目录
[1.1 四层模型 vs OSI七层模型](#1.1 四层模型 vs OSI七层模型)
[1.2 协议数据单元(PDU)的演变过程](#1.2 协议数据单元(PDU)的演变过程)
[2.1 TCP的三次握手与四次挥手:状态机视角](#2.1 TCP的三次握手与四次挥手:状态机视角)
[2.2 IP协议:互联网的"邮政系统"](#2.2 IP协议:互联网的"邮政系统")
[3.1 TCP性能优化:从理论到实践](#3.1 TCP性能优化:从理论到实践)
[3.2 零拷贝技术优化](#3.2 零拷贝技术优化)
[4.1 TCP/IP协议栈攻击与防御](#4.1 TCP/IP协议栈攻击与防御)
[4.2 TLS/SSL集成优化](#4.2 TLS/SSL集成优化)
[4.3 网络层安全:IPSec实践](#4.3 网络层安全:IPSec实践)
[5.1 QUIC协议:TCP的替代者](#5.1 QUIC协议:TCP的替代者)
[5.2 eBPF:内核可编程网络](#5.2 eBPF:内核可编程网络)
[5.3 协议栈性能监控与调优](#5.3 协议栈性能监控与调优)
如果您喜欢此文章,请收藏、点赞、评论,谢谢,祝您快乐每一天。
一、TCP/IP协议栈的层次化架构深度剖析
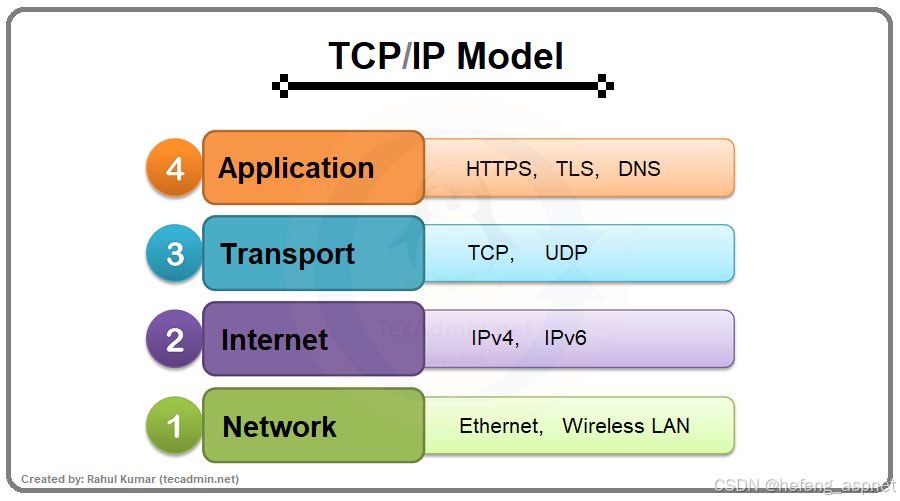
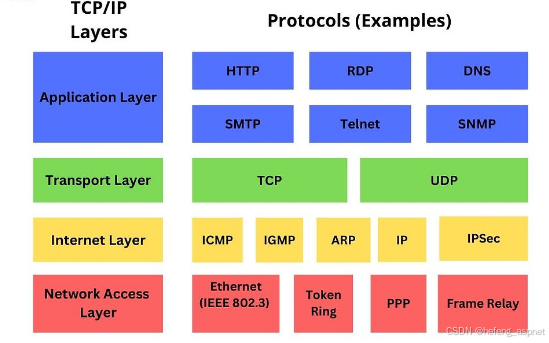
1.1 四层模型 vs OSI七层模型
TCP/IP四层模型的核心哲学:
应用层 (Application Layer) ← 数据生成与消费
传输层 (Transport Layer) ← 端到端通信控制
网络层 (Internet Layer) ← 路由与寻址
网络接口层 (Network Interface) ← 物理传输
与OSI模型的对应关系:
// TCP/IP的"实用主义"设计
class TCPIPStack {
// 应用层 = OSI(5-7层)
void handleApplication(Data& data) {
// HTTP、FTP、SMTP、DNS等
// 关注"数据内容"而非传输细节
}
// 传输层 = OSI第4层
void handleTransport(Segment& seg) {
// TCP/UDP:关注"可靠传输"和"流量控制"
// 核心问题:如何保证数据完整到达?
