06. Hudi Spark 集成分析
主题说明
Hudi 与 Spark 的集成主要通过 Spark DataSource API 实现,让 Spark 能够读写 Hudi 表。理解 Spark 集成有助于理解如何在 Spark 中使用 Hudi。
Spark 集成包括:
- DataSource API:实现 Spark 的数据源接口
- SparkRDDWriteClient:Spark 的写入客户端
- HoodieSparkEngineContext:Spark 引擎上下文
- Spark SQL 集成:支持 Spark SQL 查询
细化内容
DataSource API 集成
Hudi 通过 BaseDefaultSource 实现 Spark DataSource API,支持通过 spark.read.format("hudi") 和 df.write.format("hudi") 读写数据。
主要接口:
DataSourceRegister:注册数据源名称RelationProvider:提供数据源关系CreatableRelationProvider:支持写入
数据源配置:
path:表的路径hoodie.datasource.*:Hudi 特定配置
SparkRDDWriteClient - Spark 写入客户端
SparkRDDWriteClient 是 Spark 的写入客户端,它封装了写入逻辑。
主要方法:
upsert():更新或插入记录insert():插入新记录delete():删除记录commit():提交写入操作
特点:
- 使用 JavaRDD 作为数据容器
- 支持分布式写入
- 自动管理 Commit
HoodieSparkEngineContext - Spark 引擎上下文
HoodieSparkEngineContext 是 Spark 的引擎上下文实现,它封装了 Spark 的上下文信息。
主要功能:
- 并行化:将数据转换为 RDD
- 聚合操作:使用 Spark 的聚合功能
- 任务调度:管理 Spark 任务
- 累加器:使用 Spark 累加器统计信息
Spark SQL 集成
Hudi 支持 Spark SQL 查询,通过 Catalog 和 Extension 实现。
Catalog 集成:
- 注册 Hudi 表到 Spark Catalog
- 支持
CREATE TABLE语句 - 支持表属性配置
Extension 集成:
- Spark SQL Extension 支持 Hudi 特定语法
- 支持时间旅行查询
- 支持增量查询
关键技术
RDD 转换
Hudi 使用 JavaRDD 作为数据容器,需要与 Spark 的 RDD 系统集成:
- 数据转换:将 HoodieRecord 转换为 RDD
- 分区管理:使用 Spark 的分区机制
- 序列化:使用 Kryo 序列化
写入流程
Spark 写入流程:
- 数据准备:将 DataFrame 转换为 RDD
- 分区处理:按分区处理数据
- 索引查找:查找记录位置
- 文件写入:写入数据文件
- 提交:创建 Commit
查询优化
Hudi 在 Spark 中的查询优化:
- 谓词下推:在文件层面过滤数据
- 列裁剪:只读取需要的列
- 分区裁剪:只扫描相关分区
关键对象说明
类关系图
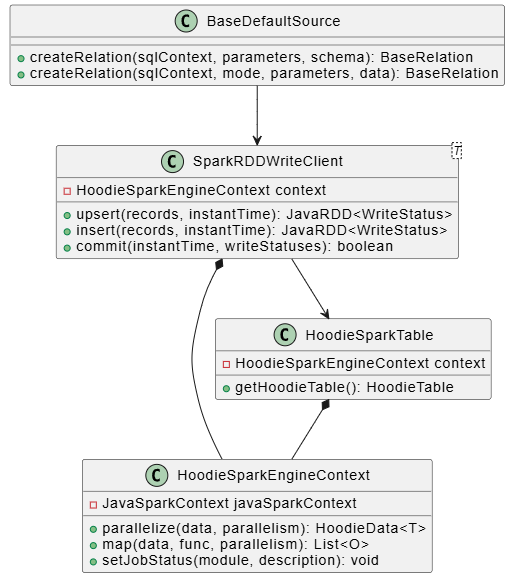
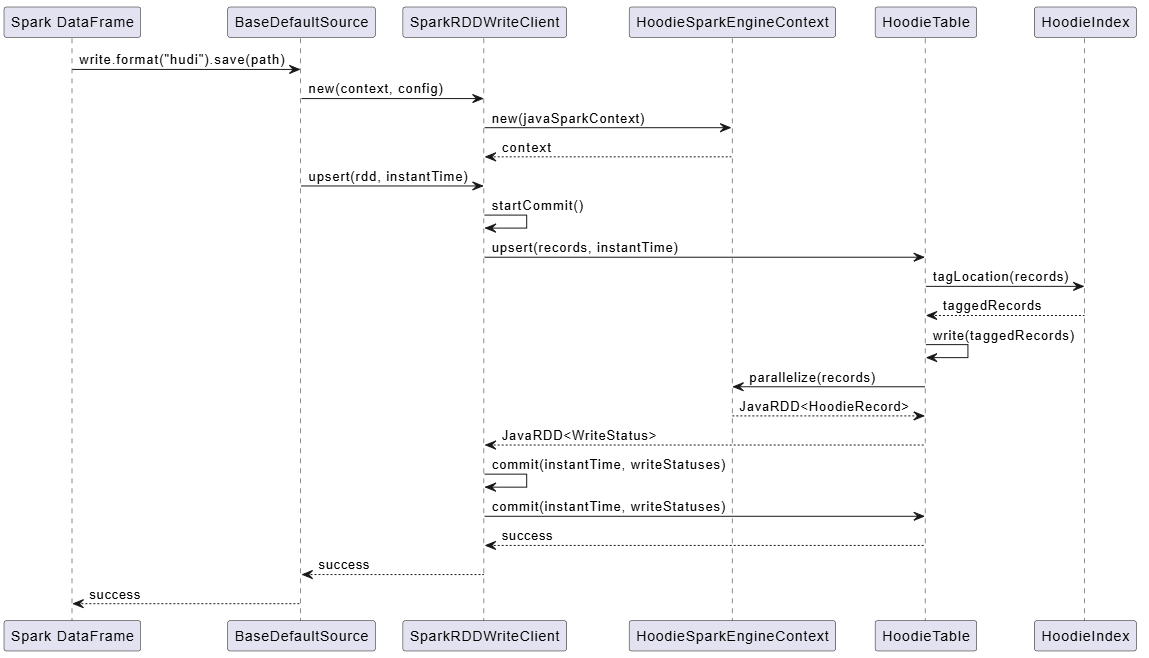
关键操作时序图
代码示例
Spark 写入示例
scala
import org.apache.spark.sql.SaveMode
val df = spark.read.json("input.json")
df.write
.format("hudi")
.option("hoodie.datasource.write.table.type", "COPY_ON_WRITE")
.option("hoodie.datasource.write.table.name", "my_table")
.option("hoodie.datasource.write.recordkey.field", "id")
.option("hoodie.datasource.write.partitionpath.field", "partition")
.option("hoodie.datasource.write.keygenerator.class", "org.apache.hudi.keygen.SimpleKeyGenerator")
.mode(SaveMode.Overwrite)
.save("/path/to/table")Spark 查询示例
scala
val df = spark.read
.format("hudi")
.load("/path/to/table")
df.show()总结
Hudi 与 Spark 的集成通过 DataSource API 实现,支持读写操作。核心要点:
- BaseDefaultSource 实现 Spark DataSource API
- SparkRDDWriteClient 是 Spark 的写入客户端
- HoodieSparkEngineContext 封装 Spark 上下文
- Spark SQL 支持通过 Catalog 和 Extension 集成
- RDD 转换 使用 JavaRDD 作为数据容器
- 查询优化 支持谓词下推、列裁剪等
理解 Spark 集成有助于在 Spark 应用中高效使用 Hudi。