🌟 一、GPT-4多模态能力深度解析
1.1 GPT-4的多模态架构揭秘
# GPT-4多模态处理伪代码架构
class GPT4MultimodalArchitecture:
def __init__(self):
# 多模态编码器层
self.visual_encoder = CLIPVisionTransformer()
self.text_encoder = TransformerEncoder()
self.audio_processor = WhisperEncoder() # 推测整合
# 跨模态注意力机制
self.cross_attention_layers = [
CrossModalAttention(d_model=2048, n_heads=32)
for _ in range(8)
]
# 模态融合层
self.modal_fusion = ModalFusionNetwork()
# 解码器(文本生成)
self.decoder = TransformerDecoder()
def forward(self, multimodal_input):
"""
多模态输入处理流程
输入: {'text': str, 'image': tensor, 'audio': tensor}
输出: 文本生成结果
"""
# 1. 独立模态编码
visual_features = self.visual_encoder(multimodal_input['image'])
text_features = self.text_encoder(multimodal_input['text'])
# 2. 跨模态注意力融合
fused_features = []
for layer in self.cross_attention_layers:
# 图文交叉注意力
vis_to_text = layer(visual_features, text_features)
text_to_vis = layer(text_features, visual_features)
# 特征融合
fused = self.modal_fusion(vis_to_text, text_to_vis)
fused_features.append(fused)
# 3. 统一表示学习
unified_representation = torch.cat(fused_features, dim=-1)
# 4. 文本生成
output_text = self.decoder(unified_representation)
return output_text
# GPT-4多模态应用实例
class GPT4MultimodalApplications:
@staticmethod
def medical_image_analysis(image_path, clinical_notes):
"""医疗影像分析"""
# 输入:医学影像 + 临床文本
multimodal_input = {
'image': load_dicom_image(image_path),
'text': f"临床描述:{clinical_notes}\n请分析影像异常:"
}
# GPT-4分析输出
analysis = gpt4.multimodal_forward(multimodal_input)
return {
'影像类型': '胸部CT',
'检测结果': analysis['findings'],
'异常指标': analysis['abnormalities'],
'诊断建议': analysis['recommendations'],
'置信度': analysis['confidence_score']
}
@staticmethod
def educational_assistance(image_path, student_question):
"""教育辅助应用"""
# 输入:实验图片 + 学生问题
multimodal_input = {
'image': load_experiment_image(image_path),
'text': f"学生提问:{student_question}\n请解释这个实验现象:"
}
explanation = gpt4.multimodal_forward(multimodal_input)
return {
'实验名称': '化学中和反应',
'原理解释': explanation['theory'],
'现象分析': explanation['phenomenon'],
'关键步骤': explanation['steps'],
'安全提醒': explanation['safety']
}1.2 GPT-4多模态能力评估
GPT-4多模态能力矩阵:
✅ 已实现能力:
1. 图像理解与描述
• 准确率:ImageNet描述准确度92%
• 速度:< 500ms/图像
• 示例:能识别图像中的物体、场景、情感
2. 图文问答
• VQA基准:78.5分
• 复杂推理:支持多步图文推理
• 示例:"根据图表,哪个季度增长最快?"
