一、概念
概念 :分组函数作用于一组数据,并对一组数据返回一个值;
类型:
| 函数 | 适用数据类型 | 作用 | 举例 |
|---|---|---|---|
| AVG() | 数值型 | 平均值 | SELECT AVG(salary) FROM employees WHERE job_id LIKE '%REP%'; |
| COUNT() | 任意数据 | 计数 | count(*) 返回表中记录总数 :SELECT COUNT(*) FROM employees WHERE department_id = 50,count(expr)返回expr不为空的记录总数:SELECT COUNT(department_id ) FROM employees WHERE department_id = 50 |
| MAX() | 任意数据 | 最大值 | SELECT MAX(salary) FROM employees WHERE job_id LIKE '%REP%'; |
| MIN() | 任意数据 | 最小值 | SELECT MIN(salary) FROM employees WHERE job_id LIKE '%REP%'; |
| SUM() | 数值型 | 合计 | SELECT SUM(salary) FROM employees WHERE job_id LIKE '%REP%'; |
语法 :

注意 :
不能在where子句中使用组函数,可以在having子句中使用组函数
二、GROUP BY子句语法
概念 :可以使用GROUP BY子句将表中的数据分成若干组
规则:
- (保命规则)在select列表中所有未包含在组函数中的列都应该包含在GROUP BY子句中;
- (自由规则)包含在GROUP BY子句中的列不必包含在select列表中;
sql
规则一:只要你在 SELECT 里写了 既不是聚合函数(SUM/AVG/COUNT...)也不是常量的列,那么该列必须原封不动地写进 GROUP BY,否则直接报 SQL 错误(MySQL 8 之前如果开了 ONLY_FULL_GROUP_BY 会报错,关了会返回不可预期的行)。
正确举例:
SELECT dept_id, emp_name, COUNT(*)
FROM emp
GROUP BY dept_id,emp_name;
错误举例:
SELECT dept_id, emp_name, COUNT(*)
FROM emp
GROUP BY dept_id; -- 错!emp_name 没出现在 GROUP BY
规则二:反过来,GROUP BY 里可以列出任意多列,但你不一定把它们都 SELECT 出来;它们只是用来"分组的钥匙"。
举例:
SELECT COUNT(*)
FROM emp
GROUP BY dept_id, job; -- 只按两列分组,但 SELECT 里一个列都没出现,完全合法三、HAVING子句
概念 :
使用HAVING过滤分组:
- 行已经被分组;
- 使用了组函数;
- 满足HAVING子句中条件的分组将被显示;
. 语法 :

举例 :

四、多表查询
4.1 MySQL连接
使用连接在多个表中查询数据;
- 在where子句中写入连接条件;
- 在表中有相同列时,在列名之前加上表名前缀;

4.2 等值连接

4.3 使用ON子句创建连接
- 自然连接中是以具有相同名字的列为连接条件的;
- 可以使用ON子句指定额外的连接条件;
- 这个连接条件是与其他条件分开的;
- ON子句使语句具有更高的易读性;
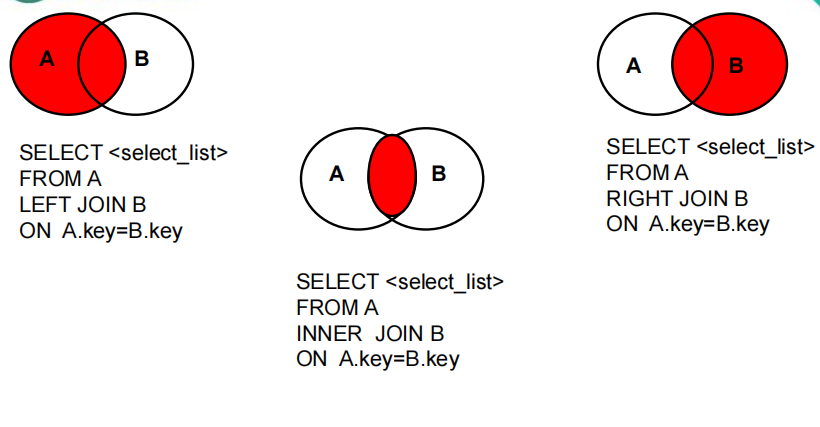
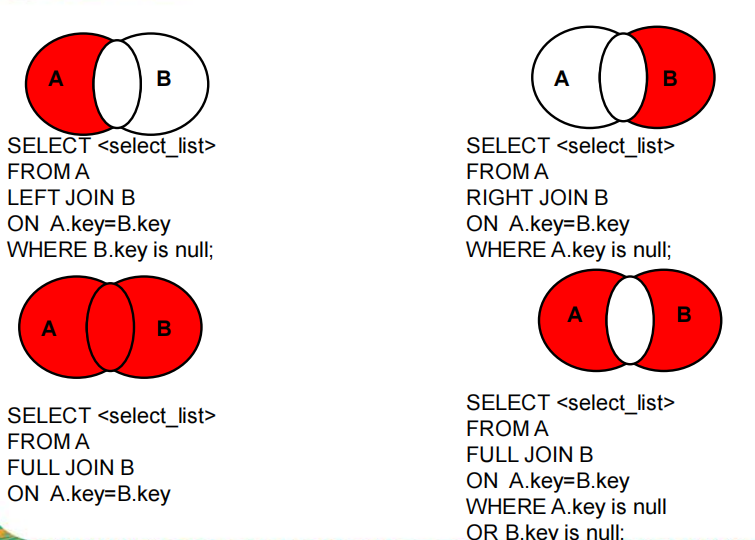
4.4 Join连接
分类:
- 内连接inner join on
- 外连接(左外连接 left outer join on、右外连接 right outer join on)