一、增删改查(CRUD)
CRUD是数据库操作的基石,对应创建(create)、读取(read)、更新(update)、删除(delete)四类核心操作。
0. 创建用户表
sql
-- 创建用户信息表
CREATE TABLE IF NOT EXISTS user_info (
id INT PRIMARY KEY AUTO_INCREMENT COMMENT '用户ID',
username VARCHAR(50) NOT NULL UNIQUE COMMENT '用户名',
age INT COMMENT '年龄',
phone VARCHAR(20) COMMENT '手机号',
create_time DATETIME DEFAULT CURRENT_TIMESTAMP COMMENT '创建时间',
update_time DATETIME DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP COMMENT '更新时间'
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COMMENT='用户信息表';
1. 新增数据
单条插入
insert into 表名 (字段1,字段2,......) values (值1,值2,......);
批量插入
insert into 表名 (字段1,字段2,......)
values
(值1,值2,......),
(值1,值2,......),
...;
sql
-- 单条插入
INSERT INTO user_info (username, age, phone) VALUES ('zhangsan', 25, '13800138000');
sql
-- 批量插入(效率更高)
INSERT INTO user_info (username, age, phone)
VALUES
('lisi', 28, '13800138001'),
('wangwu', 30, '13800138002');
2. 查询数据
select 字段1,字段2,... | * from 表名
where 条件
order by 字段 \[asc \| desc\]
limit 偏移量,条数;
参数说明:
- * :代表查询所有字段
- where :筛选条件,支持 " = > < in like " 等运行符
- order by :排序,asc 升序,desc 降序
- limit:分页,偏移量=(页码 - 1)x 每页条数
sql
-- 基础查询:查询所有字段
SELECT * FROM user_info;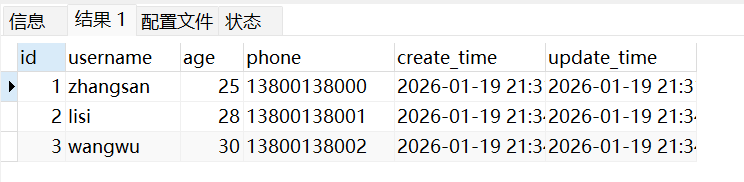
sql
-- 指定字段查询:只查用户名和年龄
SELECT username, age FROM user_info;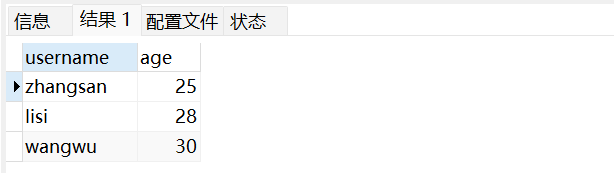
sql
-- 条件查询:年龄大于25且手机号以138开头的用户
SELECT username, age FROM user_info WHERE age > 25 AND phone LIKE '138%';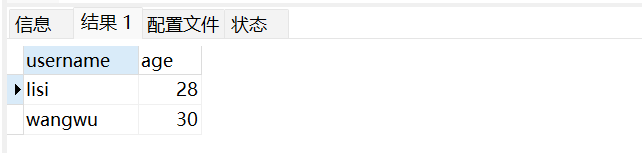
sql
-- 排序查询:按年龄降序、创建时间升序排列
SELECT username, age FROM user_info ORDER BY age DESC, create_time ASC;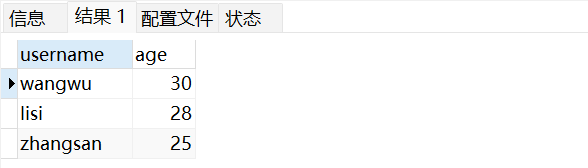
sql
-- 分页查询:第2页,每页2条(偏移量=2,条数=2)
SELECT username, age FROM user_info LIMIT 2, 2;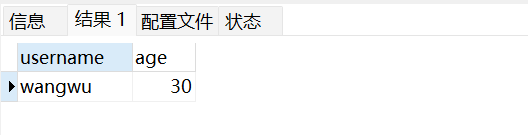
3. 更新数据
update 表名
set 字段1 = 值1,字段2 = 值2,...