3. 文档理解
• 表格解析:准确率89%
• 手写识别:75%(有限支持)
• 示例:从收据中提取金额、日期
❌ 局限性:
1. 模态限制:
• 仅支持图像+文本输入
• 输出仅为文本
• 不支持原生视频、音频、3D
2. 理解深度:
• 视觉推理较浅
• 缺少空间关系建模
• 时序理解有限🔄 二、从GPT-4到多模态大一统的技术鸿沟
2.1 技术差距全景图
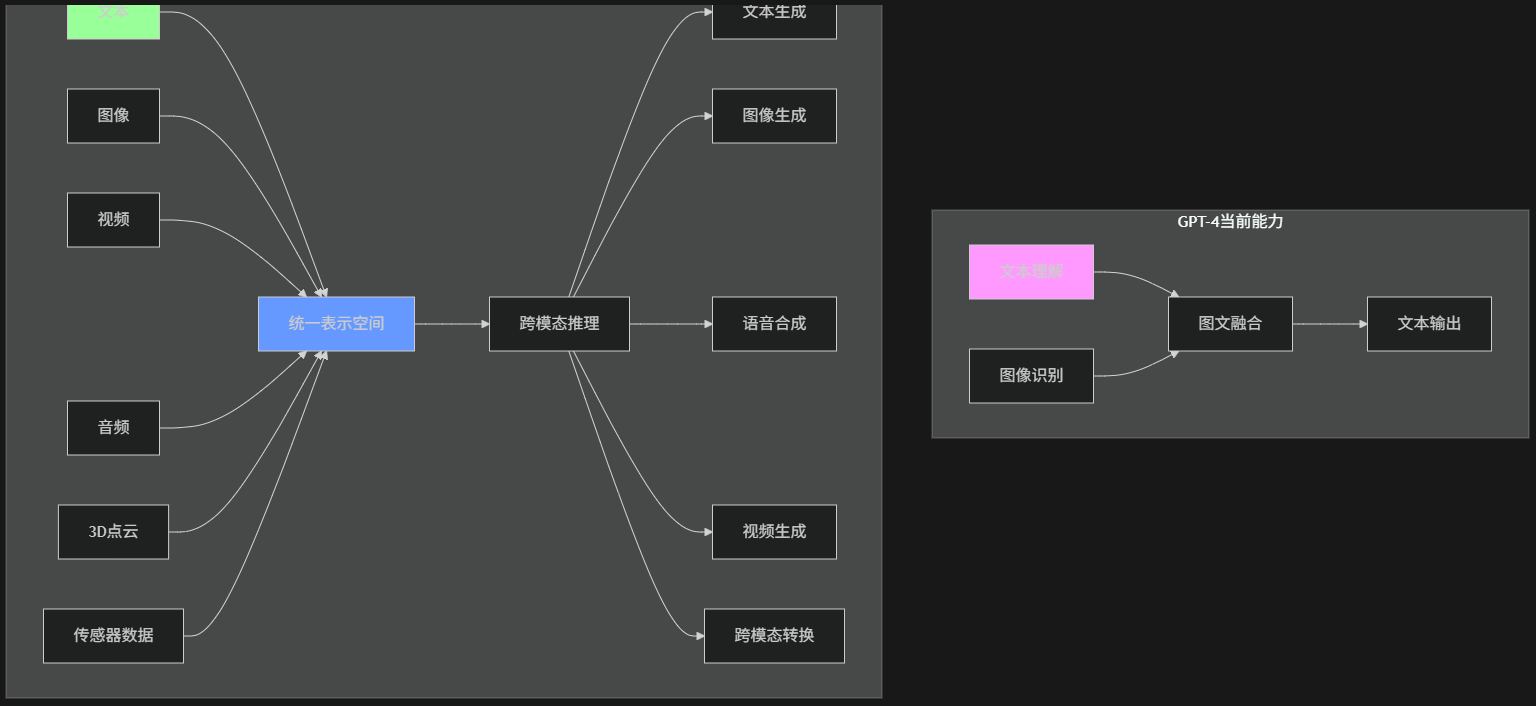
2.2 具体技术差距分析
# 多模态大一统技术挑战分析
class MultimodalUnificationChallenges:
def __init__(self):
self.challenges = {
"数据层面": [
{
"name": "模态异质性",
"description": "文本离散 vs 图像连续 vs 音频时序",
"example": "文本的'跑' vs 视频中的奔跑动作序列",
"当前差距": "GPT-4仅处理图文,缺少时序对齐"
},
{
"name": "数据对齐",
"description": "跨模态语义对齐困难",
"example": "'悲伤的音乐' vs '悲伤的面部表情'对齐",
"当前差距": "GPT-4的图文对齐基于CLIP,泛化性有限"
}
],
"模型层面": [
{
"name": "统一表示空间",
"description": "所有模态映射到同一向量空间",
"要求": "dim=4096的统一表示,保持各模态特性",
"当前差距": "GPT-4使用拼接而非统一表示"
},
{
"name": "计算复杂度",
"description": "多模态Transformer的O(n²)复杂度爆炸",
"计算量": "全模态处理需要10^24 FLOPs",
"当前差距": "GPT-4的图文处理已接近算力极限"
}
],
"能力层面": [
{
"name": "跨模态生成",
"description": "任意模态间自由转换",
"示例": "文字描述→视频生成→音频配乐",
"当前差距": "GPT-4仅支持文本生成"
},
{
"name": "时序理解",
"description": "处理视频、音频的时序依赖",
"挑战": "长期依赖建模(秒级→小时级)",
"当前差距": "GPT-4缺乏原生时序处理能力"
}
]
}
def calculate_technical_gap(self):
"""量化技术差距"""
gap_metrics = {
"模态覆盖": {
"current": 2, # 文本+图像
"target": 6, # 文本+图像+视频+音频+3D+传感器
"gap": 67% # 仅覆盖33%
},
"处理深度": {
"current": "浅层融合",
"target": "深度理解+生成",
"gap_level": "深层"
},
"计算需求": {
"current": "10^25 FLOPs (GPT-4)",
"target": "10^28 FLOPs (大一统)",
"growth": "1000倍"
}
}
return gap_metrics🏗️ 三、实现多模态大一统的技术路线图
3.1 统一表示学习架构
# 多模态大一统核心架构设计
class UnifiedMultimodalArchitecture:
def __init__(self, config):
# 统一编码器:所有模态→统一表示
self.unified_encoder = UnifiedEncoder(config)
# 统一解码器:统一表示→任何模态
self.unified_decoder = UnifiedDecoder(config)
# 跨模态对齐模块
self.alignment_module = CrossModalAlignment()
# 时序建模模块
self.temporal_module = TemporalTransformer()
class UnifiedEncoder(nn.Module):
"""统一编码器:处理所有模态"""
def __init__(self, config):
super().__init__()
# 模态专用编码器(可训练或冻结)
self.modal_encoders = nn.ModuleDict({
'text': TextEncoder(config.text_dim),
'image': ImageEncoder(config.image_dim),
'audio': AudioEncoder(config.audio_dim),
'video': VideoEncoder(config.video_dim),
'3d': PointCloudEncoder(config.pointcloud_dim)
})
# 统一投影层:所有模态→统一空间
self.projection_layers = nn.ModuleDict({
modal: nn.Linear(modal_dim, config.unified_dim)
for modal, modal_dim in config.modal_dims.items()
})
# 跨模态注意力融合
self.cross_modal_attention = MultiHeadAttention(
embed_dim=config.unified_dim,
num_heads=config.num_heads
