关于前面关于深度学习的学习我们介绍了深度学习的运行环境,以及使用食物识别的例子对于深度学习基于神经网络搭建的模型的优化。这次补充有助于更好地理解深度学习。
1.使用深度学习进行模型训练
- 模型训练的目的:使得参数尽可能的与真实的模型逼近
- 具体做法:1.首先给所有参数赋上随机值,使用随机参数值来预测训练数据的样本;2.其次计算预测值为yi,真实值为y,那么定义一个损失值loss,损失值用于判断预测的结果和真实值的误差,误差越小越好
神经网络中,单个神经元是用来模拟逻辑回归的,本质上就是逻辑回归。
神经网络可以做非线性映射------隐藏层
2.神经网络的构造(主要是看中间层的确定)
- 输入层的节点数:与特征的维度匹配
- 输出层的节点数:与目标的维度匹配
- 中间层的节点数:没有什么特定的规则,就目前来说。一般根据经验设置,可以通过预先设定几个可选值,通过切换这几个值来看整个模型的预测效果,选择最为合适的
在深度学习中损失函数用的最多的就是交叉熵损失函数和均方差损失函数
3.损失函数都有哪些?
- 0-1损失函数(二分类)
- 均方差损失
- 平均绝对值损失
- 交叉熵损失
- 合页损失
4.梯度下降
其实就是神经网络工作过程中,w不停更新的过程就是梯度下降。
各个w在什么情况下使得loss最小,一开始w的初始化随机给值,求损失函数loss关于权重w的偏导数,找到往loss最小的方向进行更新,学习率就是决定往这个方向走多少,这样的操作循环进行
求偏导过程中会出现一些连乘因子,梯度消失和梯度爆炸就和这些连乘因子有关:
- 梯度消失:如果连乘因子大部分小于1,最后乘积的结果可能趋于0,也就是梯度消失,后面的网络层的参数不发生改变。
- 梯度爆炸:如果连乘因子大部分大于1,最后乘积可能趋于无穷。
造成原因:梯度反向传播中的连乘效果,对于更普遍的梯度消失问题,可以使用relu,tanh等代替sigmoid函数。
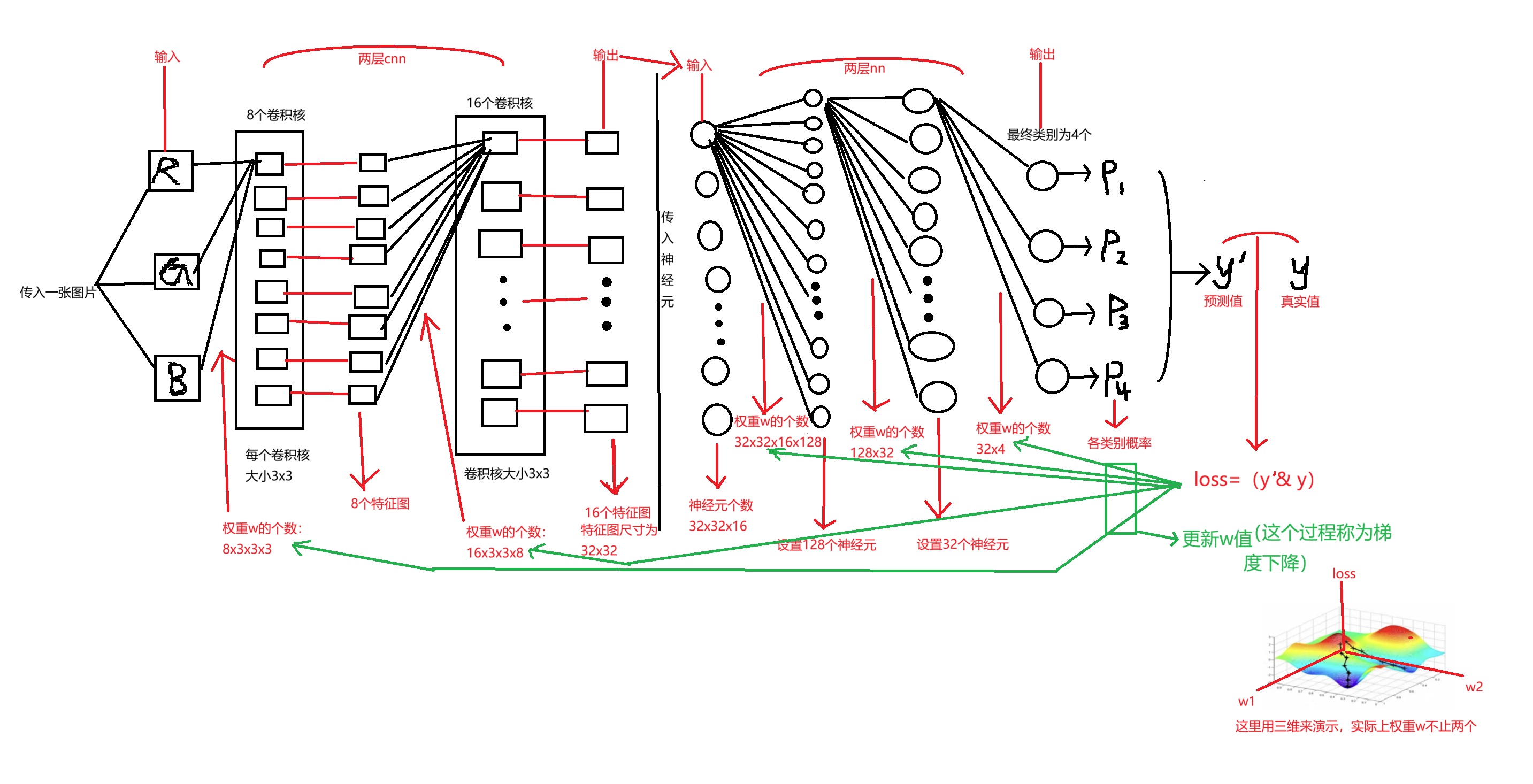
- 特征图个数就等于卷积核个数
- cnn和nn不同的是,权重w的个数要考虑特征图的尺寸
- 得到的特征图对应的每个数值都是他的特征,所以我们cnn转nn时,输入神经元是要乘上特征图尺寸的。
5.cnn神经网络的分析
torch,其实就相当于pandas,都是用来处理数据的。
PIL库,完整名字为pillow,是图像处理库。Opencv包含大量的算法,pillow就类似于电脑中的画图。和opencv的区别就在于opnecv能看到对应的像素点,pillow就只进行简单的处理。
python
import torch#搭建网络
from torch.utils.data import Dataset, DataLoader#处理图片数据集,之前我们的数据都是用pandas和numpy
import numpy as np
from PIL import Image#画图板
from torchvision import transforms#对数据进行处理工具,尤其是图片
import torch.nn as nn
#torchaudio是用来处理语音的如果我们在这里传入的图片大小是256x256,那数据处理最后我们图片要保证是256x256,否则我们后面神经网络一些数值也是需要修改的。
关于数据增强:缓解深度学习中数据不足的场景。
此外训练集如果对图片进行标准化或归一化,那测试集也必须进行标准化或者归一化
Normalize(0.485,0.456,0.406,0.229,0.224,0.225)图片标准化,第一个中括号里面是均值,第二个是标准差,标准化在tensor后 。标准化原因:如果图片亮度不同,像素矩阵值是差别很大的,标准化就是让他们值在固定的值范围内,真对rgb分别做归一化 #我们图片实际上是没有变多的,但因为我们多轮训练,每次图片随机改变是不一样的,所以达到了图片变多的效果。
