文章目录
-
- 进程间通信(一):IPC基础与管道机制深度剖析
- 一、进程间通信概述
-
- [1.1 为什么需要进程间通信](#1.1 为什么需要进程间通信)
- [1.2 进程间通信的四大目的](#1.2 进程间通信的四大目的)
- [1.3 进程间通信的发展历史](#1.3 进程间通信的发展历史)
- [1.4 进程间通信分类体系](#1.4 进程间通信分类体系)
- 二、管道的本质与原理
-
- [2.1 什么是管道](#2.1 什么是管道)
- [2.2 管道在内核中的实现](#2.2 管道在内核中的实现)
- [2.3 站在文件描述符角度理解管道](#2.3 站在文件描述符角度理解管道)
- [2.4 站在内核角度理解管道本质](#2.4 站在内核角度理解管道本质)
- 三、匿名管道深度剖析
-
- [3.1 pipe系统调用](#3.1 pipe系统调用)
- [3.2 单进程使用管道](#3.2 单进程使用管道)
- [3.3 用fork共享管道原理](#3.3 用fork共享管道原理)
- [3.4 父子进程管道通信实战](#3.4 父子进程管道通信实战)
- [3.5 管道的读写规则](#3.5 管道的读写规则)
-
- [3.5.1 读端的行为](#3.5.1 读端的行为)
- [3.5.2 写端的行为](#3.5.2 写端的行为)
- [3.6 管道的特点总结](#3.6 管道的特点总结)
- 四、管道的高级特性
-
- [4.1 PIPE_BUF与原子性](#4.1 PIPE_BUF与原子性)
- [4.2 管道容量](#4.2 管道容量)
- [4.3 验证管道的4种边界情况](#4.3 验证管道的4种边界情况)
- 五、管道的应用场景
-
- [5.1 实现进程间的协作](#5.1 实现进程间的协作)
- [5.2 实现简单的shell管道](#5.2 实现简单的shell管道)
- 六、总结
进程间通信(一):IPC基础与管道机制深度剖析
💬 欢迎讨论:在学习了进程概念、进程控制之后,我们知道每个进程都有独立的地址空间。但实际开发中,进程之间经常需要协作完成任务,比如浏览器的渲染进程和网络进程需要交换数据,shell需要将一个命令的输出传给另一个命令。那么,进程之间如何通信呢?本篇将带你深入理解Linux进程间通信的基础------管道机制,从原理到实战,层层剖析。
👍 点赞、收藏与分享:这篇文章包含了IPC的完整分类、管道的底层原理、大量实战代码和边界情况测试,内容深入且实用,如果对你有帮助,请点赞、收藏并分享!
🚀 循序渐进:建议先掌握进程相关知识(fork、execl、进程地址空间等),这样理解进程间通信会更轻松。
一、进程间通信概述
1.1 为什么需要进程间通信
在前面的学习中,我们知道每个进程都有独立的虚拟地址空间,这是操作系统为了保护进程而设计的机制。
bash
进程A的地址空间 进程B的地址空间
┌──────────────┐ ┌──────────────┐
│ 栈 │ │ 栈 │
├──────────────┤ ├──────────────┤
│ 堆 │ │ 堆 │
├──────────────┤ ├──────────────┤
│ 数据段 │ │ 数据段 │
├──────────────┤ ├──────────────┤
│ 代码段 │ │ 代码段 │
└──────────────┘ └──────────────┘
隔离! 隔离!这种隔离带来了安全性,但也带来了问题:进程之间如何协作?
