大型语言模型(入门篇)C
- 一、使用预训练大语言模型
-
- [1. 预训练模型](#1. 预训练模型)
- [2. 查找与选择大语言模型服务](#2. 查找与选择大语言模型服务)
- [3. 通过网页界面交互](#3. 通过网页界面交互)
- [4. LLM API使用简介](#4. LLM API使用简介)
一、使用预训练大语言模型
1. 预训练模型
预训练模型是大型语言模型(LLM)完成其训练阶段后的结果。
使用预训练模型的原因:
- 易得性: 它使得高级AI功能变得可用,而无需超级计算机或海量数据集。你可以直接使用大规模训练的成果,而无需自己进行训练。
- 即时可用: 你可以立即开始与模型交互并将其用于各种任务。你不需要自己制造引擎,可以直接开车。
- 内置功能: 这些模型自带在大量训练中学到的广泛语言理解和生成功能。它们通常可以开箱即用地出色完成翻译、摘要、问答和文本生成等任务。
2. 查找与选择大语言模型服务
预训练LLM的访问途径:
- 模型提供商直属平台: 许多开发大语言模型的机构都提供自己的平台。这些平台常包含用户友好的网页界面,有时称为"操场"或"工作室",您可以在其中直接在浏览器中输入提示并查看结果,无需编写任何代码。例子有OpenAI平台(提供GPT-4等模型的访问)、Google AI Studio(用于Gemini模型)、Anthropic的Console(用于Claude模型)以及Cohere平台。这些是极佳的起步地点,因为它们专为试用而设,并且常为新用户提供慷慨的免费层级或初始额度。
- 主要云服务提供商: 像亚马逊网络服务(AWS)、谷歌云平台(GCP)和微软Azure这样的公司,通过AWS Bedrock、Google Vertex AI和Azure AI服务(包括Azure OpenAI)等,提供各种大语言模型(包括它们自己的和第三方的模型)的访问。这些平台虽然功能强大且可扩展,但通常更侧重于开发应用程序的开发者,相比模型提供商直属平台的操场,起初的学习曲线可能稍陡。然而,它们是行业中的重要平台。
- 模型中心: 像Hugging Face这样的平台是数千个预训练模型的中心库,其中包括许多开放获取模型。Hugging Face不仅列出模型,还常提供工具、数据集,甚至托管的"空间"或"推理端点",您可以在其中试用模型,有时直接在浏览器中或通过简单的API调用。它是用于试用提供商所供模型的宝贵资源。
- 消费者应用程序: 您可能已经通过ChatGPT、Google Gemini(网页应用)或Claude的网页界面等流行应用程序接触过大语言模型。虽然这些主要是面向最终用户应用,但与它们交互是感受大语言模型功能的极佳方式。请记住,使用消费者应用程序不同于通过应用程序编程接口(API)使用底层模型服务,后者提供更多控制,也是构建应用程序时的重点。
3. 通过网页界面交互
LLM网页界面的常见功能:
虽然设计各不相同,但大多数用于与LLM交互的网页界面都有一些共同组成部分:
- 提示输入区: 这通常是一个文本框,您可以在其中输入对LLM的指令或问题。这是您向模型传达意图的主要方式。
- 提交/生成按钮: 在编写好提示后,您会点击一个按钮(通常标有"提交"、"生成"、"发送"或类似字样),将您的输入发送给模型。
- 回应显示区: 该部分显示LLM根据您的提示生成文本。有时文本会一次性出现,而其他界面可能会逐字或逐句显示,模拟对话。
- 对话历史(常见): 许多界面,特别是以聊天为中心的界面,会保留您当前交互的记录,显示您的提示和模型的回答。这有助于模型在一次会话中保持上下文。
- 可选控制项: 某些界面可能会提供基本控制项来调整模型表现,尽管这在最简单的实现中不太常见。您偶尔可能会看到以下选项:
a. 选择特定模型版本(如果提供商提供多个)。
b. 清除对话历史以重新开始。
c. 修改简单参数。
4. LLM API使用简介
API可以看作是不同软件程序之间相互通信的一种规范方式。你的程序可以直接向LLM服务提供商的系统发送请求,而非人工在网站上输入,随后该系统将会响应发回给你的程序。
