha/app1.cnf
app1 (pid:7152) is running(0:PING_OK), master:10.0.0.527.数据库高可用维护操作
7.1 实现MHA高可用主节点在线切换(手工操作)
可以在主库没有故障的情况下,利用手工方式将主库业务切换到其它的从库节点上,从而解放原有主库节点(维护性操作时应用);
sh
1.关闭MHA服务程序
[root@db03 binlog_server]# masterha_stop --conf=/etc/mha/app1.cnf
-- 关闭mha程序是保证手工切换时,不会受到mha自动切换的影响
2. 执行MHA手工切换
[root@db03 ~]#masterha_master_switch --conf=/etc/mha/app1.cnf --master_state=alive --new_master_host=10.0.0.51 --orig_master_is_new_slave --running_updates_limit=10000
...
It is better to execute FLUSH NO_WRITE_TO_BINLOG TABLES on the master before switching. Is it ok to execute on 10.0.0.52(10.0.0.52:3306)? (YES/no):
-- 以上说明信息,表示在进行切换之前,在原有主库节点执行FLUSH NO_WRITE_TO_BINLOG TABLES这个命令
-- 此命令表示,关闭所有打开的表,强制关闭所有正在使用的表,不写入binlog;
-- 因为此时VIP还没有漂移,表示禁止原主库继续写入数据信息
#关闭原主库的写入功能
db02 [(none)]>FLUSH NO_WRITE_TO_BINLOG TABLES ;
Is it ok to execute on 10.0.0.52(10.0.0.52:3306)? (YES/no):YES
Starting master switch from 10.0.0.52(10.0.0.52:3306) to 10.0.0.51(10.0.0.51:3306)? (yes/NO): yes
master_ip_online_change_script is not defined. If you do not disable writes on the current master manually, applications keep writing on the current master. Is it ok to proceed? (yes/NO):
--出现master_ip_online_change_script is not defined时,提示没有配置在线漂移VIP脚本,停止下一步操作
3. 编写MHA手工切换脚本文件master_ip_online_change_script功能脚本
#此脚本可以在线进行切换时,自动锁定原主库,以及将原主库VIP地址进行自动飘移
[root@db03 ~]# cd /usr/local/bin/
[root@db03 bin]# vim master_ip_online_change
...
###########################################################################
my $vip = "10.0.0.50";
my $key = "1";
my $ssh_start_vip = "/sbin/ifconfig eth0:$key $vip";
my $ssh_stop_vip = "/sbin/ifconfig eth0:$key $vip down";
my $ssh_Bcast_arp= "/sbin/arping -I eth0 -c 3 -A 10.0.0.50";
###########################################################################
...
4. 修改MHA服务程序配置文件
[root@db03 ~]# vim /etc/mha/app1.cnf
master_ip_online_change_script=/usr/local/bin/master_ip_online_change
5. 再次进行MHA服务手工在线切换
[root@db03 ~]#masterha_master_switch --conf=/etc/mha/app1.cnf --master_state=alive --new_master_host=10.0.0.51 --orig_master_is_new_slave --running_updates_limit=10000
--步骤参照2操作
...
[info] Switching master to 10.0.0.51(10.0.0.51:3306) completed successfully.
6. 重构binlogserver功能
[root@db03 ~]# cd /data/binlog_server/
[root@db03 binlog_server]# rm -rf ./*
[root@db03 binlog_server]# mysql -e "show slave status\G"|grep "Master_Log"
Master_Log_File: binlog.000002
Read_Master_Log_Pos: 196
Relay_Master_Log_File: binlog.000002
Exec_Master_Log_Pos: 196
[root@db03 binlog_server]# mysqlbinlog -R --host=10.0.0.51 --user=mha --password=mha --raw --stop-never binlog.000001 &
[root@db03 binlog_server]# ll
total 8
-rw-r----- 1 root root 1208 Oct 13 00:20 binlog.000001
-rw-r----- 1 root root 196 Oct 13 00:20 binlog.000002
7.恢复启动MHA
[root@db03 ~]# nohup masterha_manager --conf=/etc/mha/app1.cnf --remove_dead_master_conf --ignore_last_failover < /dev/null> /var/log/mha/app1/manager.log 2>&1 &
[3] 7441
[root@db03 ~]# masterha_check_status --conf=/etc/mha/app1.cnf
app1 (pid:7441) is running(0:PING_OK), master:10.0.0.51
#查看主从关系
[root@db01 ~]# mysql -e "show slave hosts;"
+-----------+------+------+-----------+--------------------------------------+
| Server_id | Host | Port | Master_id | Slave_UUID |
+-----------+------+------+-----------+--------------------------------------+
| 53 | | 3306 | 51 | 80c3ac5f-6900-11ee-95a7-000c29878b35 |
| 52 | | 3306 | 51 | 7ed80e81-6900-11ee-9663-000c2957def8 |
+-----------+------+------+-----------+--------------------------------------+执行切换命令参数信息说明:
| 序号 | 参数信息 | 解释说明 |
|---|---|---|
| 01 | --master_state | 执行手工切换的状态,alive表示主节点存活状态进行切换 |
| 02 | --new_master_host | 指定切换后的新主库节点的地址信息 |
| 03 | -- orig_master_is_new_slave | 将原有主库指定为新的从库角色 |
| 04 | --running_updates_limit | 指定切换过程的时间限制,超过指定时间未完成切换,即切换失败,单位毫秒 |
在进行MHA高可用节点在线手工切换时,有以下信息需要注意:
- 无法自动调整原有主库的binlog_server,需要手工重新拉取新主库的binlog;
- 无法进行触发邮件脚本功能,邮件发送功能只能在MHA产生故障转移时触发;
- 需要进行架构主从关系的切换,以及可以调整转移VIP地址信息;
- 需要对切换前的主库进行锁定(FTWRL flush tables with read lock),避免数据不一致。
8.总结
MHA作为MySQL高可用生态的重要组成部分,虽然有其特定限制,但在许多生产环境中仍然发挥着关键作用。随着技术发展,虽然出现了更多新型高可用方案(如MGR、云原生方案等),但MHA的设计思想和实践经验仍然具有重要参考价值。掌握MHA不仅是为了应对当前需求,更是为了培养全面的高可用架构思维,为应对未来更复杂的技术挑战打下坚实基础。
在实际应用中,建议结合具体业务需求、技术团队能力和基础设施条件,选择最适合的高可用方案。无论选择哪种方案,核心目标都是相同的:在保证数据安全的前提下,提供持续可用的数据服务,为业务创造稳定可靠的技术支撑。