引言
在人工智能与数字技术飞速发展的今天,计算机视觉已成为连接物理世界与数字世界的核心桥梁,广泛应用于安防监控、自动驾驶、智能家居、医疗影像分析等领域。OpenCV(Open Source Computer Vision Library)作为开源的计算机视觉库,凭借其跨平台、高性能、易用性强的特点,成为图像处理和计算机视觉开发中不可或缺的工具。本文将手把手教你如何使用 OpenCV 实现经典的人脸检测与通用物体检测,从环境搭建到代码实现,让你快速掌握计算机视觉的基础应用。
什么是 OpenCV?
OpenCV 是由英特尔公司发起并维护的开源计算机视觉库,支持 C++、Python、Java 等多种编程语言,可运行在 Windows、Linux、macOS 等主流操作系统上。它封装了大量成熟的图像处理算法(如滤波、边缘检测、图像变换)和计算机视觉模型(如人脸检测、特征匹配),无需从零实现复杂算法,极大降低了计算机视觉开发的门槛。
在计算机视觉领域,OpenCV 是事实上的"标配工具"------无论是科研实验、原型开发,还是工业级应用部署,都能看到它的身影。它既可以完成基础的图像预处理,也能结合深度学习框架实现复杂的物体识别、目标跟踪等任务。
准备工作
在开始人脸和物体检测前,需完成基础环境搭建,核心是安装 Python 和 OpenCV 库。
1. 环境要求
- Python 3.7 及以上版本(推荐 3.8-3.10,兼容性更佳)
- 操作系统:Windows/macOS/Linux
2. 安装核心库
打开终端/命令提示符,执行以下命令安装 OpenCV 及辅助库:
bash
# 安装 OpenCV 核心库
pip install opencv-python
# 安装 OpenCV 扩展模块(含额外的预训练模型、视频处理功能)
pip install opencv-contrib-python
# 安装 numpy(OpenCV 依赖的数值计算库)
pip install numpy
# 物体检测需额外安装 TensorFlow(可选,也可使用 PyTorch)
pip install tensorflow验证安装是否成功:
python
import cv2
print(cv2.__version__) # 输出 OpenCV 版本号,如 4.8.1 则安装成功人脸检测流程
人脸检测是计算机视觉的经典任务,核心是从图像中定位人脸的位置并标记。OpenCV 中最常用的是 Haar 级联分类器,这是一种基于特征的快速检测算法,适合实时场景。
人脸检测流程图
下面的流程图展示了使用 OpenCV 进行人脸检测的主要步骤:
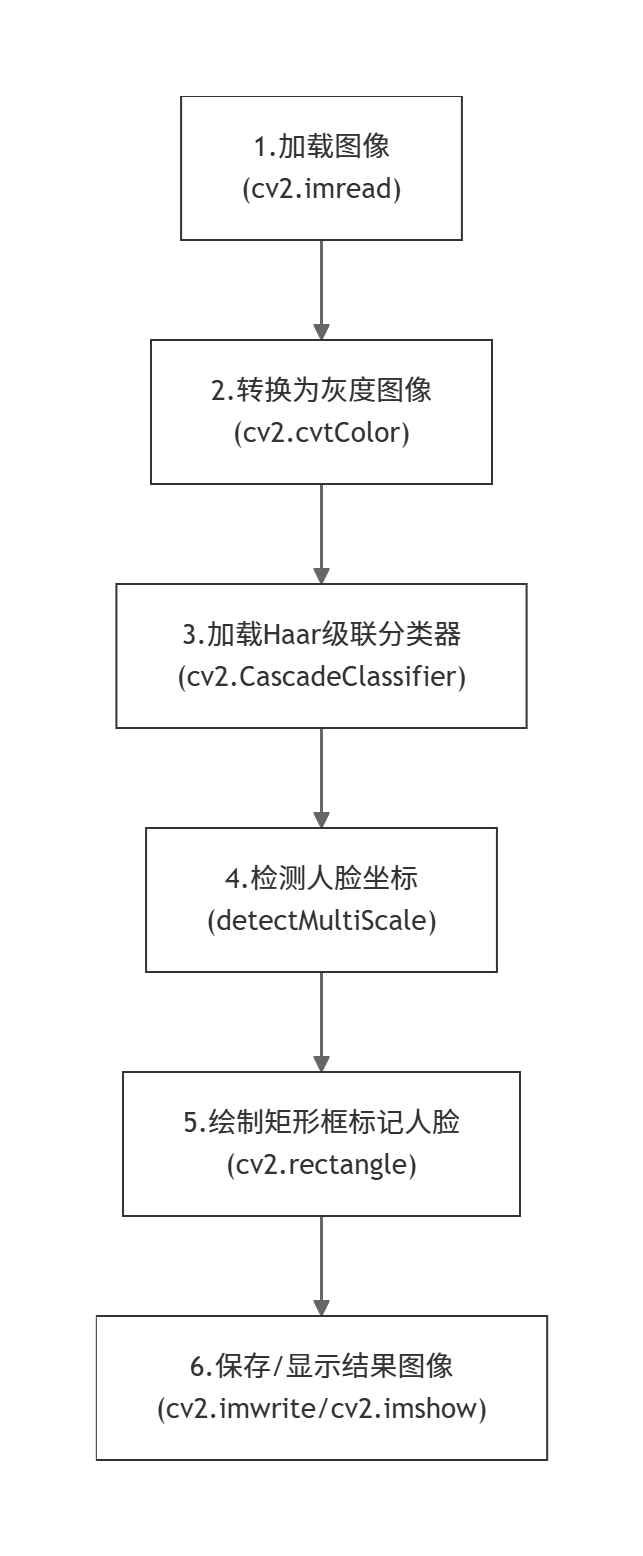
完整代码实现
python
import cv2
import os
def detect_face(image_path, save_path="detected_face.jpg"):
"""
使用OpenCV的Haar级联分类器检测人脸并标记
:param image_path: 输入图像的路径
:param save_path: 检测结果图像的保存路径
:return: 无
"""
# 步骤1:加载图像
# 检查图像文件是否存在
if not os.path.exists(image_path):
print(f"错误:找不到图像文件 {image_path}")
