分词化(Tokenization )与词表映射
一、什么是分词化?
Tokenization 是 NLP 中将文本切分为最小处理单元(token)的过程,是所有语言模型的第一步。
🌰 示例:
- 原始句子:
I want to study ACA. - 分词后:
['I', 'want', 'to', 'study', 'ACA', '.']
二、三种主流分词粒度
| 类型 | 说明 | 适用场景 | 优点 | 缺点 |
|---|---|---|---|---|
| 词粒度(Word-Level) | 按完整单词切分 | 英文等空格分隔语言 | 精确、直观 | 词汇表大,无法处理未登录词(OOV) |
| 字符粒度(Character-Level) | 按单个字符切分 | 中文、日文等无空格语言 | 无需分词器,支持任意字符 | 信息冗余,序列过长 |
| 子词粒度(Subword-Level) | 按词根/前缀/后缀切分 | 多语言通用,尤其适合新词 | 平衡灵活性与效率,支持 OOV | 切分规则复杂(如 BPE、WordPiece) |
💡 当前主流大模型(如 GPT、BERT、Qwen)都使用 Subword-Level 分词(如 Byte Pair Encoding, BPE)。
三、词表映射(Token → ID)
- 每个 token 通过 预定义词表(Vocabulary) 映射为唯一的 token ID
- 例如:
'I'→40'ACA'→64938'.'→13
- 最终输入模型的是一个整数列表(ID 序列),而不是原始文本
✅ 这一步是 从自然语言到数学向量的桥梁
四、为什么需要分词化?
- 标准化输入:统一格式,便于模型处理
- 降低维度:避免直接处理海量字符
- 支持泛化:子词方法能处理新词(如 "AI"、"ChatGPT")
- 提升效率:减少训练和推理时间
五、常见分词算法
| 算法 | 特点 |
|---|---|
| BPE(Byte Pair Encoding) | 从字符开始,逐步合并常见字符对,形成子词 |
| WordPiece | Google 提出,类似 BPE,但优先选择概率更高的组合 |
| SentencePiece | 支持无空格语言(如中文),可同时处理中英文 |
🌐 Qwen、GPT、LLaMA 等模型均采用基于 BPE 或 WordPiece 的分词器。
六、图示解读
- 左侧:展示分词后的 token 列表
- 右侧:展示每个 token 对应的 ID(来自预训练词表)
- 关键点:同一个 token 在不同模型中可能对应不同 ID
✅ 总结:分词化的意义
分词化 = 把人类语言变成机器能理解的"数字代码"
它是 NLP 的"第一步",决定了模型能否准确理解文本。
大语言模型生成文本的过程
一、核心原理:自回归生成(Autoregressive Generation)
"一步一步来" ------ 每次只生成一个 token,将其加入上下文,再生成下一个。
✅ 流程图解:
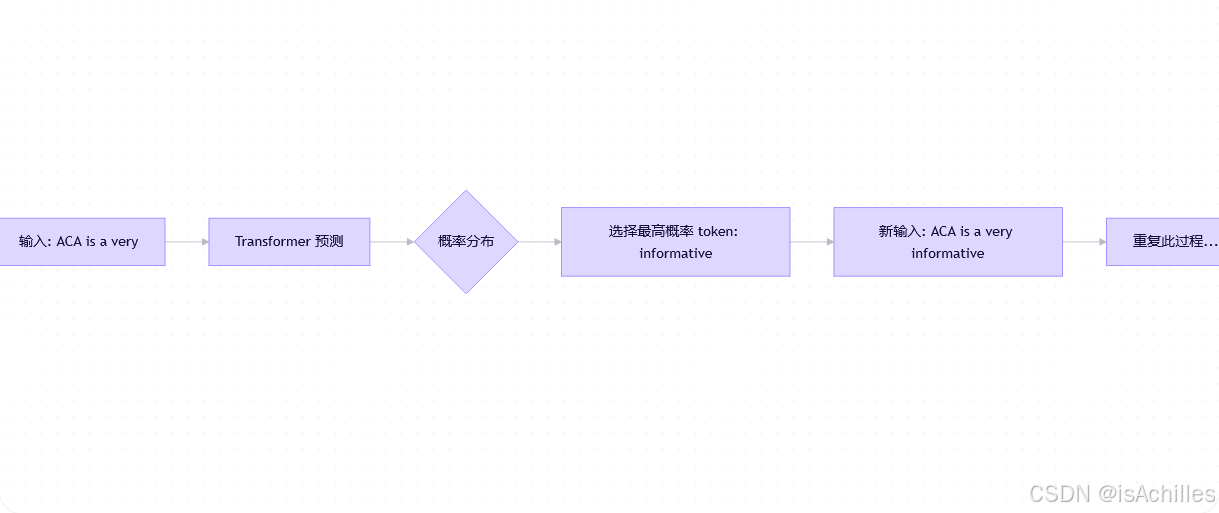
二、关键概念详解
| 概念 | 说明 |
|---|---|
| Token | 文本的基本单位(如单词、子词) |
| 概率分布 | 模型为每个可能的 next token 计算出现的概率 |
| 采样策略 | 如何从概率分布中选择 token: • 贪心搜索(Greedy Search)→ 总选最高概率 • 拓展采样(Sampling)→ 按概率随机选 • Top-k / Top-p(Nucleus Sampling)→ 限制候选范围 |
| (End of Sentence) | 特殊 token,表示句子结束,触发停止生成 |
| 最大长度(Max Length) | 设置输出的最大 token 数,防止无限生成 |
三、为什么叫"自回归"?
