一、监督学习 半监督学习
1、监督学习
监督学习:数据样本 xxx 都有对应的一个已知的输出标签yyy
使用监督学习训练一个模型,测试数据能使用该模型预测出准确的标签
监督学习的常见任务包括分类(预测离散标签)和回归(预测连续值)。
2、半监督学习
半监督学习:数据样本xxx没有对应的输出标签yyy
主要结合了监督学习和无监督学习的元素,利用少量带标签数据和大量无标签的数据进行预训练,当监督学习模型稳定、置信度一致时,可以将该模型用于半监督学习
在半监督学习中,损失函数通常包含两部分:监督损失(基于带标签数据)和无监督损失(基于无标签数据)。
二、无监督学习
无监督学习:只有数据样本xxx
无监督的方法:
1、机器学习:聚类 :将数据集的样本划分成若干个分组,使得每一个分组内的样本彼此相似、而不同的样本彼此不同,如K-means; 降维 :减少数据的特征维度,同时尽可能保留重要信息,如:主成分分析
2、深度学习:生成对抗式网络、自监督学习
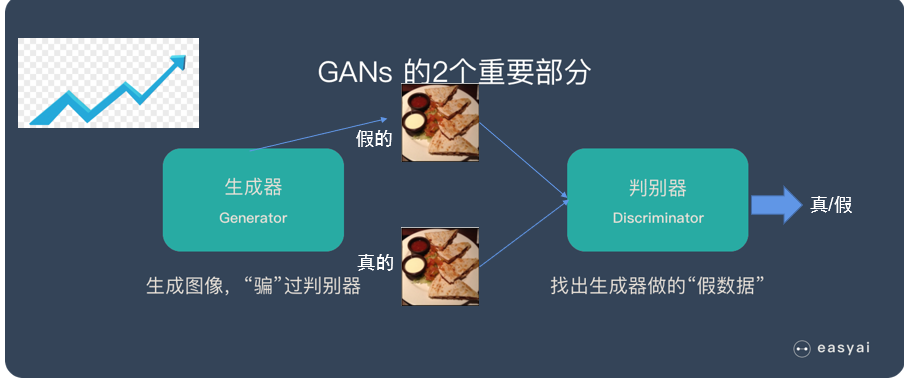
