1.参数解释
1.最大似然估计(Maximum Likelihood Estimation, MLE) 是一种参数估计方法,其核心思想是:在已知观测数据的前提下,寻找最有可能产生这些数据的参数值,多个独立事件的乘积
通俗地说:如果我们看到某些现象发生了,那么我们就认为导致这种现象发生的原因(参数)应该是最可能的那个。
概率函数 :在已知参数 θ 的情况下,预测观测数据 X 出现的概率:P(X|θ)
似然函数:在已知观测数据 X 的情况下,评估参数 θ 的可能性:L(θ|X)
- 对于独立同分布的样本 X = {x₁, x₂, ..., xₙ},似然函数为:L(θ|X) = ∏ᵢ f(xᵢ|θ),其中 f(xᵢ|θ) 是概率密度函数(连续)或概率质量函数(离散)。
- 假设抛硬币10次,观察到7次正面,3次反面。设正面概率为 θ。
- 先把乘积求对数,对数不改变函数单调性,其次再求导,当导数接近0是取到最大值,从而计算参数
- L(θ|数据) = θ⁷ × (1-θ)³
ℓ(θ) = 7 ln θ + 3 ln(1-θ)
∂ℓ / ∂θ = 7/θ - 3/(1-θ) = 0
7/θ = 3/(1-θ)
θ = 0.7 - 结论:θ̂ = 0.7 是最有可能产生观测数据的参数值。
2.卡方分箱保持单调性方法
- 先对数据进行100组的等频分箱,然后计算每一箱的卡方值,然后对相邻箱进行合并,,为保持单调性对,可能破坏单调性的箱进行特殊处理,优先选择不会破坏单调性的箱合并,多次循环直到,完全单调为止,如果不满足缩减分箱个数,分箱完成后,若发现个别箱破坏了单调性,可以尝试微调分箱边界。
3.正则化直观理解
- 正则化就像给模型戴上一个"紧箍咒",防止它变得太复杂、太专注于训练数据中的细节(包括噪声),从而提高泛化能力。

- 例如:
没有正则化:学生死记硬背所有例题和答案,包括印刷错误
有正则化:学生理解核心概念,能解答没见过的新题
2.支持向量机
-
支持向量机 (Support Vector Machine,SVM)是一种有监督的机器学习算法,广泛应用于分类和回归问题,支持向量是离分类超平面最近的那些数据点,找到一个超平面,使得俩边的点到超平面距离最大。
-
SVM要找到一条线(超平面)将它们分开:
离分隔线最近的那些点(图中用标记红色)就是支持向量:
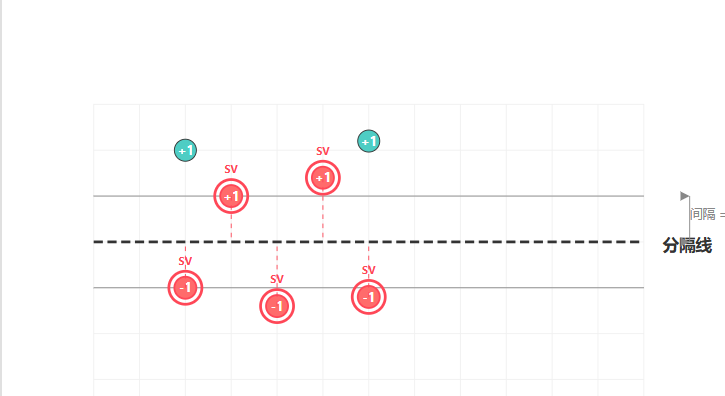
-
线性可分情况 :在特征空间中,SVM 试图找到一个超平面,将不同类别的数据点完全分开,并且使这个超平面到最近的数据点(即支持向量)的距离最大化。这个距离被称为间隔(margin)。例如,在二维平面上,两类数据点可以用一条直线分开,SVM 要找的就是使间隔最大的那条直线。
线性不可分情况:现实中数据往往并非线性可分,这时引入松弛变量,允许一些数据点在一定程度上越过超平面,目标是在最大化间隔和最小化分类错误之间找到平衡。也就是把低维度图像转换为高纬度,之后变得线性可分 -
核函数作用:当数据在原始特征空间中线性不可分时,核函数可以将数据映射到更高维的特征空间,使数据在新空间中变得线性可分。
低维 -- 高维 转换过程
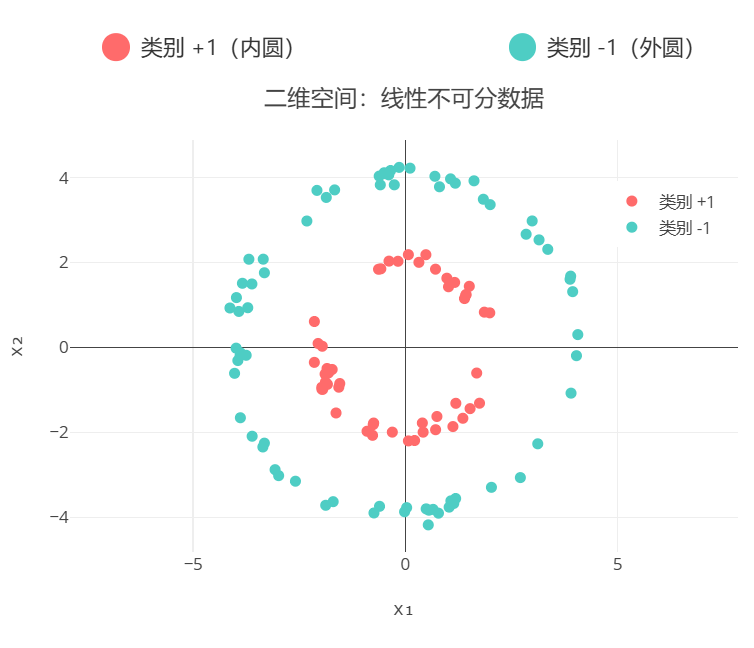
- 数据描述 :在二维平面上,数据点呈同心圆分布:内圆为类别+1(红色),外圆为类别-1(蓝色)。由于两类数据是环形分布,无法找到一条直线完美地将它们分开,这就是线性不可分问题。
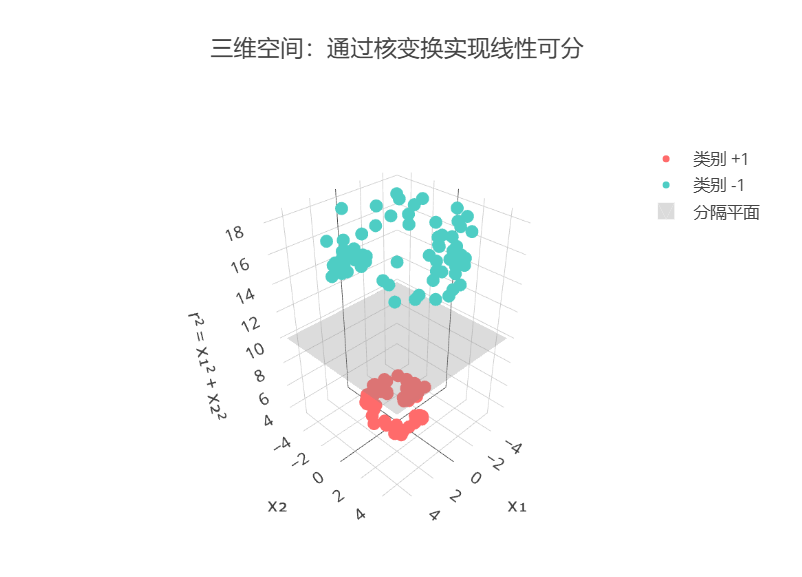
- 问题描述:通过非线性映射 φ(x₁, x₂) = (x₁, x₂, x₁² + x₂²) 将数据从二维转换到三维空间。在三维空间中,两类数据可以通过一个平面(超平面)完美分隔,线性可分问题得到解决。
3.Xgboost
- XGBoost不像随机森林那样并行训练多棵树,而是串行地训练一系列树,每棵树都试图修正前几棵树的错误。
- 基本原理 就是多颗决策树依次预测,第二颗决策树基于第一颗决策数残差,来进行学习预测,第三颗决策树根据前俩颗决策树看成整体的残差进行预测
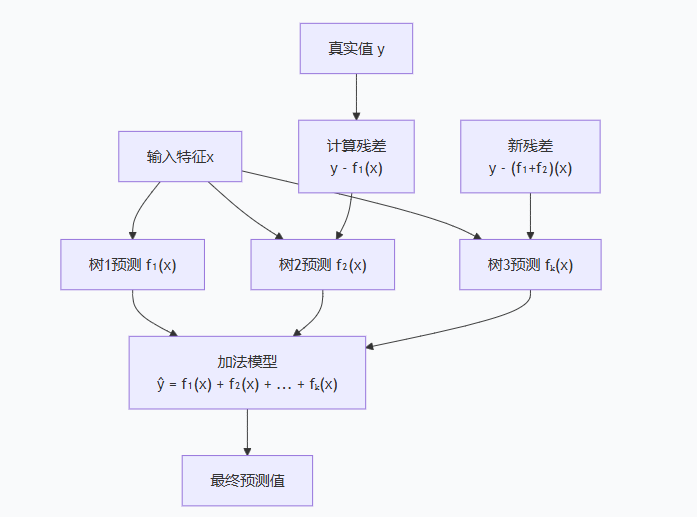
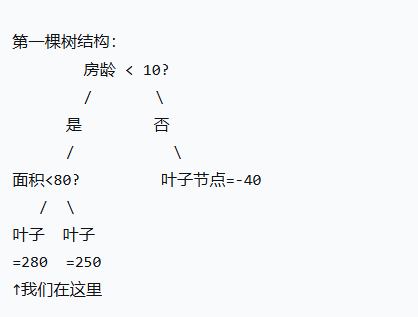
- 例如预测一套房产的价格:面积100平米,房龄5年,
- 第一轮预测第一棵树
输入:面积=100, 房龄=5
第一棵树预测:f₁(x) = 280万元
残差(误差):300 - 280 = 20万元
- 第二轮预测第二棵树
- 输入:同样的特征(面积=100, 房龄=5)
真实目标:残差20万元(不是原房价!)