where 条件;
⚠️没有where条件的话会更新全表数据
sql
-- 条件更新:修改lisi的年龄为29,手机号为13800138005
UPDATE user_info SET age = 29, phone = '13800138005' WHERE username = 'lisi';
sql
-- 错误示例(谨慎执行):无WHERE条件,全表age字段被修改
-- UPDATE user_info SET age = 30;4. 删除数据
delete from 表名
where 条件;
清空表 (重置自增主键,不可回滚)
truncate table 表名;
sql
-- 条件删除:删除手机号为13800138002的用户
DELETE FROM user_info WHERE phone = '13800138002';
sql
-- 清空表(谨慎使用:truncate会重置自增主键,且无法通过事务回滚)
-- TRUNCATE TABLE user_info;二、索引
索引是MySQL优化查询的关键,相当于书籍的目录,可以避免全表扫描,大幅度提升查询速度。
1. 索引的核心类型与语法
创建普通索引
create index 索引名 on 表名 (字段1,字段2,......);
创建唯一索引(字段值不可重复)
create unique index 索引名 on 表名 (字段);
创建主键索引(表默认自带,无需手动创建)
alter table 表名 add primary key (字段);
删除索引
drop index 索引名 on 表名;
查看表索引
show index from 表名;
sql
-- 创建普通索引:给phone字段创建索引(适合查询频繁的字段)
CREATE INDEX idx_user_info_phone ON user_info(phone);
sql
-- 创建复合索引:年龄+手机号(适合多字段联合查询)
CREATE INDEX idx_user_info_age_phone ON user_info(age, phone);
sql
-- 创建唯一索引:username字段值唯一,适合创建唯一索引
CREATE UNIQUE INDEX idx_user_info_username ON user_info(username);
sql
-- 查看索引
SHOW INDEX FROM user_info;
sql
-- 删除索引
DROP INDEX idx_user_info_phone ON user_info;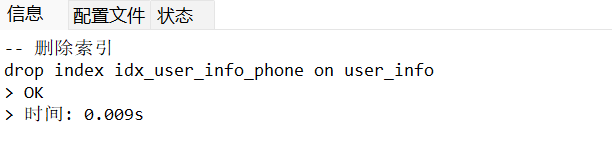
三、事务
保证数据操作的原子性,用于保证一组操作要么全部成功,要么全部失败,核心适用于转账,订单提交等场景。
1. 事务的ACID特性
-
原子性(Atomicity):事务中的操作不可分割,要么全做,要么全不做;
-
一致性(Consistency):事务执行前后,数据完整性保持一致(如转账总金额不变);
-
隔离性(Isolation) :MySQL 默认隔离级别为
REPEATABLE READ(可重复读),避免脏读、不可重复读; -
持久性(Durability):事务提交后,数据修改永久生效,即使数据库崩溃也不会丢失。
2. 事务语法
开启事务
start transaction; / begin;
执行SQL操作(增删改)
SQL语句1;
SQL语句2;
...