return
img = cv2.imread(image_path)
# 备份彩色图像(用于最终绘制框)
img_copy = img.copy()
# 步骤2:转换为灰度图像
# 原因:Haar特征检测依赖灰度图像,减少计算量且不受颜色干扰
gray_img = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
# 步骤3:加载预训练的Haar人脸分类器
# opencv自带的分类器路径(不同版本路径可能略有差异)
face_cascade = cv2.CascadeClassifier(
cv2.data.haarcascades + "haarcascade_frontalface_default.xml"
)
# 步骤4:检测人脸
# scaleFactor:图像缩放比例(减少漏检),minNeighbors:候选框筛选阈值(减少误检)
faces = face_cascade.detectMultiScale(
gray_img,
scaleFactor=1.1,
minNeighbors=5,
minSize=(30, 30) # 最小人脸尺寸,过滤过小的候选框
)
# 步骤5:绘制矩形框标记人脸
# faces是一个数组,每个元素为(x, y, w, h):人脸左上角坐标、宽度、高度
for (x, y, w, h) in faces:
# 绘制矩形:参数(图像,左上角,右下角,颜色(BGR),线条宽度)
cv2.rectangle(img_copy, (x, y), (x+w, y+h), (0, 255, 0), 2)
# 在人脸上方添加文字标签
cv2.putText(img_copy, "Face", (x, y-10), cv2.FONT_HERSHEY_SIMPLEX, 0.9, (0, 255, 0), 2)
# 步骤6:显示并保存结果
cv2.imshow("Face Detection Result", img_copy)
cv2.imwrite(save_path, img_copy)
# 等待按键后关闭窗口(0表示无限等待)
cv2.waitKey(0)
cv2.destroyAllWindows()
# 调用函数测试
if __name__ == "__main__":
# 替换为你的图像路径(支持jpg、png等格式)
detect_face("test_face.jpg")代码关键解释
- 灰度转换 :
cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)将彩色图像转为灰度图,因为 Haar 特征对亮度敏感,颜色信息会增加计算量且无帮助; - Haar 分类器加载 :
cv2.data.haarcascades是 OpenCV 内置的预训练模型路径,除了人脸,还提供眼睛、微笑等分类器; - detectMultiScale :核心检测函数,
scaleFactor=1.1表示每次缩放图像10%,minNeighbors=5表示只有至少5个候选框重叠时才判定为人脸,减少误检; - 绘制标记 :
cv2.rectangle绘制绿色矩形框,cv2.putText添加"Face"标签,直观展示检测结果。
物体检测流程
