DSFuse:一种用于特征保真度的红外与可见光图像融合的双扩散结构
DSFuse: A Dual-Diffusion Structure for Feature Fidelity Infrared and Visible Image Fusion
作者: Zhijia Yang , Kun Gao , Yanzheng Zhang , Xiaodian Zhang, Zibo Hu , Junwei Wang , Jingyi Wang , and Wei Li
发表期刊: IEEE TRANSACTIONS ON NEURAL NETWORKS AND LEARNING SYSTEMS
论文地址: https://ieeexplore.ieee.org/document/11074762/
摘要---图像融合旨在结合不同模态的互补特征,以生成信息更丰富的融合图像。由于成像机制的不同,红外与可见光源图像之间可能会产生信息冲突。现有的红外与可见光融合方法致力于尽可能保留源图像的特征,然而对冲突信息的处理往往被忽视。因此,我们利用扩散模型强大的生成先验,提出了一种双扩散结构,称为 DSFuse,用于在图像融合过程中处理冲突信息并实现特征保真。引入扩散模块以引导融合网络更容易理解源图像中的有意义信息。首先,使用融合网络尽可能在融合图像中保留特征。然后,基于融合网络的输出,扩散模块从噪声中重建源图像。最后,来自扩散模块的反馈促使融合网络聚合模态信息以确保保真性;同时,高质量的融合结果也有助于扩散模块获得更好的重建效果,从而形成一个正反馈循环。此外,我们发布了一个新的用于红外/可见光融合的数据集,以支持融合网络的训练与评估,命名为多场景红外与可见光(MSIV)图像数据集。大量实验表明,DSFuse 优于其他最先进(SOTA)的融合方法。
关键词---扩散模块,特征保真,生成模型,图像融合,红外与可见光图像。
I. 引言
图像融合将来自不同传感器获取的多模态图像中的互补特征进行整合 1。由图像融合方法生成的融合结果包含大量细节,适用于全天候目标检测和显著目标分割等高层视觉任务 2。红外与可见光图像融合是一项经典的融合任务。红外图像在复杂场景中能够突出热目标区域,但存在分辨率低、纹理信息不足的问题;而可见光图像具有较高的图像质量,在良好的天气和光照条件下更符合人类视觉感知 3,4,5。红外与可见光图像的融合整合了二者的优势,并为高层视觉应用提供信息丰富的融合图像 6,7。

近年来,利用深度学习优势的大量融合方法相继提出。尽管现有融合方法能够生成较为理想的融合图像,但仍存在一些值得关注的问题。首先,大多数现有方法侧重于保留源图像中的显著特征 8。然而,对融合方法的指导主要基于源图像的梯度和像素强度,这些并不能充分描述源图像中的所有重要信息。如图 1 所示的夜间场景中,现有方法(如 TGFuse 9 和 Dif-Fusion 10)在低照度条件下无法有效保留树木的全部细节(蓝色框),同时在突出热目标方面(红色框)表现也不够理想。此外,红外与可见光图像的融合不可避免地会导致一定程度的信息损失。如何在去除冗余信息的同时保留关键信息,是图像融合任务中亟需解决的问题。

最后,可见光与红外图像中还存在冲突信息。当同一目标在红外图像和可见光图像中的特征呈现出强烈对比或差异时,我们将其称为冲突信息。如图 1 所示的白天场景中,黑色汽车比白色汽车更容易吸收热量,因此在红外图像中黑色汽车往往具有比白色汽车更高的像素强度,而在可见光图像中情况正好相反。类似地,平坦道路在热成像图像中也具有复杂的热分布。可以看出,现有方法在融合这类冲突信息时表现较差。与此同时,如图 2 所示,当前红外与可见光图像融合的数据集包含的红外目标种类有限,场景和视角相对单一,主要为夜间或白天低温条件下的街景正视图。然而,真实世界的场景要比数据集中的情况复杂得多。例如,在几乎所有数据集中,行人的温度显著高于背景,使其在红外图像中更加突出;而在实际场景中,如温暖的白天,路面的温度可能高于行人,从而使行人在这些条件下并不显著。模型训练过程中缺乏多场景数据可能会引入偏置。
为了解决上述问题,我们提出了一种基于双扩散模块的特征保真红外与可见光图像融合方法,称为 DSFuse。该方法采用基于 Swin Transformer 的残差连接 Transformer 融合网络(RTFusionNet),用于建模不同模态之间的全局依赖关系。为了为 RTFusionNet 提供更好的指导,我们引入双扩散模块,根据 RTFusionNet 的输出结果从纯噪声中重建源图像。RTFusionNet 生成信息丰富的融合图像以引导扩散模块的重建过程;同时,扩散模块生成的重建结果质量会反向反馈,引导 RTFusionNet 实现更好的图像融合并达到特征保真,尤其是在处理冲突信息时。如图 1(e) 所示,我们的融合图像包含了来自不同模态的更多互补信息。此外,我们构建了一种专门的损失函数用于训练 DSFuse,以保留模态特征并满足人类视觉感知。最后,我们发布了一个包含多场景和多种视角热目标的 MSIV 数据集,使模型在训练过程中能够接触更多接近真实场景的图像,从而消除模型偏置并提升泛化能力。
本文的主要贡献总结如下:
1)提出了一种基于双扩散模块和 Transformer 的红外与可见光图像融合方法 DSFuse,能够生成具有特征保真度且视觉效果良好的融合图像。
2)提出了一种用于融合网络指导的双扩散结构,该结构在 DSFuse 的训练过程中相互促进,使其能够保留关键信息并有效处理冲突信息。
3)构建了一种专门的损失函数,并对 DSFuse 的双扩散过程进行了形式化描述,以确保特征保真并满足人类观察需求。
4)构建了一个新的用于融合网络训练和评估的数据集,称为多场景红外与可见光(MSIV)图像数据集。该数据集包含多种场景和多类红外目标,数据集地址为:https://github.com/Yzhijia/Multi-ScenaryInfrared-and-Visible-images-dataset
