音频降噪 ------ SNR/ASNR/STOI
一:SNR相关
1.SNR的定义
SNR(Signal-to-Noise Ratio)衡量有用信号与背景噪声之间关系的重要指标(有用信号功率与噪声功率之比),顾名思义,就是信号和噪声的比值,实际应用时比值结果常转到dB域中
信噪比(SNR),即放大器的输出信号的功率,与同时输出的噪声功率的比值,常常用分贝数表示。设备的信噪比越高表明它产生的杂音越少。一般来说,信噪比越大,说明混在信号里的噪声越小,声音回放的音质量越高
2.计算公式
2.1 SNR比值计算:P signal/P noise
S N R = P s i g n a l P n o i s e SNR=\cfrac{P_{signal}}{P_{noise}} SNR=PnoisePsignal
2.2 SNR(dB)分贝值计算:SNR(dB) = 10 × log₁₀(P signal/P noise)
S N R ( d B ) = 10 ⋅ log 10 ( P s i g n a l P n o i s e ) SNR(dB)=10⋅\log_{10}\begin{pmatrix}\cfrac{P_{signal}}{P_{noise}}\end{pmatrix} SNR(dB)=10⋅log10(PnoisePsignal)
2.3 SNR(dB)采用电压值计算:SNR(dB) = 20 × log₁₀(V signal/V noise)
S N R ( d B ) = 20 ⋅ log 10 ( ( V s i g n a l V n o i s e ) SNR(dB)=20⋅\log_{10}(\begin{pmatrix}\cfrac{V_{signal}}{V_{noise}}\end{pmatrix} SNR(dB)=20⋅log10((VnoiseVsignal)
2.4 STOI计算
S T O I = s t o i ( s , z ) STOI=stoi(s,z) STOI=stoi(s,z)
1 ⩾ S T O I ⩾ 0 1\geqslant STOI \geqslant 0 1⩾STOI⩾0
STOI 衡量的不是声音干不干净,而是一个人听这段语音,能不能把话听清楚、听懂
- 当噪音能量大于人声能量时(SNR < 0 dB):
STOI 通常会明显下降,但并不会像 SNR 一样必然为负或直接失效