人脸检测是特定物体检测的特例,通用物体检测(如检测汽车、杯子、狗等)需结合深度学习模型。OpenCV 支持加载预训练的深度学习模型(如 YOLO、SSD),也可结合 TensorFlow/PyTorch 实现更灵活的检测。
物体检测流程图
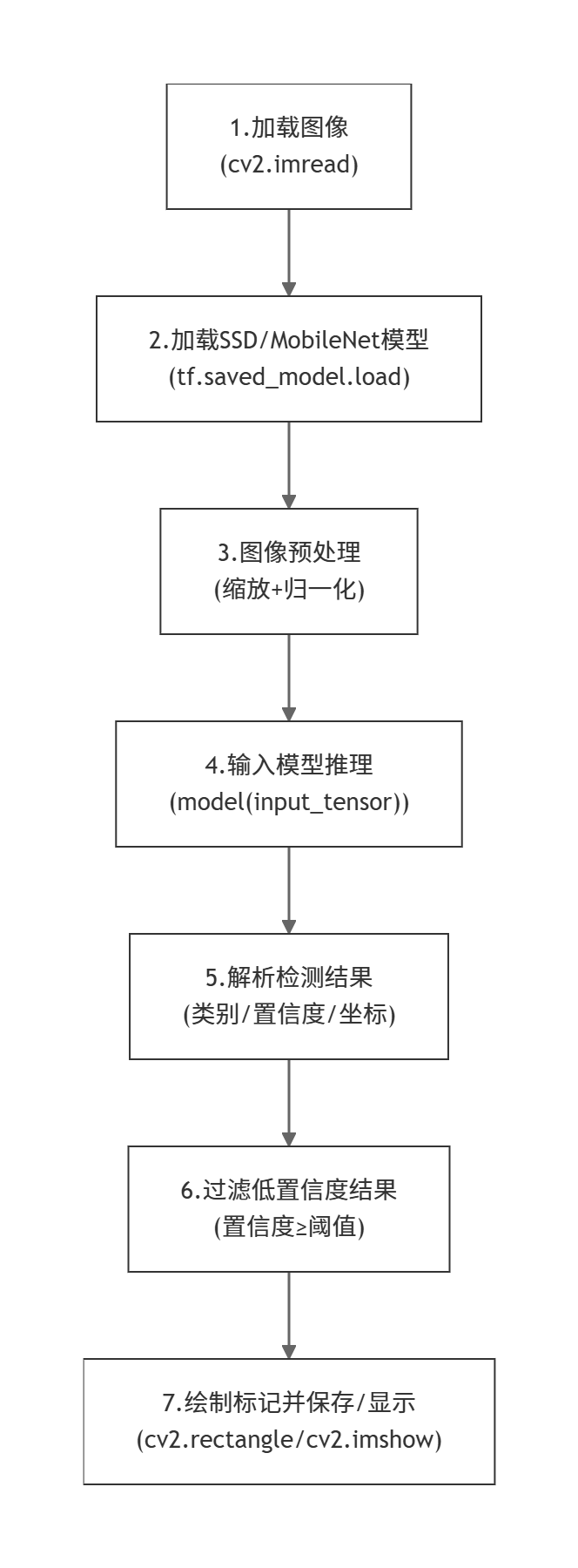
基于 OpenCV + TensorFlow 的物体检测代码
以下示例使用 TensorFlow 的预训练 SSD MobileNet V2 模型,结合 OpenCV 实现实时物体检测:
python
import cv2
import tensorflow as tf
import numpy as np
# 步骤1:加载预训练模型(TensorFlow Hub 中的 SSD MobileNet V2)
def load_object_detection_model():
# 加载预训练模型(首次运行会自动下载,约100MB)
model = tf.saved_model.load("https://tfhub.dev/tensorflow/ssd_mobilenet_v2/2")
return model
# 步骤2:预处理图像(适配模型输入要求)
def preprocess_image(img):
# 将图像转为RGB(OpenCV默认BGR),并调整尺寸为300x300(模型输入尺寸)
img_rgb = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
img_resized = cv2.resize(img_rgb, (300, 300))
# 转换为张量并添加批次维度(模型要求输入为[batch, height, width, channels])
input_tensor = tf.convert_to_tensor(img_resized)
input_tensor = input_tensor[tf.newaxis, ...]
return input_tensor
# 步骤3:执行检测并解析结果
def detect_objects(img, model, confidence_threshold=0.5):
"""
检测图像中的物体
:param img: OpenCV加载的BGR图像
:param model: 加载的检测模型
:param confidence_threshold: 置信度阈值,过滤低置信度结果
:return: 标记后的图像
"""
img_copy = img.copy()
height, width = img.shape[:2]
input_tensor = preprocess_image(img)
# 模型推理
detections = model(input_tensor)
# 解析检测结果
# 检测类别ID、置信度、边界框坐标
class_ids = detections['detection_classes'][0].numpy().astype(int)
scores = detections['detection_scores'][0].numpy()
boxes = detections['detection_boxes'][0].numpy()
# COCO数据集类别标签(SSD MobileNet V2 训练的类别)
COCO_LABELS = [