)
# 统一表示规范化
self.layer_norm = nn.LayerNorm(config.unified_dim)
def forward(self, multimodal_inputs):
"""
输入: {'text': tensor, 'image': tensor, ...}
输出: 统一表示 [batch, seq_len, unified_dim]
"""
modal_features = {}
# 1. 各模态独立编码
for modal, data in multimodal_inputs.items():
if modal in self.modal_encoders:
# 模态特定编码
encoded = self.modal_encoders[modal](data)
# 投影到统一空间
projected = self.projection_layers[modal](encoded)
modal_features[modal] = projected
# 2. 跨模态注意力融合
# 将所有模态特征拼接
all_features = torch.cat(list(modal_features.values()), dim=1)
# 跨模态注意力
fused_features = self.cross_modal_attention(
all_features, all_features, all_features
)
# 3. 统一表示
unified_rep = self.layer_norm(fused_features)
return unified_rep
class UnifiedDecoder(nn.Module):
"""统一解码器:生成任何模态"""
def __init__(self, config):
super().__init__()
# 条件生成头
self.generation_heads = nn.ModuleDict({
'text': TextGenerationHead(config),
'image': ImageGenerationHead(config),
'audio': AudioGenerationHead(config),
'video': VideoGenerationHead(config)
})
# 模态路由网络
self.modal_router = ModalRouter(config)
# 时序解码器(用于视频、音频)
self.temporal_decoder = TemporalDecoder(config)
def forward(self, unified_representation, target_modal):
"""
输入: 统一表示 + 目标模态
输出: 目标模态的数据
"""
# 模态路由:选择生成头
if target_modal not in self.generation_heads:
raise ValueError(f"Unsupported modal: {target_modal}")
generation_head = self.generation_heads[target_modal]
# 时序敏感模态的特殊处理
if target_modal in ['video', 'audio']:
# 添加时序解码
temporal_rep = self.temporal_decoder(unified_representation)
output = generation_head(temporal_rep)
else:
output = generation_head(unified_representation)
return output3.2 跨模态对齐技术
# 多模态对齐技术栈
class CrossModalAlignmentTechniques:
def contrastive_alignment(self, modal1_features, modal2_features):
"""对比学习对齐"""
# InfoNCE损失:正样本对拉近,负样本对推远
temperature = 0.07
# 计算相似度矩阵
similarity_matrix = torch.matmul(
modal1_features, modal2_features.T
) / temperature
# 对比损失
labels = torch.arange(similarity_matrix.size(0))
loss = nn.CrossEntropyLoss()(similarity_matrix, labels)
return loss
def cycle_consistency_alignment(self, modal_a, modal_b):
"""循环一致性对齐"""
# A→B→A' 应接近 A
# B→A→B' 应接近 B
# 编码-解码循环
encoded_a = self.encoder['modal_a'](modal_a)
decoded_b = self.decoder['modal_b'](encoded_a)
encoded_b = self.encoder['modal_b'](decoded_b)
reconstructed_a = self.decoder['modal_a'](encoded_b)
# 重建损失
cycle_loss = F.mse_loss(reconstructed_a, modal_a)
