LightOnOCR-2-1B:10 亿参数的轻量级 OCR 革命,速度与精度双杀
OCR 进入"端到端 + 轻量化"新纪元
在文档处理领域,传统 OCR(光学字符识别)系统长期依赖复杂的多阶段流水线:图像预处理 → 文本检测 → 文字识别 → 布局分析 → 后处理。这种架构不仅脆弱、维护成本高,还难以处理表格、数学公式或多列排版等复杂场景。
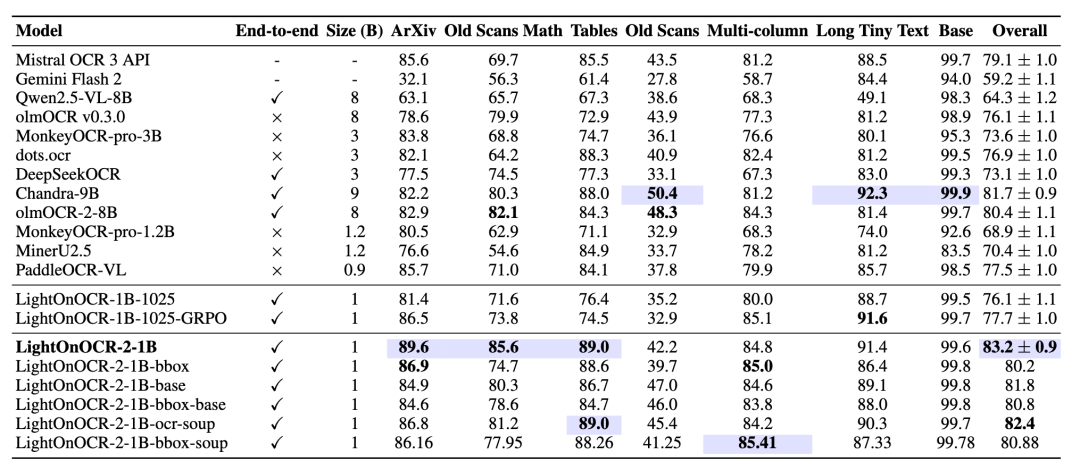
而今天,随着 LightOnOCR-2-1B 的发布,这一切正在被颠覆。这款仅 10 亿参数的端到端视觉语言模型,不仅在权威基准 OlmOCR-Bench 上登顶 SOTA(得分 83.2),还以 比 Chandra-9B 快 3.3 倍、模型体积小近 9 倍 的优势,证明了"小模型也能打大仗"。
更重要的是------它完全开源(Apache 2.0),支持 Hugging Face Transformers,可微调、可部署、可商用。

一、 性能飞跃:小身材,大能量
LightOnOCR-2-1B 是对第一代 LightOnOCR-1B-1025 的全面升级。尽管仅拥有约 10 亿参数,其体量仅为竞争对手(如 Chandra-9B)的九分之一,但在 OlmOCR-Bench 基准测试中,LightOnOCR-2-1B 凭借 83.2 ± 0.9 的惊人得分,超越了包括 Chandra-9B 在内的所有评估系统。
这一显著提升得益于更高质量的标注数据、更广泛的数据规模以及对欧洲语言和科学文献的深度优化。特别是在以下场景中,模型表现尤为卓越:
-
ArXiv 科学文献: 对复杂数学公式和 LaTeX 处理更加精准。
-
旧式扫描件: 对图像退化和扫描噪点具有极强的鲁棒性。
-
复杂表格: 能够完美保留多列布局和表格结构。
二、 速度狂飙:专为大规模生产设计
在企业级应用中,吞吐量往往与准确度同等重要。LightOnOCR-2-1B 在这一维度上实现了对主流竞品的全面碾压:
-
对比 Chandra OCR: 速度快 3.3 倍
-
对比 OlmOCR: 速度快 1.7 倍
-
对比 DeepSeekOCR: 速度快 1.73 倍
-
对比 PaddleOCR-VL-0.9B: 速度快 2 倍
-
对比 dots.ocr: 速度快 5 倍
在实际生产环境中,基于单个 H100 GPU,LightOnOCR-2-1B 可达到 5.71 页/秒 的处理速度(约合每天 49.3 万页),成本控制在 每 1000 页低于 0.01 美元。这种极致的效率使其非常适合大规模文档处理流程。
三、 端到端架构:拒绝脆弱的管道
不同于传统依赖多阶段拼接的 OCR 方案,LightOnOCR-2-1B 采用完全可微分的端到端架构。这意味着:
-
无需外部组件: 没有脆弱的预处理或后处理管道,简化了部署复杂度。
-
多功能合一: 不仅能输出干净、自然排序的文本,还能通过变体模型直接预测嵌入图形/图像的边界框,为布局分析和文档理解提供强有力的支持。
-
全能手: 轻松处理表格、收据、表单、多列布局以及复杂的数学符号。
四、 开源生态与易用性
为了推动社区发展,LightOnOCR-2 在 Apache 2.0 许可证下发布,并附带了一系列开放权重的检查点,包括 OCR 专注型、边界框功能型以及用于微调的基础检查点。
- 巨大的数据集贡献
LightOn AI 公开了两个训练期间使用的高质量数据集:
lightonai/LightOnOCR-mix-0126: 包含超过 1600 万页高质量标注文档。
lightonai/LightOnOCR-bbox-mix-0126: 包含近 50 万个带有图形和图像边界框的高质量标注。
- 极致的兼容性
开发者无需依赖 vLLM 等复杂推理引擎,可直接使用标准的 Transformers 工具运行模型。无论是使用 LoRA/PEFT 进行微调,还是在 CPU/低吞吐量环境下进行本地推理,LightOnOCR-2-1B 都提供了极高的灵活性。
五、 实用建议:如何获得最佳效果
为了充分发挥 LightOnOCR-2-1B 的性能,官方推荐以下预处理技巧:
-
格式: 将 PDF 渲染为 PNG 或 JPEG 格式。
-
分辨率: 目标最长维度设置为 1540px。
-
几何结构: 保持原始宽高比,以保留文本的几何形状。
-
策略: 每页使用一张图片,并利用 vLLM 支持批处理以提高效率。
LightOnOCR-2-1B 不仅仅是一个模型,更是一套完整的文档处理解决方案。它用事实证明,在 1B 参数规模下,通过高质量的训练数据和创新的架构设计,完全可以在速度、精度和成本之间实现完美的平衡。对于需要进行文档数字化、科学文献解析或大规模 OCR 落地的开发者和企业来说,这无疑是一个不容错过的最佳选择。
**模型:**https://huggingface.co/lightonai/LightOnOCR-2-1B
**演示:**https://huggingface.co/spaces/lightonai/LightOnOCR-2-1B-Demo