1、生成对抗网络 GAN
GAN:generative adversarial Network
主要有两种部分组成:生成器(类似假钞机)generator; 判别器(类似验钞器)discriminator
一个小故事:
刚开始造假钱的工厂技术很差,造出来的假币一眼就能识别,也就辨别器很容易就能辨别)但随着训练的进行,造假者不断改进技术,判别器技术也变得越来越好,双方技术你追我赶技术都在提高,最终造假者能造出连最先进的判别器都分不清真假的假币
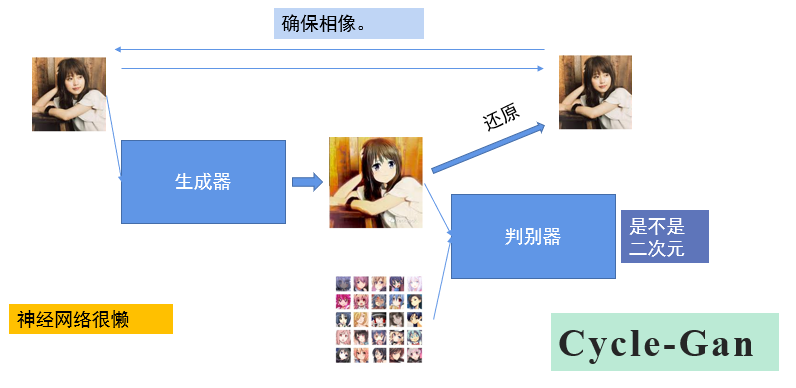
2、CycleGAN
输入一张真实的图像(比如抖音上一个很火的变二次元的特效就是这个),真人照片与训练图库进行对比,提取特征,最终输出一张二次元照片,还能够通过反向生成器近似还原真人
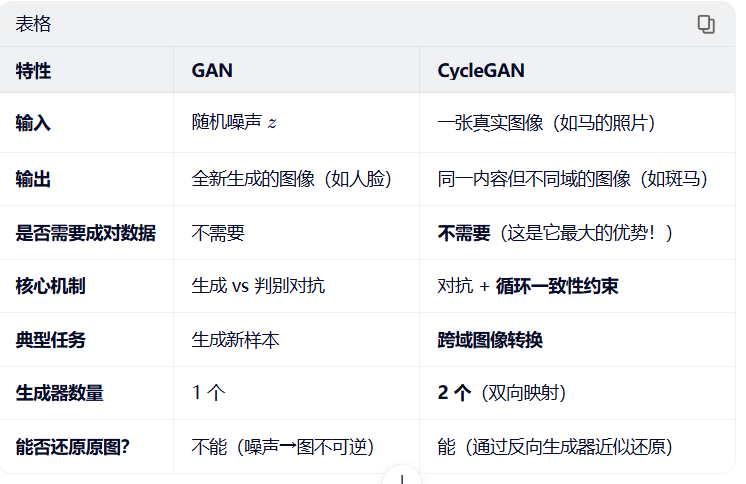
cycleGan 与Gan 的区别
Gan:很老旧:生成器只有一个,不能还原原图,输入数据是一个随机的噪声。