举个实际例子:
bash
# 在shell中执行
cat file.txt | grep "error" | wc -l这条命令背后发生了什么?
bash
1. cat进程读取文件内容
2. 将内容传递给grep进程
3. grep过滤出包含"error"的行
4. 将结果传递给wc进程
5. wc统计行数
三个进程协作完成任务!如果没有进程间通信,这种协作根本无法实现。
1.2 进程间通信的四大目的
根据实际应用场景,进程间通信主要有四个目的:
1. 数据传输
一个进程需要将它的数据发送给另一个进程。
c
// 场景:父进程读取文件,子进程处理数据
父进程: 读取100MB的日志文件
↓ (通过管道传输)
子进程: 解析日志,提取关键信息2. 资源共享
多个进程之间共享同样的资源,避免重复加载。
bash
# 场景:多个进程共享配置文件
进程A ──┐
├──→ 共享内存(存储配置) ←──┐
进程B ──┘ ├── 进程C3. 通知事件
一个进程需要向另一个或一组进程发送消息,通知它们发生了某种事件。
c
// 场景:子进程退出时通知父进程
子进程: exit(0)
↓ (发送SIGCHLD信号)
父进程: 收到信号,调用waitpid回收资源4. 进程控制
一个进程希望完全控制另一个进程的执行,比如调试器。
bash
# 场景:gdb调试程序
gdb程序 ──控制──→ 被调试程序
├─ 设置断点
├─ 单步执行
├─ 查看变量
└─ 修改内存1.3 进程间通信的发展历史
Linux的IPC机制经历了三个发展阶段:
bash
时间轴:
1970s 1980s 1990s 现在
│ │ │ │
▼ ▼ ▼ ▼
管道(Pipe) System V IPC POSIX IPC 全部共存
│ │ │
│ ├─ 消息队列 ├─ 消息队列
│ ├─ 共享内存 ├─ 共享内存
│ └─ 信号量 ├─ 信号量
│ ├─ 互斥量
│ ├─ 条件变量
│ └─ 读写锁
│
├─ 匿名管道(最早的IPC)
└─ 命名管道(FIFO)为什么有这么多IPC机制?
不同的机制适用于不同的场景:
- 管道:简单的单向数据流
- 共享内存:大量数据的高速传输
- 消息队列:带优先级的消息传递
- 信号量:同步与互斥控制
1.4 进程间通信分类体系
下面是Linux中所有IPC机制的完整分类:
bash
进程间通信(IPC)
│
├─ 管道(Pipe)
│ ├─ 匿名管道(pipe) ← 本篇重点
│ └─ 命名管道(FIFO) ← 下篇重点
│
├─ System V IPC
│ ├─ System V 消息队列
│ ├─ System V 共享内存 ← 下下篇重点
│ └─ System V 信号量
│
└─ POSIX IPC
├─ POSIX 消息队列
├─ POSIX 共享内存
├─ POSIX 信号量
├─ 互斥量(Mutex)
├─ 条件变量(Condition Variable)
└─ 读写锁(Read-Write Lock)本系列重点:
我们主要学习管道 和System V共享内存,因为:
- 管道是最基础、最常用的IPC机制
- 共享内存是性能最高的IPC机制
- 这两个在校招笔试面试中考察最多
二、管道的本质与原理
2.1 什么是管道
定义:
管道是Unix中最古老的进程间通信形式。我们把从一个进程连接到另一个进程的一个数据流称为一个"管道"。
生活中的类比:
你可以把管道想象成水管:
bash
水龙头(进程A) ──→ [水管] ──→ 水桶(进程B)
↑
管道- 水龙头只能往水管里灌水(写端)
- 水桶只能从水管里接水(读端)
- 水只能单向流动(单工)
2.2 管道在内核中的实现
管道在内核中是如何实现的呢?
核心思想:管道本质上是内核维护的一块缓冲区。
bash
用户空间:
进程A 进程B
write(fd[1], data, len) read(fd[0], buf, len)
│ ▲
└──────────┐ ┌──────────┘
│ │
▼ │
═══════════════════════════════════════════
内核空间:
┌─────────────────┐
│ 管道缓冲区 │ ← 内核维护的一块内存
│ (默认64KB) │
│ │
│ [数据...] │
└─────────────────┘关键点:
- 管道是内核对象,不是文件
- 但通过文件描述符来访问
- 遵循"一切皆文件"的Unix哲学
2.3 站在文件描述符角度理解管道
还记得我们学过的文件描述符吗?
c
struct task_struct { // 进程描述符
// ...
struct files_struct *files; // 文件描述符表
// ...
