目录
[1.1 为什么需要复制](#1.1 为什么需要复制)
[1.2 基本概念](#1.2 基本概念)
[2.1 建立复制的三种方式](#2.1 建立复制的三种方式)
[2.2 配置文件修改示例](#2.2 配置文件修改示例)
[2.3 查看复制状态](#2.3 查看复制状态)
[2.4 断开与切换复制](#2.4 断开与切换复制)
[3.1 一主一从](#3.1 一主一从)
[3.2 一主多从(星形结构)](#3.2 一主多从(星形结构))
[3.3 树状主从(分层结构)](#3.3 树状主从(分层结构))
[4.1 复制过程流程图](#4.1 复制过程流程图)
[5.1 PSYNC命令](#5.1 PSYNC命令)
[5.2 核心概念](#5.2 核心概念)
[5.2.1 复制ID (Replication ID/replid)](#5.2.1 复制ID (Replication ID/replid))
[5.2.2 偏移量 (Offset)](#5.2.2 偏移量 (Offset))
[5.3 全量复制流程](#5.3 全量复制流程)
[5.4 部分复制流程](#5.4 部分复制流程)
[5.5 复制积压缓冲区](#5.5 复制积压缓冲区)
[5.6 实时复制](#5.6 实时复制)
一、复制的作用与基本概念
1.1 为什么需要复制
单点问题:单个Redis节点可用性不高,性能有限
故障恢复:主节点宕机时,从节点可以提供服务
负载均衡:主节点负责写,从节点负责读,降低主节点压力
1.2 基本概念
主节点(Master):负责写操作的节点,数据源
从节点(Slave):复制主节点数据,通常负责读操作
复制流:单向,只能从主节点到从节点
二、配置复制相关操作
2.1 建立复制的三种方式
java
# 方式1:配置文件中加入(永久生效)
# 在从节点的redis.conf中添加:
slaveof {masterHost} {masterPort}
# 方式2:启动命令时加入
redis-server /etc/redis/redis-slave.conf --port 6380 --slaveof 127.0.0.1 6379
# 方式3:使用Redis命令(临时生效)
127.0.0.1:6380> SLAVEOF 127.0.0.1 63792.2 配置文件修改示例
java
# 复制配置文件
cp /etc/redis/redis.conf /etc/redis/redis-slave.conf