}
// 网络层 = OSI第3层
void handleNetwork(Packet& pkt) {
// IP协议:关注"路径选择"和"地址管理"
// 核心问题:数据走哪条路?
}
// 网络接口层 = OSI(1-2层)
void handleLink(Frame& frame) {
// 以太网、Wi-Fi、PPP等
// 关注"物理传输"和"本地寻址"
}
};
1.2 协议数据单元(PDU)的演变过程
用户数据 (User Data)
↓ 应用层封装
应用层PDU + 应用层头部 = 消息(Message)
↓ 传输层封装
消息 + TCP/UDP头部 = 段(Segment)
↓ 网络层封装
段 + IP头部 = 数据包(Packet/Datagram)
↓ 网络接口层封装
数据包 + 帧头部/尾部 = 帧(Frame)
↓ 物理层转换
帧 → 比特流(Bits) → 电信号/光信号
二、核心协议深度拆解
2.1 TCP的三次握手与四次挥手:状态机视角
三次握手状态迁移:
// 服务器端视角
enum class TCPState {
CLOSED, // 初始状态
LISTEN, // 监听连接
SYN_RCVD, // 收到SYN
ESTABLISHED, // 连接建立
FIN_WAIT_1, // 主动关闭
FIN_WAIT_2, // 等待对方确认
CLOSE_WAIT, // 被动关闭
LAST_ACK, // 最后确认
CLOSING, // 同时关闭
TIME_WAIT // 等待时间
};
class TCPConnection {
private:
TCPState state_ = TCPState::CLOSED;
uint32_t seq_num_; // 序列号
uint32_t ack_num_; // 确认号
uint16_t window_size_; // 窗口大小
public:
// 三次握手处理
void processHandshake(const TCPSegment& seg) {
switch(state_) {
case TCPState::LISTEN:
if (seg.hasFlag(SYN)) {
// 第一次握手:收到SYN
sendSYNACK();
state_ = TCPState::SYN_RCVD;
}
break;
case TCPState::SYN_RCVD:
if (seg.hasFlag(ACK)) {
// 第三次握手:收到ACK
state_ = TCPState::ESTABLISHED;
onConnected(); // 连接建立回调
}
break;
}
}
// 为什么需要TIME_WAIT状态?
// 1. 确保最后的ACK能够到达
// 2. 让旧连接的重复数据包在网络中消失
// 默认等待2MSL(Maximum Segment Lifetime)
void enterTimeWait() {
state_ = TCPState::TIME_WAIT;
startTimer(2 * MSL); // 通常2分钟
}
};
TCP头部关键字段解析:
struct TCPHeader {
uint16_t src_port; // 源端口
uint16_t dst_port; // 目的端口
uint32_t seq_num; // 序列号:防重排序
uint32_t ack_num; // 确认号:累计确认
uint8_t data_offset; // 头部长度(4字节为单位)
uint8_t flags; // 控制位:URG|ACK|PSH|RST|SYN|FIN
uint16_t window; // 接收窗口大小:流量控制
uint16_t checksum; // 校验和
uint16_t urgent_ptr; // 紧急指针
// 选项字段(可变长度)
// MSS、窗口缩放因子、时间戳、SACK等
};
2.2 IP协议:互联网的"邮政系统"
IPv4头部结构:
struct IPv4Header {
#if __BYTE_ORDER == __LITTLE_ENDIAN
uint8_t ihl:4; // 头部长度(32位字)
uint8_t version:4; // 版本号
#else
uint8_t version:4;
uint8_t ihl:4;
#endif
uint8_t tos; // 服务类型(DSCP/ECN)
uint16_t total_len; // 总长度
uint16_t id; // 标识符:用于分片重组
uint16_t frag_off; // 分片偏移和标志
uint8_t ttl; // 生存时间
uint8_t protocol; // 上层协议(TCP=6, UDP=17)
uint16_t checksum; // 头部校验和
uint32_t src_addr; // 源IP地址
uint32_t dst_addr; // 目的IP地址
// 选项字段(如果有)
};
IP分片与重组算法:
class IPFragmentReassembler {
private:
struct Fragment {
uint16_t offset; // 偏移量(8字节为单位)
uint16_t length; // 数据长度
bool more_fragments; // MF标志
std::vector<uint8_t> data;
time_t arrival_time; // 到达时间
};
std::map<uint16_t, std::vector<Fragment>> fragments_; // 按ID分组
static constexpr uint32_t TIMEOUT = 30; // 30秒超时
public:
bool processFragment(const IPv4Header& ip, const uint8_t* payload) {
uint16_t id = ntohs(ip.id);
uint16_t offset = (ntohs(ip.frag_off) & 0x1FFF) * 8;
bool mf = (ntohs(ip.frag_off) & 0x2000) != 0;
// 检查重叠分片(安全风险!)
auto& frag_list = fragments_id;
for (auto& frag : frag_list) {
if (offset >= frag.offset &&
offset < frag.offset + frag.length) {
// 重叠分片:可能是攻击
logSecurityEvent("IP fragment overlap detected");
return false;
}
}
// 存储分片
frag_list.push_back({offset, ip.total_len - ip.ihl*4,
mf, {payload, payload + (ip.total_len - ip.ihl*4)},
time(nullptr)});
// 尝试重组
return tryReassemble(id);
}
};
三、协议栈优化实践
3.1 TCP性能优化:从理论到实践
拥塞控制算法演进:
Reno (1988) → NewReno (1990) → Vegas (1994) →
BIC (2004) → CUBIC (2005) → BBR (2016)
BBR (Bottleneck Bandwidth and Round-trip propagation time):
BBR核心思想:测量真实带宽和RTT,而非依赖丢包
class BBRCongestionControl:
def init(self):
self.bw = 0 # 估计的最大带宽
self.min_rtt = float('inf') # 最小RTT
self.pacing_rate = 0 # 发送速率
self.cwnd = 0 # 拥塞窗口
def on_ack(self, packet):
测量带宽:交付的数据量 / 时间间隔
delivered = packet.bytes_delivered
interval = packet.rtt
bw_sample = delivered / interval
if bw_sample > self.bw:
self.bw = bw_sample
更新最小RTT
if packet.rtt < self.min_rtt:
self.min_rtt = packet.rtt
计算发送速率
self.pacing_rate = self.bw * GAIN # GAIN通常为1.25
计算拥塞窗口
self.cwnd = max(2, self.bw * self.min_rtt)
Linux内核TCP优化参数:
查看当前TCP参数
sysctl -a | grep -E "^net\.ipv4\.tcp"
优化建议配置(服务器端)
echo "net.ipv4.tcp_window_scaling = 1" >> /etc/sysctl.conf
echo "net.ipv4.tcp_timestamps = 1" >> /etc/sysctl.conf
echo "net.ipv4.tcp_sack = 1" >> /etc/sysctl.conf
echo "net.ipv4.tcp_congestion_control = bbr" >> /etc/sysctl.conf
echo "net.core.rmem_max = 134217728" >> /etc/sysctl.conf # 128MB
echo "net.core.wmem_max = 134217728" >> /etc/sysctl.conf
echo "net.ipv4.tcp_rmem = 4096 87380 134217728" >> /etc/sysctl.conf
echo "net.ipv4.tcp_wmem = 4096 65536 134217728" >> /etc/sysctl.conf
echo "net.ipv4.tcp_max_syn_backlog = 8192" >> /etc/sysctl.conf
