一、导语
得物社区推荐的实践中,我们发现用户兴趣容易收敛到少数几个主兴趣上,难以做到有效的兴趣拓展,通过将大模型与推荐结合的方式,在得物社区的用户兴趣拓展方向上切实取得了突破,拿到了显著的业务收益并推全上线。因此我们将相关工作中采用的核心算法与模型策略总结整理,投稿了AAAI-PerFM,入选了长论文《Enhancing Serendipity Recommendation System by Constructing Dynamic User Knowledge Graphs with Large Language Models》。AAAI Conference on Artificial Intelligence)由人工智能促进会(AAAI)主办,是人工智能领域历史最悠久的国际学术会议之一。以下内容为正文的详细介绍。
二、背景介绍
得物社区作为得物的首tab,满足得物用户分享生活、发现好物的内容生产消费需求。跟其他内容平台一样,得物的社区推荐系统也存在"推荐 → 用户反馈 → 再推荐"的反馈闭环问题,系统会越来越倾向于推送相似内容,导致推荐结果收敛、同质化,进而形成信息茧房,降低用户的新鲜感与满意度。
同时随着大语言模型(LLM)的发展,世界知识提取的效率逐渐得到提升,为打破信息茧房,提高用户内容消费的新鲜感带来了新的机遇。我们提出用大语言模型(LLM)来动态构建用户知识图谱(User Knowledge Graph),并在知识图谱上进行更可控的推理来挖掘用户"潜在兴趣",再把这些潜在兴趣以工程可落地的方式接入工业推荐链路,在得物社区业务场景取得了显著的消费指标收益。
得物App的社区页示例:
三、问题与挑战
1.为了打破信息茧房并提升用户体验,新颖性推荐应该给用户推荐意料之外的物品,并且吸引用户点击,即同时具备意外性和相关性。但受限于意外发现数据的稀缺性,近些年的研究往往只能采用较小的模型,或者在有偏差的推荐数据的基础上进行数据扩充,这可能反而会强化反馈循环,增大打破信息茧房和识别新颖性物品的难度。
2.虽然大语言模型拥有丰富的世界知识,并展现出卓越的理解和推理能力。但在将大模型推理落地到推荐系统的实践中,依然发现大模型难以通过单跳推理正确生成复杂问题的答案。
3.工业推荐系统对实时性有要求,通常响应时间在100ms内。基于大模型的新颖性推荐有较高的延迟,计算成本高昂。
4.当推理生成出用户潜在兴趣后,在推荐系统中如何高效地召回相关候选item,既要保证item与用户潜在兴趣的相关性,又要兼具高消费效率的特性(比如拥有更好的点击率,保护用户消费体验),是能否在工业场景取得收益的关键。
四、优化方案
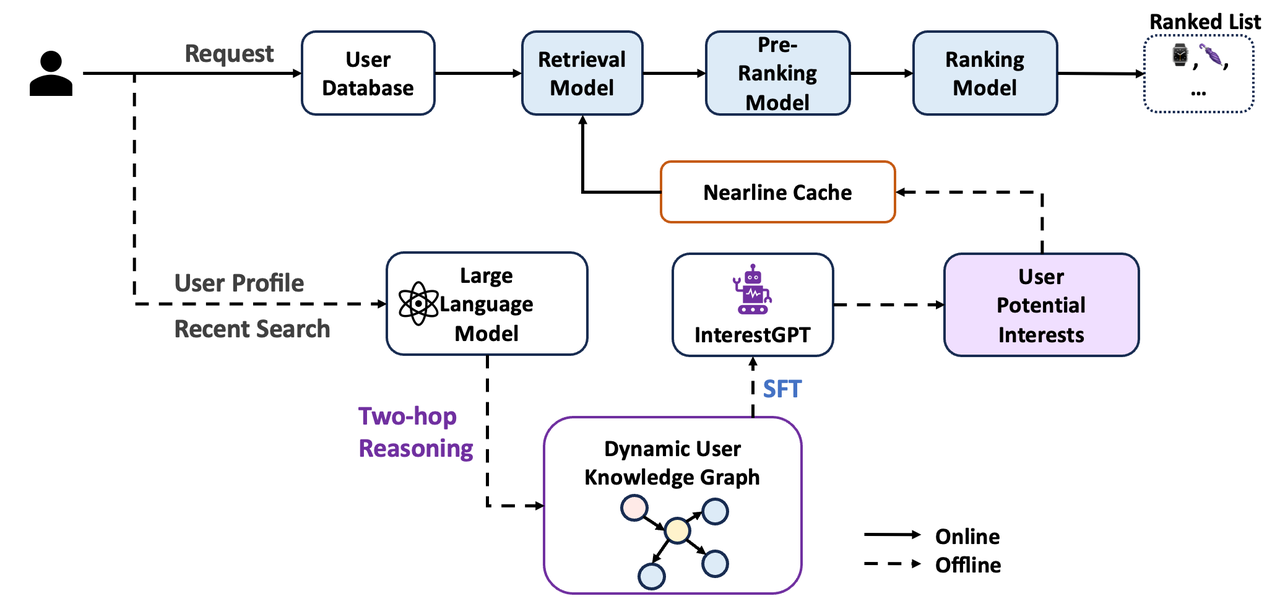
整体框架如上图所示:
1.采用大语言模型替代传统小模型,从用户行为中提取潜在兴趣,从而缓解显式兴趣发现数据稀缺的问题。
2.通过两跳推理与多智能体多轮辩论机制,提升大模型在兴趣推理中的准确性与稳定性,保障输出质量。
3.采用近线召回架构进行工程部署,缓解大模型推理时延较高的挑战,实现推荐系统的实时响应。
