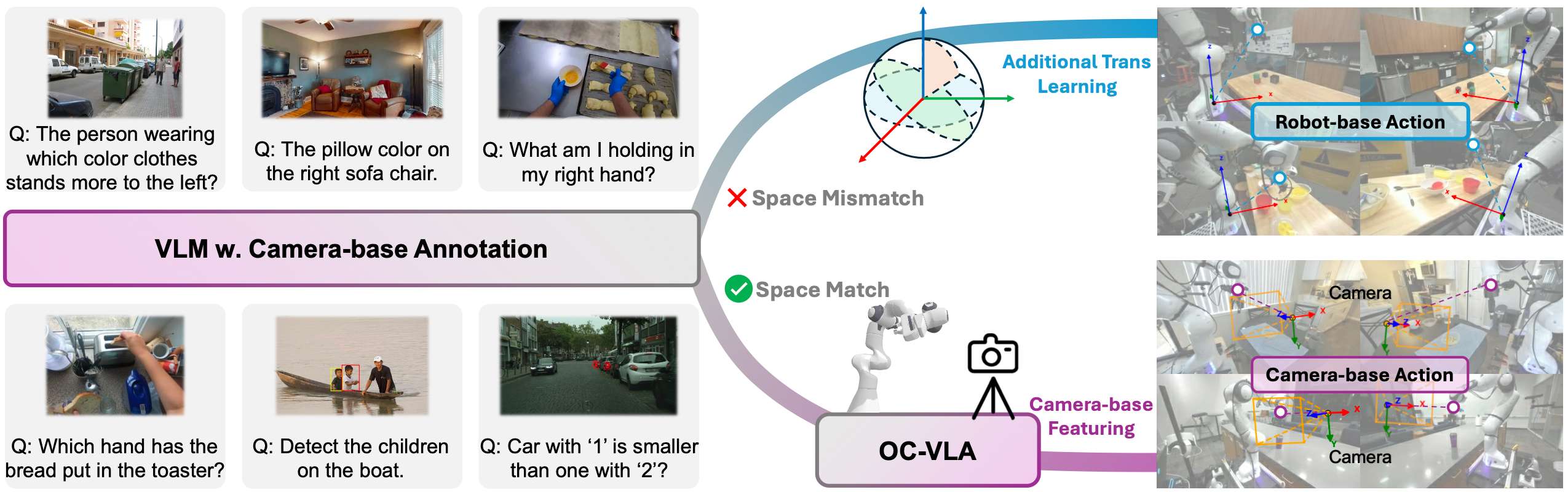
OC-VLA提出的背景和动机
在 VLA 模型中,一种常见的做法是将预训练的视觉-语言模型或视觉编码器应用于下游机器人任务以增强模型的泛化能力。然而,这些视觉模型主要是在相机坐标系中进行标注、训练和监督的,因此其潜在表征是对齐到相机空间的。相比之下,大多数机器人控制信号是在机器人基坐标系中进行定义和完成采集的。这种差异导致感知空间和动作空间之间存在错位,阻碍了机器人策略的有效学习,特别是将预训练的视觉模型迁移到机械人控制任务时。
机器人数据通常是在多样的相机视角和异构硬件配置下收集的,这种情况下,必须从不同的第三方摄像机视角预测出在机器人坐标系中执行的相同动作。这隐式地要求模型从有限的二维观测中重建或推断出一致的三维动作。这种不一致性在大规模预训练期间尤其有害,因为训练数据中往往存在不同的摄像机视角的观测信息:从不同角度捕捉同一机械臂动作的图像被迫共享机器人坐标系空间中的单个监督信号,从而引入学习冲突并阻碍泛化。
为了解决这些问题,这里提出了一种新颖的范式,该范式将机器人的监督动作与机器人坐标系解耦,转而直接在第三人称相机坐标系中预测动作,称之为Observation-Centric VLA(OC-VLA)。给定机械臂基座和每个相机之间的外参变换,我们将机械臂空间中的末端执行器动作转换到相机坐标系中的等效表示,并将其作为预测目标。通过将动作目标锚定在与视觉观察相同的空间中,这种方法减轻了感知和动作模态之间的错位,缓解了相机视角变化带来的歧义。此外,它明确地鼓励模型学习机械臂和相机之间的相对空间关系,从而增强其在不同视角和硬件配置下的泛化能力。