};
struct files_struct {
struct file *fd_array[NR_OPEN]; // 文件描述符数组
};
struct file { // 文件对象
struct file_operations *f_op; // 文件操作函数指针
// ...
};创建管道后的数据结构:
bash
进程A的────────┐
│ fd │ 指针 │
├─────┼──────────┤
│ 0 │ stdin │
│ 1 │ stdout │
│ 2 │ stderr │
│ 3 │ ─────────┼──→ file对象(读端) ──→ pipe_inode
│ 4 │ ─────────┼──→ file对象(写端) ──→ pipe_inode
└─────┴──────────┘ ↓
管道缓冲区pipe系统调用做了什么?
c
int pipe(int fd[2]);
// fd[0]: 读端文件描述符
// fd[1]: 写端文件描述符
// 内核操作:
// 1. 分配一个pipe_inode对象(管道缓冲区)
// 2. 创建两个file对象,一个用于读,一个用于写
// 3. 分配两个文件描述符,指向这两个file对象
// 4. 返回fd[0]和fd[1]2.4 站在内核角度理解管道本质
管道 = 特殊的文件
bash
普通文件 管道
┌─────────────┐ ┌─────────────┐
│ 磁盘上的数据 │ │ 内存中的数据 │
│ │ │ │
│ open()打开 │ │ pipe()创建 │
│ │ │ │
│ 有inode编号 │ │ 有pipe_inode│
│ │ │ │
│ 数据持久化 │ │ 数据临时 │
└─────────────┘ └─────────────┘关键理解:
看待管道,就如同看待文件一样!
c
// 操作文件
int fd = open("file.txt", O_RDONLY);
read(fd, buf, size);
close(fd);
// 操作管道
int pipefd[2];
pipe(pipefd);
read(pipefd[0], buf, size); // 完全一样的接口!
close(pipefd[0]);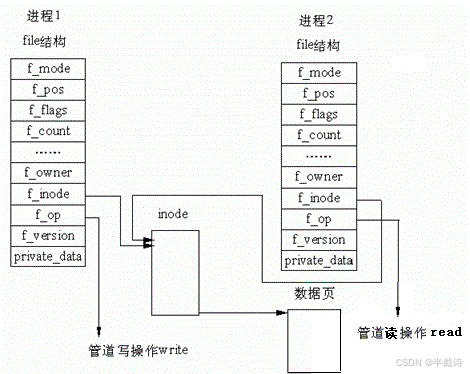
这就是Unix"一切皆文件"思想的体现!
三、匿名管道深度剖析
3.1 pipe系统调用
函数原型:
c
#include <unistd.h>
int pipe(int fd[2]);
// 参数:
// fd[2]: 输出参数,用于接收两个文件描述符
// fd[0] - 读端
// fd[1] - 写端
//
// 返回值:
// 成功: 0
// 失败: -1,并设置errno使用示例:
c
#include <stdio.h>
#include <unistd.h>
int main() {
int pipefd[2];
if (pipe(pipefd) == -1) {
perror("pipe");
return 1;
}
printf("读端fd: %d\n", pipefd[0]); // 通常是3
printf("写端fd: %d\n", pipefd[1]); // 通常是4
close(pipefd[0]);
close(pipefd[1]);
return 0;
}3.2 单进程使用管道
最简单的例子:从键盘读数据,写入管道,再从管道读出,写到屏幕
c
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#include <unistd.h>
int main(void) {
int fds[2];
char buf[100];
int len;
if (pipe(fds) == -1) {
perror("make pipe");
exit(1);
}
while (fgets(buf, 100, stdin)) {
len = strlen(buf);
// 写入管道
if (write(fds[1], buf, len) != len) {
perror("write to pipe");
break;
}
memset(buf, 0x00, sizeof(buf));
// 从管道读取
if ((len = read(fds[0], buf, 100)) == -1) {
perror("read from pipe");
break;
}
// 写到屏幕
if (write(1, buf, len) != len) {
perror("write to stdout");
break;
}
}
return 0;
}运行效果:
bash
gcc pipe_test.c -o pipe_test
./pipe_test
hello ← 输入
hello ← 输出(从管道读回)
world
world
^C流程分析:
bash
键盘 → stdin(fd=0) → fgets读取 → buf
↓
write(fds[1])
↓
管道缓冲区
↓
read(fds[0])
↓
write(fd=1)
↓
屏幕输出但这样用管道没什么意义,真正有用的是多进程使用管道。
3.3 用fork共享管道原理
关键问题:子进程如何访问父进程创建的管道?