本文结构安排如下:第二节讨论图像融合和扩散模块的相关工作;第三节详细介绍 DSFuse,包括研究动机、整体结构以及损失函数;第四节描述用于评估 DSFuse 及其他方法的实验细节;第五节对全文进行总结。
II. 相关工作
A. 基于深度学习的图像融合模型
近年来,许多与融合任务相关的研究通过引入独特的网络结构并采用特定的损失函数取得了显著成果。主流的基于深度学习的融合方法通常分为四类 11,12:
1)基于卷积神经网络(CNN)的方法 13,14,15;
2)基于自编码器(AE)的方法 16,17,18;
3)基于生成对抗网络(GAN)的方法 19,20,21;
4)基于 Transformer 的方法 9,22,23。
基于 AE 的方法采用编码器--解码器结构来实现源图像的特征提取以及融合图像的重建 24。Li 和 Wu 17 利用致密块作为 AE 提出了 Densefuse,并采用 L1 范数作为其融合策略。此外,Li 等人 25 在编码器中引入了嵌套连接和多尺度结构,以提升模型的特征表示能力。Yang 等人 16 提出了一种领域特定的 AE 结构,并采用显著性感知损失来保留包含复杂场景的源图像中的重要特征。
基于 CNN 的方法旨在直接合成融合图像。U2Fusion 基于统一框架进行开发 14。PMGI 是一种实时融合网络,侧重于保留源图像的梯度和强度信息 26。SDNet 基于一种挤压与分解网络,用于图像融合与分解 27。近年来,结合目标检测或分割等高级任务的融合网络逐渐出现 28,29。SeAFusion 架起了图像融合与视觉分割任务之间的桥梁 30。IRFS 具有一种交互式结构,使其能够将图像融合与目标检测相结合 31。
基于 GAN 的方法为生成器和判别器提供了一种对抗训练范式,适用于生成包含丰富细节和显著目标的融合图像 21。Ma 等人 19 采用 GAN 结构进行图像融合,在其方法中通过建模对抗博弈,融合结果能够较好地保留可见光图像中的纹理信息 19。随后,D2WGAN 采用双判别器以避免来自不同模态的信息丢失 32。为帮助网络更加关注输入图像中的显著特征,Li 等人 33 在生成器和判别器中引入了多尺度注意力机制。然而,基于 GAN 的方法优化难度较大,且许多方法存在模式崩溃问题。
基于 Transformer 的方法近年来逐渐兴起,其利用 Transformer 强大的全局感受野和长程依赖建模能力。Ma 等人 22 提出了用于融合任务的 Transformer 模块 SwinFusion,通过充分保留局部与全局特征实现信息整合。在 TCCFusion 中,Tang 等人 34 使用 Transformer 进行全局特征提取,以替代卷积操作。Rao 等人 9 采用 Transformer 结构来建模全局融合关系,并提出了结合 Transformer 模块与对抗训练的 TGFuse。
B. 扩散概率模块
扩散模块近年来成为深度学习中的研究热点,具有显著的生成能力 35。在训练过程中,扩散模型通常包括两个阶段:前向扩散和反向去噪。在前向过程中,扩散模块采用马尔可夫链,通过逐步添加噪声来不断扰乱图像,直到所有信息转化为纯高斯噪声。在反向去噪过程中,扩散模型采用相同的迭代方式逐步去除噪声,从而重建原始图像。在推理过程中,图像由随机高斯噪声通过迭代方式逐步生成。
与 GAN 等其他生成模型相比,扩散模块具有诸多优势。GAN 通常难以训练,并且容易出现模式崩溃问题;而扩散模块在训练过程中更加稳定,并且由于其似然特性,能够提供更丰富的生成多样性。扩散模型适用于多种计算机视觉生成任务,如图像合成 36 和超分辨率 37。近年来,一些研究将扩散模块引入图像融合领域。Yue 等人 10 使用去噪网络进行扩散特征提取,生成具有较强颜色保真的可见光与红外融合图像。Zhao 等人 38 将图像融合表述为特定条件下的生成问题,并通过将期望--最大化的推理解集成到扩散模块中,实现了利用跨模态信息生成高质量融合图像 38。
III. 方法
本节将对 DSFuse 进行全面介绍。在 III-A 节中,我们描述研究动机;随后在 III-B 节中,给出 DSFuse 的整体结构,并详细说明其网络结构与损失函数;III-C 节讨论训练流程;最后在 III-D 节中对我们提出的数据集进行详细介绍。
A. 动机
红外与可见光图像融合的主要目的是实现对热目标及其背景的同时观测。然而,同一物体在红外/可见光图像中的表征存在差异,甚至可能相互冲突。在融合过程中,保留更多背景信息可能会降低红外目标的显著性,而过分强调热目标又可能削弱纹理细节的保留。受限于图像动态范围以及人类视觉感知特性,过亮或过暗区域中的细节难以清晰呈现,即使这些细节存在,也难以被人眼辨识。类似地,在图像融合中,也难以在高亮或低对比度的可见光背景中保留红外图像细节,或在高亮红外区域中保留可见光细节。因此,我们将其称为冲突信息。
我们的方法旨在获得一种理想的融合图像,该图像应包含来自红外和可见光图像的所有关键信息,包括冲突信息。然而,在红外与可见光图像融合任务中并不存在真实的参考真值。因此,已有方法通常通过设计越来越复杂的损失函数来生成同时包含红外与可见光特征的融合图像。在损失函数设计中,通常采用像素强度损失、梯度损失以及 SSIM 损失。然而,这些损失函数远不足以描述理想的融合图像。
我们认为,理想的融合图像应包含源图像中的全部关键信息。如果能够从融合图像中重建源图像,则可以合理地认为该融合图像包含了源图像中的所有关键信息(包括冲突信息),从而是一幅理想的融合图像。其过程可表示为以下公式:
If=F(Iir,Ivi)(1) I_f = F(I_{ir}, I_{vi}) \tag{1} If=F(Iir,Ivi)(1)
