前面,我们经过学习string类的增删查改,对string进行深一步的了解,发现那我们的汉字是如何存储的呢?ASCII码表只对应英文和一些符号,这些英文、符号和数字一一对应映射。
编码
我们的汉字和符号在计算机中是不能直接存储在内存和硬盘中的,而是通过一个叫ASCII码表,在这个表中对应的值来表示数字、字母。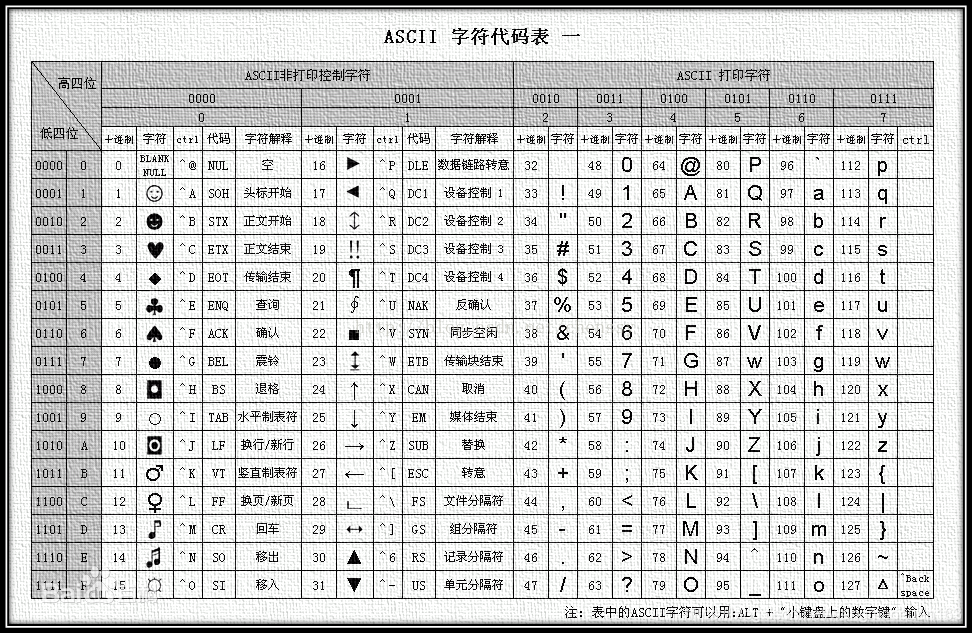
总而言之:编码就是值和符号的映射关系。
但是ASCII码表中不能存储汉字和其他文字,那这种时候,就出现了统一码(Unicode)。
Unicode 是一个字符集,给世界上所有字符(中文、英文、 emoji、特殊符号等)分配了一个唯一的数字编号(称为 "码点",如 U+4E2D 代表 "中")。
Unicode 只是 "字符 - 编号" 映射表,要在计算机中存储 / 传输,需要把码点转成二进制字节序列,常见实现方式有 3 种:
| 编码方式 | 特点 |
|---|---|
| UTF-8 | 变长编码(1-4 字节),兼容 ASCII |
| UTF-16 | 变长编码(2/4 字节) |
| UTF-32 | 固定 4 字节 |
我们在存储汉字或者其他国家文字的时候,可能需要2个字节存储一个汉字,也就是16个bit位。
cpp
string s("中国");
cout << "大小:" << s.size() << endl; // 输出4,而非2!乱码
为啥会出现乱码?
就像你用 "英语规则" 写了一张纸条,别人却用 "日语规则" 去解读,结果完全看不懂 ------ 二进制数据本身没有意义,只有用对应的编码规则解析,才能还原成正确的字符。
乱码的本质是 字符的编码规则与解码规则不匹配,或 二进制数据本身被破坏,导致无法正确还原字符。这种情况又可能是这个符号或文字在编码表中没有对应的值,或者是编码表不匹配(我们了解一下就好)
乱码的根源可以归结为 3 类核心问题:
规则错:编码和解码用了不同的映射表;
数据坏:多字节字符被截断、二进制被篡改;
表不全:编码表不支持目标字符。
string深浅拷贝
之前的实现string拷贝构造,在写法上很传统,这里有一些更方便的写法,相当于你当了一回资本家。具体怎么写呢?
代码如下:
这是我们传统写法,需要我们自己手动开空间,在拷贝值。赋值同理
cpp
string(const char* str = "")
{
_size = strlen(str);
_capacity = _size;
_str = new char[_capacity + 1];
strcpy(_str, str);
}
string(const string& s)
{
_str = new char[s.capacity()+1];
strcpy(_str,s._str);
_capacity = s.capacity();
_size = s.size();
}
string& operator=(const string& s)
{
if (this != &s)
{
delete[]_str;
_str = new char[s.capacity()+1];
strcpy(_str, s._str);
_capacity = s.capacity();
_size = s.size();
}新的写法是我们通过一个临时变量赋值,在和临时变量 交换数据就可以,具体就像三个数交换一样。等于说,你找了一个"仆人",帮你干活,完事之后,干活的钱还在你的手中。
cpp
String(const char* str = "")
{
_size = strlen(str);
_capacity = _size;
_str = new char[_capacity + 1];
strcpy(_str, str);
}
void swap(String& s)
{
std::swap(_str, s._str);
std::swap(_size, s._size);
std::swap(_capacity, s._capacity);
}
String(const string& s)
{
String tmp(s);
swap(tmp);
}
String& operator=(const string& s)
{
String tmp(s);
swap(tmp);
return *this;
}
~String()
{
if (_str != nullptr)
{
delete[] _str;
_str = nullptr;
_size = 0;
_capacity = 0;
}
}
const char* c_str()const
{
return _str;
}
private:
char* _str=nullptr;
size_t _size=0;
size_t _capacity=0;
};这种写法是不是感觉更方便了,效率上和传统写法一致。只是写法上不同而已。
引用计数和写时拷贝
我们先浅浅了解一下就好。
写时拷贝就是一种拖延症,是在浅拷贝的基础之上增加了引用计数的方式来实现的。
引用计数:用来记录资源使用者的个数。在构造时,将资源的计数给成1,每增加一个对象使用该资源,就给计数增加1,当某个对象被销毁时,先给该计数减1,然后再检查是否需要释放资源,如果计数为1,说明该对象时资源的最后一个使用者,将该资源释放;否则就不能释放,因为还有其他对象在使用该资源。