核心设计与方法
OC-VLA的核心设计在于将预测目标由机械臂基座坐标系重新定义到第三人称相机坐标系中。这使得模型看到的图像和预测的动作都在同一个空间参考系中定义,极大缓解了感知与动作之间的错位问题。
训练阶段
将数据中机械臂的pose由机械臂基座坐标系定义到第三人称相机坐标系,可表示为:
P c a m = T P w o r l d P_{cam} = TP_{world} Pcam=TPworld
T T T表示第三人称相机的外参矩阵, P c a m P_{cam} Pcam和 P w o r l d P_{world} Pworld分别表示机械臂的pose在第三人称相机坐标系和机械臂基座坐标系下的表示。第三人称相机坐标系下的机械臂的action A c a m A_{cam} Acam表示为:
A c a m = P c a m 2 P c a m 1 − 1 A_{cam} = P_{cam_{2}}P_{cam_{1}}^{-1} Acam=Pcam2Pcam1−1
推理阶段
将模型预测的机械臂的pose或action由第三人称相机坐标系重新定义到机械臂基座坐标系,并用于机械臂控制
P c a m 2 = A c a m P c a m 1 P w o r l d = T − 1 P c a m P_{cam_{2}} = A_{cam}P_{cam_{1}} \\ P_{world} = T^{-1}P_{cam} Pcam2=AcamPcam1Pworld=T−1Pcam
