我们正在经历一场静默但壮阔的权力转移。主导权正从精心设计的算法规则,移交给由海量数据"喂养"出的、行为难以完全预测的智能实体。理解这场变革,只需看透一个本质:AI如何"开会"------即如何组织信息、做出决策。这背后的演进,恰似一部从独裁到扁平,再到多元混战的"公司权力结构演变史"。
上篇:权力的演进------从"董事长独裁"到"全村开会"
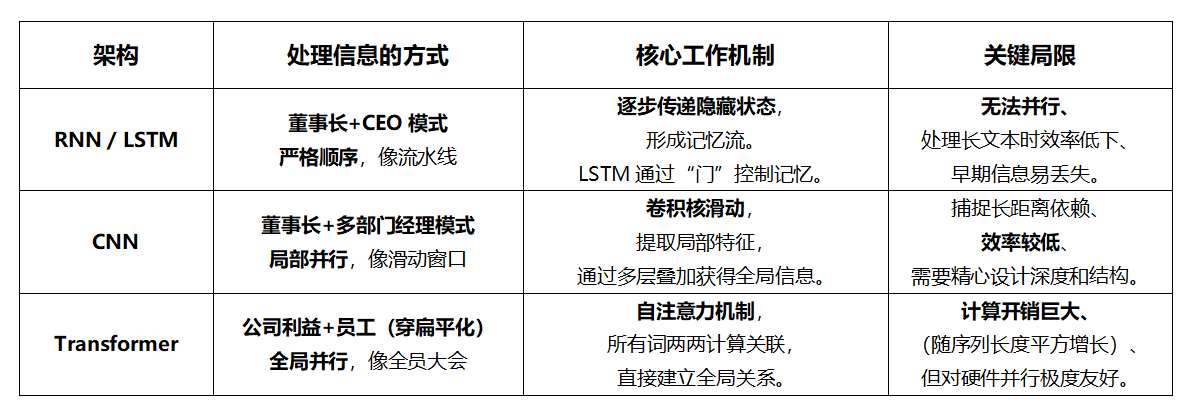
1.0时代:中央集权的"家族企业" (RNN/LSTM)
早期的AI,如循环神经网络及其升级版LSTM,像一家传统的家族企业。信息必须像流水线一样,从第一个字到最后一个字,严格按顺序逐级上报 。每个新词进来,都要向"中央处理器"(隐藏状态)汇报,后者更新记忆后再传递下去。LSTM引入了"门控"机制,如同设立了精明的秘书团,能选择记住重点、忘记琐事,但"一切信息必须经过董事长"的根本瓶颈未变。其权力逻辑是线性的、脆弱的:链条一旦拉长,开头的记忆便在末端模糊、扭曲,导致理解失焦。
2.0时代:部门林立的"科层制巨头" (CNN)
卷积神经网络带来了"部门制"改革。它不再严格顺序处理,而是设立多个"部门经理"(卷积核),同时扫描句子的不同局部,提取特征后层层上报汇总。这提升了并行效率,但也筑起了深厚的"部门墙"。一个部门(卷积核)的视野极其有限 ,若要理解"宇宙"和"粒子"这两个相隔甚远的词之间的关系,需要经过复杂冗长的多层汇报,信息在传递中耗散、失真。其权力结构是局部高效、全局迟钝的。
3.0时代:彻底扁平的"全员共识制" (Transformer)
2017年,Transformer架构的诞生,发动了一场彻底的"管理革命"。它瞬间召集所有词汇,召开一场全员共识大会 。在这个会议上,每个词都通过"自注意力机制",与句中所有其他词直接对话、动态计算亲疏关系。例如,"它"能瞬间与"苹果"紧密关联,而非"吃"。
这一设计的革命性在于三点:
- 绝对并行:全员同时工作,极大解放了算力,使训练万亿参数模型成为可能。
- 全局视野:任何两个词都能直接关联,彻底终结了"长程遗忘"。
- 去中心化 :决策依赖于动态、涌现的集体共识,而非固定中央。
Transformer奠定了现代AI帝国的基石,它不是一家公司,而是一个全新的、可复制的"国家体制"。此后所有的竞争,都是基于这一体制,发展出不同的"国策"与"文明形态"。
下篇:帝国的裂变------大模型"战国时代"的文明竞合
基于Transformer这一先进体制,各大科技力量展开了殊途同归的探索,形成了风格迥异的"文明形态"。
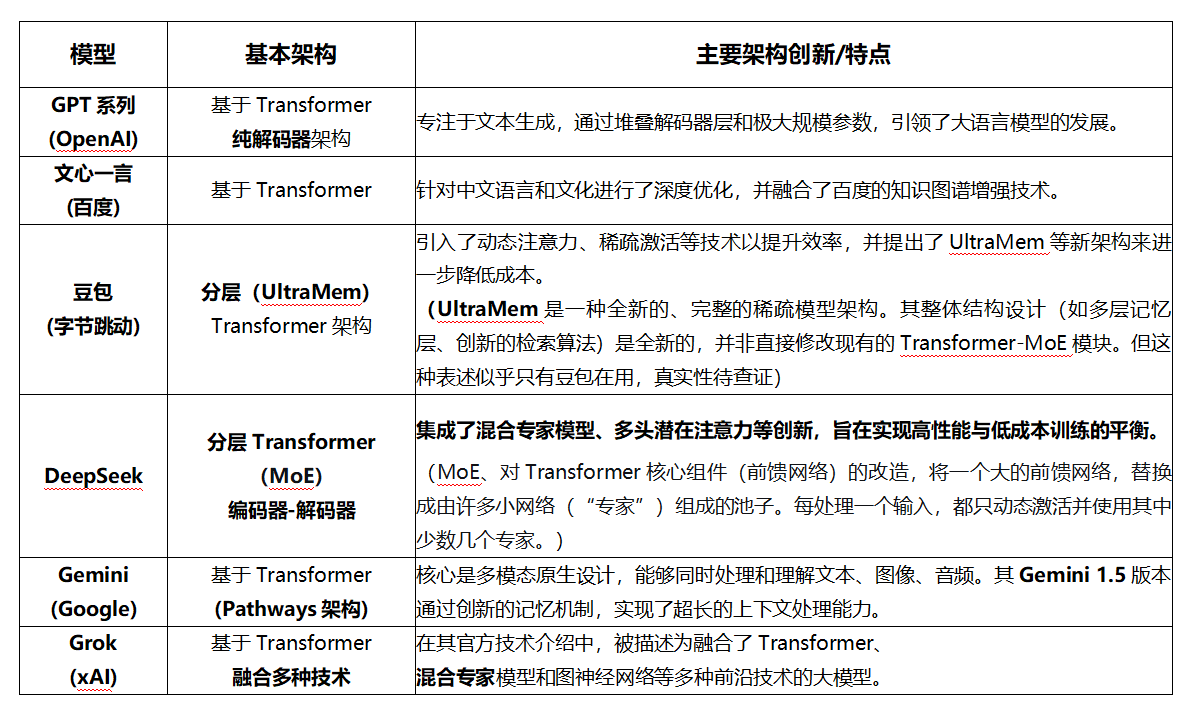
1. OpenAI:封闭的"技术神权"殿堂
OpenAI的GPT系列是 "纯解码器"架构的极致代表 ,它如同一个专注于"神谕生成"的殿堂。其权力核心在于通过预测下一个词的简单目标,从海量数据中涌现出复杂智能 。它的战略是追求"神性"------即模型的通用性与对齐能力,并通过紧密闭源 和与微软的深度联盟,构建起坚固的护城河。它的挑战在于,"神谕"的生成过程如同黑箱,且消耗巨大的算力贡品。