答案:fork会复制文件描述符表!
fork前后的文件描述符:
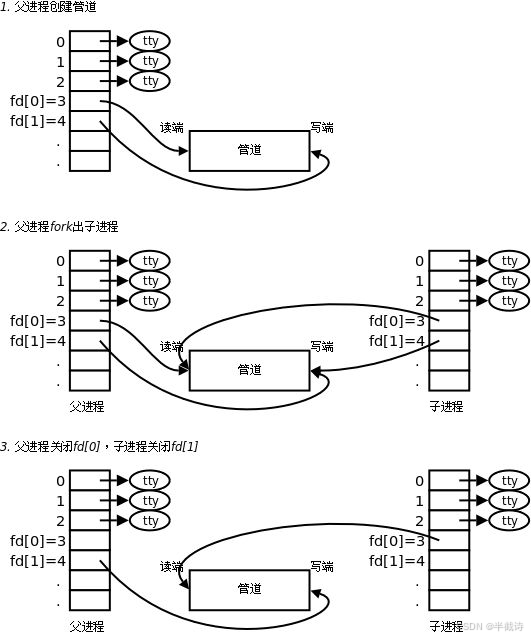
完整的通信流程:
bash
1. 父进程创建管道
pipe(fds); // fds[0]=读端, fds[1]=写端
2. fork创建子进程
pid = fork();
// 子进程复制了文件描述符表
3. 父进程关闭读端,只写
close(fds[0]);
write(fds[1], data, len);
4. 子进程关闭写端,只读
close(fds[1]);
read(fds[0], buf, len);
流程图:
父进程 子进程
│ │
├─ close(fds[0]) ├─ close(fds[1])
│ │
├─ write(fds[1]) ──→ 管道 ──→ ├─ read(fds[0])
│ │3.4 父子进程管道通信实战
完整代码:
c
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#include <unistd.h>
#include <sys/wait.h>
#define ERR_EXIT(m) \
do { \
perror(m); \
exit(EXIT_FAILURE); \
} while(0)
int main() {
int pipefd[2];
// 1. 创建管道
if (pipe(pipefd) == -1)
ERR_EXIT("pipe error");
// 2. 创建子进程
pid_t pid = fork();
if (pid == -1)
ERR_EXIT("fork error");
if (pid == 0) { // 子进程
close(pipefd[1]); // 关闭写端
char buf[128] = {0};
read(pipefd[0], buf, sizeof(buf));
printf("子进程收到: %s\n", buf);
close(pipefd[0]);
exit(EXIT_SUCCESS);
}
// 父进程
close(pipefd[0]); // 关闭读端
char *msg = "hello from parent";
write(pipefd[1], msg, strlen(msg));
close(pipefd[1]);
wait(NULL); // 等待子进程
return 0;
}运行结果:
bash
gcc parent_child_pipe.c -o test
./test
子进程收到: hello from parent为什么要关闭不用的端?
bash
原因1: 避免文件描述符泄漏
原因2: 让管道能正确检测到写端关闭
原因3: 节省系统资源
如果不关闭:
父进程: fds[0]和fds[1]都打开
子进程: fds[0]和fds[1]都打开
↓
管道的写端引用计数=2 (父和子各一个)
当父进程写完数据,子进程read会一直阻塞!