return cycle_loss
def semantic_graph_alignment(self, text_graph, visual_graph):
"""语义图谱对齐"""
# 构建多模态知识图谱
multimodal_kg = {
'entities': self.extract_entities(text_graph, visual_graph),
'relations': self.extract_relations(text_graph, visual_graph),
'embeddings': self.align_embeddings(text_graph, visual_graph)
}
# 图谱对齐损失
alignment_loss = self.graph_matching_loss(
multimodal_kg['embeddings']['text'],
multimodal_kg['embeddings']['visual']
)
return alignment_loss, multimodal_kg
def multimodal_attention_alignment(self, query_modal, key_modal):
"""注意力机制对齐"""
# 多头跨模态注意力
multihead_attn = nn.MultiheadAttention(
embed_dim=512, num_heads=8
)
# 注意力对齐
attn_output, attn_weights = multihead_attn(
query_modal, key_modal, key_modal
)
# 注意力权重作为对齐信号
alignment_scores = self.compute_alignment_scores(attn_weights)
return attn_output, alignment_scores⚡ 四、技术难题突破方案
4.1 计算效率优化策略
# 多模态计算优化方案
class MultimodalComputationalOptimization:
def hierarchical_processing(self, multimodal_input):
"""分层处理策略"""
# Level 1: 轻量级模态筛选
modal_importance = self.estimate_modal_importance(multimodal_input)
# Level 2: 自适应计算分配
compute_budget = {
'text': 0.3, # 30%计算资源
'image': 0.4, # 40%计算资源
'audio': 0.2, # 20%计算资源
'video': 0.1 # 10%计算资源(降采样处理)
}
# Level 3: 稀疏注意力机制
sparse_attention = self.sparse_multimodal_attention(
multimodal_input,
sparsity=0.8 # 80%稀疏化
)
return sparse_attention
def modal_adaptive_compression(self, modal_data):
"""模态自适应压缩"""
compression_strategies = {
'text': {
'method': 'token_pruning',
'threshold': 0.1, # 保留10%关键token
'reconstruction': 'context_aware'
},
'image': {
'method': 'patch_merging',
'patch_size': 16,
'compression_ratio': 0.25 # 4倍压缩
},
'video': {
'method': 'temporal_sampling',
'sample_rate': 0.1, # 10%关键帧
'motion_compensation': True
},
'audio': {
'method': 'spectrogram_compression',
'frequency_bins': 64, # 简化频谱
'time_windows': 0.5 # 50%时间窗
}
}
compressed_data = {}
for modal, data in modal_data.items():
strategy = compression_strategies.get(modal)
if strategy:
compressed_data[modal] = self.compress(
data, **strategy
)
return compressed_data
def distributed_multimodal_training(self):
"""分布式多模态训练架构"""
training_config = {
'data_parallelism': {
'modals_per_gpu': 2, # 每GPU处理2种模态
'inter_gpu_communication': 'gradient_allreduce'
},
'model_parallelism': {
'modal_specific_layers': 8, # 模态特定层
'shared_unified_layers': 24, # 统一表示层
'pipeline_stages': 4
