随着人工智能技术的快速发展,智能语音识别已经广泛应用于各个领域,尤其是在移动端和边缘设备上的实时语音识别。为了满足这些设备在计算能力和资源上的限制,优化和轻量化模型成为了实现高效语音识别的关键。以下是熙瑾会悟基于模型优化与部署技术的轻量化实现方案,旨在适配不同场景的实时需求。
- 模型压缩:减小模型大小以适应移动端和边缘端
模型压缩技术其核心目标是在尽可能保留模型原有识别精度的前提下,通过精简模型参数、优化模型结构,降低模型的存储需求与运算复杂度,使其适配资源受限设备。目前,在语音识别模型压缩领域,量化与剪枝是应用最为广泛且效果显著的两种核心方法,二者协同配合可实现"精度损失可控、体积大幅缩减、效率显著提升"的优化目标。
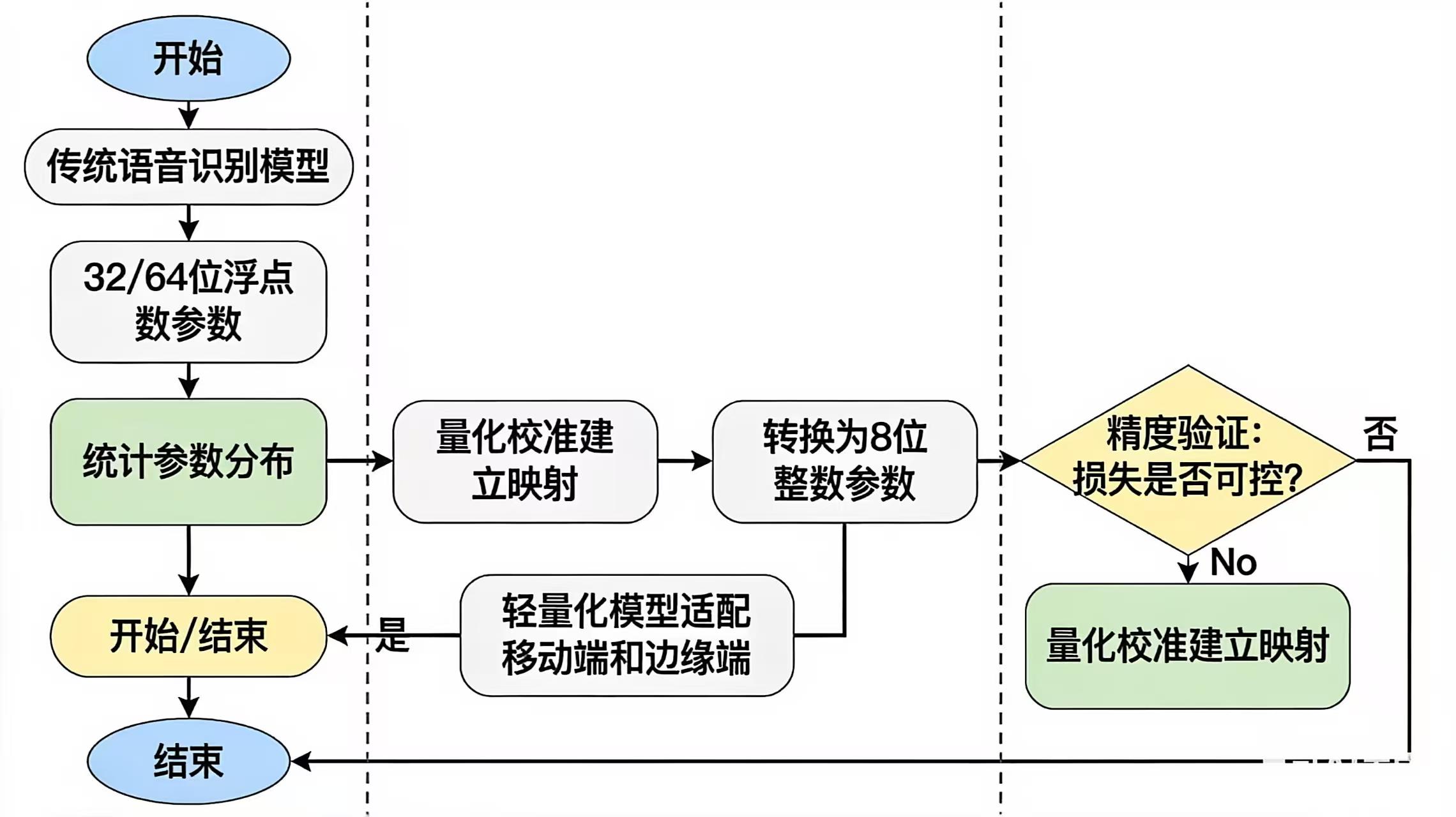
量化技术的核心思路是通过降低模型参数的数据精度,实现存储体积与运算效率的双重优化。传统语音识别模型的参数多采用32位或64位浮点数存储,这类高精度数据虽能保障计算精度,但占用存储空间较大,且在设备运算时需要消耗更多资源。