因为内核认为"还有写端存在,可能还会有数据"3.5 管道的读写规则
管道的读写行为比较复杂,需要分情况讨论。
3.5.1 读端的行为
情况1: 管道中有数据
c
read(pipefd[0], buf, size);
// 立即返回,返回值 = 实际读取的字节数情况2: 管道中无数据,但写端还存在
c
// 默认情况(阻塞模式):
read(pipefd[0], buf, size);
// 阻塞等待,直到有数据到来
// 非阻塞模式(O_NONBLOCK):
read(pipefd[0], buf, size);
// 立即返回-1, errno = EAGAIN情况3: 管道中无数据,且写端已关闭
c
read(pipefd[0], buf, size);
// 返回0 (表示EOF,文件结束)3.5.2 写端的行为
情况1: 管道未满
c
write(pipefd[1], data, size);
// 立即返回,返回值 = 实际写入的字节数情况2: 管道已满,但读端还存在
c
// 默认情况(阻塞模式):
write(pipefd[1], data, size);
// 阻塞等待,直到管道有空间
// 非阻塞模式(O_NONBLOCK):
write(pipefd[1], data, size);
// 立即返回-1, errno = EAGAIN情况3: 读端已关闭
c
write(pipefd[1], data, size);
// 产生SIGPIPE信号!
// 默认行为: 进程终止测试代码:写端写入,但读端已关闭
c
#include <stdio.h>
#include <unistd.h>
#include <signal.h>
void handler(int sig) {
printf("收到信号: %d (SIGPIPE)\n", sig);
}
int main() {
signal(SIGPIPE, handler); // 捕获SIGPIPE
int pipefd[2];
pipe(pipefd);
close(pipefd[0]); // 关闭读端
char *msg = "test";
int ret = write(pipefd[1], msg, 4);
if (ret == -1) {
perror("write");
}
printf("程序继续运行\n");
return 0;
}运行结果:
bash
./test
收到信号: 13 (SIGPIPE)
write: Broken pipe
程序继续运行3.6 管道的特点总结
1. 单向数据流(严格语义) vs 半双工(常见说法)
-
严格语义(内核/接口层) :
pipe()创建的单个匿名管道是单向字节流 ,数据永远从写端fd[1]流向读端fd[0],因此单个 pipe 本质是单工(simplex)。fd[0]只能read,fd[1]只能write;方向不是"可切换"的开关。- 关闭/保留不同端口只能改变"谁扮演写者/读者",并不会让同一条 pipe 发生真正的"反向传输"。
-
常见口径(教学/使用层) :- 很多资料把管道称为"半双工",通常是指父子双方都持有读端/写端句柄,可以在应用层通过约定"谁负责写、谁负责读"来组织通信。
- 但需要强调:单个 pipe 本身只有一个固定方向(fd1→fd0),无法在同一条 pipe 上实现"先父→子、再子→父"的反向传输。
- 如果需要真正的双向通信,应当使用两条管道 (p2c 与 c2p)或使用
socketpair()。
单向通信(单个 pipe):
cpp
进程A ──写(fd[1])──→ 管道 ──读(fd[0])──→ 进程B双向通信(推荐做法:两条 pipe 组成双向通道,全双工通信):
cpp
A ──pipe1──→ B
A ←─pipe2── B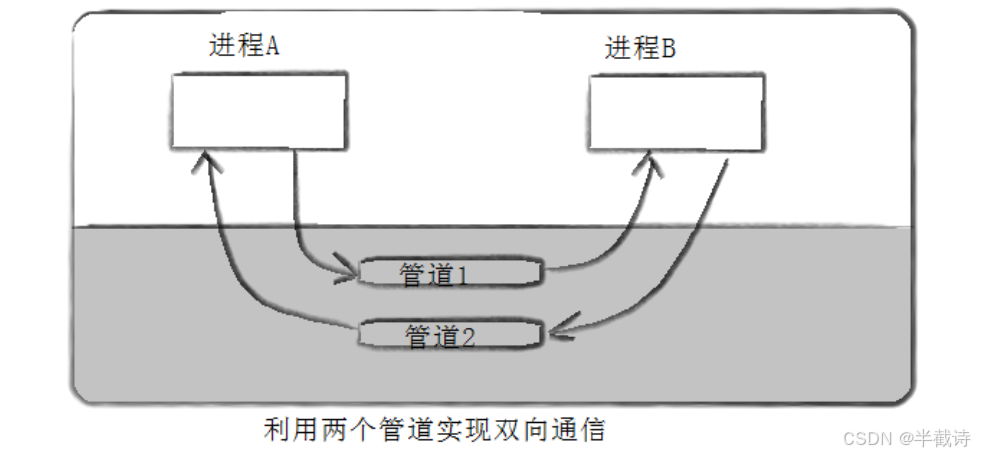
2. 匿名管道只能用于有亲缘关系的进程
匿名管道只能在父子进程、兄弟进程之间使用,因为需要通过fork继承文件描述符。
3. 管道提供流式服务
管道是面向字节流的
c
// 写入
write(pipefd[1], "hello", 5);
write(pipefd[1], "world", 5);
// 读取
read(pipefd[0], buf, 3); // 可能读到 "hel"
read(pipefd[0], buf, 7); // 可能读到 "loworld"
// 数据是字节流,没有边界!4. 管道的生命周期随进程