相比网页界面,使用LLM API具有多项优势:
- 自动化: 可以编写脚本或程序来自动发送提示并处理响应。
- 整合: API能够将LLM能力直接嵌入到自己的软件中,可以构建聊天机器人,为文档编辑器添加智能摘要功能,或创建由LLM驱动的定制内容生成工具。
- 定制与控制: API通常比网页界面提供对大型语言模型行为更精细的控制,能够调整响应的创造性(常被称为temperature)、最大输出长度(max_tokens)等参数,以优化输出结果。
- 规模化: 如果你需要处理成百上千的提示,通过网页界面手动操作是不切实际的。API旨在以程序方式处理请求,使得大规模使用LLM成为可能。
1)API请求的组成部分
与LLM API进行的大多数交互都使用网络标准协议,特别是HTTP请求。一个典型请求包含以下几个部分:
-
端点URL: 发送请求的特定网址(URL)。每个LLM服务提供商都有自己的端点URL,用于不同的操作(例如生成文本);
-
HTTP方法: 告诉服务器你想执行什么操作,向LLM发送数据以获取响应时,方法几乎总是POST;
-
头部:
- Content-Type: 告诉服务器你在请求体中发送的数据格式,这通常是 application/json。
- Authorization: 提供你的凭据,通常是API密钥,以证明你有权限使用该服务。
-
正文: 包含你要发送的实际数据(提示词和任何控制LLM行为的参数),通常是JSON(JavaScript对象表示法)格式。
2)认证:API密钥
在发送请求之前,你总是需要一个API密钥,通常通过在LLM服务提供商处注册账户获得此密钥。API密钥通常包含在 Authorization 头部中。常见格式是 Bearer YOUR_API_KEY,其中 YOUR_API_KEY 替换为从提供商处获得的实际密钥。
3)构建请求正文(Payload)
请求正文是您放置LLM指令的地方,它是一个包含键值对的JSON对象。常见元素包括:
- prompt(字符串): 希望LLM处理或响应的文本输入;
- model(字符串): 指定你想使用的特定LLM(例如,example-model-v2 或 llama-3-8b-instruct);
- max_tokens(整数): 你希望生成响应包含的最大token数量(大致相当于单词或单词的一部分);
- temperature(浮点数,通常在0到1之间): 控制输出的随机性;
4)发送请求:使用curl的示例
curl 是一个用于通过URL传输数据的命令行工具,下面以千问为例展示如何发送上述请求:
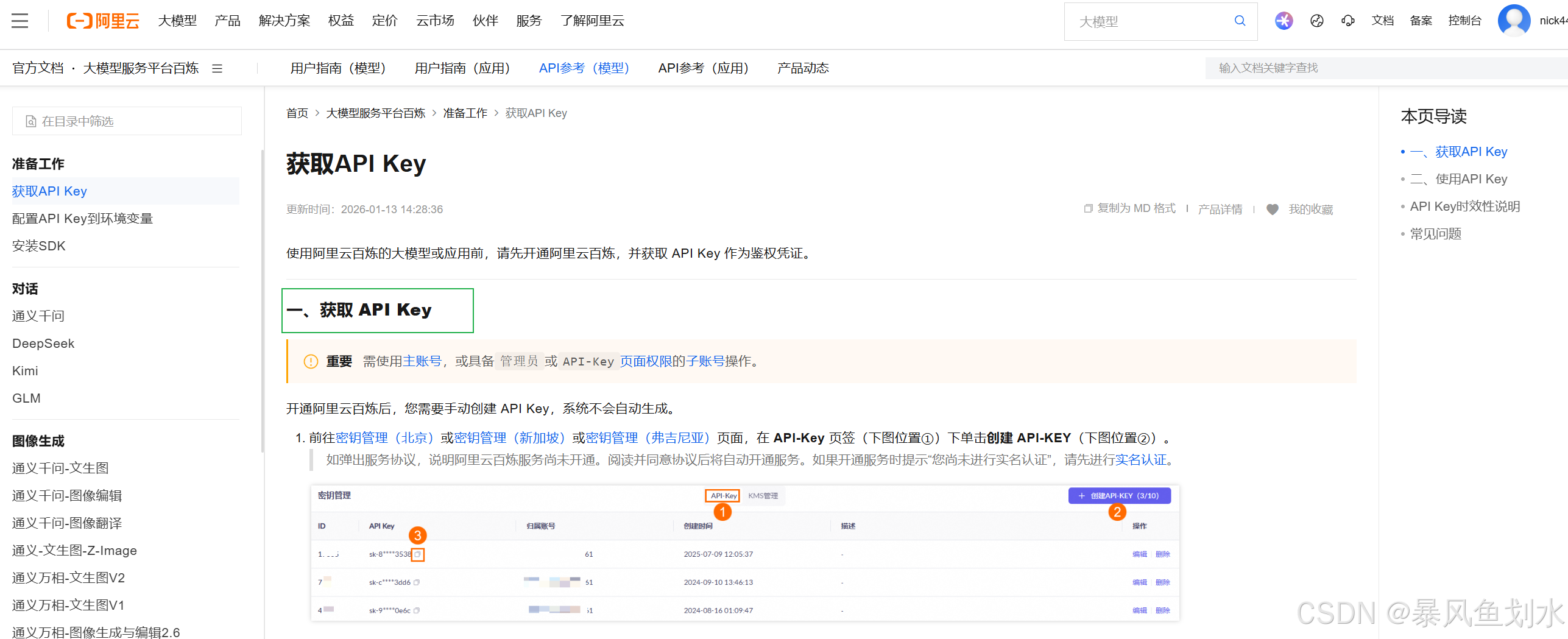
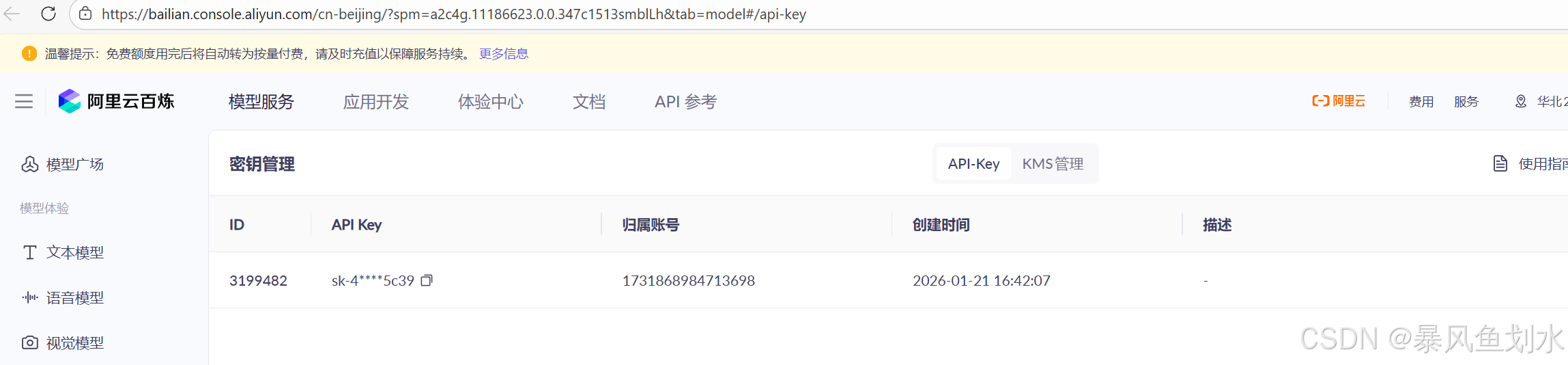
- 如下图所示首先获取API Key,
- 其次发送curl请求
bash
curl -i https://dashscope.aliyuncs.com/compatible-mode/v1/chat/completions \ #Base URL
-H "Content-Type: application/json" \
-H "Authorization: Bearer ${YOUR_API_KEY}" \ # 更换为你的API KEY
-d '{
"model": "qwen-plus", # 模型名称
"messages": [
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "Hello!"}
]
}'- 最后得到返回结果
bash
"content": "Hello! ٩(◕‿◕。)۶ How can I assist you today?"5)发送请求:使用Python的示例
在实际操作中,通常会在脚本或应用程序中进行API调用。Python的requests库是实现该方式的常用选择:
python
import os