提交事务(所有操作生效)
commit;
回滚事务(撤销所有操作)
rollback;
保存点(部分回滚)
savepoint 保存点名;
rollback to 保存点名;
模拟转账场景:用户1给用户2转100元
sql
-- 先创建账户表
CREATE TABLE IF NOT EXISTS account (
user_id INT PRIMARY KEY COMMENT '用户ID',
balance DECIMAL(10,2) DEFAULT 0 COMMENT '账户余额'
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;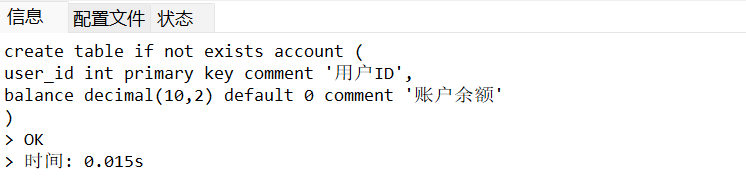
sql
-- 插入测试数据
INSERT INTO account (user_id, balance) VALUES (1, 1000), (2, 500);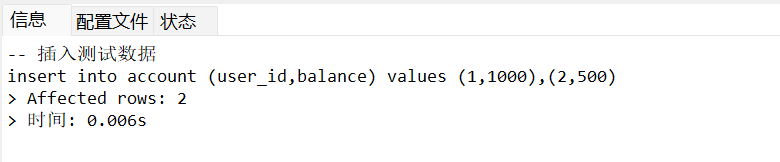
sql
-- 开启事务
START TRANSACTION;
sql
-- 操作1:用户1账户减100元
UPDATE account SET balance = balance - 100 WHERE user_id = 1;
sql
-- 操作2:用户2账户加100元
UPDATE account SET balance = balance + 100 WHERE user_id = 2;
sql
-- 验证数据(事务未提交,仅当前会话可见)
SELECT * FROM account;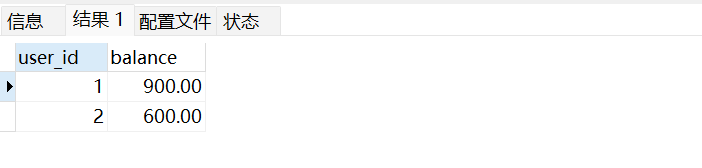
sql
-- 提交事务(所有操作生效)
COMMIT;
-- 若操作过程中出错,回滚事务(所有操作撤销)
-- ROLLBACK;
sql
-- 保存点示例
START TRANSACTION;
UPDATE account SET balance = balance - 50 WHERE user_id = 1;
SAVEPOINT sp1; -- 创建保存点
UPDATE account SET balance = balance + 50 WHERE user_id = 2;
ROLLBACK TO sp1; -- 回滚到保存点(仅撤销第二个更新)
COMMIT;四、多表查询
实际业务中,单一表查询无法满足需求,需要通过多表联查、子查询、聚合函数实现复杂的数据验证。
1. 多表联查
先创建订单表 order_info , 关联 user_info 表:
sql
CREATE TABLE IF NOT EXISTS order_info (
order_id INT PRIMARY KEY AUTO_INCREMENT COMMENT '订单ID',
user_id INT NOT NULL COMMENT '用户ID(关联user_info.id)',
order_amount DECIMAL(10,2) COMMENT '订单金额',
order_status TINYINT COMMENT '订单状态:1-待支付,2-已支付,3-已取消',
create_time DATETIME DEFAULT CURRENT_TIMESTAMP COMMENT '创建时间',
FOREIGN KEY (user_id) REFERENCES user_info(id)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COMMENT='订单表';
sql
-- 插入测试订单数据
INSERT INTO order_info (user_id, order_amount, order_status)
VALUES (1, 199.99, 2), (1, 89.99, 1), (2, 299.99, 2);
1.1 内连接
select 字段列表
from 表1
inner join 表2 on 表1.关联字段 = 表2.关联字段
where 条件;
逻辑:只返回两张表中匹配的记录
sql
-- 查询有订单的用户信息(仅返回有匹配的记录)
SELECT u.username, o.order_id, o.order_amount, o.order_status
FROM user_info u
INNER JOIN order_info o ON u.id = o.user_id
WHERE o.order_status = 2; -- 仅查已支付订单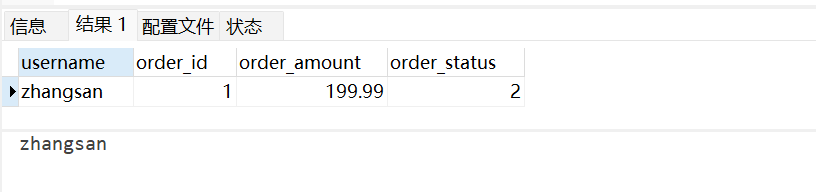
1.2 左连接
查询所有用户,包括无订单的用户(无订单则订单字段为NULL)
select u.username,o.order_id,o.order_amount
from user_info u
left join order_info o on u.id = o.user_id;
逻辑:返回主表所有记录,从表无匹配则显示NULL
sql
-- 查询所有用户,包括无订单的用户(无订单则订单字段为NULL)
SELECT u.username, o.order_id, o.order_amount