4.引入对比学习,将大模型提取的兴趣与推荐系统内现有用户兴趣表征进行对齐,确保召回内容既符合用户潜在偏好,又具备高相关性与高消费转化效率的特点。
基于LLM大模型兴趣提取过程:
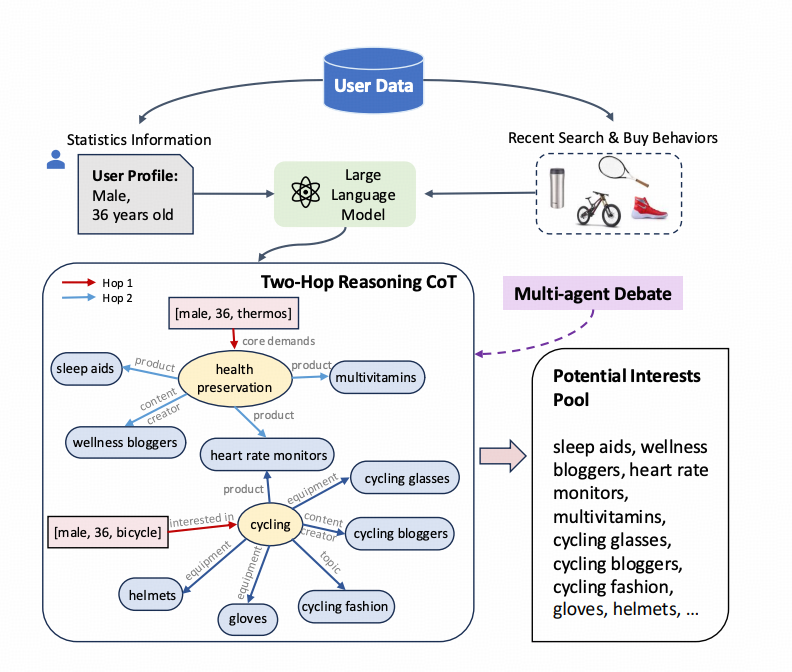
两跳推理
用户的静态画像(年龄、性别)以及用户的历史行为(过去30天的搜索词)作为初始输入节点,大模型作为用户动态图谱构建工具:
将大模型作为知识图谱构建器,动态构建节点和关系 G=(V,E),其中 V 是实体集合,E 是关系集合。给定两个实体 v1 和 v3,目标是通过两跳推理判断它们之间是否存在潜在兴趣关系。
- 第一步: 从 用户静态画像和搜索词v1 出发,找到满足上位关系的节点v2。
- 即找到所有满足 (v1,v2)∈E 的 v2。
- v2是v1的核心述求和动机。
- 第二步: 从 v2 出发,找到所有满足用户核心诉求的同位或者下位的节点 v3。
- 即找到所有满足 (v2,v3)∈E 的 v3。
- 为了避免不相关的输出并减少幻觉v3限制在商品、商品类目、话题范围。
多智能体多回合辩论
通过提示工程根据用户静态画像和用户行为构建用户动态画像及完成两跳推理,会出现推理路径错误及潜在兴趣不相关问题。在本文中,我们采用了一种互补方法来改进推理过程和输出响应,其中多个语言模型实例在多个回合中提出和辩论其各自的响应和推理过程,以得出共同的最终答案。 我们发现,这种方法显著增强了任务的两跳推理能力。同时这种方法还提高了生成内容的事实有效性,减少了当代模型容易出现的谬误答案和幻觉。
具体来说,我们首先提示每个代理独立解决给定的问题或任务。 在每个代理生成回复后,我们向每个代理提供一个共识提示,如图 所示,其中每个代理被指示根据其他代理的回复更新其回复。 然后可以使用每个代理的更新回复反复给出此生成的共识提示。

SFT
为了降低部署成本,我们先使用参数量较大的推理模型deepseek-r1构建户动态图谱(思考过程)和生成潜在兴趣作,然后蒸馏到参数量更小的模型qwq-32b。将思考过程和潜在兴趣转换为文本化的SFT数据集D,其中每个条目是一个元组(x,y)。 这里,y 指的是输出,代表思考过程和潜在兴趣,而x 代表输入提示,输入和输出如图接下来,遵循如下公式,对qwq-32b进行监督微调得到interestGPT,以提高其生成期望回答的概率。
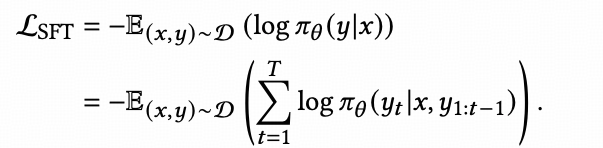
大模型兴趣在推荐系统中的应用
为了兼顾i2i召回和u2i召回的优点,我们设计了一种兼具i2i召回能力的u2i召回模型。具体而言,双塔召回模型是多任务目标,在传统双塔u2i的BCE-Loss基础上,在user塔中引入了基于兴趣对齐的对比学习损失,通过最大化相同兴趣下用户嵌入与物品嵌入之间的相似性,同时最小化不同兴趣下用户嵌入与物品嵌入之间的相似性,从而在预估阶段能够基于用户新兴趣生成与之高相关度的user-embedding。这样得到的embedding用于向量检索召回,召回得到的item集合不仅与新兴趣保持了高度的相关性,同时保持了u2i召回的消费效率高的优点。
