1.算法解析
1.1 算法概念
布隆过滤器可以看作是位数组和多个哈希函数共同组成的数据结构,相较于我们平时使用的List,Map,Set等数据结构,它的占用空间更小,查找效率更高。但是因为哈希函数的使用,其映射过程可能存在哈希冲突,导致查询结果并不准确,理论上,集合中的元素越多,误报的可能性就越大。并且布隆过滤器的元素不可被删除。
布隆过滤器会用一个比较大的bit数组来存所有的数据,数组中的每个元素大小为1bit,每个元素只能代表0或1,因此,布隆过滤器能极大地节省内存。这样算来,存100万个元素的位数组只占用 1000000Bit / 8 = 125000 Byte = 125000/1024 KB ≈ 122KB 的空间。
**总结:**一个名叫 Bloom 的人提出了一种来检索元素是否在给定大集合中的数据结构,这种数据结构是高效且性能很好的,但缺点是具有一定的错误识别率和删除难度。并且,理论情况下,添加到集合中的元素越多,误报的可能性就越大。
1.2 算法原理
当一个元素加入布隆过滤器中的时候,会进行如下操作:
- 使用布隆过滤器中的哈希函数对元素值进行计算,得到哈希值(有几个哈希函数得到几个哈希值)。
- 根据得到的哈希值,在位数组中把对应下标的值置为 1。
当我们需要判断一个元素是否存在于布隆过滤器的时候,会进行如下操作:
- 对给定元素再次进行相同的哈希计算;
- 得到值之后判断位数组中的每个元素是否都为 1,如果值都为 1,那么说明这个值在布隆过滤器中,如果存在一个值不为 1,说明该元素不在布隆过滤器中。
Bloom Filter 的简单原理图如下:
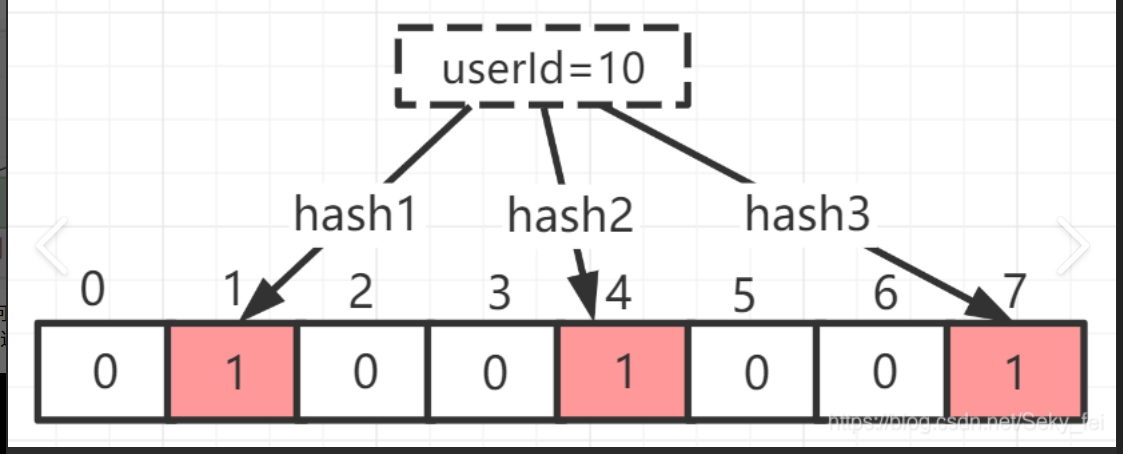
如图所示,当字符串存储要加入到布隆过滤器中时,该字符串首先由多个哈希函数生成不同的哈希值,然后将对应的位数组的下标设置为 1(当位数组初始化时,所有位置均为 0)。当第二次存储相同字符串时,因为先前的对应位置已设置为 1,所以很容易知道此值已经存在(去重非常方便)。
如果我们需要判断某个字符串是否在布隆过滤器中时,只需要对给定字符串再次进行相同的哈希计算,得到值之后判断位数组中的每个元素是否都为 1,如果值都为 1,那么说明这个值在布隆过滤器中,如果存在一个值不为 1,说明该元素不在布隆过滤器中。
不同的字符串可能哈希出来的位置相同,这种情况我们可以适当增加位数组大小或者调整我们的哈希函数。
综上,我们可以得出:布隆过滤器说某个元素存在,小概率会误判。布隆过滤器说某个元素不在,那么这个元素一定不在。
1.3 算法应用
- 判断给定数据是否存在:比如判断一个数字是否存在于包含大量数字的数字集中(数字集很大,上亿)、 防止缓存穿透(判断请求的数据是否有效避免直接绕过缓存请求数据库)等等、邮箱的垃圾邮件过滤(判断一个邮件地址是否在垃圾邮件列表中)、黑名单功能(判断一个 IP 地址或手机号码是否在黑名单中)等等。
- 去重:比如爬给定网址的时候对已经爬取过的 URL 去重、对巨量的 QQ 号/订单号去重。
去重场景也需要用到判断给定数据是否存在,因此布隆过滤器主要是为了解决海量数据的存在性问题。
2.GuavaCache中的BloomFilter
自己实现的目的主要是为了让自己搞懂布隆过滤器的原理,Guava 中布隆过滤器的实现算是比较权威的,所以实际项目中我们不需要手动实现一个布隆过滤器。
首先我们需要在项目中引入 Guava 的依赖:
XML
<dependency>
<groupId>com.google.guava</groupId>
<artifactId>guava</artifactId>
<version>28.0-jre</version>
</dependency>实际使用如下:
我们创建了一个最多存放 最多 1500 个整数的布隆过滤器,并且我们可以容忍误判的概率为百分之(0.01)
java
// 创建布隆过滤器对象
BloomFilter<Integer> filter = BloomFilter.create(
Funnels.integerFunnel(),
1500,
0.01);
// 判断指定元素是否存在