# 修改从节点配置
# 1. 启用守护进程模式
daemonize yes
# 2. 如果主节点有密码,需要配置
masterauth {masterPassword}
# 3. 从节点默认只读(建议保持)
slave-read-only yes2.3 查看复制状态
java
# 查看主节点复制状态
127.0.0.1:6379> INFO REPLICATION
# 查看从节点复制状态
127.0.0.1:6380> INFO REPLICATION2.4 断开与切换复制
java
# 断开复制,从节点晋升为主节点
127.0.0.1:6380> SLAVEOF NO ONE
# 切换主节点(会删除当前所有数据)
127.0.0.1:6380> SLAVEOF {newMasterIP} {newMasterPort}注:从节点断开复制之后并不会删除原有数据,只是无法再获取到主节点上的数据变化
从节点如果要切换到别的主节点,会删除所有数据,与新主节点进行复制操作
三、复制拓扑结构
3.1 一主一从
一主一从结构用于主节点出现宕机时从节点提供故障转移支持;
场景:业务写请求并发量高,又怕数据丢失(需要持久化)
主节点:关闭 AOF → 避免磁盘 IO 拖慢性能(主节点只专注处理写请求,不做持久化)
从节点:开启 AOF → 保证数据不丢(就算主节点数据丢了,从节点的 AOF 能恢复全部数据,保证数据安全。)
注意:主节点关闭持久化,宕机要避免自动重启
理由:主节点重启→内存空了(没持久化文件恢复)→从节点发现主节点数据是空的→自动清空自己的所有数据(包括 AOF 里的备份)→整个集群数据全丢
3.2 一主多从(星形结构)
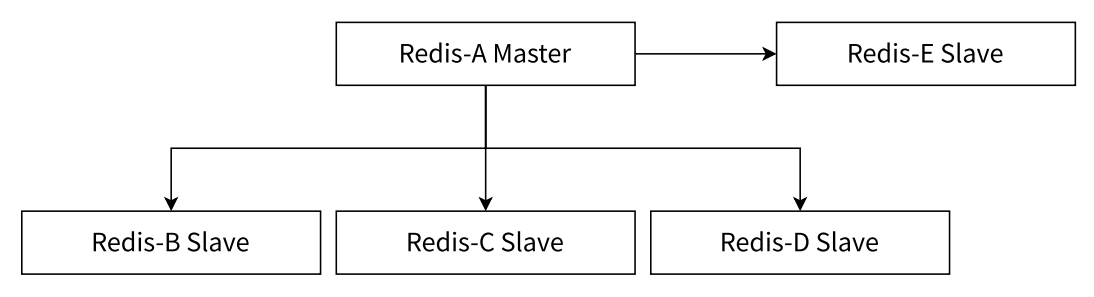
⼀主多从结构使应用端可以利用多个从节点实现读写分离;
主节点:唯一处理所有写请求 (比如
set/hmset/del等修改数据的操作)是数据的 "唯一写入源";从节点:都从主节点同步数据,只处理读请求 (比如
get/hgetall等查询操作)注意:高写并发下会加重主节点负载
3.3 树状主从(分层结构)
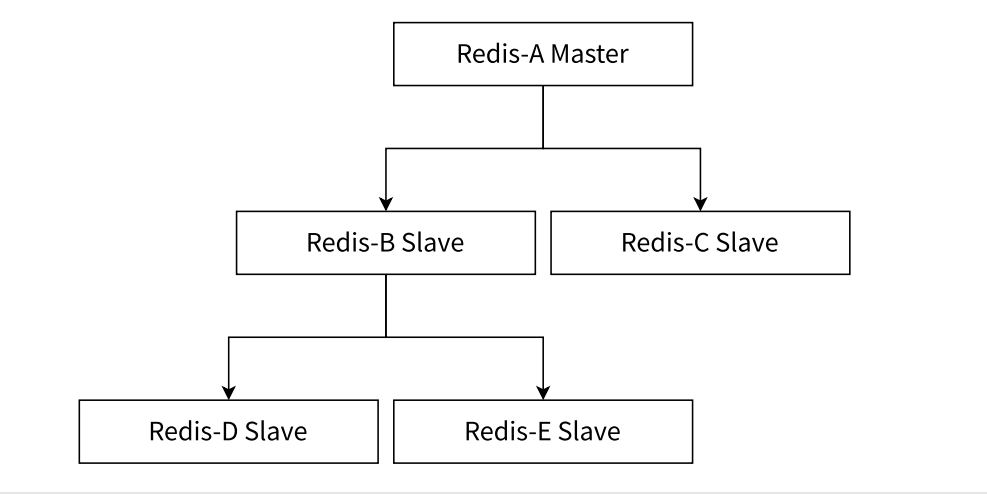
树形主从结构使从节点不但可以复制主节点数据,同时可以作为其他从节点的主节点继续向下层复制。
顶层主节点 A :唯一处理写请求,仅需给直接相连的中间节点 B、C同步数据;