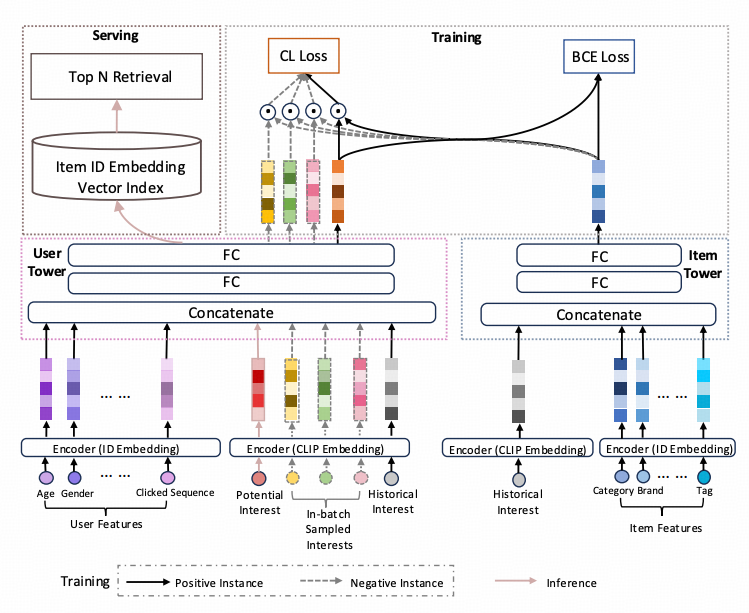

模型输入
用户塔的输入特征包括:用户静态画像如:年龄、性别等,用户历史交互物品序列特征如类目、品牌、标签等,这些特征通过id-emddding的方式表征为fᵘ;用户兴趣,用户兴趣通过文本编码器获得
embedding
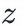
。在训练阶段,用户兴趣正样本是用户点击过的物品,用户兴趣负样本是batch内采样的其他物品,在推理阶段,用户兴趣是通过两跳推理生成的潜在新兴趣。文本编码器可以选择 CLIP、BERT、USE、BGE 等模型, 在我们的实验中,我们选择了 CLIP 作为编码器。值得注意的是,大模型推理出来的新兴趣只在推理的时候使用,而不参与到训练过程中。
双塔模型
物品塔的输入包含:物品的静态特征,如:类目体系、品牌、标签等,这些特征用id-embdedding进行表征
用户塔:将用户特征fᵘ
和历史兴趣
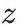
拼接,通过两层全连接层得到
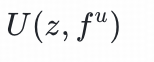
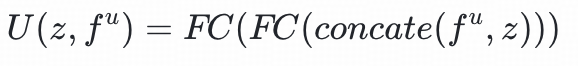
物料塔:将物品特征fᵘ
和历史兴趣
拼接,通过两层全连接层得到
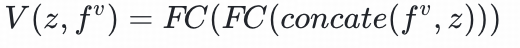
训练阶段
通过双塔模型来训练用户点击样本同时,我们希望对于同一用户,不同的z输入user塔后得到的兴趣表征具有较大的区分度:
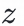
兴趣下的用户兴趣表征
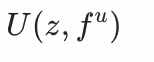
要与同为
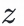
兴趣
的物品表征更加相关,他们之间的关联度要大于其他
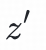
兴趣下的用户兴趣表征
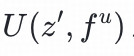
与
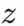
兴趣的物品表征。这样就能尽可能做到,输入用户的潜在兴趣给到user towel的时候,就能获取到用户新颖性兴趣的表征而不至于与已有的兴趣混淆。
因此,我们引入了对比学习
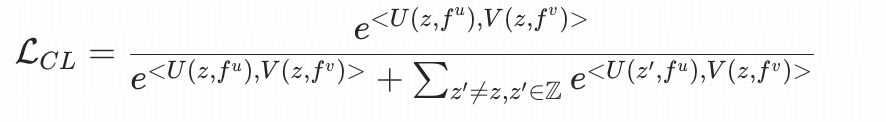
综合以上考虑,我们采用多目标联合训练的方法,采用multi-task loss,由对比学习损失和二分类交叉熵损失构成:
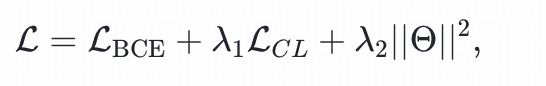
其中,

是模型的参数集合,
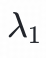
和