2. Google:开放的"多模态"联邦实验室
Google的Gemini代表了另一种哲学:原生多模态 。从底层设计上,就让文本、图像、音频、视频等"不同种族"的信息在同一空间内共生协作。其权力基础是庞大的用户生态与数据疆域。作为Transformer的发明者,Google试图通过开源基础模型 和多模态统一来制定行业标准。但它的帝国庞大,有时显得决策迟缓,在多条战线上同时应对挑战。
3. 中国军团:激进的"功能主义"集团
中国模型在统一的基础体制下,走出了强烈的实用主义路线。
- 百度文心一言 :推行 "知识增强"政策。如同在全员大会旁常驻一个权威的"翰林院"(知识图谱),为生成内容注入事实与文化校验,尤其深耕中文理解。
- 字节豆包 :高举 "效率革命"旗帜 。其动态注意力、稀疏激活 等技术旨在优化开会效率。最新提出的UltraMem架构,更是旨在彻底解决大模型推理时"记忆调用"成本过高的问题,堪称一场针对模型"行政开销"的廉洁改革,目标直指落地应用的性价比。
- 深度求索DeepSeek :奉行 "性价比"务实主义 。采用编码器-解码器全架构,并集成MoE。这好比养着千名专家,每次只请相关几位开会,用动态组织的方式,实现了高性能与低成本的精妙平衡。
4. 新贵与变量:xAI与开源浪潮
- xAI的Grok :被伊隆·马斯克赋予"叛逆"人设。其技术描述暗示了一种 "融合架构" ,试图将Transformer、MoE甚至图神经网络相结合,像是一个鼓励跨学科碰撞的"疯狂实验室",探索现有路径之外的未知可能。
- 开源模型 :以Meta的Llama系列为代表,正在发动一场"底层革命"。它们将强大的基础模型"武器" democratize(民主化),使得任何中小企业甚至个人都能在此基础上微调、创新。这正在瓦解单纯依靠模型规模构筑的壁垒,将竞争引入到数据质量、垂直优化和社区生态的新维度。
终章:未完成的革命------权力、成本与失控的担忧
当前的"战国时代"呈现几个清晰的趋势:
- 架构收敛:MoE已成为处理超大规模参数、平衡训练与推理成本的主流选择。
- 多模态内卷:纯文本模型已显基础,理解并生成图像、视频、音频等多模态信息,成为头部玩家的标配竞技场。
- 成本与落地之战 :推理成本成为商业化的最大拦路虎。豆包的UltraMem、DeepSeek的MoE优化,本质都是"降本之战",目标是将AI从云端贵族拉向寻常百姓家。
- 开源与闭源的拉锯:闭源模型追求性能极致与商业控制,开源模型催化创新生态与广泛部署。两者相互刺激,共同推进边界。
然而,权力愈是强大,忧虑愈是深重。当AI的"全员大会"变得过于复杂,以至于连它的设计者也无法完全理解其共识形成的全过程时,一种新的、非人类的权力逻辑正在悄然形成。我们创造了超越古典管理学的"扁平化共识机器",但它最终将带领我们走向何方,仍是这个时代最激动人心也最深刻的悬疑。
这场AI帝国演进史远未结束,它不再是单纯的技术迭代,而是关乎生产力、权力结构与文明形态的深刻叙事。我们每个人,都既是观众,也是即将被写入新历史的角色。