Agent 系统发展得这么快那么检索模型还重要吗?RAG 本身都已经衍生出 Agentic RAG和 Self-RAG(这些更复杂的变体了。
答案是肯定的,无论 Agent 方法在效率和推理上做了多少改进,底层还是离不开检索。检索模型越准,需要的迭代调用就越少,时间和成本都能省下来,所以训练好的检索模型依然关键。讨论 RAG 怎么用的文章铺天盖地,但真正比较检索模型学习方式的内容却不多见。
检索系统包含多个组件:检索嵌入模型、索引算法(HNSW 之类)、向量搜索机制(余弦相似度等)以及重排序模型。这篇文章只聚焦检索嵌入模型的学习方式。
本文将介绍我实验过的三种方法:Pairwise cosine embedding loss(成对余弦嵌入损失)、Triplet margin loss(三元组边距损失)、InfoNCE loss。
成对余弦嵌入损失
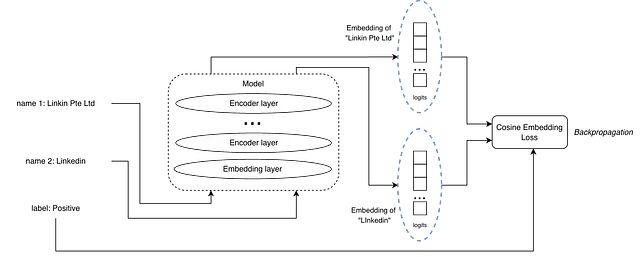
正样本对示例
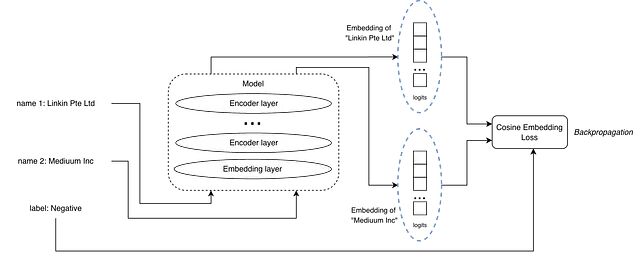
负样本对示例
输入是一对文本加一个标签,标签标明这对文本是正匹配还是负匹配。和 MNLI 数据集里的蕴含、矛盾关系类似。
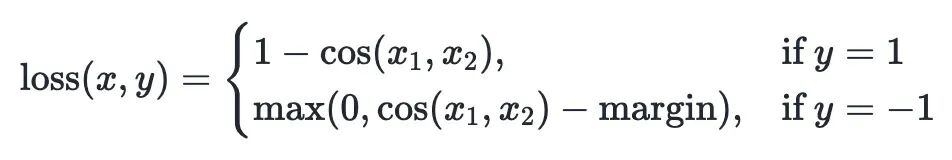
损失函数用的是余弦嵌入损失,x 和 y 分别是文本对的嵌入向量。
三元组边距损失
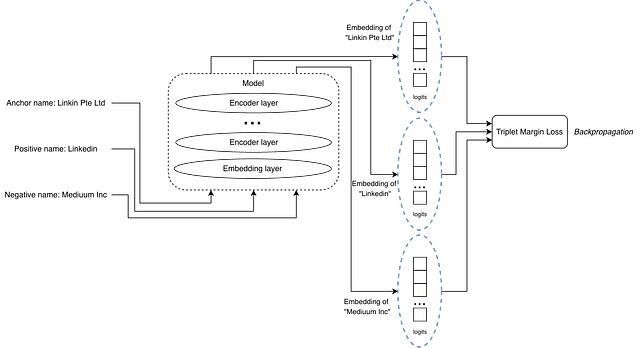
输入变成三个文本:一个锚文本、一个正匹配、一个负匹配。
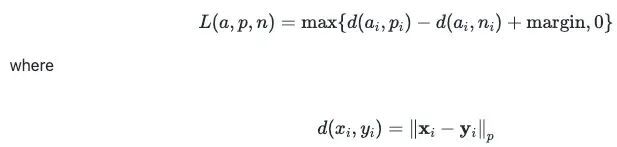
损失函数是 Triplet Margin Loss。公式里 a 代表锚文本嵌入,p 代表正样本嵌入,n 代表负样本嵌入。
InfoNCE 损失
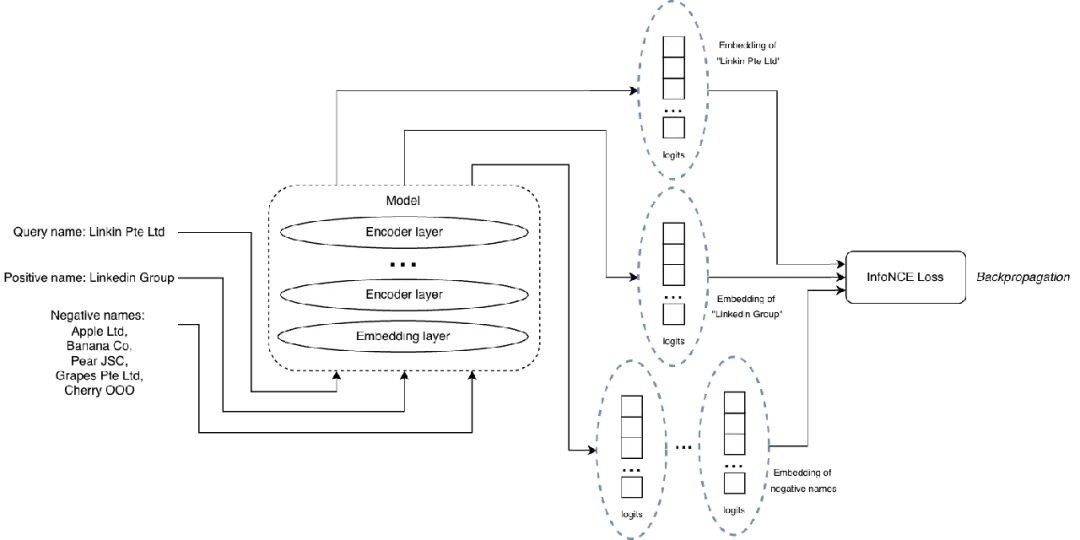
输入包括一个查询、一个正匹配、一组负样本列表。

损失函数采用 InfoNCE,灵感来自 M3-Embedding 论文(arxiv:2402.03216)。公式中 p* 是正样本嵌入,P' 是负样本嵌入列表,q 是查询嵌入,s(.) 表示相似度函数,比如余弦相似度。
比较
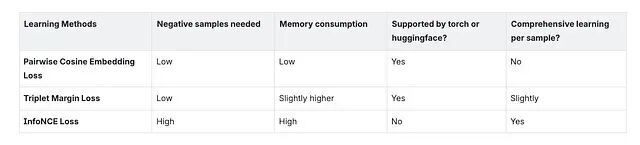
哪种方法最好?要看具体场景、数据量和算力。从我的实验来看,InfoNCE 覆盖面最广。但只要实验做得够充分、训练数据比例调得够细,余弦嵌入损失也能达到差不多的效果。三元组边距损失我没有深入探索,不过它可能是介于另外两者之间的一个折中选项。
https://avoid.overfit.cn/post/7958652dd31e4cf5ace899b97e0eac27
作者:Jerald Teo