echo "net.core.somaxconn = 8192" >> /etc/sysctl.conf
应用配置
sysctl -p
3.2 零拷贝技术优化
传统数据拷贝路径:
应用缓冲区 → 内核缓冲区 → 网卡缓冲区
↓ ↓ ↓
用户态 内核态 硬件
零拷贝优化方案:
// 使用sendfile系统调用(Linux)
#include <sys/sendfile.h>
class ZeroCopySender {
public:
bool sendFile(int sockfd, int filefd, off_t* offset, size_t count) {
// 内核直接在内核空间完成文件到socket的数据传输
ssize_t sent = sendfile(sockfd, filefd, offset, count);
// 对比传统方式:
// read(filefd, buffer, count); // 用户态→内核态拷贝
// write(sockfd, buffer, count); // 内核态→用户态→内核态拷贝
// 总共2次拷贝 + 4次上下文切换
// sendfile:0次拷贝 + 2次上下文切换
return sent == count;
}
};
// 使用mmap + writev进一步优化
class MMAPSender {
private:
void* mapped_data_;
size_t file_size_;
public:
bool mapFile(const std::string& filename) {
int fd = open(filename.c_str(), O_RDONLY);
file_size_ = lseek(fd, 0, SEEK_END);
// 内存映射文件
mapped_data_ = mmap(nullptr, file_size_,
PROT_READ, MAP_PRIVATE, fd, 0);
close(fd);
return mapped_data_ != MAP_FAILED;
}
bool sendWithWritev(int sockfd) {
struct iovec iov2;
// 构建头部和数据
std::string header = "HTTP/1.1 200 OK\r\nContent-Length: ";
header += std::to_string(file_size_) + "\r\n\r\n";
iov0.iov_base = const_cast<char*>(header.data());
iov0.iov_len = header.size();
iov1.iov_base = mapped_data_;
iov1.iov_len = file_size_;
// 一次系统调用发送所有数据
ssize_t sent = writev(sockfd, iov, 2);
return sent == (ssize_t)(header.size() + file_size_);
}
};
四、安全实践深度解析
4.1 TCP/IP协议栈攻击与防御
常见攻击类型及防护:
class TCPSecurityGuard {
public:
// 1. SYN Flood防护
bool validateSYN(const TCPSegment& syn) {
static std::unordered_map<uint32_t, SYNRecord> syn_cache;
static constexpr size_t MAX_SYN_RATE = 1000; // 每秒最大SYN数
uint32_t src_ip = syn.src_addr;
auto& record = syn_cachesrc_ip;
auto now = std::chrono::steady_clock::now();
auto elapsed = std::chrono::duration_cast<std::chrono::milliseconds>(
now - record.last_syn_time).count();
if (elapsed < 1000) { // 1秒内
record.syn_count++;
if (record.syn_count > MAX_SYN_RATE) {
// 触发防护:SYN Cookie或丢弃
enableSYNCookie(src_ip);
return false;
}
} else {
record.syn_count = 1;
record.last_syn_time = now;
}
return true;
}
// 2. 序列号预测防护
bool validateSequence(uint32_t seq, uint32_t ack) {
// 严格的序列号检查
uint32_t expected = calculateExpectedSeq();
// 允许的窗口:RFC 793定义的窗口大小
uint32_t window_left = expected;