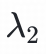
是超参数。
另外交叉熵损失用于建模用户对历史物品的点击偏好,其公式为:
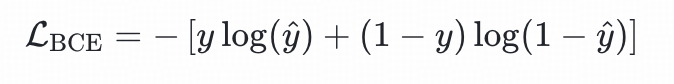
其中,
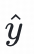
是对物品
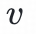
的点击概率的预测值。
预估阶段
在预估阶段,首先将用户的某个潜在新兴趣
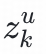
(1<=k<=n,n为用户u潜在新兴趣总数)连同用户特征一起输入user塔,获得用户新兴趣表征向量
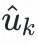
。利用
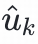
进行ann检索得到物品集合,作为潜在兴趣
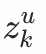
的召回结果。将用户所有的潜在新兴趣的召回结果归并在一起,与其他召回通道内容一同给到后续的推荐链路中。
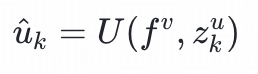
五、实验效果
我们在得物App(Dewu)上进行实验,得物App是一个拥有数千万用户的潮流电子商务平台。我们随机选取了得物社区10%的流量来进行A/B实验,目标是基于用户历史搜索词和静态画像,生成用户潜在兴趣,并为其推荐意外物品。我们选择得物原有的社区推荐召回系统作为基线,使用CLIP模型作为兴趣文本encoder,在此基础上为新颖性推荐新增了一个召回渠道。
我们使用8个指标来衡量在线性能:人均时长(AVDU),UVCTR,人均阅读量(ACR),UV互动渗透(ER),人均一级类目点击数(ACC-1),人均三级类目点击数(ACC-3),一级类目新颖性曝光占比(ENR)和一级类目新颖性点击占比(CNR)。其中人均一级类目点击数,人均三级类目点击数是用于评估多样性的指标。我们将一级类目新颖性定义为:当某物品的一级类目不在用户最近200次点击记录的一级类目集合内时,该物品的曝光或点击即具有一级类目新颖性。通过计算一级类目新颖性曝光占所有曝光的比例,以及一级类目新颖性点击占所有点击的比例,评估推荐系统的新颖性表现。
我们用deepseek-r1生成的3万条数据做标注样本,对qwq-32b模型经过sft后得到模型interestGPT,使用离线评估标准对interestGPT在1万条测试集上评估,抽样1000个用户评估结果如下: 0分占比:1%,1分占比:3%,2分占比:96%。

为了评估我们方法的在线效果,我们随机选取了大盘10%的流量进行A/B测试。我们在基线的基础上,为新颖性推荐新增了一个召回渠道。在新颖性召回渠道中,我们基于用户最近30天的用户搜索行为进行潜在兴趣拓展,每个用户最多选择16个潜在兴趣,每个兴趣召回40个对应的item。然后将这一路召回与其他渠道融合得到最终的召回结果。