I^ir=Rir(If)(2) \hat{I}{ir} = R{ir}(I_f) \tag{2} I^ir=Rir(If)(2)
I^vi=Rvi(If)(3) \hat{I}{vi} = R{vi}(I_f) \tag{3} I^vi=Rvi(If)(3)
其中,FFF 表示融合过程,RirR_{ir}Rir 和 RviR_{vi}Rvi 表示重建过程,IfI_fIf 为融合图像,IirI_{ir}Iir 和 IviI_{vi}Ivi 分别为红外图像和可见光图像,I^ir\hat{I}{ir}I^ir 和 I^vi\hat{I}{vi}I^vi 为重建得到的红外与可见光图像。
尽管红外与可见光图像来自不同模态,但二者之间仍存在一定程度的信息冗余。我们认为,通过寻找合适的融合过程 FFF,可以在去除大部分冗余信息的同时保留各模态中的关键信息,从而获得理想的融合图像。在该理想融合图像的基础上,可以进一步找到 Rir/viR_{ir/vi}Rir/vi 并重建原始图像。基于上述理论,我们提出了一种基于双扩散结构的融合方法。融合模块 RTFusionNet 负责生成融合图像,红外/可见光扩散模块从噪声中重建源图像,对应于 Rir/viR_{ir/vi}Rir/vi。在训练过程中,来自扩散模块的反馈迫使融合网络聚合模态信息以保证高保真度;同时,高质量的融合图像也有利于扩散模块获得更好的重建效果。最终,我们可以实现式 (1)--(3),并获得理想的融合图像。根据上述分析,如果能够从融合图像中重建源图像,则可以认为该融合图像包含了源图像中的全部必要信息,即冲突信息得到了有效处理。
B. 网络结构
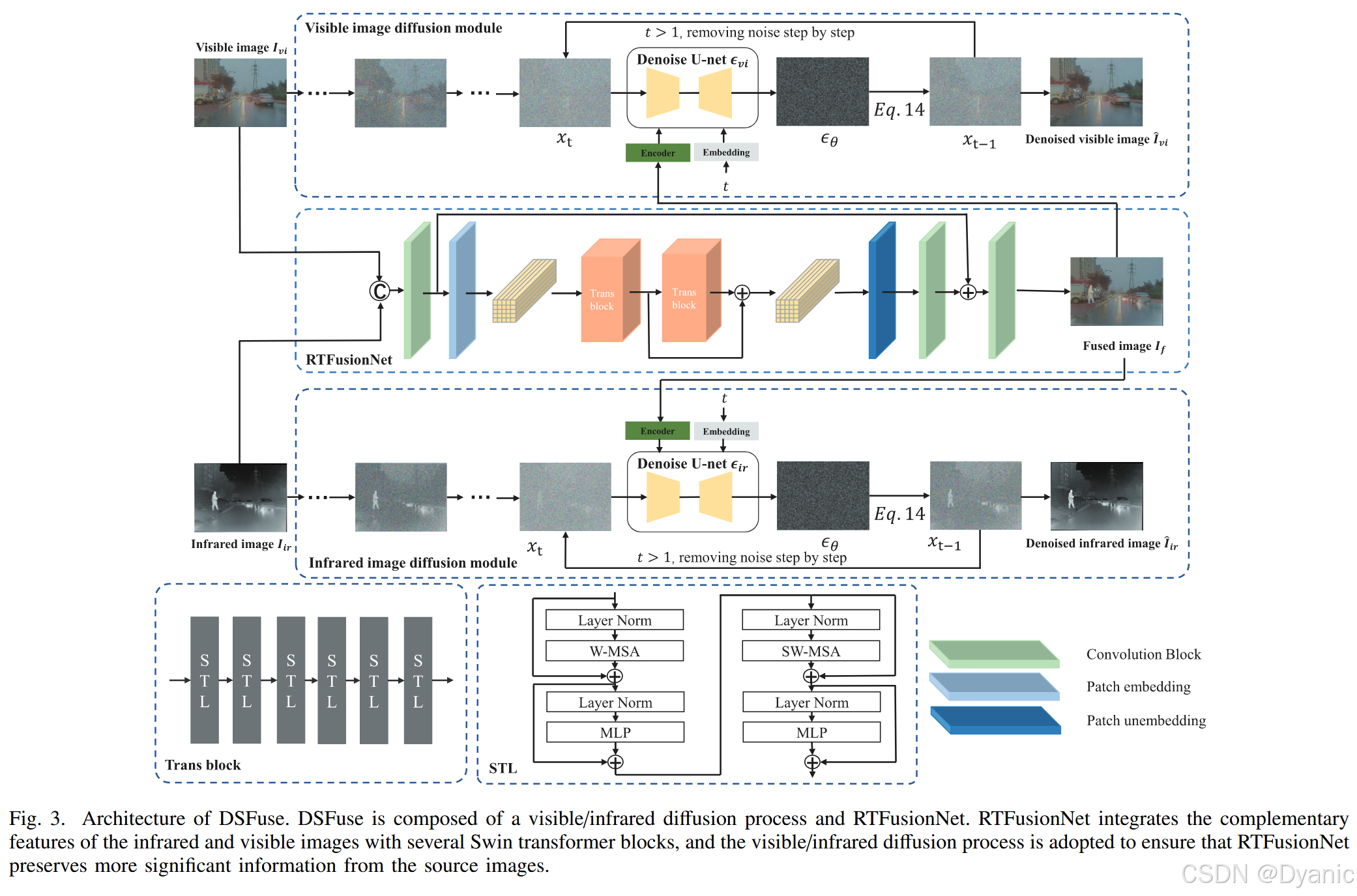
我们采用双扩散框架以确保融合图像包含多模态图像的关键特征。图 3 展示了 DSFuse 的整体结构,
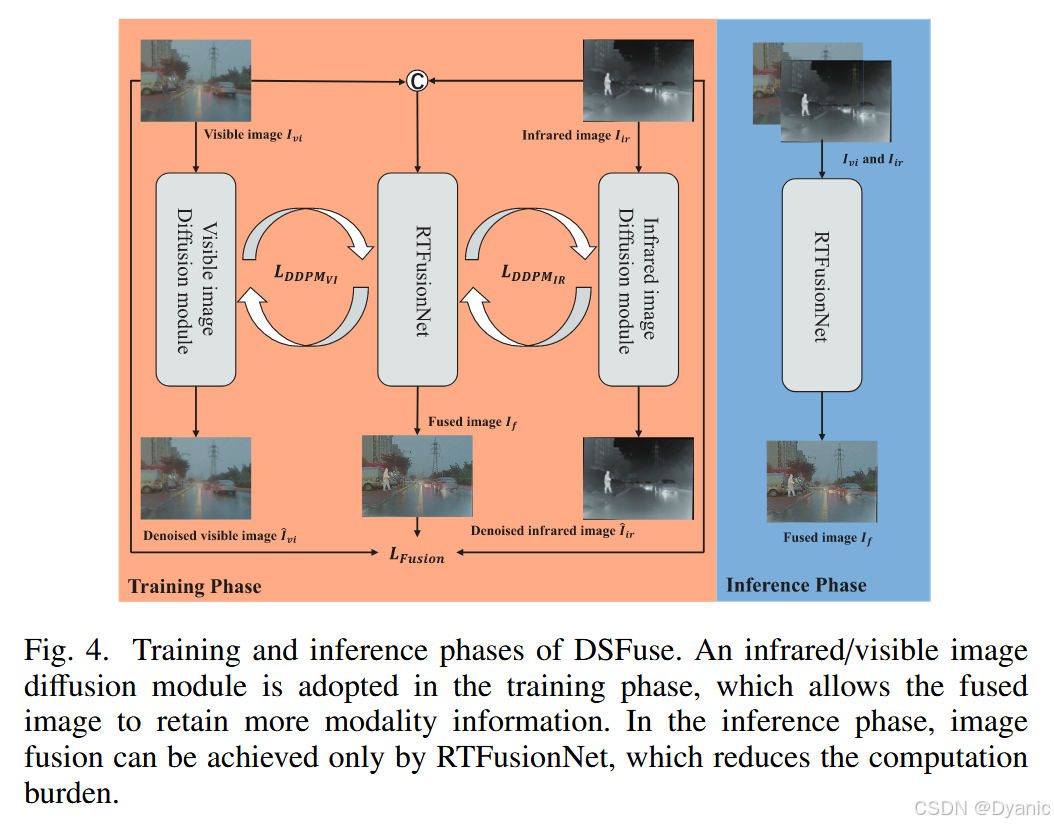
其训练与推理阶段如图 4 所示。DSFuse 由两个 Transformer 模块和若干卷积模块组成。每个卷积模块包含一个卷积层、一个批归一化层以及一个激活函数层。红外与可见光图像表示为 Il∈RH×W×CinI_l \in \mathbb{R}^{H \times W \times C_{in}}Il∈RH×W×Cin,其中 HHH、WWW 和 CinC_{in}Cin 分别表示图像的高度、宽度和通道数,lll 表示输入图像类型,l=irl=irl=ir 表示红外图像,l=visl=visl=vis 表示可见光图像。
首先,将红外或可见光图像输入到一个 3×33 \times 33×3 的卷积模块中以提取浅层特征 ϕI\phi_IϕI。随后,通过 Patch Embedding 层将特征划分为多个 Patch,得到 ϕSF∈RHp×Wp×C\phi_{SF} \in \mathbb{R}^{H_p \times W_p \times C}ϕSF∈RHp×Wp×C,以满足 Transformer 模块的输入需求,其中 Hp=H/pH_p=H/pHp=H/p,Wp=W/pW_p=W/pWp=W/p,ppp 为 Patch 大小。Patch Embedding 表达式如下:
ϕSF=HPE(ϕI)(4) \phi_{SF} = H_{PE}(\phi_I) \tag{4} ϕSF=HPE(ϕI)(4)
其中 HPEH_{PE}HPE 表示 Patch Embedding 层,ϕI\phi_IϕI 为第一层卷积模块提取的特征。在实现中,我们采用核大小和步长均等于 Patch 大小的卷积模块,将图像划分为不重叠的 Patch 作为 Token。
随后,引入 Transformer 模块以提取全局特征 ϕGF∈RHp×Wp×C\phi_{GF} \in \mathbb{R}^{H_p \times W_p \times C}ϕGF∈RHp×Wp×C。每个 Transformer 模块由六个 Swin Transformer Layer(STL)组成,并通过残差连接加速模型收敛,其计算过程如下:
ϕGF=HPUE(HTrans2(HTrans1(ϕSF)))+HTrans1(ϕSF)(5) \phi_{GF} = H_{PUE}(H_{Trans_2}(H_{Trans_1}(\phi_{SF}))) + H_{Trans_1}(\phi_{SF}) \tag{5} ϕGF=HPUE(HTrans2(HTrans1(ϕSF)))+HTrans1(ϕSF)(5)
其中,HTransiH_{Trans_i}HTransi 表示第 iii 个 Transformer 模块,HPUEH_{PUE}HPUE 表示 Patch Unembedding 层,该层采用核大小和步长均等于 Patch 大小的反卷积操作。经过 Transformer 模块与 Patch Unembedding 层后,输出特征 ϕGF\phi_{GF}ϕGF 被重塑为与输入图像相同的尺寸。最终,通过若干卷积模块生成融合图像 IfI_fIf,其定义如下:
If=Hconv2(Hconv1(ϕGF))+Hconv2(ϕI)(6) I_f = H_{conv_2}(H_{conv_1}(\phi_{GF})) + H_{conv_2}(\phi_I) \tag{6} If=Hconv2(Hconv1(ϕGF))+Hconv2(ϕI)(6)
其中,HconviH_{conv_i}Hconvi 表示第 iii 个卷积层,并结合 tanh 激活函数用于特征重建。