uint32_t window_right = expected + window_size_;
// 检查序列号是否在可接受窗口内
if (seq < window_left || seq > window_right) {
logAttack("Sequence prediction attempt detected");
sendRST(); // 发送重置
return false;
}
return true;
}
// 3. 分片攻击防护
bool validateFragments(const IPv4Header& ip) {
// 检查分片重叠(Teardrop攻击)
if (ip.frag_off & 0x1FFF) { // 是分片
if (ip.total_len > 65535 || ip.frag_off * 8 > 65535) {
return false; // 非法偏移
}
}
// 检查微小分片(Tiny Fragment攻击)
if (ip.total_len < 68) { // 小于最小MTU
logAttack("Tiny fragment attack detected");
return false;
}
return true;
}
};
4.2 TLS/SSL集成优化
现代TLS最佳实践:
class TLSOptimizer {
public:
struct TLSConfig {
bool enable_tls_1_3 = true; // 优先TLS 1.3
bool disable_tls_1_0 = true; // 禁用不安全的TLS版本
bool disable_tls_1_1 = true;
bool enable_ocsp_stapling = true; // OCSP装订
bool enable_session_tickets = true; // 会话票据
std::vector<std::string> cipher_suites = {
"TLS_AES_256_GCM_SHA384",
"TLS_CHACHA20_POLY1305_SHA256",
"TLS_AES_128_GCM_SHA256"
};
};
// 0-RTT数据防护(TLS 1.3特性)
bool validateZeroRTTData(const std::vector<uint8_t>& data) {
// 0-RTT数据重放攻击防护
static std::set<std::string> seen_0rtt_tokens;
std::string token = generateToken(data);
if (seen_0rtt_tokens.count(token)) {
// 检测到重放攻击
logSecurityEvent("TLS 0-RTT replay attack detected");
return false;
}
// 只允许幂等操作在0-RTT中
if (!isIdempotentOperation(data)) {
return false;
}
seen_0rtt_tokens.insert(token);
// 设置合理的过期时间
scheduleCleanup(token, 300); // 5分钟后清理
return true;
}
// 证书验证优化
bool verifyCertificateChain(const X509Certificate& cert) {
// 1. 检查证书吊销状态(CRL/OCSP)
if (!checkCertificateRevocation(cert)) {
return false;
}
// 2. 证书透明度检查
if (!checkCertificateTransparency(cert)) {
return false;
}
// 3. 密钥强度检查
if (cert.publicKeyBits() < 2048) {
return false; // RSA密钥至少2048位
}
// 4. 算法检查:禁用弱算法
if (cert.signatureAlgorithm() == "SHA1withRSA") {
return false; // 禁用SHA1
}
return true;
}
};
4.3 网络层安全:IPSec实践
class IPSecManager {
private:
enum class Mode { TRANSPORT, TUNNEL };
enum class Protocol { AH, ESP };
struct SecurityAssociation {
uint32_t spi; // 安全参数索引
std::vector<uint8_t> key;
Mode mode;
Protocol protocol;
time_t created;
time_t lifetime;
};
std::map<uint32_t, SecurityAssociation> sas_;
public:
// IPSec封装安全载荷(ESP)