import requests
API_KEY = os.getenv("DASHSCOPE_API_KEY", "sk-xxxxxxxxxxxxxxxxxxxx") # 此处记得换成你自己的API KEY
BASE_URL = "https://dashscope.aliyuncs.com/compatible-mode/v1"
URL = f"{BASE_URL}/chat/completions"
payload = {
"model": "qwen-plus",
"messages": [
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "Hello!"}
],
"stream": False
}
headers = {
"Content-Type": "application/json",
"Authorization": f"Bearer {API_KEY}",
}
resp = requests.post(URL, json=payload, headers=headers, timeout=60)
# 不是 200 就把错误信息打印出来
print("HTTP:", resp.status_code)
print("RAW :", resp.text)
resp.raise_for_status()
data = resp.json()
print("\nAssistant:", data["choices"][0]["message"]["content"])
print("Usage:", data.get("usage"))生产级封装(含超时、重试、错误信息打印,返回request-id):
python
import os
import time
import requests
from typing import List, Dict, Any, Optional
DASHSCOPE_BASE_URL = "https://dashscope.aliyuncs.com/compatible-mode/v1"
CHAT_URL = f"{DASHSCOPE_BASE_URL}/chat/completions"
class DashScopeError(RuntimeError):
pass
def chat_qwen(
messages: List[Dict[str, str]],
model: str = "qwen-plus",
api_key: Optional[str] = None,
timeout: int = 60,
max_retries: int = 3,
backoff_sec: float = 0.8,
extra: Optional[Dict[str, Any]] = None,
) -> Dict[str, Any]:
"""
Returns the raw JSON response (OpenAI-compatible).
"""
api_key = api_key or os.getenv("DASHSCOPE_API_KEY", "YOUR_API_KEY") # 此处替换为你的API KEY
if not api_key:
raise ValueError("Missing DASHSCOPE_API_KEY env var or api_key param.")
payload: Dict[str, Any] = {
"model": model,
"messages": messages,
"stream": False,
}
if extra:
payload.update(extra)
headers = {
"Content-Type": "application/json",
"Authorization": f"Bearer {api_key}",
}
last_err = None
for attempt in range(1, max_retries + 1):