System.out.println(filter.mightContain(1));
System.out.println(filter.mightContain(2));
// 将元素添加进布隆过滤器
filter.put(1);
filter.put(2);
System.out.println(filter.mightContain(1));
System.out.println(filter.mightContain(2));在我们的示例中,当 mightContain() 方法返回 true 时,我们可以 99%确定该元素在过滤器中,当过滤器返回 false 时,我们可以 100%确定该元素不存在于过滤器中。
Guava 提供的布隆过滤器的实现还是很不错的(想要详细了解的可以看一下它的源码实现),但是它有一个重大的缺陷就是只能单机使用(另外,容量扩展也不容易),而现在互联网一般都是分布式的场景。为了解决这个问题,我们就需要用到 Redis 中的布隆过滤器了。
3.基于Redis的BitMap整合BloomFilter
java
package com.lgh.web.manager.bloomFilter;
import org.springframework.data.redis.core.StringRedisTemplate;
import org.springframework.stereotype.Component;
import org.springframework.util.Assert;
import java.nio.charset.StandardCharsets;
import java.security.MessageDigest;
import java.security.NoSuchAlgorithmException;
import java.util.Arrays;
import java.util.List;
/**
* 布隆过滤器帮助类,用于生成哈希值和判断元素是否存在于布隆过滤器中
* @Author GuihaoLv
*/
@Component
public class BloomFilterHelper<T> {
// 默认误判率:1%,是平衡空间和误判率的常用值
private static final double DEFAULT_FPP = 0.01;
// 默认预计数据量:100万条,适配初期业务规模
private static final long DEFAULT_EXPECTED_NUM = 1_000_000L;
// 哈希函数的种子集合:多个质数,保证哈希值分布均匀,减少冲突
private static final List<Integer> SEEDS = Arrays.asList(3, 5, 7, 11, 13, 31, 37, 61);
private final int numHashFunctions;//哈希函数个数
private final long bitSize;//位图大小
//无参构造 :默认预计数据量100万条,误判率1%
public BloomFilterHelper() {
this(DEFAULT_EXPECTED_NUM, DEFAULT_FPP);
}
// 有参构造:自定义预计数据量和误判率,计算核心参数
public BloomFilterHelper(long expectedNum, double fpp) {
// 参数校验:避免非法输入导致公式计算出错
Assert.isTrue(expectedNum > 0, "预计数据量必须大于0");
Assert.isTrue(fpp > 0 && fpp < 1, "误判率必须在(0,1)之间");
// 计算位图大小
this.bitSize = optimalNumOfBits(expectedNum, fpp);
// 计算哈希函数个数
this.numHashFunctions = optimalNumOfHashFunctions(expectedNum, this.bitSize);
}
//位图大小计算