std::vector<uint8_t> encryptESP(const std::vector<uint8_t>& plaintext,
const SecurityAssociation& sa) {
std::vector<uint8_t> ciphertext;
// ESP头部
struct ESPHeader {
uint32_t spi; // 安全参数索引
uint32_t seq; // 序列号
};
ESPHeader header{htonl(sa.spi), getNextSequence()};
// 加密载荷(使用AES-GCM等现代算法)
auto iv = generateIV();
auto encrypted = aesGCMEncrypt(plaintext, sa.key, iv);
// 组装:SPI + Seq + IV + 密文 + ICV
ciphertext.insert(ciphertext.end(),
reinterpret_cast<uint8_t*>(&header),
reinterpret_cast<uint8_t*>(&header) + sizeof(header));
ciphertext.insert(ciphertext.end(), iv.begin(), iv.end());
ciphertext.insert(ciphertext.end(),
encrypted.begin(), encrypted.end());
// 添加完整性校验值
auto icv = calculateICV(ciphertext, sa.key);
ciphertext.insert(ciphertext.end(), icv.begin(), icv.end());
return ciphertext;
}
// IKEv2密钥交换(现代替代方案)
bool performIKEv2Exchange(const Endpoint& peer) {
// 1. IKE_SA_INIT交换:协商加密算法,交换nonce
// 2. IKE_AUTH交换:相互认证,建立子SA
// 使用Diffie-Hellman交换生成共享密钥
auto dh_key = performDiffieHellman(peer);
// 生成加密密钥
auto keys = deriveKeys(dh_key, "ipsec-key-material");
// 建立安全关联
SecurityAssociation sa{
.spi = generateSPI(),
.key = keys,
.mode = Mode::TUNNEL,
.protocol = Protocol::ESP,
.created = time(nullptr),
.lifetime = 3600 // 1小时
};
sas_sa.spi = sa;
return true;
}
};

五、前沿技术与未来趋势
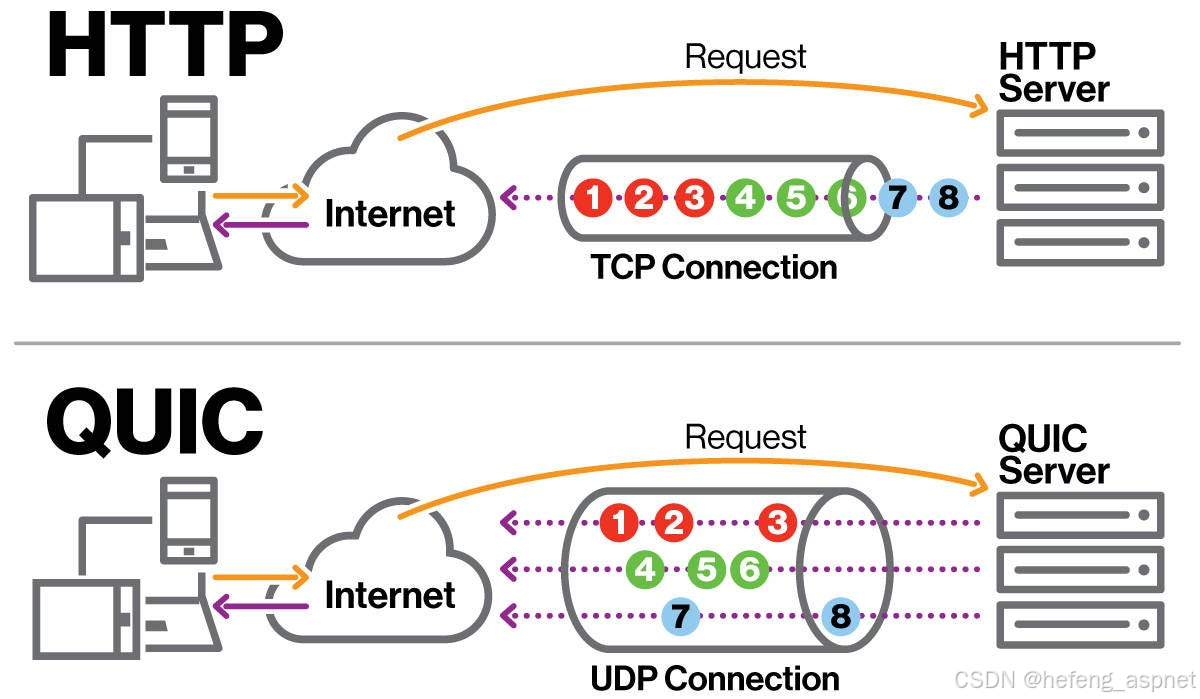
5.1 QUIC协议:TCP的替代者
class QUICConnection {
private:
// QUIC核心特性
struct ConnectionState {
uint64_t connection_id; // 连接ID(无握手)
uint64_t packet_number; // 包编号(独立递增)
std::map<uint64_t, Stream> streams; // 多路复用流
bool handshake_completed; // 0-RTT/1-RTT握手
};
public:
// QUIC vs TCP对比
void compareWithTCP() {
/*
TCP问题 QUIC解决方案
-
队头阻塞 每个流独立,无队头阻塞
-
握手延迟(3次) 0-RTT/1-RTT连接建立
-
协议僵化 UDP承载,用户空间实现
-
网络切换中断 连接迁移支持
-
加密弱 TLS 1.3强制加密
*/
}
// QUIC数据包结构
struct QUICPacket {
struct Header {
uint8_t flags; // 包类型标志
uint64_t conn_id; // 连接ID
uint64_t pkt_num; // 包编号
uint32_t version; // QUIC版本
};
Header header;
std::vector<Frame> frames; // 帧集合
std::vector<uint8_t> payload;
};
// 前向纠错(FEC)实现
std::vector<uint8_t> applyFEC(const std::vector<uint8_t>& data) {
// 使用Reed-Solomon等算法添加冗余
auto encoded = reedSolomonEncode(data, 0.2); // 20%冗余
// 即使丢失部分包也能恢复数据
return encoded;
}
};
5.2 eBPF:内核可编程网络
// eBPF程序:在内核实现TCP拥塞控制
SEC("tcp_congestion_control")
