一、数据库连接优化
客户端连接到服务端,可能会出现服务端连接数不够,导致应用程序获取不到连接。
解决方案:
1、增加服务端的可用连接数
show variables like 'max_connections' ; --修改最大连接数,当有多个应用连接的时候
2、及时释放不活动的连接
交互式和非交互式的客户端,默认超时时间都是28800秒,8小时,可以缩小这个值:
show global variables like 'wait_timeout' ; --及时释放不活动的连接
3、连接池
如果不想每一次执行SQL都创建一个新连接,可以引入连接池,实现连接的重用。常见的数据库连接池有老牌的DBCP和C3P0、阿里的Druid、Hikari (Spring Boot 2.x版本默认的连接池)。
连接池并不是越大越好,只要维护一定数量大小的连接池,其他的客户端排队等待获取连接就可以了。有的时候连接池越大,效率反而越低。Druid的默认最大连接池大小是8。Hikari的默认最大连接池大小是10。
在Hikari的github文档中,给出了一个PostgreSQL数据库建议的设置连接池大小的公式。建议是机器核数乘以2加1。4核的机器,连接池维护9个连接就够了。这个公式从一定程度上来说对其他数据库也是适用的。
二、存储引擎和表结构优化
1、存储引擎的选择
为不同的业务表选择不同的存储引擎,例如:查询、插入操作多的业务表,用MylSAM。临时数据用Memeroy。常规的并发大、更新多的表用InnoDB。
2、分表与分区
交易历史表:在年底为下一年度建立12个分区,每个月一个分区。
渠道交易表:分成:当日表、当月表、历史表,历史表再做分区。
3、字段定义
- 整数类型:INT有6种类型,不同的类型的最大存储范围不同,占用的存储空间也不同。
- 字符类型:变长情况下,varchar更节省空间,但varchar字段需要一个字节来记录长度。比如:联系地址。固定长度用char,不要用varchar,比如:行政区划编码。
- 非空:非空字段尽量定义成 NOT NULL,提供默认值,或者使用特殊值、空串代替null。NULL类型的存储、优化、使用都存在问题。
- 不要用外键、触发器、视图:降低了可读性,影响数据库性能,应该把计算的事情交给程序,数据库专心做存储,数据的完整性应该在程序中检查。
- 大文件存储:不要用数据库存储图片(比如base64编码)或者大文件。把文件放在NAS上,数据库只需要存储 URI (相对路径),在应用中配置NAS服务器地址。
- 表拆分:将不常用的字段拆分出去,避免列数过多、数据量过大。
- 字段冗余:某些场景下使用一定的冗余来减少联表查询。
三、慢分析查询
1、打开慢分析日志
慢分析日志默认是关闭的,开启会带来一定的系统开销和资源消耗。
show variables like 'slow_query%';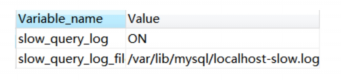
除了这个开关,还有一个参数,控制执行超过多长时间的SQL才记录到慢日志 ,默认是10秒。如果改成0秒的话就是记录所有的SQL。
show variables like 'long_query%';2、慢日志分析
(1)mysqldumpslow 查询慢SQL
MySQL提供了 mysqldumpslow 的工具,在MySQL的bin目录下:
mysqldumpslow --help例如:查询用时最多的10条慢SQL:
mysqldumpslow -s t -t 10 -g 'select' /var/lib/mysql/localhost-slow.log
- Count:这个SQL执行了多少次。
- Time:执行的时间,括号里面是累计时间。
- Lock:锁定的时间,括号是累计锁定时间。
- Rows:返回的记录数,括号是累计记录数。
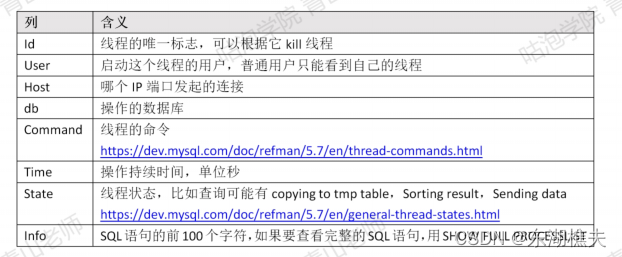
(2)show processlist 显示用户运行线程
show processlist 用于显示用户运行线程。可以根据id号kill线程:
show full processlist;也可以查表,效果一样:
select * from infbrmation schema.processlist;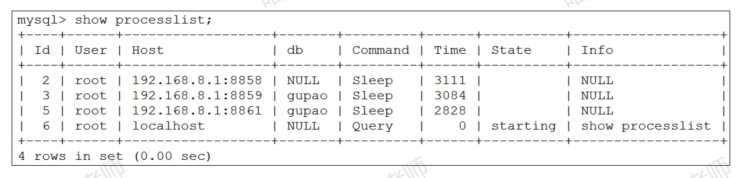
(3)show status 查看MySQL服务器运行状态
show status 用于查看MySQL服务器运行状态(重启后会清空):
SHOW GLOBAL STATUS;(4)show engine 显示存储引擎的当前运行信息