private long optimalNumOfBits(long n, double p) {
if (p == 0) {
p = Double.MIN_VALUE; // 避免除以0
}
// 核心公式:m = -n * ln(p) / (ln(2))²
return (long) (-n * Math.log(p) / (Math.log(2) * Math.log(2)));
}
//哈希函数个数计算
private int optimalNumOfHashFunctions(long n, long m) {
// 核心公式:k = (m/n) * ln(2),取最大值至少为1
return Math.max(1, (int) Math.round((double) m / n * Math.log(2)));
}
//添加元素
public void add(StringRedisTemplate redisTemplate, String key, T value) {
// 参数校验:避免空值导致哈希计算出错
Assert.notNull(value, "元素不能为null");
// 1. 计算元素的所有哈希偏移量
long[] offsets = getOffsets(value.toString());
// 2. 遍历所有偏移量,将Redis Bitmap对应位置置为1
for (long offset : offsets) {
redisTemplate.opsForValue().setBit(key, offset, true);
}
}
// 判断元素是否存在
public boolean contains(StringRedisTemplate redisTemplate, String key, T value) {
if (value == null) {
return false;
}
// 1. 计算元素的所有哈希偏移量
long[] offsets = getOffsets(value.toString());
// 2. 遍历所有偏移量:只要有一个位置为0,元素一定不存在
for (long offset : offsets) {
if (!redisTemplate.opsForValue().getBit(key, offset)) {
return false;
}
}
// 3. 所有位置都为1,元素可能存在
return true;
}
// 计算所有哈希偏移量
private long[] getOffsets(String value) {
// 初始化偏移量数组,长度=最优哈希函数个数
long[] offsets = new long[numHashFunctions];
for (int i = 0; i < numHashFunctions; i++) {
// 循环取种子(避免种子数量不足)
int seed = SEEDS.get(i % SEEDS.size());
// 计算哈希值,并对bitmap大小取模,得到偏移量
offsets[i] = hash(value, seed) % bitSize;
}
return offsets;
}
//单个哈希函数实现
private long hash(String value, int seed) {
try {
// 使用MD5哈希算法(稳定性高、分布均匀)
MessageDigest md = MessageDigest.getInstance("MD5");
// 种子+元素拼接后计算哈希:保证不同种子生成不同哈希值
md.update((seed + value).getBytes(StandardCharsets.UTF_8));
byte[] digest = md.digest();
// 将MD5的16字节结果转为长整型(取前8字节)
long hash = 0;
for (int i = 0; i < 8; i++) {
hash |= ((long) (digest[i] & 0xFF)) << (i * 8);
}
// 取绝对值:避免负偏移量