int bpf_cubic(struct bpf_sock_ops *skops)
{
switch (skops->op) {
case BPF_SOCK_OPS_TIMEOUT_INIT:
// 初始化超时参数
skops->reply = 10; // 10ms
break;
case BPF_SOCK_OPS_RTT_CB:
// RTT测量回调
update_cubic_params(skops);
break;
case BPF_SOCK_OPS_CONGESTION_CB:
// 拥塞事件处理
handle_congestion_event(skops);
break;
}
return 0;
}
// eBPF XDP程序:高性能数据包处理
SEC("xdp")
int xdp_firewall(struct xdp_md *ctx)
{
void *data_end = (void *)(long)ctx->data_end;
void *data = (void *)(long)ctx->data;
struct ethhdr *eth = data;
if (eth + 1 > data_end)
return XDP_ABORTED;
// 解析IP头部
struct iphdr *ip = data + sizeof(*eth);
if (ip + 1 > data_end)
return XDP_ABORTED;
// 实时过滤恶意IP(线速处理)
if (is_malicious_ip(ip->saddr)) {
bpf_printk("Blocked malicious IP: %pI4", &ip->saddr);
return XDP_DROP; // 直接丢弃,不进入协议栈
}
return XDP_PASS;
}
5.3 协议栈性能监控与调优
现代网络性能监控工具栈
1. 链路层监控
sudo tc -s qdisc show dev eth0
sudo ethtool -S eth0
2. IP层监控
sudo nstat -az # 实时IP/MIB统计
sudo ip -s link show eth0
3. TCP层深度监控(Linux)
安装:sudo apt-get install iproute2 tcptraceroute
sudo tcpretrans -i eth0 -l # 重传监控
sudo ss -tunap4 # Socket统计
4. 应用层监控
sudo tcpdump -i eth0 -w capture.pcap # 抓包分析
sudo wireshark capture.pcap # 图形化分析
5. 性能瓶颈定位脚本
#!/bin/bash
network_perf_diagnose.sh
echo "=== 网络性能诊断报告 ==="
echo "时间: $(date)"
echo ""
TCP连接状态统计
echo "1. TCP连接状态:"
ss -t -a | awk 'NR>1 {count$1++} END {for(s in count) print s": "counts"个"}'
重传率计算
echo -e "\n2. TCP重传率:"
retrans=(netstat -s \| grep "segments retransmitted" \| awk '{print 1}')
total=(netstat -s \| grep "segments sent out" \| awk '{print 1}')
if $total -gt 0 ; then
rate=(echo "scale=4; retrans / $total * 100" | bc)
echo "重传率: rate% (重传: retrans, 总发送: $total)"
fi
带宽使用率
echo -e "\n3. 带宽使用:"
interface="eth0"
rx_bytes_prev=(cat /sys/class/net/interface/statistics/rx_bytes)
tx_bytes_prev=(cat /sys/class/net/interface/statistics/tx_bytes)
sleep 1
rx_bytes_now=(cat /sys/class/net/interface/statistics/rx_bytes)
tx_bytes_now=(cat /sys/class/net/interface/statistics/tx_bytes)
rx_rate=(((rx_bytes_now - $rx_bytes_prev) * 8 / 1000000))
tx_rate=(((tx_bytes_now - $tx_bytes_prev) * 8 / 1000000))
echo "接收: {rx_rate}Mbps, 发送: {tx_rate}Mbps"
六、协议栈优化实战案例
案例:高并发Web服务器优化
class OptimizedHTTPServer {
private:
// 1. 使用epoll/kqueue/IOCP事件驱动
#ifdef linux
int epoll_fd_;
#elif APPLE
int kqueue_fd_;
#elif _WIN32
HANDLE iocp_port_;
#endif
// 2. 连接池管理
class ConnectionPool {
struct Connection {
int fd;
time_t last_activity;
SSL* ssl_ctx; // TLS连接复用
std::vector<uint8_t> buffer;
};
std::vector<Connection> pool_;
const size_t MAX_POOL_SIZE = 10000;
Connection& getOrCreate(int fd) {
// 连接复用逻辑
auto it = std::find_if(pool_.begin(), pool_.end(),
fd(const Connection& c) { return c.fd == fd; });
if (it != pool_.end()) {
it->last_activity = time(nullptr);
return *it;
}
// 新建连接
if (pool_.size() >= MAX_POOL_SIZE) {
// LRU淘汰
auto oldest = std::min_element(pool_.begin(), pool_.end(),
\[\](const Connection& a, const Connection& b) {
return a.last_activity < b.last_activity;
});
pool_.erase(oldest);
}
pool_.push_back({fd, time(nullptr), nullptr, {}});
return pool_.back();
}
};
// 3. TCP快速打开(TFO)
bool enableTFO() {
#ifdef linux
int qlen = 5;
return setsockopt(server_fd_, SOL_TCP, TCP_FASTOPEN,
&qlen, sizeof(qlen)) == 0;
#endif
return false;
}
// 4. 零拷贝发送
bool sendFileZeroCopy(int client_fd, const std::string& filepath) {
int file_fd = open(filepath.c_str(), O_RDONLY);
if (file_fd < 0) return false;
struct stat st;
fstat(file_fd, &st);
// 使用sendfile系统调用
off_t offset = 0;
ssize_t sent = sendfile(client_fd, file_fd, &offset, st.st_size);
close(file_fd);
return sent == st.st_size;
}
// 5. 内存池优化
class MemoryPool {
struct Block {
void* ptr;
size_t size;
bool in_use;
};
std::vector<Block> blocks_;
const size_t BLOCK_SIZE = 4096; // 页对齐
void* allocate(size_t size) {
// 查找空闲块
for (auto& block : blocks_) {
if (!block.in_use && block.size >= size) {
block.in_use = true;
return block.ptr;
}
}
// 分配新块(页对齐)
size_t alloc_size = ((size + BLOCK_SIZE - 1) / BLOCK_SIZE) * BLOCK_SIZE;
void* new_ptr = aligned_alloc(BLOCK_SIZE, alloc_size);
blocks_.push_back({new_ptr, alloc_size, true});
return new_ptr;
}
};
};
总结:协议栈优化的核心原则
- 分层优化:每层解决特定问题,避免跨层优化
- 端到端原则:智能放在端点,网络保持简单
- 渐进部署:兼容现有协议,平滑过渡
- 安全内置:安全不是附加功能,而是设计核心
- 可观测性:完善的监控是优化的前提
未来展望
- 协议定制化:针对应用特点优化协议栈
- AI驱动优化:机器学习预测网络行为
- 量子安全协议:抗量子计算攻击
- 卫星互联网协议:高延迟、高丢包环境优化
TCP/IP协议栈经过40多年发展,依然是互联网的基石。理解其原理、掌握优化技巧、关注安全实践,是每个网络工程师的必修课。随着新技术不断涌现,协议栈也在持续演进,但核心的设计哲学依然闪耀着智慧的光芒。
如果您喜欢此文章,请收藏、点赞、评论,谢谢,祝您快乐每一天。