1. @Resource 更稳、@Autowired 更快;
平台/老系统/多实现 → @Resource
快速开发/单实现 → @Autowired
2.@PathVariable 和@RequestParams()
@PathVariable 在url中进行传递数据:localhost:8081/user/1
@@RequestParams通过问号进行拼接
@GetMapping("login/ignore/{userId}")
public Object userLoginIgnore(@PathVariable String userId) {
// UserLoginVo loginVo = authService.userLoginIgnore(userId);
UserLoginVo loginVo = authService.userLoginIgnoreBySys(userId);
return R.ok(loginVo);
}
3. redis的key设置前缀的好处:
public class RedisKeys {
/**
* 验证码Key
*/
public static String getCaptchaKey(String key) {
return "sys:captcha:" + key;
}
/**
* accessToken Key
*/
public static String getAccessTokenKey(String accessToken) {
return "sys:token:" + accessToken;
}
}
区分业务,业务隔离,key的误删。
总结: Redis 本身没有命名空间的概念,所以在实际项目中通常通过 key 前缀进行业务隔离。
使用像 sys:captcha: 这样的前缀可以防止 key 冲突,提升可读性和运维效率,
同时便于按业务维度进行统计、清理和监控,在分布式和 Redis Cluster 场景下也更有利于 key 的管理。
如何解决分布式场景锁的误删:value唯一性标识+lua脚本原子性操作
前缀命名空间:
sys:captcha:xxxx
sys:token:xxxx
ws:chat:xxxx
下面场景会导致key的误删:
123456 -> 验证码
123456 -> token
123456 -> websocket 用户
4. private static final String BASE_DIR_FILE = "resource/file";
啥时候使用?
一、先给结论(一句话版)
当一个值:
① 不会变
② 被多处使用
③ 具有业务语义
就应该定义为 static final 常量
private static final int MAX_RETRY_COUNT = 3;
private static final String DEFAULT_CHARSET = "UTF-8";
public class FormGroupServiceImpl implements ModelGroupService {
//第一种
private final WflowModelGroupsMapper groupsMapper;
public FormGroupServiceImpl(WflowModelGroupsMapper groupsMapper) {
this.groupsMapper = groupsMapper;
}
//第二种
@Resource
private WflowModelsMapper modelsMapper;
}
帮我看一下上面代码,是第一种构造器方式注入比较好,还是第二种@Resource方式?
在 Service 层我更倾向于使用构造器注入,
因为它可以保证依赖在对象创建时就被完整注入,依赖不可变,
同时也更利于单元测试和代码可维护性。
字段注入更适合非核心或历史代码场景。
5.下面代码的作用?
ModelGroupVo modelGroupVo = ModelGroupVo.builder()
.id(group.getGroupId()) .name(group.getGroupName())
.items(new LinkedList<>()).build();
这行代码是使用 Builder 模式将分组实体对象转换成返回给前端的 VO 对象,
同时提前初始化子项列表,避免空指针问题,也方便后续组装分组下的子数据。
6. restful接口常用的请求方式?
GET → 查询(幂等)
POST → 新增 / 非幂等操作
PUT → 全量更新(幂等)
PATCH → 局部更新(幂等)
DELETE → 删除(幂等)
7. 频繁增删改可以用linkedList(头指针和尾指针都要存数据)
List<OrgTreeVo> orgs = new LinkedList<>(orgRepositoryService.getSubDeptById(deptId));
或者
Deque<OrgTreeVo> queue =
new ArrayDeque<>(orgRepositoryService.getSubDeptById(deptId));
8. 下面代码的含义?