具体而言,Transformer 模块结构如图 3 所示,由六个 STL 组成。给定尺寸为 Hp×Wp×CH_p \times W_p \times CHp×Wp×C 的嵌入特征,STL 将特征划分为 (Hp×Wp/N2)×N2×C(H_p \times W_p / N^2) \times N^2 \times C(Hp×Wp/N2)×N2×C,即将特征划分为不重叠的 N×NN \times NN×N 窗口,其中 Hp×Wp/N2H_p \times W_p / N^2Hp×Wp/N2 表示窗口数量。随后计算局部注意力。设 ϕz∈RN2×C\phi_z \in \mathbb{R}^{N^2 \times C}ϕz∈RN2×C 为局部窗口特征,则查询 QQQ、键 KKK 和值 VVV 的计算方式如下:
Q=ϕzWQ,K=ϕzWK,V=ϕz(7) Q = \phi_z W_Q,\quad K = \phi_z W_K,\quad V = \phi_z \tag{7} Q=ϕzWQ,K=ϕzWK,V=ϕz(7)
其中,WQW_QWQ、WKW_KWK 和 WV∈RN2×dW_V \in \mathbb{R}^{N^2 \times d}WV∈RN2×d 为可学习参数,在不同窗口中共享,ddd 为 QQQ 和 KKK 的维度。自注意力函数定义为:
Attention(Q,K,V)=SoftMax(QKTd+p)V(8) Attention(Q,K,V) = SoftMax\left(\frac{QK^T}{\sqrt{d}} + p\right)V \tag{8} Attention(Q,K,V)=SoftMax(d QKT+p)V(8)
其中 ppp 为位置编码的可学习参数。STL 进一步计算多头自注意力。在图 3 中,W-MSA 与 SW-MSA 分别表示基于常规窗口和移位窗口划分的多头注意力。每个 STL 由一个 W-MSA 和一个 SW-MSA 以及一个多层感知机MLPMLPMLP组成,MLP 采用 GELU 激活函数对 MSA 生成的 Token 进行细化。MSA 和 MLP 之前均应用层归一化,并在各模块中引入残差连接。
1. 可见光/红外扩散模块:
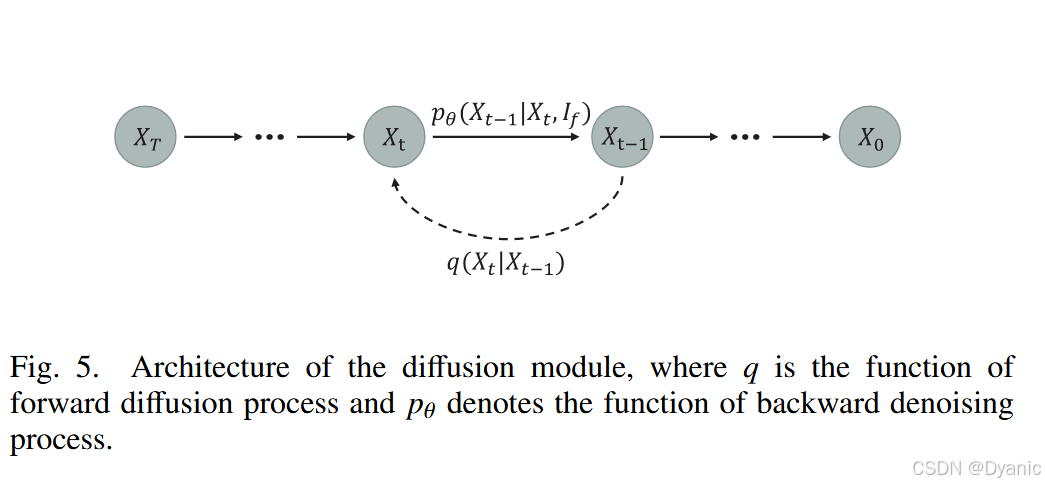
可见光与红外扩散模块具有相同的结构但参数不同,其整体结构如图 5 所示。扩散模块在训练阶段包含两个过程:前向扩散过程和反向去噪过程。在前向扩散过程中,通过多步逐渐向源图像添加高斯噪声,直至其变为纯高斯噪声。设 q(x0)q(x_0)q(x0) 为源图像的数据分布,训练样本 x0∼p(x0)x_0 \sim p(x_0)x0∼p(x0) 表示可见光/红外图像。在前向扩散过程中,噪声图像 x1,x2,...,xTx_1, x_2, \ldots, x_Tx1,x2,...,xT 按照马尔可夫过程生成:
q(xt∣xt−1)=X(xt;1−βtxt−1,βtI), ∀t∈1,...,T(9) q(x_t|x_{t-1}) = \mathcal{X}(x_t; \sqrt{1-\beta_t}x_{t-1}, \beta_t I), \ \forall t \in {1,\ldots,T} \tag{9} q(xt∣xt−1)=X(xt;1−βt xt−1,βtI), ∀t∈1,...,T(9)
其中 TTT 表示扩散步数,β1,...,βT\beta_1,\ldots,\beta_Tβ1,...,βT 为方差调度参数,III 为单位矩阵。通过迭代计算式 (9),可得到:
q(xt∣x0)=X(xt;β^tx0,(1−β^t)I)(10) q(x_t|x_0) = \mathcal{X}(x_t; \sqrt{\hat{\beta}_t}x_0, (1-\hat{\beta}_t)I) \tag{10} q(xt∣x0)=X(xt;β^t x0,(1−β^t)I)(10)
其中 β^t=∏i=1tαi\hat{\beta}t = \prod{i=1}^{t}\alpha_iβ^t=∏i=1tαi,αt=1−βt\alpha_t = 1-\beta_tαt=1−βt。据此,xtx_txt 可通过重参数化直接采样:
xt=β^tx0+1−β^tzt(11) x_t = \sqrt{\hat{\beta}_t}x_0 + \sqrt{1-\hat{\beta}_t}z_t \tag{11} xt=β^t x0+1−β^t zt(11)
其中 zt∼X(0,I)z_t \sim \mathcal{X}(0,I)zt∼X(0,I)。
反向去噪过程通过预测并逐步移除噪声来逆转前向扩散过程,其定义为:
p(xt−1∣xt)=X(xt−1;μ(xt,t),σ(xt,t))(12) p(x_{t-1}|x_t) = \mathcal{X}(x_{t-1}; \mu(x_t,t), \sigma(x_t,t)) \tag{12} p(xt−1∣xt)=X(xt−1;μ(xt,t),σ(xt,t))(12)
训练后的网络通过预测均值 μθ(xt,t)\mu_\theta(x_t,t)μθ(xt,t) 和方差 σθ(xt,t)\sigma_\theta(x_t,t)σθ(xt,t)来近似该过程:
pθ(xt−1∣xt)=X(xt−1;μθ(xt,t),σθ(xt,t))(13) p_\theta(x_{t-1}|x_t) = \mathcal{X}(x_{t-1}; \mu_\theta(x_t,t), \sigma_\theta(x_t,t)) \tag{13} pθ(xt−1∣xt)=X(xt−1;μθ(xt,t),σθ(xt,t))(13)
在推理阶段,xTx_TxT 从 X(0,I)\mathcal{X}(0,I)X(0,I) 中采样。根据下式可得:
μθ(xt,t):=1αt(xt−βt1−αˉ∗tϵθ(xt,t))(14) \mu_\theta(x_t,t) := \frac{1}{\sqrt{\alpha_t}}\left(x_t - \frac{\beta_t}{\sqrt{1-\bar{\alpha}*t}}\epsilon_\theta(x_t,t)\right) \tag{14} μθ(xt,t):=αt 1(xt−1−αˉ∗t βtϵθ(xt,t))(14)
σθ(xt,t):=β~t1/2,t∈T,T−1,...,1(15) \sigma_\theta(x_t,t) := \tilde{\beta}_t^{1/2}, \quad t \in {T, T-1, \ldots, 1} \tag{15} σθ(xt,t):=β~t1/2,t∈T,T−1,...,1(15)
最终,xt−1x_{t-1}xt−1 由下式计算:
xt−1(xt,t)=μθ(xt,t)+σθ(xt,t)z(16) x_{t-1}(x_t,t) = \mu_\theta(x_t,t) + \sigma_\theta(x_t,t)z \tag{16} xt−1(xt,t)=μθ(xt,t)+σθ(xt,t)z(16)
=1αtxt−βt1−αˉ∗tϵθ(xt,t)+β~tz(17) = \frac{1}{\sqrt{\alpha_t}}x_t - \frac{\beta_t}{\sqrt{1-\bar{\alpha}*t}}\epsilon_\theta(x_t,t) + \tilde{\beta}_t z \tag{17} =αt 1xt−1−αˉ∗t βtϵθ(xt,t)+β~tz(17)
其中 z∼X(0,I)z \sim \mathcal{X}(0,I)z∼X(0,I)。
我们采用 U-Net 结构作为去噪网络,用于预测每一步的噪声,并使用两个卷积层对融合图像 IfI_fIf 进行编码。如图 5 所示,第 i−1i-1i−1 步的噪声通过第 iii 步的噪声和融合图像作为条件进行近似。基于融合图像条件 IfI_fIf 的反向过程可表示为:
pθ(xt−1∣xt,ϕf)=X(xt−1;μθ(xt,t,ϕf),σθ(xt,t,ϕf))(18) p_\theta(x_{t-1}|x_t,\phi_f) = \mathcal{X}(x_{t-1}; \mu_\theta(x_t,t,\phi_f), \sigma_\theta(x_t,t,\phi_f)) \tag{18} pθ(xt−1∣xt,ϕf)=X(xt−1;μθ(xt,t,ϕf),σθ(xt,t,ϕf))(18)
其中 ϕf\phi_fϕf 表示融合图像 IfI_fIf 的编码特征。
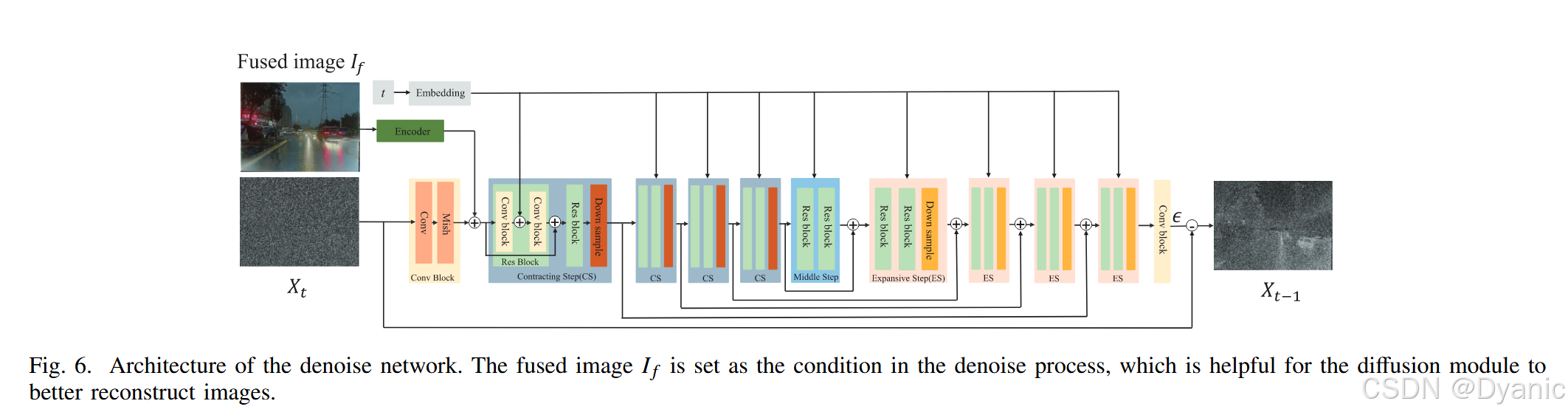
U-Net 的结构如图 6 所示。前向扩散过程中得到的高斯噪声 xtx_txt 作为输入,融合图像作为条件。在第 ttt 步中,xtx_txt 经过卷积层和 Mish 激活函数处理,同时融合图像的编码特征与卷积块输出进行融合,时间步 ttt 被输入至后续 Res Block。经过收缩、中间和扩展阶段后,预测第 ttt 步的噪声,最终通过从 xtx_txt 中减去预测噪声得到 xt−1x_{t-1}xt−1。每个收缩/扩展阶段均包含两个 Res Block 以及下采样/上采样层。
1. 损失函数:
损失函数在网络训练中起着关键作用。DSFuse 的总损失 LtotalL_{total}Ltotal 包含融合损失 LFusionL_{Fusion}LFusion 和扩散损失 LDDPML_{DDPM}LDDPM,其定义如下:
Ltotal=LFusion+λ(LDDPMir+rLDDPMvi)(19) L_{total} = L_{Fusion} + \lambda (L_{{DDPM}{ir}} + r L{{DDPM}_{vi}}) \tag{19} Ltotal=LFusion+λ(LDDPMir+rLDDPMvi)(19)
其中 λ\lambdaλ 用于平衡融合损失与扩散损失,rrr 控制 LDDPMirL_{{DDPM}{ir}}LDDPMir 与 LDDPMviL{{DDPM}{vi}}LDDPMvi 之间的权重比例。LFusionL{Fusion}LFusion 的主要作用是促使网络生成符合人类视觉感知的融合图像。
在训练阶段,我们通过最大化扩散模块对数似然 logpθ(x0)\log p_\theta(x_0)logpθ(x0) 的变分下界。简化后的扩散损失表达式为:
LDDPMir/vi=Eϵ∼X(0,1),t∣∣ϵ−ϵθir/vis(xt,t,If)∣∣22(20) L_{{DDPM}{ir/vi}} = \mathbb{E}{{\epsilon \sim \mathcal{X}(0,1),t}}\left\|\|\\epsilon - \\epsilon_{\\theta_{ir/vis}}(x_t,t,I_f)\\right\|\| _2\^2 \tag{20} LDDPMir/vi=Eϵ∼X(0,1),t∣∣ϵ−ϵθir/vis(xt,t,If) ∣22(20)
其推导细节可参考文献 37。其中 ϵθir/vis(xt,t,If)\epsilon_{\theta_{ir/vis}}(x_t,t,I_f)ϵθir/vis(xt,t,If) 表示去噪 U-Net 预测的噪声。
融合损失 LFusionL_{Fusion}LFusion 由 SSIM 损失、强度损失和梯度损失组成:
LFusion=LSSIM+α1Lint+α2Lgrad(21) L_{Fusion} = L_{SSIM} + \alpha_1 L_{int} + \alpha_2 L_{grad} \tag{21} LFusion=LSSIM+α1Lint+α2Lgrad(21)
其中 α1\alpha_1α1 和 α2\alpha_2α2 控制各损失项的权重。
SSIM 损失定义为:
LSSIM=β1(1−ssim(If,Ivi))+β2(1−ssim(If,Iir))(22) L_{SSIM} = \beta_1(1 - ssim(I_f,I_{vi})) + \beta_2(1 - ssim(I_f,I_{ir})) \tag{22} LSSIM=β1(1−ssim(If,Ivi))+β2(1−ssim(If,Iir))(22)
其中 ssim(⋅)ssim(\cdot)ssim(⋅) 表示结构相似性算子,设置 β1=β2=0.5\beta_1=\beta_2=0.5β1=β2=0.5。
强度损失为:
Lint=1HW∣If−max(Iir,Ivi)∣F2(23) L_{int} = \frac{1}{HW}\left|I_f - \max(I_{ir}, I_{vi})\right|_F^2 \tag{23} Lint=HW1∣If−max(Iir,Ivi)∣F2(23)
梯度损失定义为:
Lgrad=1HW∣∣∇If∣−max(∣∇Iir∣,∣∇Ivi∣)∣F2(24) L_{grad} = \frac{1}{HW}\left|\lvert\nabla I_f\rvert - \max(\lvert\nabla I_{ir}\rvert, \lvert\nabla I_{vi}\rvert)\right|_F^2 \tag{24} Lgrad=HW1∣∣∇If∣−max(∣∇Iir∣,∣∇Ivi∣)∣F2(24)
其中 ∇\nabla∇ 表示梯度算子,∣⋅∣|\cdot|∣⋅∣ 表示绝对值运算。
C. 训练与推理策略
DSFuse 的训练过程如算法 1 和图 4 所示。训练数据集包含 11 217 对红外与可见光图像。对图像进行尺寸调整和归一化后,随机选取 (m) 对图像输入 RTFusionNet,生成融合图像。随后,将融合图像与红外/可见光图像输入对应的扩散模块。当融合图像保留了最显著特征时,扩散模块在若干次训练迭代后即可重建高质量图像。最终,采用 Adam 优化器迭代更新 DSFuse 的参数。在推理阶段,仅需使用 RTFusionNet 即可完成图像融合,无需重复反向去噪过程,从而节省计算资源。
D. MSIV 图像数据集
现有红外与可见光图像融合数据集中的热目标种类和场景较为有限,而真实世界场景更加复杂。缺乏多样化场景数据会削弱模型的泛化性能。如图 2 所示,MSIV 数据集包含街道、自然场景、湖泊和建筑等多种环境,涵盖行人、汽车、船只、无人机及伪装目标等多种红外目标,并包含白天、夜晚和雨天等不同天气条件。MSIV 数据集包含 7000 对精确配准且带有目标标注的图像对,用于训练和评估各类融合方法。数据样例如图 7 所示。
我们使用光轴平行的可见光相机与红外相机构建图像采集系统,如图 8 所示。红外图像的波长范围为 8--14 μm,分辨率为 640×512640 \times 512640×512,可见光图像分辨率为 1280×7201280 \times 7201280×720。图像采集完成后,通过计算单应性矩阵将可见光图像坐标映射到红外图像坐标系中,最终获得精确配准的图像对。
IV. 实验
本节展示 DSFuse 的有效性。首先介绍实验配置与实现细节;随后给出定量与定性实验结果;之后通过消融实验验证我们结构设计的重要性。实验在一台台式机上实现,硬件配置为 Intel I913900K CPU、NVIDIA RTX3090 和 128-GB 内存。
A. 实验设置
在训练过程中,我们从 M3FD 15、MSRS 39、LLVIP 40 和 MSIV 中选取了 11 217 对红外与可见光图像。其中,3285 对来自 LLVIP,300 对来自 M3FD,824 对来自 MSRS,其余 6808 对来自我们提出的数据集 MSIV。训练图像被缩放至 640 × 480,并在输入网络之前随机裁剪为 360 × 360。batch size 设置为 8,epoch 和学习率分别为 50 和 (1 \times 10^{-5})。损失函数中的参数 (\lambda) 设置为 5,且 (L_{Fusion}) 中的参数 (\alpha_1) 和 (\alpha_2) 均设置为 5。
在测试过程中,我们从这些数据集中选择了 400 对图像,包含大量场景与多种光照条件。值得注意的是,测试图像对不出现在训练数据中。我们选取了 6 个客观指标进行定量评估,包括熵(EN)41、多尺度结构相似性指数(MS-SSIM)42、图像质量指标((Q_{abf}))43、空间频率(SF)44、视觉信息保真度(VIF)45 以及互信息(MI)46。这些指标可分为四类:第一类基于信息熵,包括 EN 和 MI;第二类基于图像特征,包括 SF 和 (Q_{abf});第三类基于图像结构,包括 MS-SSIM;最后一类基于人类感知,包括 VIF。上述指标的具体计算方法与公式可参考既往融合相关论文 19,47,48。所有评估指标均为值越大表示融合质量越高。
我们选取了 11 种最先进(SOTA)方法与 DSFuse 进行对比,即 FusionGAN 19、U2Fusion 14、RFN-Nest 18、Tardal 15、TGFuse 9、IRFS 31、CDDFuse 49、LRRNet 47、DDFM 38 和 Dif-Fusion 10。
B. 定性结果
图 9 展示了图像融合中极具挑战性的场景,并给出了四个数据集上各方法的融合效果。图中将包含冲突信息的关键区域用框标出并进行放大。在图 9(a) 中,可见光图像中的行人(红框)穿着黑色衣物,与红外图像中高亮的热目标形成对比,这种冲突使得在融合图像中有效表达该行人的显著性变得困难。尽管蓝框区域两幅图像存在一定错位,我们仍希望在融合图像中同时保留可见光图像稠密的高频细节以及红外目标的显著性。图 9(b) 中明暗对比强烈:在融合图像中既要保留暗区(蓝框)的红外细节,又要在亮区(红框)中突出小型热目标,这十分困难。图 9© 中,可见光图像的背光高亮区域(蓝框)几乎没有细节,而红外图像对应区域却能清晰显示车辆与行人;但在融合图像中,很难在这些高亮可见光区域内有效呈现红外目标。同时,我们希望在融合图像中自然呈现红框区域内突出的红外目标以及丰富细节。图 9(d) 中,我们期望融合图像能够充分继承源图像特性:既有效保留红外图像特征,又保持丰富纹理与良好视觉质量,例如蓝框中的树木细节与红框中的杆体纹理。