数据增强方法还有:
- RandomRotation(45)随机旋转45度,
- RandomVerticalFlip#随机垂直翻转,
- RandomGrayscale(p=0.1)灰度率
python
'''数据预处理'''
data_transforms = {#字典,两个键值对
'train':
transforms.Compose([ # 数据增强
transforms.Resize([280, 280]), # 先把图片缩放到280x280
transforms.RandomCrop(256), # 随机裁剪到256x256
transforms.RandomHorizontalFlip(p=0.5), # 50%概率水平翻转
transforms.RandomVerticalFlip(p=0.5),
transforms.ColorJitter(brightness=0.1, contrast=0.1), # 调整亮度#,saturation=0.1,hue=0.1
transforms.ToTensor(), # 转成张量
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])#标准化
]),
'valid':
transforms.Compose([
transforms.Resize([256, 256]), # 测试时就直接缩放到256x256
transforms.ToTensor(), # 转成张量
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])
]),
}__getitem__内置的有特殊功能的函数,它赋予了对象索引访问和切片访问的能力。其实列表和字典等这种可以迭代的数据类型本身就属于一种类,他们利用的就是__getitem__这个方法实现可被索引的。
python
# 数据集,读取食物图片
class food_dataset(Dataset):#继承父类Datase
def __init__(self, file_path, transform=None): #类初始化,把需要的数据加载到self共享空间中
self.file_path = file_path#创建共享空间
self.imgs = []#存图片路径
self.labels = []#存图片的标签结果
self.transform = transform
with open(self.file_path) as f:
samples = [x.strip().split() for x in f.readlines()]
for img_path, label in samples:
self.imgs.append(img_path)
self.labels.append(label)
def __len__(self): # 返回数据集大小
return len(self.imgs)
def __getitem__(self, idx): #关键,通过索引获取每一个图片数据和标签
image = Image.open(self.imgs[idx])#读取到图片数据,还不是张量形式
if self.transform:#判断是否是pil图像数据转化为张量
image = self.transform(image)#图像处理为张量
label = self.labels[idx]#label还不是张量
label = int(label)