STOI 关心的是:在人声被噪声淹没的情况下,还能不能抓住语音信息 - SNR 是能量比(物理量)
噪声能量一旦超过人声
SNR(dB) 立刻变负,这是数学上的必然 - STOI 是"可懂度预测"(感知量)
不直接看"能量谁大谁小"
而是看语音的信息结构是否还能被辨认
暂时无法在飞书文档外展示此内容 - P signal:信号功率
- P noise:噪声功率/能量值,能量单位
- V signal:信号电压
- V noise:噪声电压
数值含义:
- 高 SNR (正值): 信号强于噪声,清晰可辨
- 低 SNR (负值): 噪声淹没信号,质量差
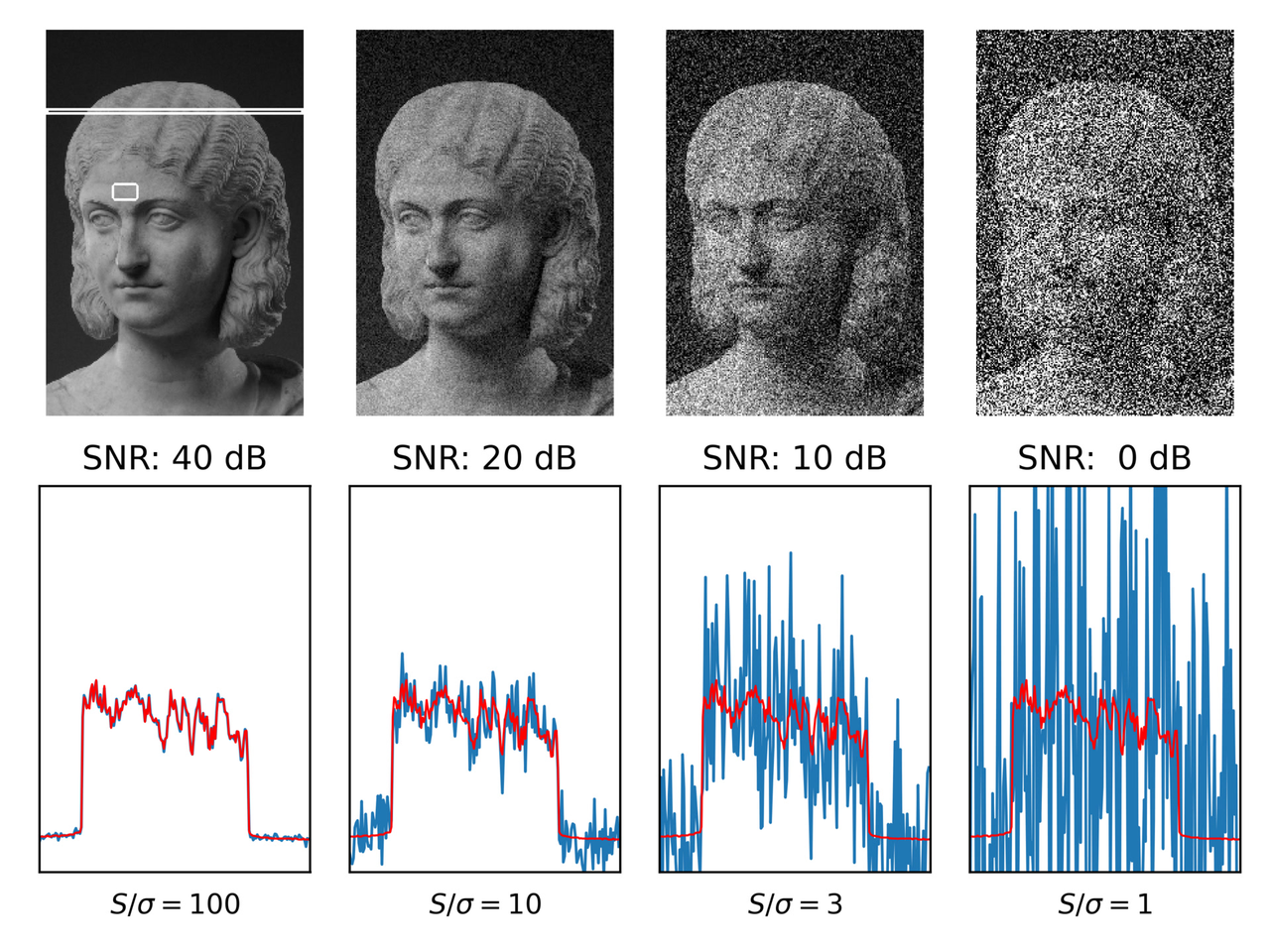
典型信噪比与图像质量的关系,来源:维基百科
二:模拟数据集实验
1.实验工具
- 数据集/混音来源:https://github.com/microsoft/MS-SNSD
2.音频标准
- 16 kHz
- Mono
- 16-bit PCM WAV
3.目录结构
AudioSNREvalNewtest/
├── clean/
│ └── clnsp9.wav
├── noise/
│ └── noisy9_SNRdb_0.0.wav
├── noisy/
│ └── noisy9_SNRdb_0.0_clnsp9.wav
├── enh_file/
│ ├── noisy9_SNRdb_0.0_clnsp9/
│ └── xxx.wav
├── eval_snr_asnr_stoi.py
├── run_all.bat
4.开始实验
4.1 实验过程
Step1:克隆 MS-SNSD
Step2:配置 MS-SNSD
python
# Configuration for generating Noisy Speech Dataset
# - sampling_rate: Specify the sampling rate. Default is 16 kHz
# - audioformat: default is .wav
# - audio_length: Minimum Length of each audio clip (noisy and clean speech) in seconds that will be generated by augmenting utterances.