尽管所有 SOTA 方法都能生成较为满意的融合图像,但仍存在一些局限。RFN-Nest 试图保留更多可见光特征,却牺牲了显著目标的亮度;FusionGAN 模糊了细节与边缘;U2Fusion 存在一定程度的红外显著特征丢失;SDNet 与可见光图像存在明显颜色差异;Tardal 与 IRFS 能保持红外目标的锐利边缘与显著区域,但对小目标及其他细节保留不足;TGFuse 存在显著热目标与小细节丢失;CDDFuse 与 LRRNet 仍难以有效突出热目标;DDFM 与 Dif-Fusion 在图 9(a)、(b) 中生成的图像热区与背景对比度较弱。
相比上述方法,我们的方法具有明显优势:融合结果纹理清晰锐利,热目标突出。在图 9(a) 中,我们的融合结果使行人(红框)更加显著;其他方法在蓝框细节区域较为杂乱,而我们保留了最清晰的细节。在图 9(b) 中,由于光照条件复杂,我们的方法是唯一同时保留蓝框信息并突出红框热目标的方法。在图 9© 中,我们结果中的行人(蓝框与红框)更易从复杂背景中区分出来。在图 9(d) 中,我们的方法在有效突出热目标的同时保证了令人满意的色彩表现,尤其是绿色框中的垃圾目标。
C. 定量结果
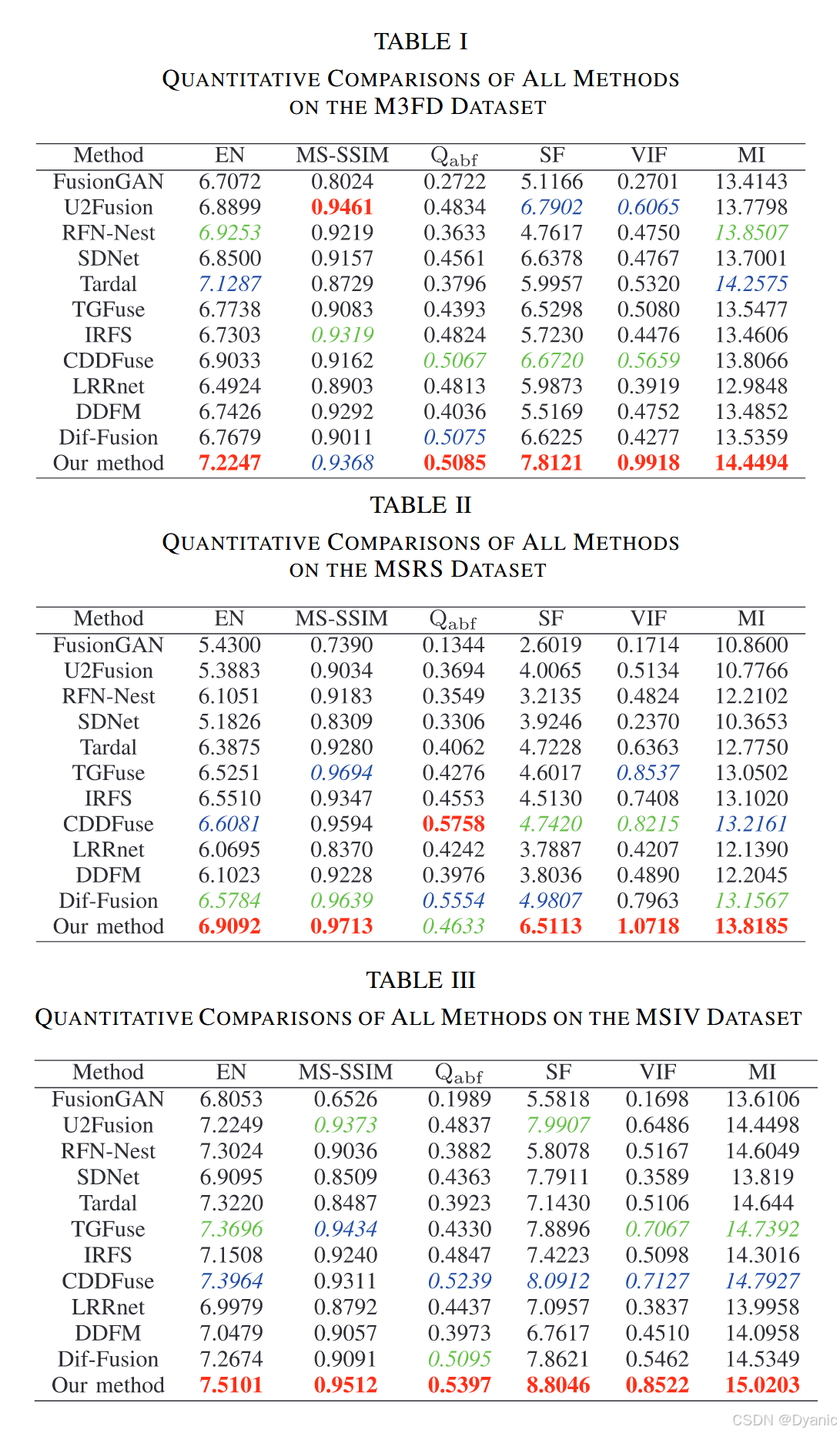
我们在测试图像上使用 6 个客观指标对 11 种 SOTA 方法与 DSFuse 进行了定量评估。结果如图 10 所示,并汇总于表 I--IV。这些表给出了不同方法在不同数据集上的客观指标均值。我们用红色加粗标注最优结果,用蓝色斜体标注第二优结果,用绿色斜体标注第三优结果。表 I 与图 10(a) 给出了 M3FD 数据集的对比结果。可以看到,DSFuse 在 M3FD 数据集的 100 对图像上,在 5 个指标上取得最佳表现。此外,如表 II--IV 与图 10 所示,我们的方法在其他数据集上同样在 5 个指标上表现最佳。EN、SF、MI 和 VIF 的最佳值表明我们的方法能够充分提取并保留源图像中的互补特征;MS-SSIM 与 QabfQ_{abf}Qabf 指标体现出的优越性说明我们的方法能够生成信息丰富且稳定的融合结果。
D. 语义评估
- 检测性能对比:为进一步探索对视觉下游任务的适用性,我们采用目标检测模型 YOLOv8 50 作为基线模型。为公平评估不同融合方法在目标检测任务上的性能,我们在 LLVIP 数据集上使用红外与可见光图像重新训练 YOLOv8。结果如图 11 所示。如图 11 所示,低照度条件使得在可见光图像中几乎无法识别目标。同时,两名个体在阴影中相互遮挡,而一名骑行者位于稍亮区域。由于暗区细节保留不足,U2Fusion、SDNet 和 TGFuse 未能使检测模型识别出阴影中的两名个体。Tardal、IRFS、CDDFuse、DDFM 与 Dif-Fusion 因互相遮挡而将两名个体误识别为一人。FusionGAN 由于明显的视觉错误而错误地检测到单个人。尽管 LRRNet 能检测到阴影中的两名个体,但其置信度较低。与所有对比方法相比,DSFuse 能显著提升目标检测性能,表明 DSFuse 能有效保留语义信息。定量结果见表 V:DSFuse 在 LLVIP 数据集上的召回率与平均精度均值(mAP)优于其他算法,同时其精确率与表现最佳的方法 U2Fusion 相当。这进一步验证了 DSFuse 能为后续目标检测任务带来显著提升。
- 分割性能对比:我们采用分割模型 SegNeXt 51 作为基线,以验证语义表征的有效性。为公平评估语义质量,我们使用不同融合方法在 MSRS 数据集的训练数据上合成融合图像,然后按 Diff-IF 的设置对 SegNeXt 进行微调。评估结果如图 12 所示,定量结果见表 VI。在图 12 的场景 1 中,rfnNet、CDDFuse、TGFuse 与 DDFM 未能保留足够信息,导致分割模型在红框区域错误识别行人。此外,SDNet 与 LRRNet 中的车辆(蓝框)被误分类为自行车,Dif-Fusion 的结果也存在行人分割不完整的问题。我们的方法生成的信息丰富的融合图像使 SegNeXt 能正确识别行人、汽车与弯道。在场景 2 中,我们的融合图像同样在近处行人与远处自行车的分割上获得更佳结果。表 VI 显示 DSFuse 取得最高的平均 IoU(mIoU),说明我们的方法能更好地保留语义特征。
E. 消融实验
- 扩散模块分析:扩散模块利用融合结果重建源图像,并向 RTFusionNet 提供反馈以获得更好的融合结果。图 13 展示了扩散模块的结果并验证其有效性。如图 13 所示,去噪后的红外图像存在轻微细节损失,但显著热目标得到了良好保留;去噪后的可见光图像在像素强度分布上存在一定畸变,但纹理得以保留。在图 13(e)--(h) 中,不含红外与可见光扩散模块的结果丢失了汽车的部分结构信息,且热区域不够突出;不含可见光扩散模块的结果在热区域表现更好,但丢失部分细节信息;同样,不含红外扩散模块的结果保留了更多可见光细节,但无法突出热区域。然而,在红外与可见光扩散模块的共同指导下,我们的方法能够清晰保留结构并以锐利边缘突出热目标。MSRS 数据集的定量结果如表 VII 所示,结果表明加入扩散模块能提升性能。
