快速了解部分
基础信息(英文):
- 题目: See Once, Then Act: Vision-Language-Action Model with Task Learning from One-Shot Video Demonstrations
- 时间: 2025.12
- 机构: Beijing Institute of Technology, LimX Dynamics
- 3个英文关键词: One-Shot Visual Imitation Learning, Vision Language Action Models, Cross-embodiment Transfer
1句话通俗总结本文干了什么事情
本文提出了一种名为ViVLA的机器人策略模型,能让机器人通过看一次人类或其他机器人的示范视频,就能学会从未见过的新操作任务,无需额外训练。
研究痛点:现有研究不足 / 要解决的具体问题
现有视觉语言动作(VLA)模型虽然强大,但无法泛化到训练数据中未见过的任务;且人类能通过简单模仿学会新技能,而现有机器人模型缺乏从单次视频示范中提取细粒度操作知识并迁移到自身(尤其是跨形态/不同机器人)的能力。
核心方法:关键技术、模型或研究设计(简要)
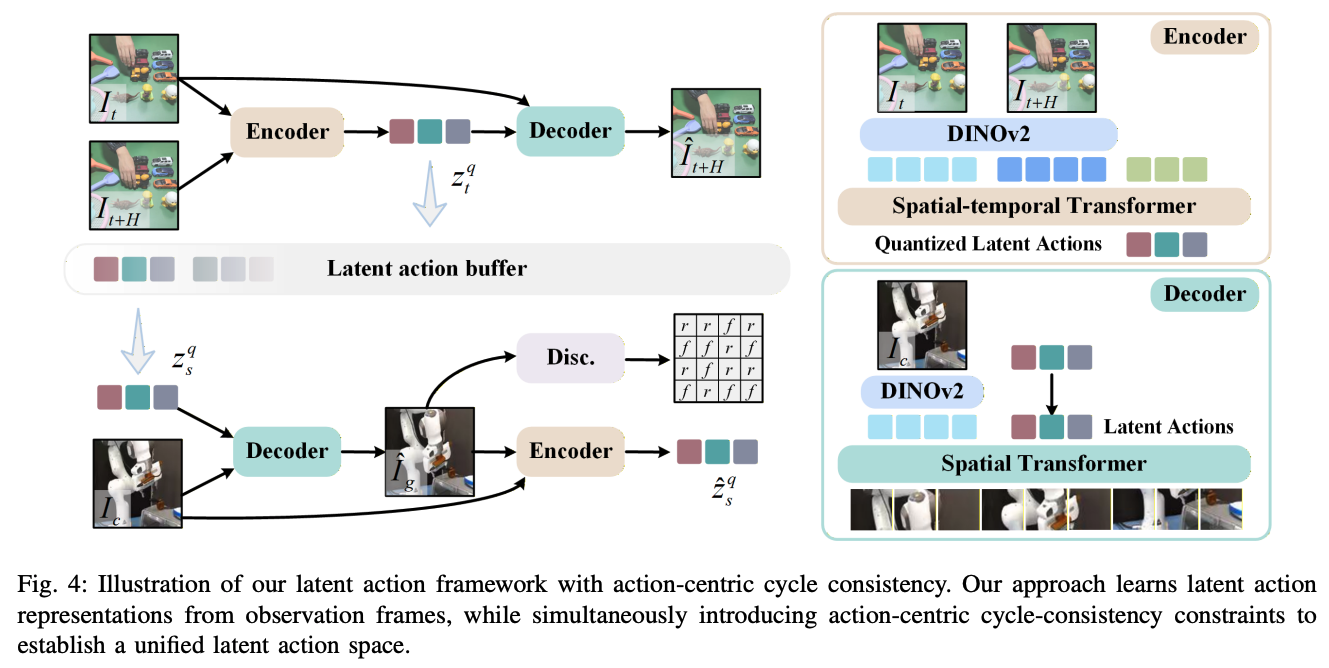
提出ViVLA模型,包含两个核心部分:一是建立统一的潜在动作空间(通过循环一致性),消除人类/不同机器人动作差异;二是开发了视频驱动的数据生成管线,将人类视频转化为机器人训练数据,并利用并行解码技术让模型通过单次示范学习动作。
深入了解部分
作者想要表达什么
作者旨在证明,通过结合视觉基础模型和特定的潜在动作学习框架,可以打破机器人训练中的数据壁垒。机器人不仅能在没有特定任务数据的情况下,通过观看单次视频学会新技能,还能跨越形态差异(如从人类视频学给机械臂用),实现通用的技能迁移。
相比前人创新在哪里
- 统一潜在动作空间:不同于前人分别处理不同机器人的数据,本文提出了基于循环一致性的潜在动作学习(A3C),强制不同形态(人类/机器人)的动作在潜空间中对齐。
- 并行解码策略:改变了以往自回归(逐个预测动作)的方式,采用并行解码预测所有动作,防止模型依赖"偷看"前序动作而忽略视频理解,同时提高了推理速度。
- 大规模数据生成管线:利用3D高斯泼溅(Gaussian Splatting)技术,将人类视频重写为机器人执行的4D场景,自动生成了89万+条专家-代理配对数据。
解决方法/算法的通俗解释
想象你要教一个哑巴机器人做动作,但它看不懂人类语言。
- 建立通用"手势语":你先发明一套通用的"手势密码本"(潜在动作空间),无论人手还是机械臂,做同一个动作对应的"密码"是一样的。
- 看视频猜密码:让机器人看一段视频,不是直接模仿肢体,而是让它猜视频里每一个动作对应的"密码"是什么。