# - silence_length: Duration of silence introduced between clean speech utterances.
# - total_hours: Total number of hours of data required. Units are in hours.
# - snr_lower: Lower bound for SNR required (default: 0 dB)
# - snr_upper: Upper bound for SNR required (default: 40 dB)
# - total_snrlevels: Number of SNR levels required (default: 5, which means there are 5 levels between snr_lower and snr_upper)
# - noise_dir: Default is None. But specify the noise directory path if noise files are not in the source directory
# - Speech_dir: Default is None. But specify the speech directory path if speech files are not in the source directory
# - noise_types_excluded: Noise files starting with the following tags to be excluded in the noise list. Example: noise_types_excluded: Babble, AirConditioner
# Specify 'None' if no noise files to be excluded.
[noisy_speech]
sampling_rate: 16000
audioformat: *.wav
audio_length: 60
silence_length: 0.2
total_hours: 1
snr_lower: 0
snr_upper: 40
total_snrlevels: 1
noise_dir: None
speech_dir: None
noise_types_excluded: NoneStep3:换算公式
1. SNR比值
P s i g n a l = 1 N ∑ s n 2 P_{signal}=\cfrac{1}{N}\sum sn^2 Psignal=N1∑sn2
P n o i s e = 1 N ∑ ( z n − s n ) 2 P_{noise}=\cfrac{1}{N}\sum (zn-sn)^2 Pnoise=N1∑(zn−sn)2
2. SNR(dB)
S N R ( d B ) = 10 ⋅ log 10 ( ∑ s n 2 ∑ ( z n − s n ) 2 + ∈ ) SNR(dB)=10⋅\log_{10}\begin{pmatrix}\cfrac{{\sum sn^2}}{{\sum (zn-sn)^2} + \in}\end{pmatrix} SNR(dB)=10⋅log10(∑(zn−sn)2+∈∑sn2)
3. ASNR
A S N R = S N R o u t − S N R i n ASNR=SNR_{out} - SNR_{in} ASNR=SNRout−SNRin
4. STOI
S T O I = s t o i ( s , z ) STOI=stoi(s,z) STOI=stoi(s,z)
Step4:运行 MS-SNSD python 脚本