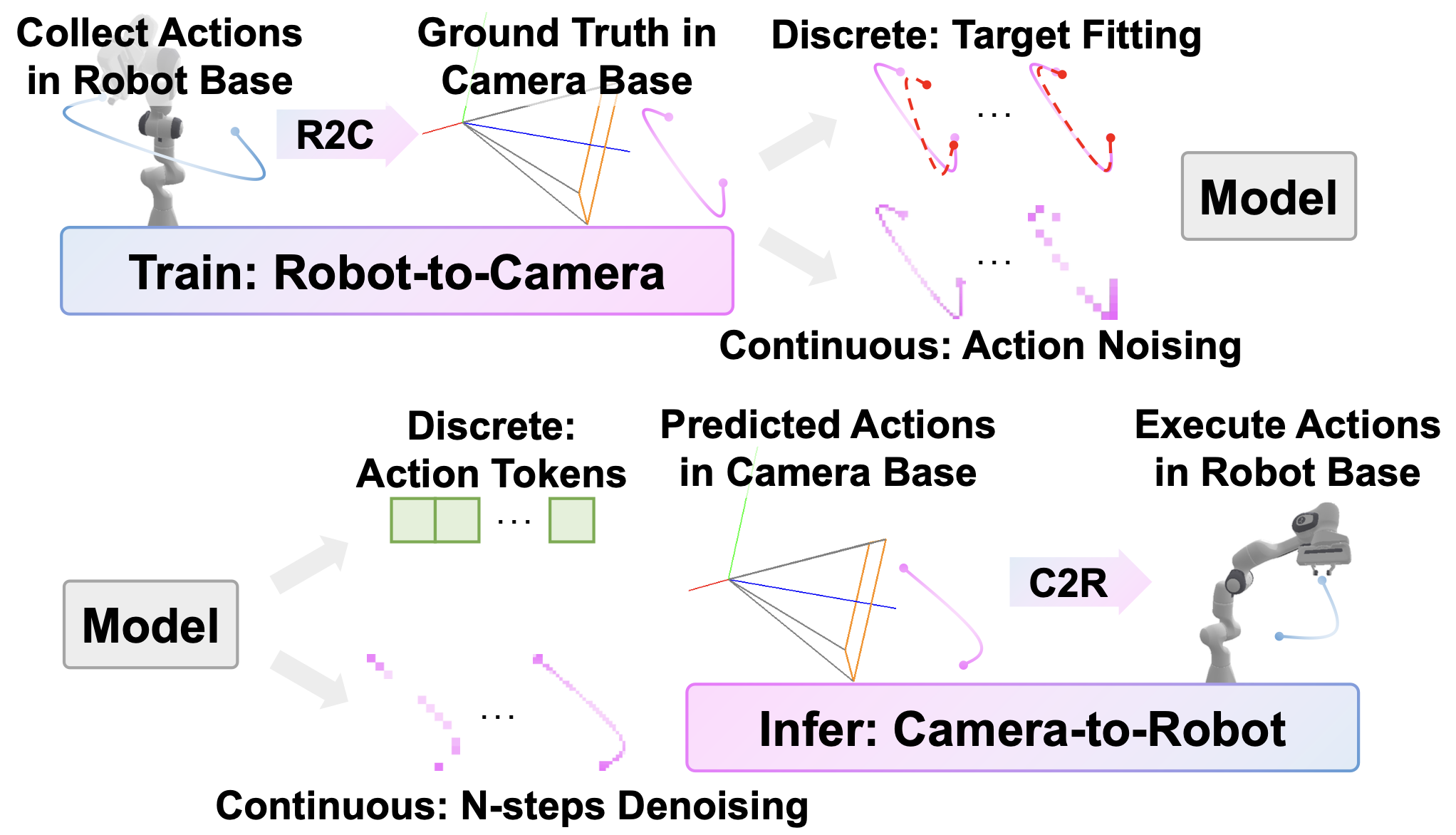
OC-VLA的做法完全模块化,不依赖特定的网络结构或模型类型,能无缝集成至当前主流的离散token式或连续动作生成式策略模型中,无需增加额外计算成本。通过这种空间对齐,模型在训练时能够避免视角冲突带来的监督混淆,从而提高学习的稳定性与收敛效率,同时在面对视角变化(如不同摄像头位置、轻微扰动或部署到新平台)时具备更强的泛化能力与鲁棒性。
实验结果
模型结构
OC-VLA采用Dita的模型结构来进行实验,并分别在离散动作空间和连续动作空间域内进行了实验验证。有关Dita的具体细节可详见https://robodita.github.io/。

ManiSkill2上的仿真实验
从 ManiSkill2 套件中选择了五个代表性任务:PickCube-v0、StackCube-v0、PickSingleYCB-v0、PickClutterYCB-v0 和 PickSingleEGAD-v0,并生成了一个包含30万个随机配置的相机视角的相机位置集合。对于每条轨迹,我们随机在集合中选取20个相机位置来渲染演示,从而生成一个包含超过4万条独特轨迹的数据集。

这里比较了是否在第三人称相机空间内预测的结果。实验结果显示,无论使用何种类型的动作空间,使用在第三人称相机坐标系中定义的机器人动作作为预测目标都能显著提高任务成功率。这种提升在采用离散动作空间的模型中尤为显著,成功率提高了约14%。