show engine用来显示存储引擎的当前运行信息,包括事务持有的表锁、行锁信息;事务的锁等待情况;线程信号量等待;文件IO请求;buffer pool统计信息。
show engine innodb status;(5)开启InnoDB标准监控和锁监控
set GLOBAL innodb_status_output = ON;
set GLOBAL innodb_status_output_locks = ON;很多开源的MySQL监控工具,原理都是读取服务器、操作系统、MySQL服务的状态和变量。
四、Explain执行计划
explain select (select 1 from actor where actor_id = 1) from
(select * from film where film_id = 1
union
select * from film where film_id = 1
) der;
1、select_type
- simple:简单查询。查询不包含子查询和union
- primary:复杂查询中最外层的 select,通常代表一个嵌套查询
- derived:包含在 from 子句中的子查询。MySQL会将结果存放在一个临时表中,也称为派生表(derived的英文含义)
- union:在 union 中的第二个和随后的 select
- union result:从 union 去重临时表检索结果的 select,union all 不会出现union result
- subquery:包含在 select 中的子查询(不在 from 子句中)
- id列没有值:代表是中间结果,采用Memory类型临时表处理
2、table
访问的表
3、partitions
查询作用在哪个分区表上,基本不用这个
4、type
从上往下,执行效率递减
- system:执行效率最高
- const:对查询的某部分进行优化并将其转化成一个常量。用于 primary key 或 unique key 的所有列与常数比较时,表最多有一个匹配行,读取1次,速度比较快
- eq_ref:primary key 或 unique key 索引的所有部分被连接使用 ,最多只会返回一条符合条件的记录。简单的 select 查询不会出现 eq_ref
- ref:相比eq_ref,不使用唯一索引,使用普通索引或者唯一性索引的部分前缀,索引要和某个值相比较,可能会找到多个符合条件的行。
- fulltext:全文检索
- ref_or_null:类似ref,但是可以搜索值为NULL的行。
- index_merge
- unique_subquery
- index_subquery
- range:范围扫描,通常出现在 in()、between 、> 、<、 >= 等操作中。使用一个索引来检索给定范围的行。
- index:和ALL一样,不同点是mysql只需扫描索引树,无需回表,通常比ALL快一些。
- ALL:全表扫描,意味着mysql需要从头到尾查找所需要的行。这种情况下需要增加索引来进行优化了。
5、possible_keys
查询时可能使用的索引
6、key
查询时实际使用的索引
7、key_len
索引里使用的字节数,通过这个值可以算出具体使用了索引中的哪些列。例如: key=PRIMARY, 主键类型为int ,长度为4,所以key_len=4
8、ref
在key列记录的索引中,表查找值所用到的列或常量,常见的有:const(常量),func,NULL,字段名(例:film.id)
9、rows
估计要读取并检测的行数,这个不是结果集里的行数。
10、filtered
一个百分比的值,代表 (rows * filtered) / 100,这个结果代表将于前表产生交互的数据量。
11、Extra
展示额外信息
- Distinct:一旦mysql找到了与行相联合匹配的行,就不再搜索了
- Using index:索引覆盖,查询列是索引列,返回的数据只是用了索引中的信息而没有回表,是性能高的表现
- Using index condition:使用索引来执行WHERE子句中的条件过滤,索引下推ICP
- MRR:Multi-Range Read,多块顺序读优化
- Using join buffer: 使用连接缓冲区来处理查询。连接缓冲区是一种内存结构,用于存储连接操作的中间结果,以便优化查询性能
- Using where:先读取整行数据,再按 where 条件进行检查,符合就留下,不符合就丢弃
- Using temporary:创建一张临时表来处理查询。出现这种情况一般是要进行优化的,首先是想到用索引来优化
- Using filesort:采用文件扫描对结果进行计算排序,效率很差