- 输入:clean + noise(共模拟5种不同环境噪音混合干净人声)
- 输出:noisy(0 dB)(5种不同环境下的合成噪音)
Step5:降噪处理
为了能够处理各种复杂环境下的降噪和效果对比,随机模拟了以下5种噪音环境
1.模拟环境:电钻 + 干净人声
- 运行 MS-SNSD python 脚本,将 clnsp9.wav 和 noisy9_SNRdb_0.0.wav 混成 noisy9_SNRdb_0.0_clnsp9.wav
2.模拟环境:室内嘈杂(展会/商场/咖啡厅/公共场合如车站、机场、地铁站等)
- 运行 MS-SNSD python 脚本,将 clnsp11.wav 和 noisy11_SNRdb_0.0.wav 混成 noisy11_SNRdb_0.0_clnsp11.wav
3.模拟环境:键盘 + 干净人声
- 运行 MS-SNSD python 脚本,将 clnsp14.wav 和 noisy14_SNRdb_0.0.wav 混成 noisy14_SNRdb_0.0_clnsp14.wav
4.模拟环境:风噪/机房/车床/加工厂等场地
- 运行 MS-SNSD python 脚本,将 clnsp22.wav 和 noisy22_SNRdb_0.0.wav 混成 noisy22_SNRdb_0.0_clnsp22.wav
5.模拟环境:室内嘈杂人声(开会/聚会等场景)
- 运行 MS-SNSD python 脚本,将 clnsp23.wav 和 noisy23_SNRdb_0.0.wav 混成 noisy23_SNRdb_0.0_clnsp23.wav
最后分别采用声加算法和内部二开算法进行降噪处理
4.2 实验结果(5个模拟环境随机抽1进行介绍,有兴趣的可以找我要全部素材)
随机模拟环境介绍:电钻 + 干净人声
处理速度:文件时长 1:03 ,处理时间 1032 ms
降噪效果:
链接: https://pan.baidu.com/s/1LXAvfikflgis2WS_ipWqCA?pwd=8888 提取码: 8888
!在这里插入图片描述(https://i-blog.csdnimg.cn/direct/12653392e682424a8886432649ec5b91.png
一共6个文件,下面是文件说明:
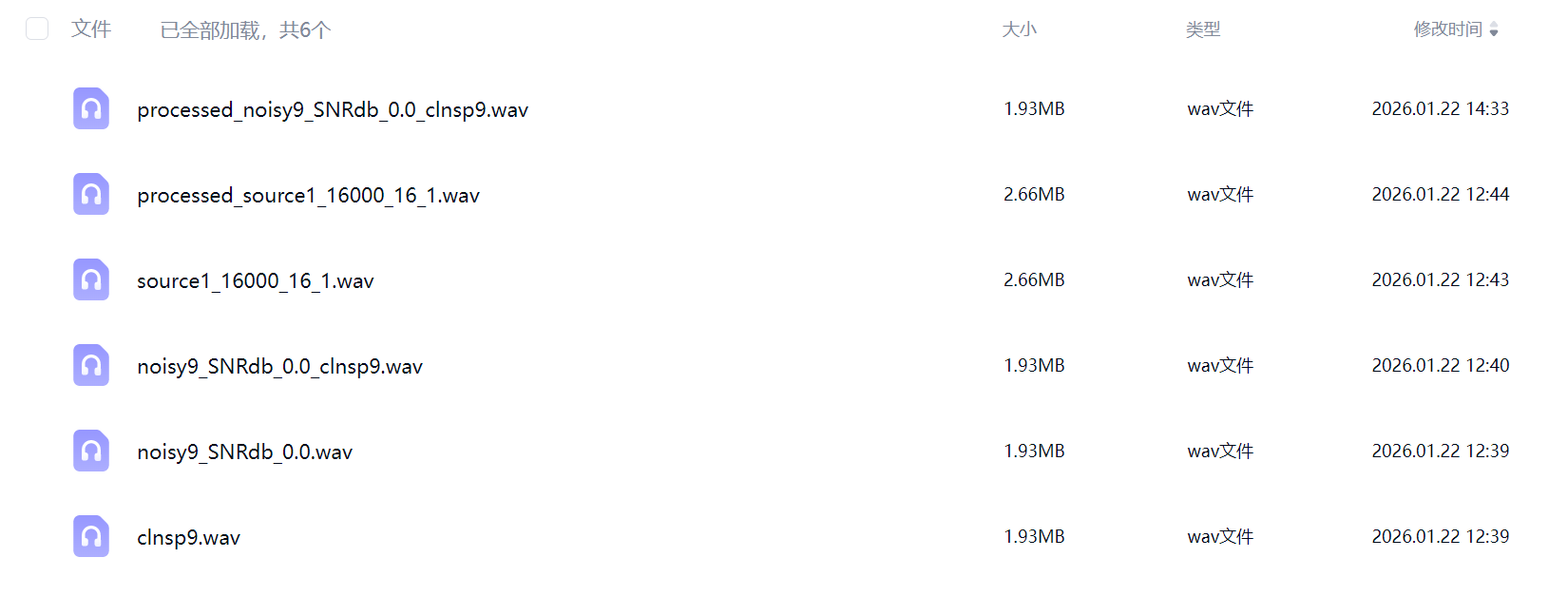
工程实验文件(4个文件):
clnsp9.wav ===>>> 干净的人声
noisy9_SNRdb_0.0.wav ===>>> 电钻噪声
noisy9_SNRdb_0.0_clnsp9.wav ===>>> 电钻噪声 + 干净人声 (混音,降噪前)
processed_noisy9_SNRdb_0.0_clnsp9.wav ===>>> 电钻噪声 + 干净人声 (混音,降噪后)
实际使用场景(2个文件):
source1_16000_16_1.wav ===>>> 降噪前
processed_source1_16000_16_1.wav ===>>> 降噪后
算法是我自己基于 WebRTC 开源二次开发的一个算法库,目前没有开源的打算,因为RNNoise需要 48KHz 数据,我目前的项目是16KHz 所以没有直接采用RNNoise,但官方推荐的做法是先将 16KHz resample to 48KHz 再经过算法降噪得到 48KHz 的信噪比(SNR)信号优化之后的数据,最后再将 48KHz resample to 16KHz 即可,可以使用官方的开源库 SpeexDSP 进行 resample
5.实验工程数据来源/参考
- 工程实验中所有用到的公式计算均来源:Google Gemini
- 典型信噪比与图像质量的关系来源:维基百科
- 混音工具数据集生成来源:https://github.com/microsoft/MS-SNSD