进程退出,管道自动释放,不需要手动删除。
5. 内核提供同步与互斥
多个进程同时写管道,内核保证数据不会混乱(有条件,见下节)。
四、管道的高级特性
4.1 PIPE_BUF与原子性
问题:
如果多个进程同时往管道写数据,会不会乱?
答案:看写入的数据量!
c
// PIPE_BUF 在 Linux 上通常是 4096 字节
// 情况1: 写入数据 <= PIPE_BUF
write(pipefd[1], data, 4096);
// 保证原子性! 要么全写入,要么全不写入
// 情况2: 写入数据 > PIPE_BUF
write(pipefd[1], data, 8192);
// 不保证原子性! 可能与其他进程的数据交织测试代码:
c
#include <stdio.h>
#include <unistd.h>
#include <string.h>
#include <sys/wait.h>
int main() {
int pipefd[2];
pipe(pipefd);
pid_t pid1 = fork();
if (pid1 == 0) {
close(pipefd[0]);
char data[5000]; // 大于PIPE_BUF
memset(data, 'A', sizeof(data));
write(pipefd[1], data, sizeof(data));
close(pipefd[1]);
return 0;
}
pid_t pid2 = fork();
if (pid2 == 0) {
close(pipefd[0]);
char data[5000]; // 大于PIPE_BUF
memset(data, 'B', sizeof(data));
write(pipefd[1], data, sizeof(data));
close(pipefd[1]);
return 0;
}
close(pipefd[1]);
char buf[10000];
read(pipefd[0], buf, sizeof(buf));
// 检查是否有AABB交织
printf("数据: %.*s...\n", 50, buf);
close(pipefd[0]);
wait(NULL);
wait(NULL);
return 0;
}可能看到AAABBBAAABBB这样的交织。
4.2 管道容量
查看管道容量:
c
#include <stdio.h>
#include <unistd.h>
#include <fcntl.h>
int main() {
int pipefd[2];
pipe(pipefd);
long size = fpathconf(pipefd[0], _PC_PIPE_BUF);
printf("PIPE_BUF: %ld\n", size);
// Linux特有,查看管道总容量
int capacity = fcntl(pipefd[1], F_GETPIPE_SZ);
printf("管道容量: %d 字节\n", capacity);
return 0;
}输出:
bash
PIPE_BUF: 4096
管道容量: 65536 字节4.3 验证管道的4种边界情况
我们写代码验证前面说的读写规则。
测试1: 写正常,读空
c
#include <stdio.h>
#include <unistd.h>
#include <sys/wait.h>
int main() {
int pipefd[2];
pipe(pipefd);
pid_t pid = fork();
if (pid == 0) {
close(pipefd[1]);
printf("子进程准备读取...(管道为空,会阻塞)\n");
char buf[10];
ssize_t n = read(pipefd[0], buf, sizeof(buf));
printf("子进程读到 %ld 字节: %s\n", n, buf);
close(pipefd[0]);
return 0;
}
close(pipefd[0]);
printf("父进程睡眠3秒...\n");
sleep(3);
printf("父进程开始写入\n");
write(pipefd[1], "hello", 5);
close(pipefd[1]);
wait(NULL);
return 0;
}运行效果:
bash
./test
子进程准备读取...(管道为空,会阻塞)
父进程睡眠3秒...