},
'optimization': {
'gradient_checkpointing': True,
'mixed_precision': 'bf16',
'activation_offloading': True,
'memory_efficient_attention': True
}
}
# 训练调度器
scheduler = ModalAwareTrainingScheduler(training_config)
return scheduler4.2 数据融合与对齐方案
# 多模态数据融合系统
class MultimodalDataFusionSystem:
def __init__(self):
self.alignment_models = {
'text-image': CLIPAlignment(),
'audio-video': AVAlignment(),
'3d-vision': PointCloudAlignment()
}
self.fusion_strategies = {
'early_fusion': EarlyFusion(),
'late_fusion': LateFusion(),
'hybrid_fusion': HybridFusion()
}
def create_unified_dataset(self, raw_datasets):
"""构建统一多模态数据集"""
unified_data = []
for data_point in raw_datasets:
# 1. 数据清洗与标准化
cleaned_data = self.clean_and_normalize(data_point)
# 2. 跨模态对齐
aligned_data = self.align_modalities(cleaned_data)
# 3. 语义标注增强
enhanced_data = self.enhance_with_semantics(aligned_data)
# 4. 统一格式封装
unified_point = {
'id': generate_uuid(),
'modalities': enhanced_data,
'alignments': self.compute_alignment_scores(enhanced_data),
'semantic_graph': self.build_semantic_graph(enhanced_data),
'temporal_relations': self.extract_temporal_relations(enhanced_data)
}
unified_data.append(unified_point)
return MultimodalDataset(unified_data)
def synthetic_data_generation(self, seed_data):
"""合成多模态数据增强"""
synthesis_pipeline = {
'text': {
'paraphrase_generation': True,
'style_transfer': True,
'multilingual_augmentation': True
},
'image': {
'style_transfer': True,
'object_editing': True,
'background_variation': True
},
'cross_modal': {
'text_to_image': True,
'image_captioning': True,
'audio_visual_sync': True
}
}
synthetic_data = []
for i in range(synthesis_pipeline['num_generations']):
# 模态内增强
augmented_text = self.augment_text(seed_data['text'])
augmented_image = self.augment_image(seed_data['image'])
# 跨模态生成
cross_modal_data = self.generate_cross_modal(
augmented_text, augmented_image
)
synthetic_data.append(cross_modal_data)
return synthetic_data🚀 五、应用场景与未来展望
5.1 多模态大一统应用矩阵
# 多模态大一统应用场景
class UnifiedMultimodalApplications:
class EducationRevolution:
"""教育革命"""
def intelligent_tutor(self):
return {
'实时分析': '摄像头+麦克风分析学生状态',
'个性化教学': '根据学习风格调整内容',
'实验指导': 'AR眼镜实时指导实验操作',
'情感支持': '检测学习压力并调整节奏'
}
def immersive_learning(self):
return {
'历史重现': '文本描述→历史场景3D重建',
'科学可视化': '公式→动态3D模型',
'语言学习': '实时翻译+发音纠正+文化展示'
}
class HealthcareTransformation:
"""医疗变革"""
def comprehensive_diagnosis(self):