如果 type 是 user,就查询部门下的用户,标记是否是负责人,
把负责人排在最前面,然后加入 orgs 列表中。
判断 type == user
↓
查部门下所有用户
↓
遍历用户,标记是否负责人
↓
负责人 = true 的用户排前
↓
加入 orgs
orgs.addAll(
orgRepositoryService.selectUsersByDept(deptId)
.stream()
.map(u -> {
u.setIsLeader(
StrUtil.isNotBlank(department.getLeader())
&& department.getLeader().equals(u.getId())
);
return u;
})
.sorted(Comparator.comparing(OrgTreeVo::getIsLeader).reversed())
.toList()
);
9. 流式编程优化
models.forEach(v -> {
List<WflowSubProcess> list = listMap.get(v.getGroupId());
if (Objects.isNull(list)){
list = new LinkedList<>();
listMap.put(v.getGroupId(), list);
}
list.add(v);
});
代码替换:
models.forEach(v -> {
List<WflowSubProcess> list = listMap.get(v.getGroupId());
map.computeIfAbsent(key, k -> new ArrayList<>()).add(v);
});
线程安全使用:
map.computeIfAbsent(key, k -> new CopyOnWriteArrayList<>()).add(v);
代码解释:
第一步:
List<T> list = map.computeIfAbsent(
key,
k -> new CopyOnWriteArrayList<>()
);
它的返回值是:
map 中 key 对应的 value
如果 key 已存在
👉 返回已有的 List
如果 key 不存在
👉 创建一个新的 CopyOnWriteArrayList
👉 放进 map
👉 返回这个新建的 List
第二步:
然后立刻调用 .add(v)
list.add(v);
也就是:
往这个 List 里加一个元素 v
//listMap.getOrDefault()获取到值直接返回,没有获取到创建一个空的list返回
groups.stream()
.map(v -> new SubModelGroupVo(v.getGroupId(), v.getGroupName(),
listMap.getOrDefault(v.getGroupId(), Collections.emptyList())))
.collect(Collectors.toList())
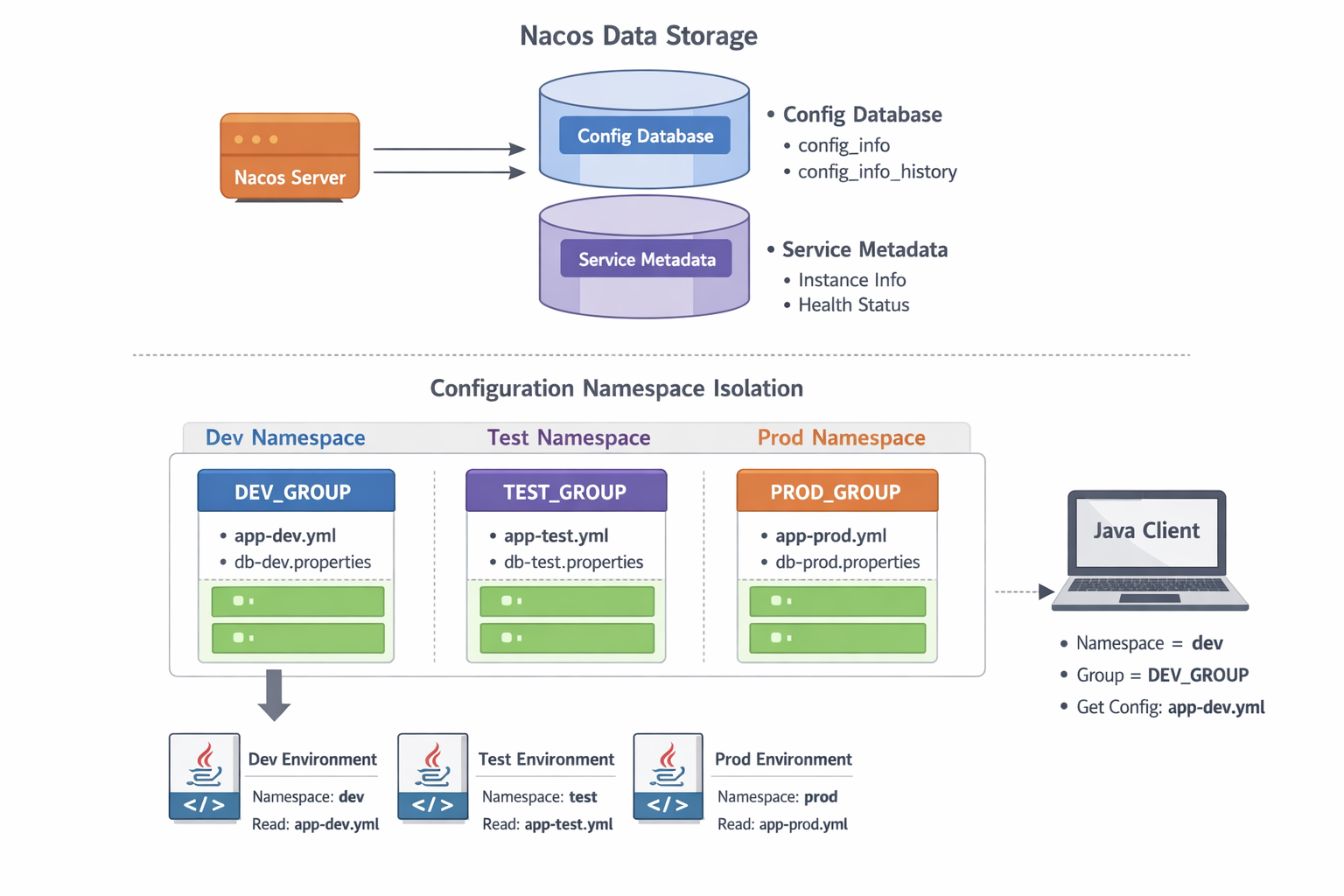
- nacos数据的存储