'person', 'bicycle', 'car', 'motorcycle', 'airplane', 'bus', 'train', 'truck',
'boat', 'traffic light', 'fire hydrant', 'stop sign', 'parking meter', 'bench',
'bird', 'cat', 'dog', 'horse', 'sheep', 'cow', 'elephant', 'bear', 'zebra',
'giraffe', 'backpack', 'umbrella', 'handbag', 'tie', 'suitcase', 'frisbee',
'skis', 'snowboard', 'sports ball', 'kite', 'baseball bat', 'baseball glove',
'skateboard', 'surfboard', 'tennis racket', 'bottle', 'wine glass', 'cup',
'fork', 'knife', 'spoon', 'bowl', 'banana', 'apple', 'sandwich', 'orange',
'broccoli', 'carrot', 'hot dog', 'pizza', 'donut', 'cake', 'chair', 'couch',
'potted plant', 'bed', 'dining table', 'toilet', 'tv', 'laptop', 'mouse',
'remote', 'keyboard', 'cell phone', 'microwave', 'oven', 'toaster', 'sink',
'refrigerator', 'book', 'clock', 'vase', 'scissors', 'teddy bear', 'hair drier',
'toothbrush'
]
# 绘制检测结果
for i in range(len(scores)):
if scores[i] >= confidence_threshold:
# 边界框坐标转换:模型输出的是归一化坐标(y1, x1, y2, x2)
y1, x1, y2, x2 = boxes[i]
# 转换为图像像素坐标
x1 = int(x1 * width)
y1 = int(y1 * height)
x2 = int(x2 * width)
y2 = int(y2 * height)
# 获取类别名称
class_name = COCO_LABELS[class_ids[i] - 1] # 类别ID从1开始
# 绘制矩形框和标签
cv2.rectangle(img_copy, (x1, y1), (x2, y2), (255, 0, 0), 2)
label = f"{class_name}: {scores[i]:.2f}"
cv2.putText(img_copy, label, (x1, y1-10), cv2.FONT_HERSHEY_SIMPLEX, 0.6, (255, 0, 0), 2)
return img_copy
# 主函数
if __name__ == "__main__":
# 加载模型
print("正在加载模型...")