CycleGan:可以还原原图
3、自监督学习
没有标注标签,自己作为自己监督的信号也就是自己给自己出题,自己给自己打分。
主要是学习到一个强大的特征编码器,用于下游任务
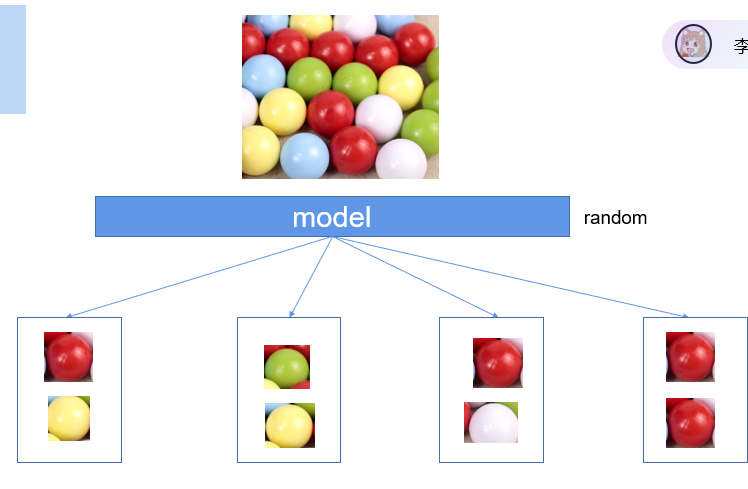
(1)对比学习
对比学习:学会辨认同一类事物;相同特诊样本靠近,不同样本远离
很像消消乐
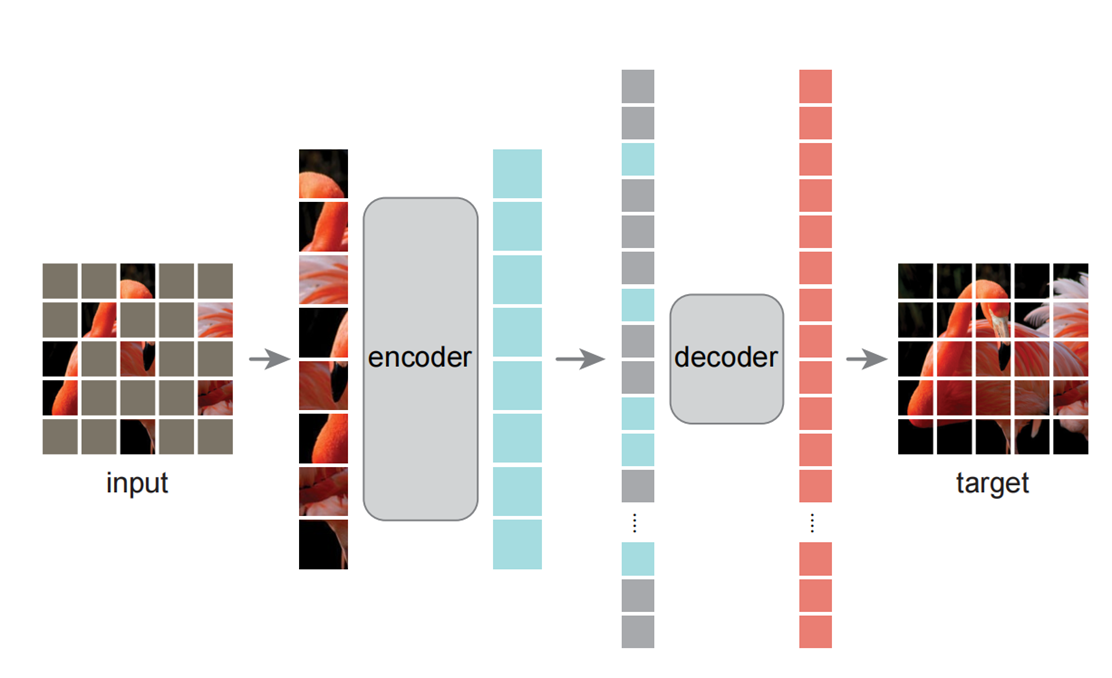
(2)生成式自监督
学习并重构原始输入;
encoder:编码器;
decoder:解码器
比如压缩文件也是有压缩工具和解压缩工具

比如使用马赛克遮住某些图片内容,模型能够根据剩余信息还原整个图
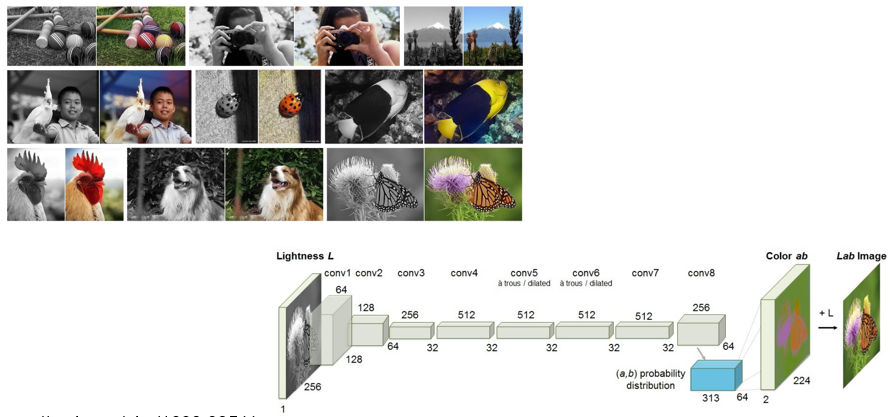
比如:黑白照片经过模型后变成有颜色的照片
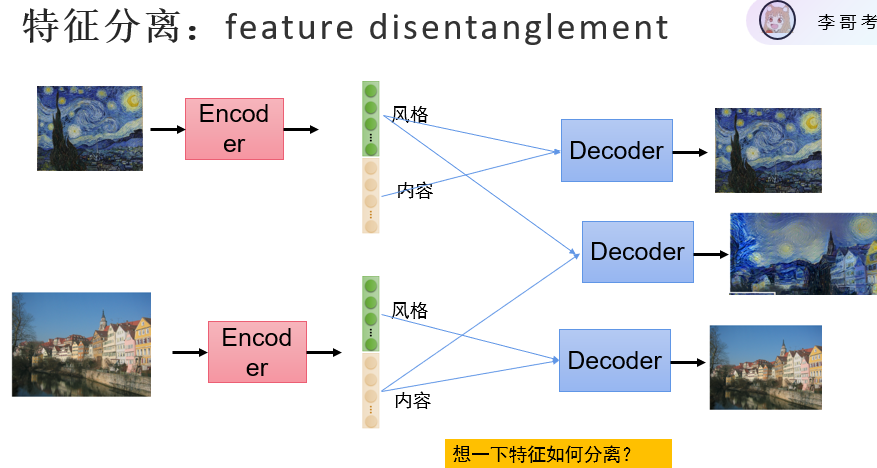
特征分离
将图片的特征进行分割提取:风格和内容,随后可以将特征进行融合组建