label = torch.from_numpy(np.array(label, dtype=np.int64))#label也转化为张量数据
return image, label#元祖形式返回dataloader,是一个类,对文件进行打包。
python
#训练集和预测集的路径,把数据做好准备
training_data = food_dataset(file_path=r'.\trainda.txt', transform=data_transforms['train'])
test_data = food_dataset(file_path=r'.\testda.txt', transform=data_transforms['valid'])
#打包数据,dataloader是一个类,这里这里只是把包存在类中
train_dataloader = DataLoader(training_data, batch_size=64, shuffle=True)#64个批次
#打包,负责发给gpu,一个包64张,无gpu这个数值要写小一点,图片也不是按照顺序取的
test_dataloader = DataLoader(test_data, batch_size=64, shuffle=True)输入图片256x256
python
# 自定义cnn模型
class CNN(nn.Module):
def __init__(self):
super(CNN, self).__init__()
self.conv1 = nn.Sequential(
nn.Conv2d(
in_channels=3,#图像通道数,1表示为灰度图
out_channels=16,#要得到多少个特征图,也就是卷积核的个数
kernel_size=5,#卷积核大小,5X5
stride=1,#步长为1
padding=2,#填充为2,输出特征图16*256*256
),
nn.ReLU(),#激活函数,矩阵中每个值做一个非线性映射,不改变还是16*256*256
nn.MaxPool2d(kernel_size=2),
#也有1d,3d的,对数据进行池化压缩,压缩一半,16*128*128
)
self.conv2 = nn.Sequential(#输入16*128*128
nn.Conv2d(16, 32, 5, 1, 2),#32*128*128
nn.ReLU(),
nn.Conv2d(32, 32, 5, 1, 2),#32*128*128
nn.ReLU(),
nn.MaxPool2d(2),#32*64*64
)
self.conv3 = nn.Sequential(#32*64*64
nn.Conv2d(32, 128, 5, 1, 2),#128*64*64
nn.ReLU(),
)
self.dropout = nn.Dropout(0.3)
self.out = nn.Linear(128 * 64 * 64, 20)#全连接,定义一个神经网络层,把数据展开为一维
def forward(self, x):#负责把模型串起来,真正的数据
x = self.conv1(x)
x = self.conv2(x)
x = self.conv3(x)
x = x.view(x.size(0), -1)#view改变维度,这里x.size(0)=64
output = self.out(x)#64*20个结果
return output这里我们卷积核大小,步长和填充设置为512是有原因的,512是一个很经典的设置组合
例如,输入数据为32x32x3的图像,用10个5x5x3的卷积核来进行操作,步长为1,边界0填充为2,最终输出结果为?