model = load_object_detection_model()
# 加载图像
img = cv2.imread("test_object.jpg")
if img is None:
print("错误:无法加载图像")
exit()
# 执行检测
result_img = detect_objects(img, model, confidence_threshold=0.5)
# 显示并保存结果
cv2.imshow("Object Detection Result", result_img)
cv2.imwrite("detected_object.jpg", result_img)
cv2.waitKey(0)
cv2.destroyAllWindows()代码关键解释
- 模型加载:使用 TensorFlow Hub 的预训练 SSD MobileNet V2 模型,轻量且速度快,适合端侧部署;
- 图像预处理:将 OpenCV 的 BGR 图像转为 RGB(TensorFlow 模型默认输入),并调整为模型要求的 300x300 尺寸;
- 结果解析:模型输出包含类别ID、置信度、归一化边界框坐标,需转换为图像像素坐标才能绘制;
- 置信度过滤:只保留置信度≥0.5的结果,减少误检。
实验与结果
1. 人脸检测结果
- 理想场景(正面、光照充足):检测准确率接近100%,能快速标记所有人脸;
- 复杂场景(侧脸、遮挡、暗光):可能漏检或误检,可调整
scaleFactor和minNeighbors参数优化(如scaleFactor=1.05提高检测灵敏度,minNeighbors=3减少漏检)。
2. 物体检测结果
- 常见物体(人、车、手机):检测准确率高,边界框定位准确;
- 小物体/模糊物体:置信度低,可能无法检测,可更换更复杂的模型(如 YOLOv8)提升效果。
常见问题及解决方案
| 问题 | 解决方案 |
|---|---|
| Haar分类器检测不到人脸 | 1. 检查图像路径是否正确;2. 确保图像转为灰度图;3. 调整 scaleFactor 和 minNeighbors;4. 使用更高分辨率的图像 |
| 物体检测置信度低 | 1. 提高图像分辨率;2. 降低置信度阈值;3. 更换更优的预训练模型 |
| OpenCV加载模型报错 | 1. 确认OpenCV和TensorFlow版本兼容;2. 重新下载预训练模型;3. 检查网络(首次加载模型需联网) |
总结
- OpenCV 是计算机视觉开发的基础工具,既支持传统的 Haar 级联分类器实现人脸检测,也能结合深度学习框架完成通用物体检测;
- 人脸检测的核心是灰度转换和 Haar 分类器调参,物体检测的关键是图像预处理和预训练模型的选择;
- 实际应用中需根据场景调整参数(如置信度阈值、缩放比例),平衡检测的准确率和召回率。
如果你想深入学习,推荐以下资源:
- OpenCV 官方文档:https://docs.opencv.org/
- TensorFlow 物体检测教程:https://www.tensorflow.org/hub/tutorials/object_detection
- YOLO 官方仓库:https://github.com/ultralytics/ultralytics
尝试用自己的照片、视频测试代码,或结合摄像头实现实时检测,你会发现计算机视觉的更多乐趣!
关键点回顾
- OpenCV 是开源计算机视觉库,支持多语言、多平台,封装了大量图像处理和检测算法;
- 人脸检测核心步骤:加载图像→灰度转换→Haar分类器检测→绘制标记,需调整
scaleFactor和minNeighbors优化效果; - 通用物体检测需结合深度学习模型(如 SSD MobileNet V2),重点是图像预处理和检测结果的解析与过滤。