父进程开始写入
子进程读到 5 字节: hello测试2: 读正常,写满
c
#include <stdio.h>
#include <unistd.h>
#include <string.h>
#include <sys/wait.h>
int main() {
int pipefd[2];
pipe(pipefd);
pid_t pid = fork();
if (pid == 0) {
close(pipefd[0]);
char data[1024];
memset(data, 'A', sizeof(data));
int count = 0;
while (1) {
ssize_t n = write(pipefd[1], data, sizeof(data));
if (n > 0) {
count++;
printf("第%d次写入 %ld 字节\n", count, n);
} else {
break;
}
if (count >= 100) { // 写满管道
printf("管道已满,阻塞中...\n");
write(pipefd[1], "X", 1); // 这里会阻塞
break;
}
}
close(pipefd[1]);
return 0;
}
close(pipefd[1]);
printf("父进程睡眠5秒,让子进程写满管道\n");
sleep(5);
printf("父进程开始读取,释放空间\n");
char buf[1024];
read(pipefd[0], buf, sizeof(buf));
close(pipefd[0]);
wait(NULL);
return 0;
}测试3: 写关闭,读正常
c
#include <stdio.h>
#include <unistd.h>
#include <sys/wait.h>
int main() {
int pipefd[2];
pipe(pipefd);
pid_t pid = fork();
if (pid == 0) {
close(pipefd[0]);
write(pipefd[1], "data", 4);
close(pipefd[1]); // 关闭写端
return 0;
}
close(pipefd[1]);
sleep(1); // 等待子进程关闭写端
char buf[10];
ssize_t n = read(pipefd[0], buf, sizeof(buf));
printf("第一次读取: %ld 字节\n", n);
n = read(pipefd[0], buf, sizeof(buf));
printf("第二次读取: %ld 字节 (返回0表示EOF)\n", n);
close(pipefd[0]);
wait(NULL);
return 0;
}运行结果:
bash
./test
第一次读取: 4 字节
第二次读取: 0 字节 (返回0表示EOF)测试4: 读关闭,写正常(触发SIGPIPE)
c
#include <stdio.h>
#include <unistd.h>
#include <signal.h>
#include <sys/wait.h>
void sigpipe_handler(int sig) {
printf("捕获到SIGPIPE信号! 信号编号=%d\n", sig);
}
int main() {
signal(SIGPIPE, sigpipe_handler);
int pipefd[2];
pipe(pipefd);
pid_t pid = fork();
if (pid == 0) {
close(pipefd[1]);
close(pipefd[0]); // 子进程关闭读端
return 0;
}
close(pipefd[0]);
wait(NULL); // 等待子进程退出
printf("所有读端已关闭,尝试写入...\n");
ssize_t n = write(pipefd[1], "test", 4);
if (n == -1) {
perror("write");
}
close(pipefd[1]);
return 0;
}运行结果:
bash
./test
所有读端已关闭,尝试写入...