(32-5+2x2)/1+1=32,所以输出的特征图为10个32x32尺寸的(特征图个数就等于卷积核个数)
这里无论输入尺寸为多少,使用512设置,特征图的输出尺寸就和输入尺寸是一样的
python
# 设备设置和模型初始化
device = "cuda" if torch.cuda.is_available() else "mps" if torch.backends.mps.is_available() else 'cpu'
model = CNN().to(device)
print(model)
python
# 训练函数
def train(dataloader, model, loss_fn, optimizer):
model.train()
batch_size_num = 1 # 统计训练的batch数量
for X, y in dataloader:
X, y = X.to(device), y.to(device) # 把训练数据集和标签传入cpu或GPU
pred = model.forward(X) # 前向计算
loss = loss_fn(pred, y) # 计算损失
optimizer.zero_grad() # 梯度清零
loss.backward() # 反向传播
optimizer.step() # 更新参数
loss_value = loss.item()
if batch_size_num %1==0:
print(f"loss:{loss_value:>7f} [number:{batch_size_num}]")
batch_size_num += 1
#with open () as f:上下文管理器
# 测试函数
def test(dataloader, model, loss_fn):
size = len(dataloader.dataset)
num_batchs = len(dataloader)
model.eval()#w进入测试模式,没有再被修改的权限
test_loss, correct = 0, 0
with torch.no_grad():#上下文管理器,关闭梯度计算
for X, y in dataloader:
X, y = X.to(device), y.to(device)
pred = model.forward(X)
test_loss += loss_fn(pred, y).item() # test_loss是会自动累加每一个批次的损失值,不用累加,改一下!!!!!!!
correct += (pred.argmax(1) == y).type(torch.float).sum().item() # 标量
test_loss /= num_batchs
correct /= size
accuracy = 100 * correct
print(f"Test result: \n Accuracy :{(accuracy)}%,Avg loss:{test_loss}")
return accuracy
python
# 损失函数
loss_fn = nn.CrossEntropyLoss()
# 优化器
# optimizer = torch.optim.SGD(model.parameters(),lr=0.001)#尝试不同的值可以确保最后的准确率
optimizer = torch.optim.Adam(model.parameters(), lr=0.0001)
# train(train_dataloader, model, loss_fn, optimizer)
# current_acc = test(test_dataloader, model, loss_fn)
# 训练循环
best_acc = 0
epochs =20
for t in range(epochs):
print(f"Epoch{t + 1}\n------")
train(train_dataloader, model, loss_fn, optimizer)
current_acc = test(test_dataloader, model, loss_fn)
if current_acc > best_acc:
best_acc = current_acc
torch.save(model.state_dict(), 'cnn_best_model_da.pth')
print(f'cnn最佳模型:准确率{best_acc:.2f}%')
print("Dnoe!")
print(f'最佳模型:准确率{best_acc:.2f}%')6.getitem的演示
python
class USE_getitem():
def __init__(self,text):
self.text=text
def __getitem__(self, index):
result=self.text[index].upper()
return result
def __len__(self):
return len(self.text)
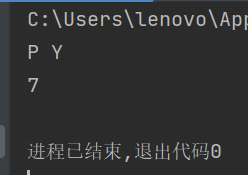
p= USE_getitem("pytorch")
print(p[0],p[1])
print(len(p))
python
class fun():
def __init__(self,text):
self.text=text
def __getitem__(self,index):
result=self.text[index]
return result
def __len__(self):
return len(self.text)
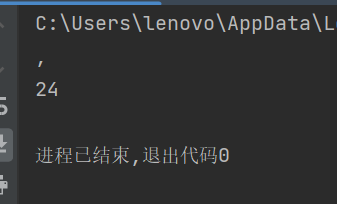
a=fun('1,2,3,4,5,20,30,40,50,60')
print(a[5])
print(len(a))