为进一步验证扩散模块的有效性,我们用卷积模块替换扩散模块:将融合图像输入卷积模块以重建红外/可见光图像,并使用 MSE 损失约束重建图像与原始红外/可见光图像,从而同样提供反馈以增强模态信息。网络结构如图 14 所示。卷积模块包含两条分支,分别用于重建红外图像和可见光图像。每条分支包含 4 个卷积块,每个卷积块由卷积层、批归一化层和激活函数层组成,第一卷积块在两条分支间共享。最后一个卷积块使用 tanh 激活函数,其余卷积块使用 Leaky ReLU。如图 15 所示,尽管卷积模块也能提供融合指导,但其生成能力有限,导致其在处理红外与可见光之间的冲突信息(如高亮红外目标区域)方面不如扩散模块有效。例如,在图 15(o) 与 § 中,扩散模块在红框突出目标的融合效果更好。此外,卷积模块也难以有效引导融合图像保留可见光图像的精细细节;相较之下,如图 15(g) 与 (h) 所示,使用扩散模块的结果更锐利且细节更丰富。进一步地,卷积模块重建的红外与可见光图像在细节表达与整体视觉质量上均不如扩散模块的重建结果。表 VIII 给出了两种方法融合结果在客观指标上的差异,扩散模块提升了多项指标。因此,引入扩散模块更有利于实现特征保真。
1. 融合损失分析 :融合损失由 SSIM 损失、纹理损失和强度损失构成。为验证损失函数的有效性,我们进行了一系列消融实验,视觉结果如图 16,定量结果如表 IX。强度损失 LintL_{int}Lint 用于促使 RTFusionNet 保持源图像的灰度分布。缺少 LintL_{int}Lint 约束时,DSFuse 难以保留合适的强度信息,如图 16© 与 (l) 所示,会生成显著目标减弱的融合图像。在图 16(d) 与 (j) 中,缺少 LgradL_{grad}Lgrad 的 DSFuse 会使纹理与目标边缘变得模糊。如图 16(e) 与 (k) 所示,缺少 LSSIML_{SSIM}LSSIM 的引导时,网络在保持结构与强度信息方面的效果不理想,显著目标与细节相较于完整 DSFuse 略有减弱。表 IX 给出了定量结果:当损失项缺失时,客观评估指标显著下降。综上,LintL_{int}Lint、LgradL_{grad}Lgrad 与 LSSIML_{SSIM}LSSIM 对 DSFuse 生成令人满意的融合图像至关重要。
2. 超参数分析 :α1\alpha_1α1 与 α2\alpha_2α2 控制融合图像中强度信息与纹理信息保留的比例。在式 (21) 中,过小的 α1\alpha_1α1 或 α2\alpha_2α2 可能无法约束网络保留必要特征;过大的 α1\alpha_1α1 或 α2\alpha_2α2 又可能破坏强度保留与纹理保留之间的平衡。超参数 λ\lambdaλ 用于平衡损失 LFusionL_{Fusion}LFusion 与 LDDPMir/viL_{{DDPM}_{ir/vi}}LDDPMir/vi。因此,我们进行消融实验以验证超参数取值的合理性,将 λ\lambdaλ 赋值为 1、5 和 100。如图 17 所示,当 λ\lambdaλ 取较小值 1 时,模型整体可能难以进行特征保留;当 λ=100\lambda=100λ=100 时,融合图像在复杂环境中无法呈现突出的热目标。当 λ=5\lambda=5λ=5 时 DSFuse 表现最佳。
在图 17 中,当 α1=1\alpha_1=1α1=1 时,融合结果存在红外目标不够显著的问题,尤其是汽车与行人;当 α1=100\alpha_1=100α1=100 时,融合图像整体亮度提升,但视觉上显得不自然。对于 α2\alpha_2α2,较小的取值不利于 DSFuse 保留清晰细节,而过大的 α2\alpha_2α2 会导致融合图像在细节与目标像素强度之间失衡。因此,推荐将超参数 α1\alpha_1α1、α2\alpha_2α2 和 λ\lambdaλ 分别设为 5、5、5。rrr 控制 LDDPMirL_{{DDPM}{ir}}LDDPMir 与 LDDPMviL{{DDPM}_{vi}}LDDPMvi 之间的权重比例。在图 18 中,随着 rrr 增大,融合图像整体风格更偏向可见光图像;相反,当 rrr 减小时,融合图像整体风格更偏向红外图像。当 rrr 设置为 1 或接近该值时,如图 18 所示,融合图像能在红外与可见光信息保留之间取得良好平衡。
F. 基于扩散的融合方法开销对比
在实际应用中,计算资源与处理速度也是衡量方法实用性的重要指标。我们在一张 3090 GPU(24-GB 显存)上对比了 DSFuse 与现有基于扩散的融合方法 DDFM 和 Dif-Fusion 的开销,结果见表 X。由于显存溢出,DDFM 与 Dif-Fusion 在推理阶段无法正常运行;而我们的方法能够稳定运行,体现了其实用性。在推理阶段,我们的方法仅需运行 RTFusionNet,无需重复执行扩散模块的反向过程,从而在推理阶段以更低的计算资源消耗获得理想的融合结果。图 19 展示了浮点运算量、参数量、运行时间与模型性能的对比结果。与其他基于扩散的方法相比,我们的方法在保持更少参数量与更快推理速度的同时取得了更好的性能。
V. 结论
本文提出了一种用于红外与可见光图像融合的特征保真双扩散框架 DSFuse。我们将融合网络的指导过程表述为双扩散过程,以保留跨模态特征;随后采用两个独立的扩散模块迫使融合模块充分提取并利用跨模态信息,从而确保融合图像的特征保真。在建模多模态图像的全局关系时,我们设计了 RTFusionNet,通过采用 Swin 模块与注意力机制生成令人满意的融合结果。同时,我们为 RTFusionNet 与扩散模块设计了特定的损失函数,以保证融合结果的特征保真。此外,我们发布了一个面向红外与可见光融合的新数据集 MSIV。最后,通过一系列实验验证了所提方法的优势,结果表明 DSFuse 能有效生成同时具有显著热目标与多纹理背景的融合图像。