捕获到SIGPIPE信号! 信号编号=13
write: Broken pipe五、管道的应用场景
5.1 实现进程间的协作
场景:父进程读文件,子进程处理数据
c
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
#include <string.h>
#include <sys/wait.h>
int main() {
int pipefd[2];
pipe(pipefd);
pid_t pid = fork();
if (pid == 0) {
// 子进程:处理数据,读出管道数据
close(pipefd[1]);
char buf[256];
while (1) {
ssize_t n = read(pipefd[0], buf, sizeof(buf) - 1);
if (n <= 0) break;
buf[n] = '\0';
// 转大写
for (int i = 0; i < n; i++) {
if (buf[i] >= 'a' && buf[i] <= 'z') {
buf[i] = buf[i] - 'a' + 'A';
}
}
printf("处理后: %s", buf);
}
close(pipefd[0]);
return 0;
}
// 父进程:读文件,往管道里面写
close(pipefd[0]);
FILE *fp = fopen("input.txt", "r");
if (fp) {
char line[256];
while (fgets(line, sizeof(line), fp)) {
write(pipefd[1], line, strlen(line));
}
fclose(fp);
}
close(pipefd[1]);
wait(NULL);
return 0;
}5.2 实现简单的shell管道
原理:ls | wc -l
c
#include <stdio.h>
#include <unistd.h>
#include <sys/wait.h>
int main() {
int pipefd[2];
pipe(pipefd);
pid_t pid1 = fork();
if (pid1 == 0) {
// 第一个命令: ls
close(pipefd[0]);
dup2(pipefd[1], 1); // 标准输出重定向到管道
close(pipefd[1]);
execlp("ls", "ls", NULL);
perror("execlp");
return 1;
}
pid_t pid2 = fork();
if (pid2 == 0) {
// 第二个命令: wc -l
close(pipefd[1]);
dup2(pipefd[0], 0); // 标准输入重定向到管道
close(pipefd[0]);
execlp("wc", "wc", "-l", NULL);
perror("execlp");
return 1;
}
close(pipefd[0]);
close(pipefd[1]);
waitpid(pid1, NULL, 0);
waitpid(pid2, NULL, 0);
return 0;
}相当于执行了 ls | wc -l
六、总结
本篇我们深入学习了进程间通信的基础------管道机制。
核心知识点:
-
进程间通信的必要性
- 独立地址空间导致进程隔离
- 数据传输、资源共享、事件通知、进程控制四大目的
-
管道的本质
- 内核维护的缓冲区(默认64KB)
- 通过文件描述符访问
- 体现"一切皆文件"思想
-
匿名管道的使用
- pipe创建管道,返回读写两个fd
- fork后子进程继承文件描述符
- 必须关闭不用的端
-
管道的读写规则
- 读空阻塞,写满阻塞
- 写端关闭,read返回0
- 读端关闭,write触发SIGPIPE
-
管道的特点
- 单个 pipe 单向(严格:单工);常见说法称"半双工"指轮流双向对话(角色交换)
- 匿名管道只能用于亲缘进程
- 提供流式服务
- 生命周期随进程
-
管道的限制
- 单向通信
- 容量有限(65536字节)
- 只能用于本地进程
完整的管道通信流程图:
bash
父进程 子进程
│ │
├─ pipe(fds) │
├─ fork() ─────────────────→ │ (继承fds)
│ │
├─ close(fds[0]) ├─ close(fds[1])
│ │
├─ write(fds[1], data, len) │
│ │ │
│ └─→ 管道缓冲区 ─→ │
│ │
│ ├─ read(fds[0], buf, len)
│ │
├─ close(fds[1]) ├─ read返回0 (EOF)
│ │
├─ wait(NULL) ├─ exit(0)
│ │💡 思考题
- 为什么很多资料说管道"半双工",但严格语义又常说"单工"?两种说法分别站在什么层面?
- 如果不关闭不用的管道端,会有什么后果?
- 如何让不相关的进程也能通过管道通信?(提示:下一篇的命名管道)
下一篇,我们将学习命名管道和进程池的完整实现!