中继节点 B、C:① 作为 A 的从节点,同步 A 的数据;② 作为 D、E 的主节点,给下层纯从节点同步数据(相当于 "数据转发器");
纯从节点 D、E:只做普通从节点,同步上层中继节点的数据,处理读请求。
核心优势:降低顶层主节点的负载,节省网络带宽
四、复制原理与过程
4.1 复制过程流程图
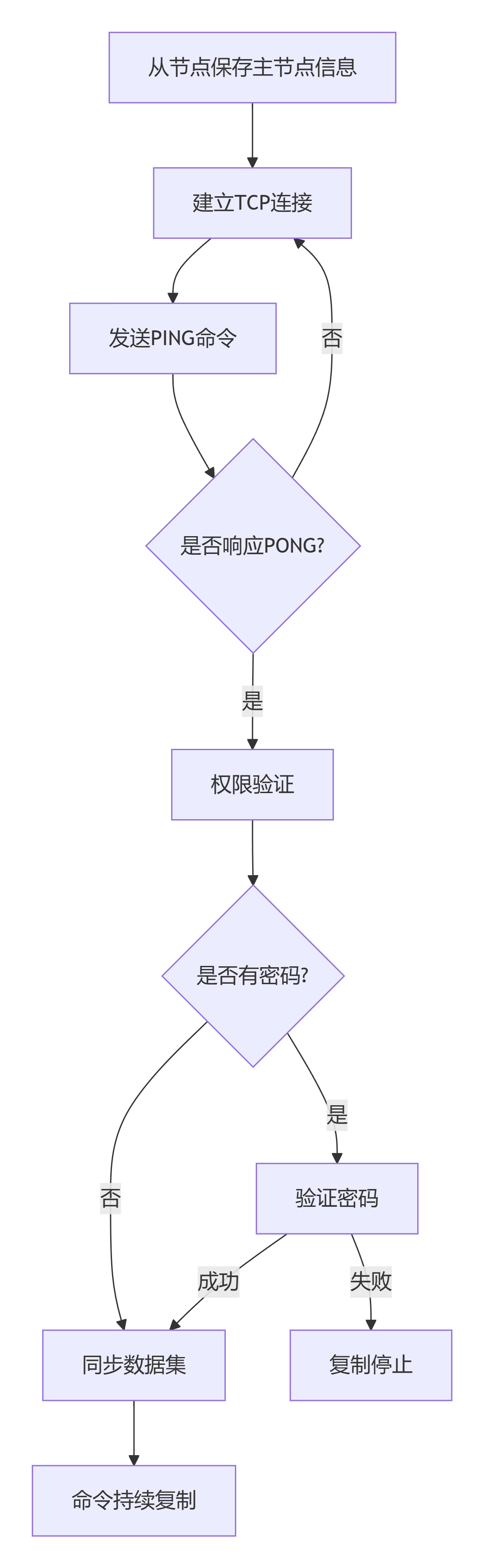
步骤1:保存主节点信息
从节点保存主节点的IP和端口;主节点连接状态标记为down
步骤2:建立连接
从节点内部定时任务尝试建立TCP连接,如果连接失败,定时任务会无限重试
步骤3:发送PING命令
连接成功后,从节点发送PING命令,如果PONG响应超时,断开连接并重试
步骤4:权限验证
如果主节点设置了requirepass,需要密码验证,从节点通过masterauth配置密码
步骤5:同步数据集
首次复制:全量复制
后续复制:部分复制或实时复制
步骤6:命令持续复制
主节点持续将修改命令发送给从节点,从节点执行命令,保持数据一致性
五、数据同步机制
Redis使用psync命令完成主从复制数据同步,同步过程分为:
全量复制:一般初次复制场景,会把主节点全部 数据⼀次性发送给从节点,当数据量较大时,会对主从节点和⽹络造成很大的开销。
部分复制:处理在主从复制中因网络闪断等原因造成的数据丢失场景,当从节点再次连上主节 点后,如果条件允许,主节点会补发数据给从节点。
5.1 PSYNC命令
java
PSYNC replicationid offset如果replicationid 设为? 并且offset设为-1 此时就是在尝试进行全量复制.
如果replicationid offset设为了具体的数值,则是尝试进行部分复制.
5.2 核心概念
5.2.1 复制ID (Replication ID/replid)
主节点的唯一标识
重启或从节点晋升时会重新生成
从节点会记录主节点的replicationid
java
# 查看复制ID
127.0.0.1:6379> INFO REPLICATION
master_replid: 1da596acecf5a34b4b2aae45bd35be785691ae69
master_replid2: 00000000000000000000000000000000000000005.2.2 偏移量 (Offset)
记录复制进度
主节点和从节点各自维护自己的偏移量
通过对比偏移量判断数据是否一致