最终的线上实验效果如下:

和baseline相比,我们的方法显著提升了推荐结果的多样性和新颖性。我们的方法在AVDU上相对提升0.15%。 UVCTR、ACR和ER分别提升了0.07%,0.15%,0.3%。在多样性方面,ACC-1 和ACC-3分别取得了0.21% 和0.23%的提升。对于新颖性,ENR和CNR分别取得了4.62%和4.85%的显著提升。
新颖性召回渠道对于推荐内容多样性和新颖性的改善是持续的。对照组的曝光新颖率为14.24%,实验组中新颖性召回通道的召回新颖率为26.53%,其他通道的召回新颖率为16.17%。这说明,当新颖性召回引入了新的信号,用户进行了新的交互,产生了和新兴趣有关的训练数据之后,其他召回通道也能够迅速捕捉到用户的新兴趣信号,从而打破反馈循环现象,冲破推荐茧房。
六、结论
这项工作通过提出利用大模型构建用户动态知识图谱并通过两跳推理来解决推荐系统中的信息茧房问题。 它包括两个阶段:两跳推理,通过大语言模型将用户静态画像和历史行为动态构建用户知识图谱,在构建的图谱上进行两跳推理;近线自适应,用于高效的工业部署。 同时设计了一种兼具i2i召回能力的u2i模型,召回得到的item集合不仅与新兴趣保持了高度的相关性,同时保持了u2i召回的item消费效率高的优点。
并部署了训练推理解耦的召回模型,利用大模型产出的新兴趣,生成对应的多兴趣user-embedding,将用户潜在兴趣召回结果集成到推荐系统中。无论是离线还是在线实验都取得了显著收益,完全可以在大规模工业系统上部署并拿到收益。
七、总结与展望
目前,我们主要基于得物App中的用户搜索行为构建兴趣挖掘模型。由于搜索行为本身具有较高的稀疏性,未来将引入点击、浏览、收藏等更丰富的交互行为,以探究在多行为数据融合下大语言模型对用户潜在兴趣的刻画能力,并验证兴趣建模是否存在与数据规模相关的扩展规律。在系统应用层面,除了在召回环节引入用户新兴兴趣外,还可进一步将兴趣表征融合至粗排、精排及重排等排序阶段,从而提升新兴趣场景下的物品评分准确性。此外,也可结合推荐场景中的实时用户反馈数据,对模型输出的多元兴趣进行动态校准,避免兴趣过度发散,确保其与用户真实需求的相关性。在大模型生成式架构基础上,我们同步探索并构建了生成式召回模型,目前已取得初步成果,并在得物推荐场景中全面上线应用。未来,我们将持续加大该方向的研发投入。
每一次技术迭代,其最终目标始终是服务于用户体验的提升。正如得物始终秉持的初心------我们希望通过智能推荐技术的持续进化,助力每一位用户更精准、更愉悦地「得到美好事物」。
往期回顾
1.Galaxy比数平台功能介绍及实现原理|得物技术
2.得物App智能巡检技术的探索与实践
3.深度实践:得物算法域全景可观测性从 0 到 1 的演进之路
4.前端平台大仓应用稳定性治理之路|得物技术
5.RocketMQ高性能揭秘:承载万亿级流量的架构奥秘|得物技术
文 /流煜曦
关注得物技术,每周更新技术干货
要是觉得文章对你有帮助的话,欢迎评论转发点赞~
未经得物技术许可严禁转载,否则依法追究法律责任。