真机实验
使用Franka机械臂平台进行实验。该平台包含一个7自由度的Franka Emika Panda 机械臂,配备Robotiq 2F-85夹爪。平台配备三台 RealSense D435i 相机,两台相机用于数据采集和少样本评估,而另一台相机则专门用于零样本评估。
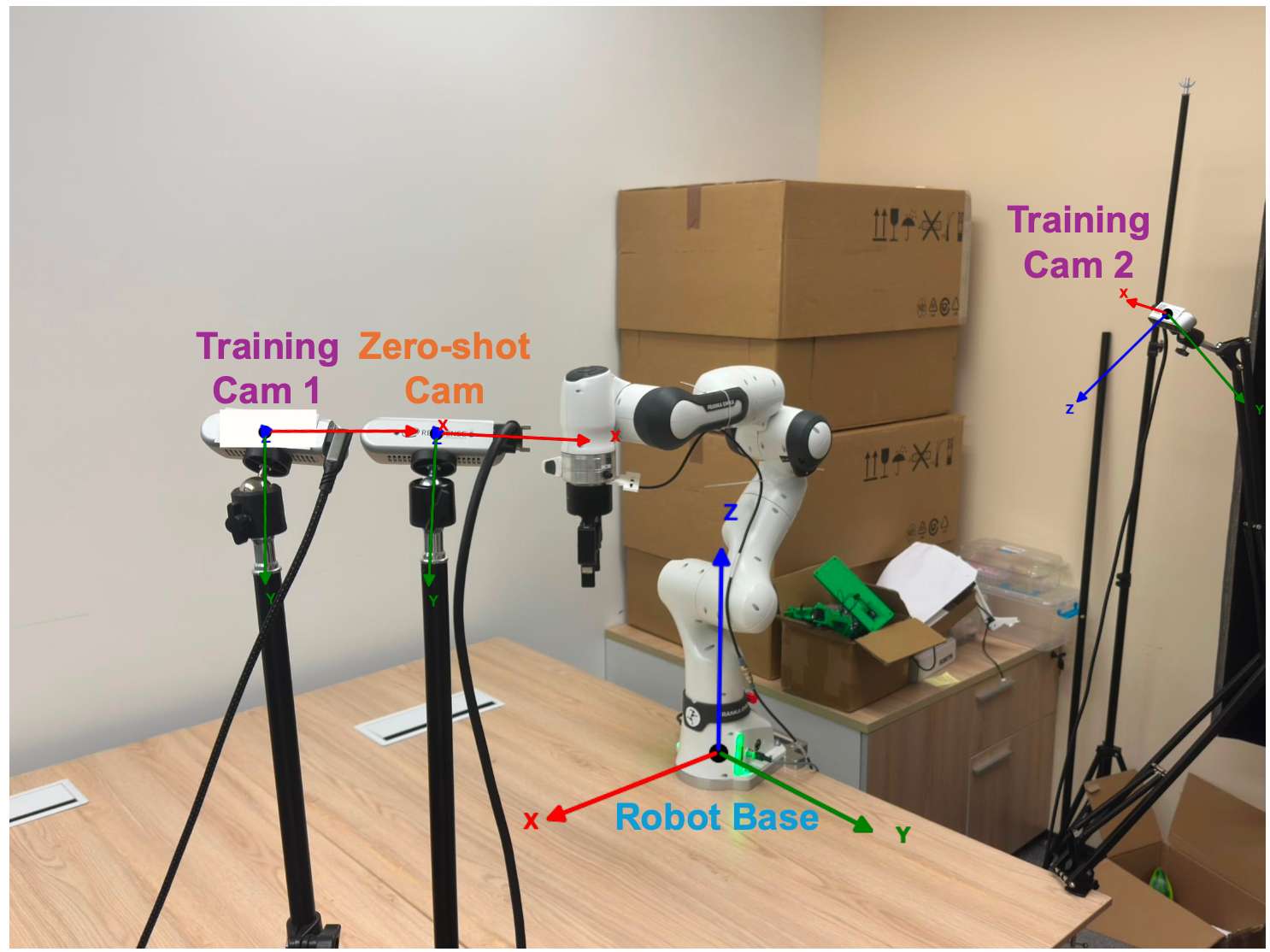
分别使用训练相机1和训练相机2从不同视角采集两组数据集。对于使用相机 1采集的数据集,我们记录了15个不同任务的轨迹,并在整个数据采集过程中保持相机位置固定。相比之下,使用相机2采集的数据集包含8个任务的轨迹,在采集过程中,我们对相机位置进行轻微扰动,以模拟视角的细微变化。收集的任务涵盖多种类别,包括抓取与放置、倾倒、堆叠、抓取与旋转、拉动与推动以及其他长时程任务,旨在全面评估模型的真实性能。参照 Dita,对于两个数据集中的每个任务,我们收集了10条演示轨迹,旨在评估模型小样本条件下的能力。

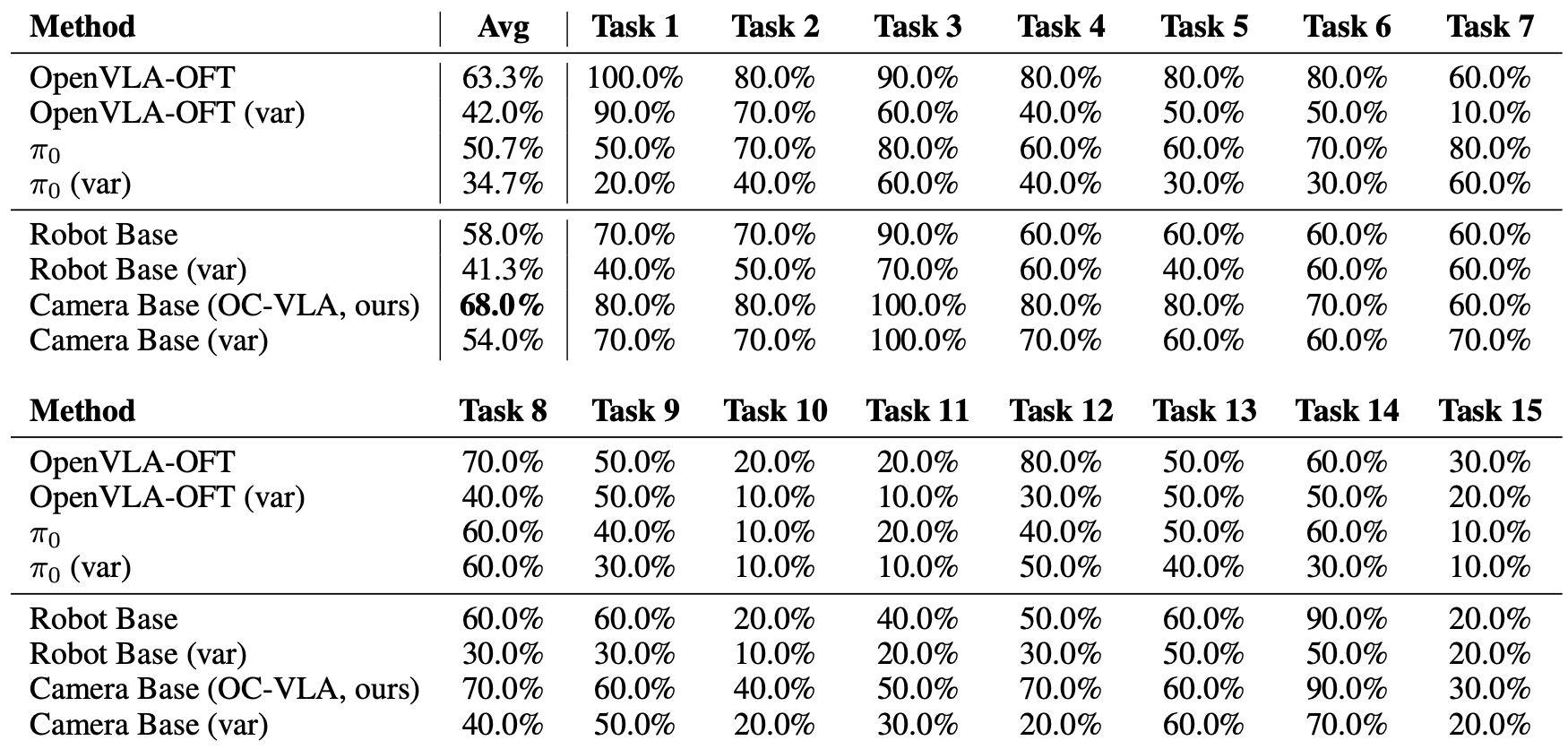
这里分别在固定相机位置,相机位置扰动以及零样本相机位置等设置下对OC-VLA的效果进行了测试,实验结果显示,OC-VLA不仅可以提升任务成功率,同样显著增强了模型在零样本视角下的表现能力。OC-VLA 展示了一种通用、轻量、可迁移的策略学习范式,为构建真正具有现实部署能力的多模态机器人系统提供了有效的解决路径。

人类数据