第二棵树预测:f₂(x) = 18万元
新残差:20 - 18 = 2万元

- 第三轮预测第三棵树
- 第三棵树预测:f₃(x) = 1.8万元
残差变为:2 - 1.8 = 0.2万元
最终预测 = 树1 + 树2 + 树3
= 280 + 18 + 1.8
= 299.8万元

- 参数调参
学习率 -- 树模型 -- 正则化参数
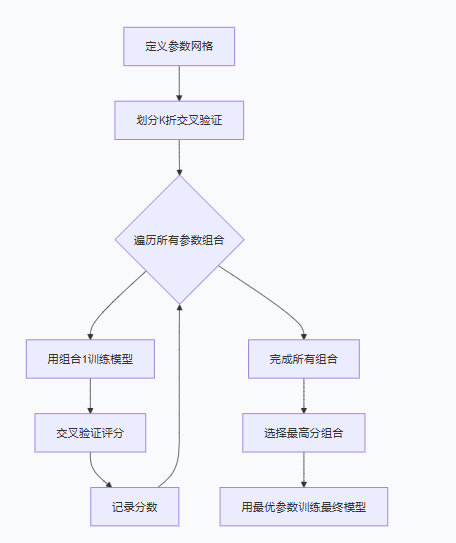
网格搜索(严谨但慢)或者随机搜索(快速抽样) - 网格搜索 (Grid Search)是机器学习里最经典的超参数调优方法,属于暴力穷举式调优,不管是单模型(决策树、逻辑回归)还是集成模型(XGBoost、随机森林)都能用,核心目的就是找到让模型泛化能力最优的超参数组合,常和交叉验证搭配使用。
- 随机搜索(Random Search)是机器学习里超参数调优的常用方法,和网格搜索目标一致,都是找最优超参数组合,常搭配交叉验证使用,但它是随机抽样式调优,完美解决了网格搜索的组合爆炸问题,工业界用得比网格搜索更广泛。
- 核心逻辑很简单:
① 先给每个待调超参数划定取值范围 / 分布(比如学习率 0.01~0.3 随机取、树深度 3~7 随机整数),不用像网格搜索那样定固定候选值;
② 从所有超参数的取值空间里,随机抽取指定数量的超参数组合(比如抽 50 组 / 100 组);
③ 用交叉验证评估每组组合的模型性能,最终选验证集表现最好的那组作为最优组合。 - xgboost基本参数
1.学习率 :学习率是机器学习梯度下降类算法的核心超参数,是一个 0 到 1 之间的小数值,核心作用就是控制模型每一步更新参数的 "步长"。模型训练时会沿着损失函数下降最快的方向(梯度方向)调整参数,学习率就是这一步迈多大的标尺,最终目的是让模型能精准收敛到损失函数的最小值,而不是错过或绕远。
2.正则化参数 :专门防止过拟合的,gamma是叶子节点分裂的最小损失减少值,越大越难分裂、树越简单;还有reg_alpha(L1正则)和reg_lambda(L2正则),L2 用得更多,值越大正则化越强。
3.树结构基础参数 :最核心的是max_depth(树的深度),控制树的复杂度,一般设 3-7,太大容易过拟合;还有min_child_weight,控制叶子节点的最小样本权重和,太小易过拟合、太大致欠拟合。
4.采样 / 缺失值参数:subsample是行采样,随机选部分样本训练单棵树;colsample_bytree是列采样,随机选部分特征,两者一般设 0.8 左右,都是为了减少过拟合;还有missing,用来指定数据中的缺失值标识,XGBoost 能自动处理缺失值,这也是它的优势。