"自" = 自己;"回归" = 回溯
即:模型不断用自己之前生成的内容作为输入,来推断下一步。
✅ 类比:就像写作文,你先写一句,再根据这句话想下一句,一直写下去。
四、模型内部机制(以 Transformer 为例)
- 输入编码:将 token 转为 embedding 向量
- 位置编码:加入顺序信息(因为 Transformer 无顺序感知)
- 自注意力机制:关注所有历史 token 的相关性
- 输出层:生成每个 token 的概率分布
💡 这个过程在训练时也一样:模型学习"给定前面的词,下一个词是什么"。
五、实际应用中的控制参数
| 参数 | 作用 |
|---|---|
temperature |
控制随机性: • 低(0.1)→ 更确定,保守 • 高(1.0)→ 更创意,可能离谱 |
top_k |
仅从概率最高的 k 个 token 中采样 |
top_p |
累计概率超过 p 的 token 才参与采样(核采样) |
max_tokens |
最大生成长度 |
🛠 示例:
temperature=0.7, top_p=0.9是常见平衡设置
六、图示解读
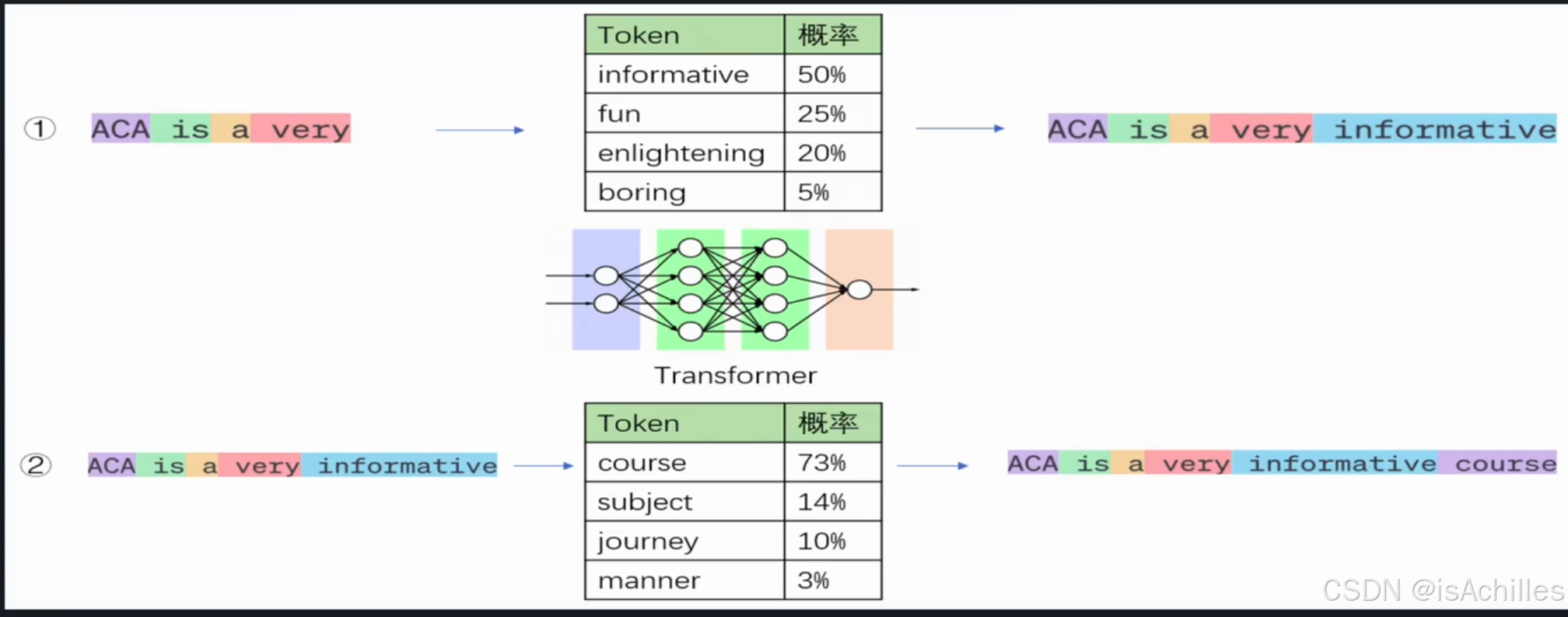
- 第一步 :模型看到
very,推测接下来可能是"informative"(50%),所以加进去。 - 第二步 :现在有
informative,推测接下来是"course"(73%),继续添加。 - 循环 :持续进行,直到遇到
<EOS>或长度超限。
✅ 总结:大语言模型是如何"思考"的?
大模型不是一次性生成整句话,而是像人一样"逐字思考" :
它不断地问:"在已有内容的基础上,下一个最可能的词是什么?"
然后一步步拼出完整的回答。