return Math.abs(hash);
} catch (NoSuchAlgorithmException e) {
throw new RuntimeException("MD5哈希算法不可用", e);
}
}
}4.BloomFilter的一个实战优化案例
4.1 问题背景
设计一个点赞操作的架构,关键在于判断是否赞过,执行点赞/取消点赞操作以及统计点赞数量。
原始方案:
java
/**
* 判断是否点赞
* @param blogId
* @return
*/
public Boolean isLiked(Long blogId) {
Long userId=UserUtil.getUserId();
Boolean flag=blogMapper.isLiked(userId,blogId);
return flag;
}
/**
* 点赞或取消点赞
* @param blogId
* @return
*/
@Transactional
public Boolean like(Long blogId) {
Long userId=UserUtil.getUserId();
Boolean flag=blogMapper.isLiked(userId,blogId);
Boolean result1=false;
Boolean result2=false;
if(flag){
//取消点赞
result1=blogMapper.unlike(blogId);
result2=blogMapper.deleteLike(blogId,userId);
} else {
//点赞
result1=blogMapper.like(blogId);
result2=blogMapper.addLike(blogId,userId);
}
return result1&&result2;
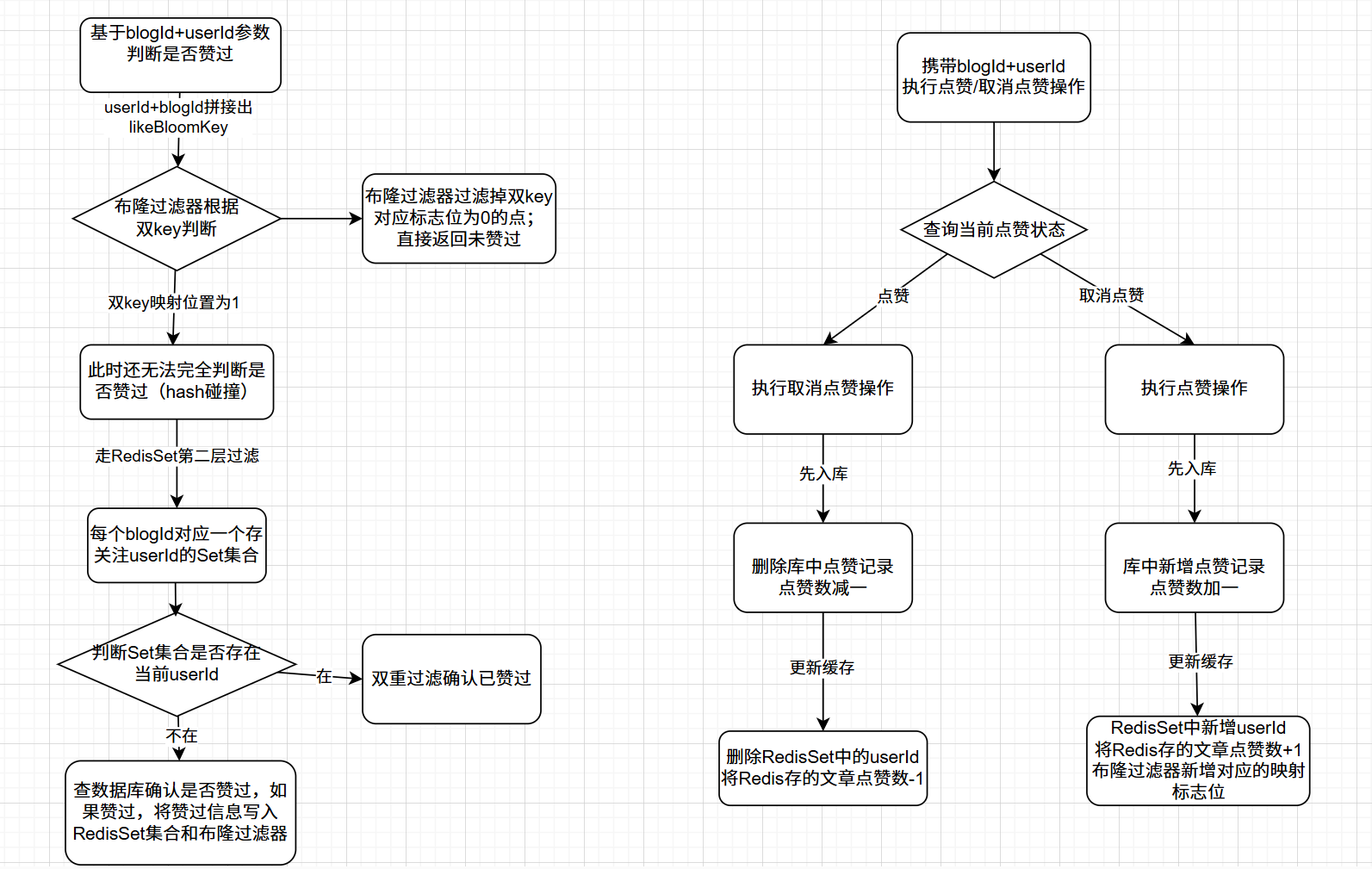
}4.2 优化思路
4.3 代码实现
java
/**
* 判断是否点赞(核心:Redis优先)
* @param blogId
* @return
*/
public Boolean isLiked(Long blogId) {
Long userId = UserUtil.getUserId();
String likeBloomKey = userId + ":" + blogId;
// 1. 布隆过滤器第一层过滤:一定不存在直接返回false
if (!bloomFilterHelper.contains(stringRedisTemplate, RedisKeyConstant.BLOOM_FILTER_LIKE_KEY, likeBloomKey)) {
return false;
}
// 2. Redis Set第二层过滤:存在则返回true
String likeSetKey = String.format(RedisKeyConstant.BLOG_LIKE_SET_KEY, blogId);
Boolean isMember = stringRedisTemplate.opsForSet().isMember(likeSetKey, userId.toString());
if (Boolean.TRUE.equals(isMember)) {
return true;
}
// 3. MySQL兜底查询(极少走到这一步)
Boolean flag = blogMapper.isLiked(userId, blogId);
// 补偿写入Redis:避免下次再查MySQL
if (Boolean.TRUE.equals(flag)) {
stringRedisTemplate.opsForSet().add(likeSetKey, userId.toString());
bloomFilterHelper.add(stringRedisTemplate, RedisKeyConstant.BLOOM_FILTER_LIKE_KEY, likeBloomKey);
}
return flag;