java
# 查看偏移量
127.0.0.1:6379> INFO REPLICATION
master_repl_offset: 1055130 # 主节点偏移量
127.0.0.1:6380> INFO REPLICATION
slave_repl_offset: 1055214 # 从节点偏移量replid+offset共同标识了⼀个"数据集".
如果两个节点,他们的replid和offset都相同,则这两个节点上持有的数据就⼀定相同.
5.3 全量复制流程
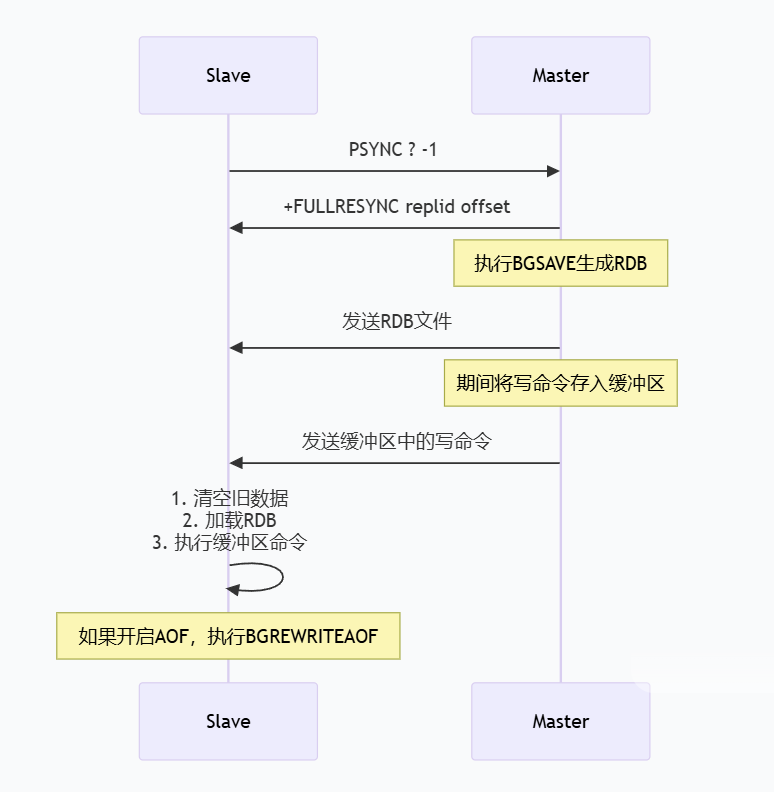
注意:
全量复制成本高,应尽量避免对大数据集进行全量复制
Redis 2.8.18+支持无磁盘复制(diskless),通过网络直接发送RDB数据
5.4 部分复制流程
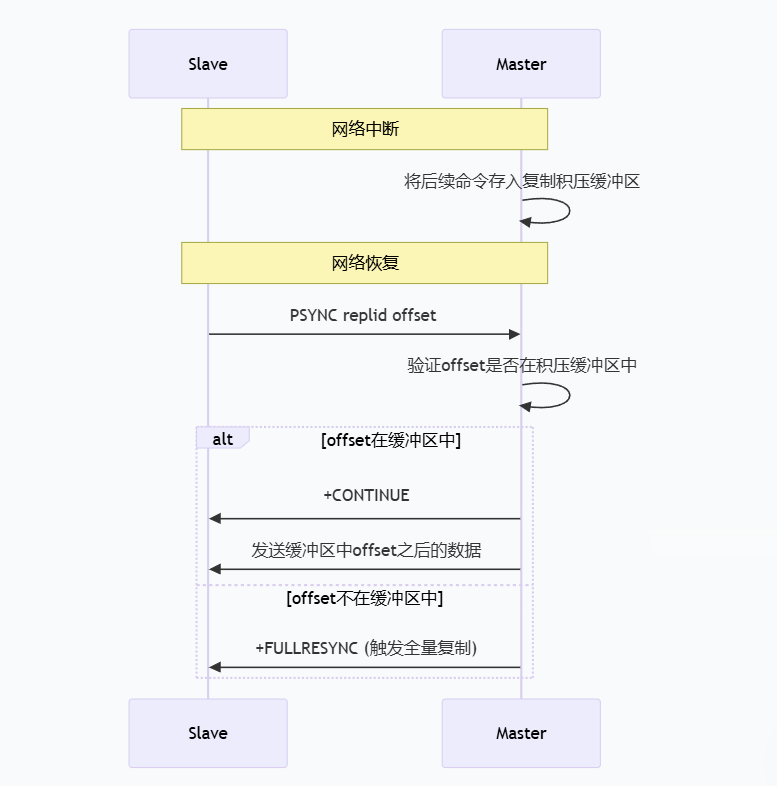
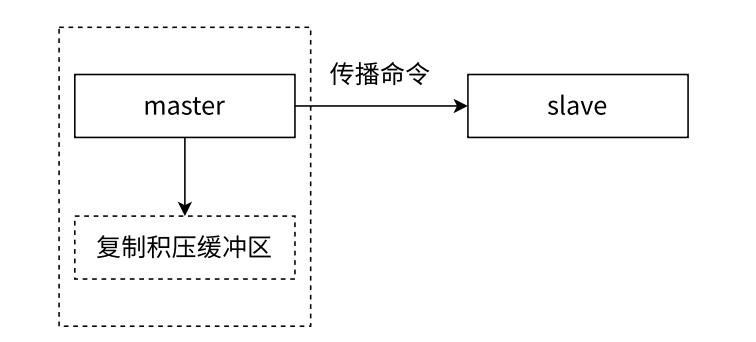
5.5 复制积压缓冲区
复制积压缓冲区是保存在主节点上的一个固定长度的队列(先进先出),默认1MB,可以保存最近已复制的数据,用于部分复制和命令丢失补救。
java
# 查看积压缓冲区信息
127.0.0.1:6379> INFO REPLICATION
repl_backlog_active:1
repl_backlog_size:1048576 # 缓冲区大小(1MB)
repl_backlog_first_byte_offset:7479
repl_backlog_histlen:1048576 # 已保存数据的有效长度可用偏移量范围:
repl_backlog_first_byte_offset, repl_backlog_first_byte_offset + repl_backlog_histlen
如果当前从节点需要的数据,已经超出了主节点的积压缓冲区的范围,则无法进行部分复制,只 能全量复制了.
5.6 实时复制
主节点会把自己收到的修改操作,通过tcp长连接的方式,源源不断的传输给从节点.
从节点就会根据这些请求来同时修改自身的数据.从而保持和主节点数据的⼀致性.
通过心跳机制维护连接状态
主节点:每10秒向从节点发送PING命令
从节点:每1秒向主节点发送
REPLCONF ACK {offset}如果主节点发现从节点通信延迟超过
repl-timeout(默认60秒),判定从节点下线断开复制客户端连接