OC-VLA 不仅适用于机器人自主采集的数据,同样可以自然扩展到基于人类演示的数据训练范式中。通过在相机坐标系下引入关键点检测技术,即可直接提取人类腕部的运动轨迹,并与机械臂末端执行器的动作空间对齐。 实验结果表明,在 OC-VLA 的训练框架下,额外引入人类演示数据能够进一步增强模型在多相机视角条件下的泛化能力,使模型在视角变化和观测不一致场景中表现得更加稳健。
写在最后&总结
我们提出了一种以观察为中心的VLA模型Observation-Centric VLA(OC-VLA)。这是一个简单而有效的框架,它将动作预测基于相机坐标系,从而解决了现有视觉语言动作模型中感知与动作之间的空间错位问题。OC-VLA 不会增加额外的架构开销,并且可以与现有流程无缝集成。大量的实验表明,OC-VLA 显著提高了跨视角泛化能力,并增强了在视角变化下的鲁棒性,展现了 OC-VLA 的实用价值及其在通用机器人策略方面的巨大潜力。
具身求职内推来啦
国内最大的具身智能全栈学习社区来啦!
推荐阅读
从零部署π0,π0.5!好用,高性价比!面向具身科研领域打造的轻量级机械臂
工业级真机教程+VLA算法实战(pi0/pi0.5/GR00T/世界模型等)
具身智能算法与落地平台来啦!国内首个面向科研及工业的全栈具身智能机械臂
VLA/VLA+触觉/VLA+RL/具身世界模型等!具身大脑+小脑算法与实战全栈路线来啦~
MuJoCo具身智能实战:从零基础到强化学习与Sim2Real
Diffusion Policy在具身智能领域是怎么应用的?为什么如此重要?