}
// ====================== 点赞/取消点赞(核心:先更库,再更缓存) ======================
@Transactional(rollbackFor = Exception.class)
public Boolean like(Long blogId) {
Long userId = UserUtil.getUserId();
String likeBloomKey = userId + ":" + blogId;
String likeSetKey = String.format(RedisKeyConstant.BLOG_LIKE_SET_KEY, blogId);
String likeCountKey = String.format(RedisKeyConstant.BLOG_LIKE_COUNT_KEY, blogId);
// 1. 查询当前点赞状态
Boolean isLiked = isLiked(blogId);
Boolean result1 = false;
Boolean result2 = false;
if (isLiked) {
// 2. 取消点赞:先更库
result1 = blogMapper.unlike(blogId);
result2 = blogMapper.deleteLike(blogId, userId);
if (result1 && result2) {
// 3. 再更缓存:删除Set中的用户ID + 递减点赞数
stringRedisTemplate.opsForSet().remove(likeSetKey, userId.toString());
stringRedisTemplate.opsForValue().decrement(likeCountKey);
}
} else {
// 2. 点赞:先更库
result1 = blogMapper.like(blogId);
result2 = blogMapper.addLike(blogId, userId);
if (result1 && result2) {
// 3. 再更缓存:添加Set + 递增点赞数 + 更新布隆
stringRedisTemplate.opsForSet().add(likeSetKey, userId.toString());
stringRedisTemplate.opsForValue().increment(likeCountKey);
bloomFilterHelper.add(stringRedisTemplate, RedisKeyConstant.BLOOM_FILTER_LIKE_KEY, likeBloomKey);
}
}
return result1 && result2;
}
// ====================== 查询帖子点赞数(核心:Redis优先) ======================
public Integer getLikedCount(Long blogId) {
String likeCountKey = String.format(RedisKeyConstant.BLOG_LIKE_COUNT_KEY, blogId);
// 1. 先查Redis
String countStr = stringRedisTemplate.opsForValue().get(likeCountKey);
if (countStr != null) {
return Integer.parseInt(countStr);
}
// 2. Redis未命中,查MySQL兜底
Integer count = blogMapper.getLikedCount(blogId);
if (count == null) {
count = 0;
}
// 3. 补偿写入Redis
stringRedisTemplate.opsForValue().set(likeCountKey, count.toString());
return count;
}