- 反向验证:为了确保猜得准,你让机器人根据猜到的密码,尝试做出动作。如果做出来的动作和视频里一样,说明密码本是对的(循环一致性)。
- 一次学会:通过这种训练,机器人以后只要看一次新视频,破译出密码,就能直接用自己身体做出对应动作。
解决方法的具体做法
- 数据准备:收集人类操作视频,利用视觉模型提取手部和物体姿态,用3D高斯泼溅渲染成机器人操作的4D场景,生成"人类视频-机器人动作"的配对数据。
- 潜在动作编码器(LAT)训练 :
- 输入连续的图像帧。
- 利用"循环一致性"约束:从缓冲区抽取潜在动作应用到当前帧生成下一帧,再训练编码器从生成的帧中还原出原始的潜在动作。
- 引入判别器保证生成图像的真实性。
- ViVLA模型训练 :
- 基于Qwen2.5-VL模型架构。
- 输入:专家示范视频(经过时空掩码处理)+ 当前机器人观察 + 语言指令。
- 输出:预测视频中的潜在动作序列 + 机器人下一步的动作。
- 采用并行解码,一次性预测所有动作Token。
基于前人的哪些方法
- 视觉基础模型:基于Qwen2.5-VL和DINOv2,利用其强大的视觉理解和语义知识。
- 潜在动作表示:借鉴了VQ-VAE(向量量化)的思想来构建离散的动作码本。
- 3D重建技术:利用3D Gaussian Splatting(高斯泼溅)进行场景重建和新视角合成。
- One-Shot Learning理念:借鉴了人类通过单次观察模仿学习的能力。
实验设置、数据、评估方式、结论
- 数据:构建了Human2Robot数据集(8.9万条)及整合公开数据集,共89.2万条专家-代理配对轨迹。
- 设置:在LIBERO基准测试(包含130个操作任务)和真实世界环境中评估。将任务分为"见过"和"未见过"两类,测试泛化能力。
- 评估方式:任务成功率(Success Rate)。
- 结论 :
- 在未见过的任务上,相比OpenVLA等SOTA模型,成功率提升超过30%。
- 在跨形态(不同机器人)视频示范下,提升超过35%。
- 在真实世界人类视频示范下,未见过任务的成功率提升超过38%。
提到的同类工作
- OpenVLA:开源的视觉语言动作模型,在大规模数据集上训练,但在未见任务上泛化能力有限。
- UniVLA:尝试从跨形态视频中学习任务中心的潜在动作,但未解决细粒度动作对齐问题。
- AWDA:通过预测属性路点实现单次模仿,但依赖手工设计的运动基元。
- Genie:一种生成交互环境模型,用于潜在动作学习,但缺乏循环一致性约束导致语义不一致。
和本文相关性最高的3个文献
- Qwen2.5-VL 5:本文模型架构的基础,提供了视觉和语言理解的核心能力。
- LIBERO Benchmark 89:本文进行核心性能对比和评估所使用的基准测试套件。
- DINOv2 68:本文在潜在动作编码器中用于提取图像嵌入的核心视觉模型。
我的
- 一个A3C值得借鉴。能自监督学习action空间