try:
resp = requests.post(CHAT_URL, json=payload, headers=headers, timeout=timeout)
req_id = resp.headers.get("x-request-id")
# 非 2xx:尽量把服务端返回的错误 JSON 打出来
if not resp.ok:
try:
err_json = resp.json()
except Exception:
err_json = {"raw": resp.text}
raise DashScopeError(
f"HTTP {resp.status_code} | x-request-id={req_id} | error={err_json}"
)
data = resp.json()
data["_x_request_id"] = req_id
return data
except (requests.Timeout, requests.ConnectionError, DashScopeError) as e:
last_err = e
if attempt < max_retries:
time.sleep(backoff_sec * attempt)
continue
raise
# 理论上不会走到这里
raise DashScopeError(f"Failed after retries: {last_err}")
if __name__ == "__main__":
resp = chat_qwen(
messages=[
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "用一句话介绍新加坡。"},
],
extra={"max_tokens": 256, "temperature": 0.7},
)
print("x-request-id:", resp.get("_x_request_id"))
print("assistant:", resp["choices"][0]["message"]["content"])
print("usage:", resp.get("usage"))如果你想开启多轮对话,可以用下面的方式:
python
import os
import time
import requests
from typing import List, Dict, Any, Optional
BASE_URL = "https://dashscope.aliyuncs.com/compatible-mode/v1"
CHAT_URL = f"{BASE_URL}/chat/completions"
class DashScopeError(RuntimeError):
pass
def chat_once(
messages: List[Dict[str, str]],
model: str = "qwen-plus",
api_key: Optional[str] = None,
timeout: int = 60,
max_retries: int = 3,
backoff_sec: float = 0.8,
temperature: float = 0.7,
max_tokens: int = 512,
) -> Dict[str, Any]:
"""Send one chat completion request (non-stream) and return raw JSON response."""
api_key = api_key or os.getenv("DASHSCOPE_API_KEY", "${YOUR_API_KEY}") # 此处记得替换为你自己的API KEY
if not api_key:
raise ValueError("Missing DASHSCOPE_API_KEY env var or api_key param.")