FROM user_info u
LEFT JOIN order_info o ON u.id = o.user_id;
1.3 右连接
select 字段列表
from 表1
right join 表2 on 表1.关联字段 = 表2.关联字段
where 条件;
逻辑:返回从表所有记录,主表无匹配则显示NULL
sql
-- 查询所有订单,包括无匹配用户的订单(如用户被删除但订单留存)
SELECT u.username, o.order_id, o.order_amount
FROM user_info u
RIGHT JOIN order_info o ON u.id = o.user_id;
2. 子查询
子查询是将一个查询结果作为另一个查询的条件/数据源,适用于分步验证数据。
作为where查询条件(单行子查询)
select 字段列表 from 表名
where 字段 运算符 (select 字段 from 表名 where 条件);
作为where条件(多行子查询)
select 字段列表 from 表名
where 字段 in (select 字段 from 表名 where 条件);
作为数据源(派生表)
select 字段列表 from (select 字段 from 表名) as 别名;
sql
-- 示例1:单行子查询 - 查询订单金额大于平均金额的订单
SELECT order_id, order_amount
FROM order_info
WHERE order_amount > (SELECT AVG(order_amount) FROM order_info);
sql
-- 示例2:多行子查询 - 查询有已支付订单的用户名称
SELECT username
FROM user_info
WHERE id IN (SELECT DISTINCT user_id FROM order_info WHERE order_status = 2);
sql
-- 示例3:派生表 - 统计每个用户的已支付订单数
SELECT u.username, t.order_count
FROM user_info u
LEFT JOIN (
SELECT user_id, COUNT(*) AS order_count
FROM order_info
WHERE order_status = 2
GROUP BY user_id
) t ON u.id = t.user_id;
1.3 聚合函数
聚合函数用于对数据进行统计计算,常用的有 COUNT、SUM、AVG、MAX、MIN,配合 GROUP BY 实现分组统计。
|-------|-------------|---------------------------------------|
| 函数 | 公式 | 说明 |
| count | count(字段*) | 统计记录数(count(*)含null,count(字段)不含null) |
| sum | sum(字段) | 求和(仅数值型字段) |
| avg | avg(字段) | 求平均值(仅数值型字段) |
| max | max(字段) | 求最大值 |
| min | min(字段) | 求最小值 |
select 聚合函数1(字段),聚合函数2(字段),...
from 表名
where 条件
group by 分组字段1,分组字段2,...
having 聚合条件;
区别:where筛选原始数据,having筛选聚合后的数据
sql
-- 示例1:全局统计 - 所有订单的核心指标
SELECT
COUNT(*) AS total_order, -- 总订单数
SUM(order_amount) AS total_amount, -- 总金额
AVG(order_amount) AS avg_amount, -- 平均金额
MAX(order_amount) AS max_amount, -- 最大订单金额
MIN(order_amount) AS min_amount -- 最小订单金额
FROM order_info;
sql
-- 示例2:分组统计 - 每个用户的订单统计(仅显示订单数>1的用户)
SELECT
u.username,
COUNT(o.order_id) AS order_count, -- 订单数
SUM(o.order_amount) AS total_amount -- 总金额
FROM user_info u
LEFT JOIN order_info o ON u.id = o.user_id
GROUP BY u.id, u.username
HAVING COUNT(o.order_id) > 0; -- 筛选有订单的用户
sql
-- 示例3:条件聚合 - 统计每个用户的已支付/待支付订单金额
SELECT
user_id,
SUM(CASE WHEN order_status = 2 THEN order_amount ELSE 0 END) AS paid_amount,
SUM(CASE WHEN order_status = 1 THEN order_amount ELSE 0 END) AS unpaid_amount
FROM order_info
GROUP BY user_id;