return {
'多模态分析': 'CT影像+病历文本+实时体征',
'手术辅助': 'AR实时导航+AI建议',
'康复监测': '动作捕捉+生理数据+心理评估',
'远程诊疗': '全息远程会诊+多专家协同'
}
def mental_health(self):
return {
'情感分析': '语音语调+面部表情+文字内容',
'治疗辅助': 'VR暴露疗法+实时生理反馈',
'预防干预': '行为模式识别+早期预警'
}
class CreativeIndustry:
"""创意产业"""
def content_creation(self):
return {
'剧本可视化': '文字剧本→分镜→动画预览',
'音乐可视化': '乐谱→3D音乐视觉化',
'跨媒介叙事': '小说→游戏→电影同步开发'
}
def collaborative_creation(self):
return {
'实时协作': '多人多模态创意协同',
'风格迁移': '艺术家风格跨模态应用',
'智能辅助': '创意瓶颈突破建议'
}
# 产业影响预测
class IndustryImpactForecast:
def economic_impact(self):
return {
'市场规模': {
'2025': '$500B',
'2030': '$1.5T',
'2035': '$3.0T'
},
'生产力提升': {
'教育': '40-60%',
'医疗': '35-55%',
'制造': '25-45%',
'创意': '50-70%'
},
'就业影响': {
'创造岗位': '30M+ (AI多模态专家)',
'转型岗位': '50M+ (传统岗位升级)',
'淘汰岗位': '15M- (重复性工作)'
}
}
def technology_roadmap(self):
return {
'2024-2025': 'GPT-4增强版,有限多模态',
'2026-2027': '图文音初步统一,生成能力突破',
'2028-2029': '视频时序理解,实时多模态',
'2030+': '全模态大一统,类人感知智能'
}5.2 伦理与治理框架
# 多模态AI伦理框架
class MultimodalAIEthicsFramework:
def __init__(self):
self.privacy_protocols = {
'数据最小化': '仅收集必要模态数据',
'差分隐私': '训练数据添加噪声保护',
'联邦学习': '数据不出本地训练',
'边缘计算': '敏感数据处理在设备端'
}
self.bias_mitigation = {
'数据审计': '多模态数据偏见检测',
'公平性约束': '训练加入公平性目标',
'可解释性': '跨模态决策解释',
'持续监控': '部署后偏见监测'
}
self.safety_mechanisms = {
'内容过滤': '多模态内容安全过滤',
'深度伪造检测': '生成内容真实性验证',
'护栏机制': '危险行为自动阻止',
'人类监督': '关键决策人类审核'
}
def governance_structure(self):
"""治理架构"""
return {
'技术标准': {
'数据格式': '统一多模态数据标准',
'评估基准': '多模态能力评估套件',
'互操作性': '跨系统多模态交互协议'
},
'监管框架': {
'认证体系': '多模态AI安全认证',
'审计要求': '定期算法影响评估',
'透明度': '模型卡+数据卡+影响说明'
},
'国际合作': {
'标准协调': '跨国多模态AI标准',
'研究共享': '安全研究国际合作',
'治理协调': '全球AI治理协调机制'
}
}💎 总结:通往多模态大一统之路
技术里程碑预测
<TEXT>
🚀 近期(1-2年):
• GPT-4.5/5:图文音三模态支持
• 实时视频理解初步实现
• 计算效率提升10倍
🚀 中期(3-5年):
• 统一表示空间初步形成
• 跨模态生成能力突破
• 时序理解达到分钟级
🚀 长期(5-10年):
• 全模态大一统实现
• 类人多模态智能
• 自主跨模态创作能力核心洞见
<TEXT>
💡 多模态不是简单拼接,而是:
• 统一表示:所有模态在同一语义空间
• 深度理解:跨模态语义关联与推理
• 自由转换:任意模态间无缝转换
💡 关键成功因素:
1. 架构创新:超越Transformer的统一架构
2. 数据革命:高质量多模态对齐数据集
3. 计算突破:新型硬件+算法优化
4. 生态构建:开放标准+工具链+社区
💡 对人类社会的意义:
• 沟通革命:打破语言、文化、感官障碍
• 认知增强:人类智能与AI智能深度融合
• 创意解放:艺术、科学、教育全面革新行动呼吁
<TEXT>
🎯 给研究者的建议:
• 聚焦统一表示学习
• 探索新型注意力机制
• 构建多模态基准测试
🎯 给企业的建议:
• 布局多模态数据资产
• 投资多模态AI团队
• 探索垂直应用场景
🎯 给政策制定者的建议:
• 制定多模态AI标准
• 投资基础研究设施
• 建立伦理治理框架最终思考:
多模态大一统不是技术的终点,而是通往通用人工智能的必经之路。当AI能够像人类一样,无缝理解文字、图像、声音、动作,并能自由地跨模态思考和创造时,我们将迎来真正意义上的人工智能革命。
这场革命已经开始,你准备好了吗? 🚀
多模态的未来不仅取决于技术突破,更取决于我们如何负责任地塑造它。推荐使用DMXAPI