payload: Dict[str, Any] = {
"model": model,
"messages": messages,
"stream": False,
"temperature": temperature,
"max_tokens": max_tokens,
}
headers = {
"Content-Type": "application/json",
"Authorization": f"Bearer {api_key}",
}
last_err = None
for attempt in range(1, max_retries + 1):
try:
resp = requests.post(CHAT_URL, json=payload, headers=headers, timeout=timeout)
req_id = resp.headers.get("x-request-id")
if not resp.ok:
# Try to parse error body as JSON for better diagnostics
try:
err_json = resp.json()
except Exception:
err_json = {"raw": resp.text}
raise DashScopeError(
f"HTTP {resp.status_code} | x-request-id={req_id} | error={err_json}"
)
data = resp.json()
data["_x_request_id"] = req_id
return data
except (requests.Timeout, requests.ConnectionError, DashScopeError) as e:
last_err = e
if attempt < max_retries:
time.sleep(backoff_sec * attempt)
continue
raise DashScopeError(f"Request failed after retries: {last_err}") from e
raise DashScopeError(f"Unexpected failure: {last_err}")
def run_multiturn_chat():
"""
Multi-turn chat demo:
- maintains conversation history (messages)
- user types input in a loop
- assistant replies using full history
- supports exit commands
"""
system_prompt = "You are a helpful assistant."
model = "qwen-plus"
messages: List[Dict[str, str]] = [{"role": "system", "content": system_prompt}]
print("✅ Qwen 多轮对话已启动。输入 /exit 或 /quit 退出;输入 /reset 清空上下文。\n")
while True:
user_text = input("You: ").strip()
if not user_text:
continue
# Commands
if user_text.lower() in {"/exit", "/quit"}:
print("Bye 👋")
break
if user_text.lower() == "/reset":
messages = [{"role": "system", "content": system_prompt}]
print("🔄 已清空上下文。\n")
continue
# Append user message to history
messages.append({"role": "user", "content": user_text})
# Call model with full history
try:
resp = chat_once(messages=messages, model=model)
except Exception as e:
print(f"❌ 请求失败:{e}\n")
# 如果失败了,为了不污染上下文,可以把刚刚那条 user 消息移除
messages.pop()
continue
assistant_msg = resp["choices"][0]["message"] # {"role": "assistant", "content": "..."}
messages.append(assistant_msg)
# Print assistant response
print(f"Assistant: {assistant_msg['content']}\n")
# Optional: print usage + request id for debugging/cost tracking
usage = resp.get("usage")
req_id = resp.get("_x_request_id")
if usage:
print(f" [usage] prompt={usage.get('prompt_tokens')} completion={usage.get('completion_tokens')} total={usage.get('total_tokens')}")
if req_id:
print(f" [x-request-id] {req_id}")
print()
if __name__ == "__main__":
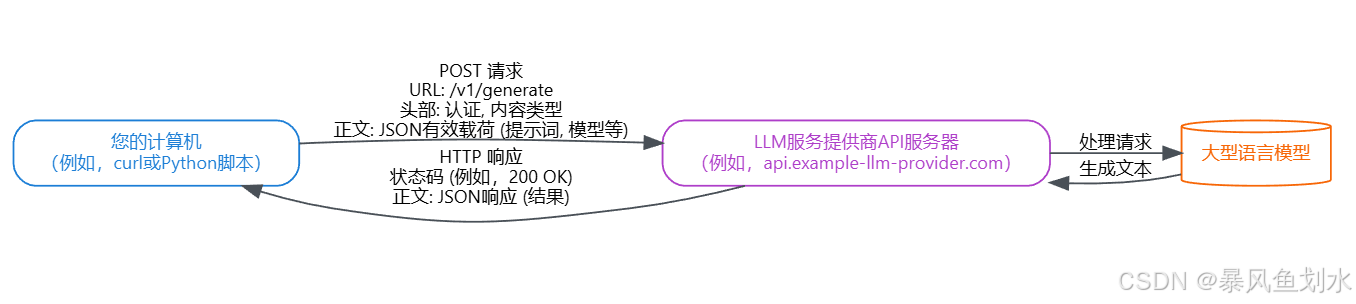
run_multiturn_chat()6)请求流程图
客户端向API服务器发送一个HTTP POST请求,其中包含必要的信息(URL、头部、正文),服务器验证请求,将指令传递给实际的LLM,接收生成的文本,并通过HTTP响应将其发送回客户端。