量化技术通过特定算法将这些高精度浮点数权重转换为低精度的整数(最常用的是8位整数),在这一过程中,技术人员会通过精准的量化校准的方法,最大限度降低精度损失。例如,通过统计模型参数的分布范围,建立浮点数与整数之间的映射关系,确保关键特征信息不被丢失。量化后的模型优势十分显著:一方面,存储体积可实现4倍甚至更高比例的缩减,原本数百兆的模型可压缩至几十兆,完全适配移动端和边缘端的有限存储资源;另一方面,低精度整数运算的效率远高于浮点数运算,能大幅提升模型的推理速度,使语音识别响应时间缩短至用户可感知的流畅范围,同时还能有效降低设备运算功耗,延长移动设备续航时间,减少边缘设备的能源消耗。在智能手表的语音拨号、手机离线语音输入等场景中,量化后的语音识别模型可实现"本地快速响应、无需依赖云端"的效果,既提升了体验,又保障了数据隐私安全。
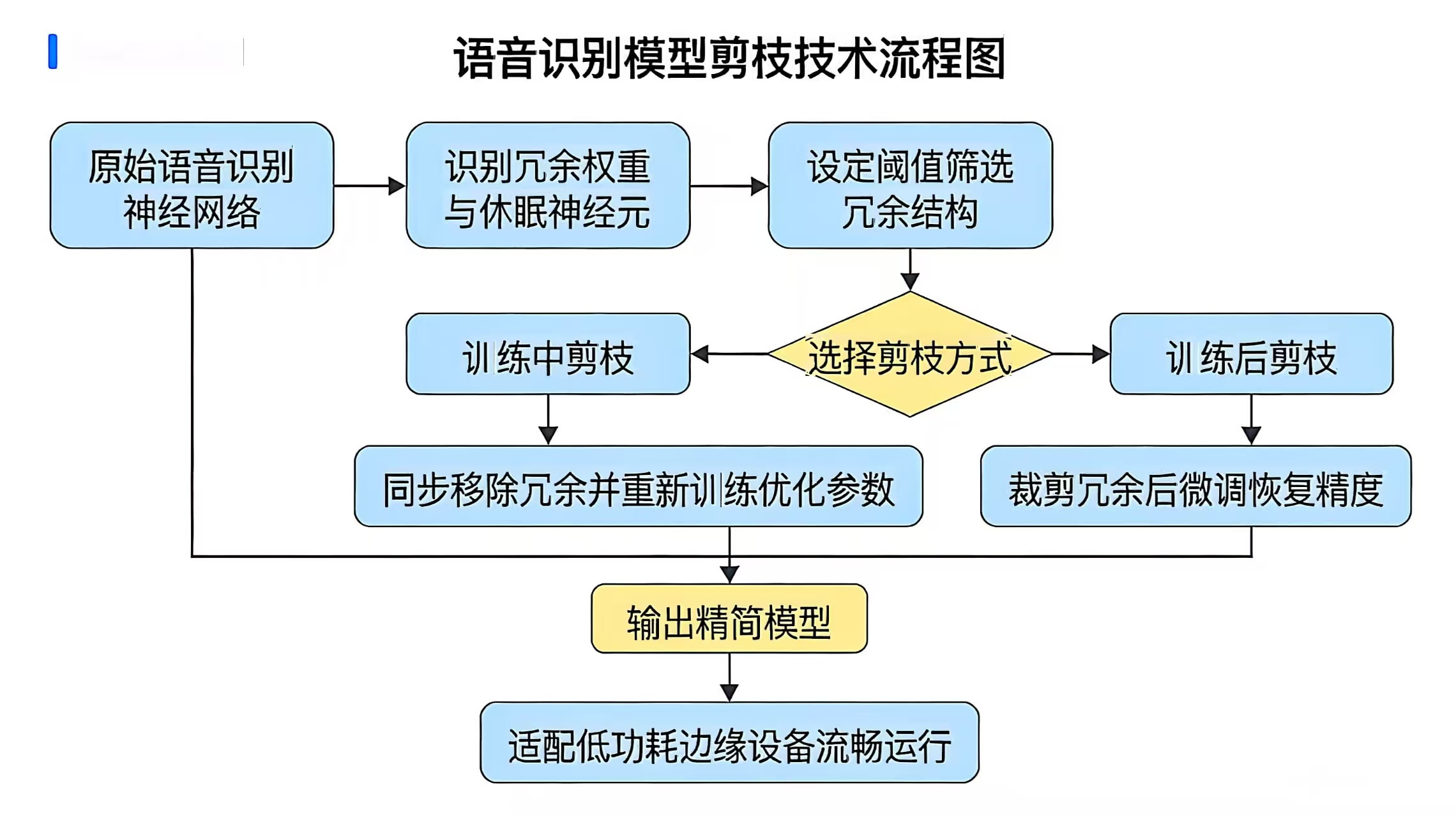
剪枝技术则聚焦于精简模型的结构冗余,通过移除神经网络中"不重要"的权重或神经元,降低模型的复杂度。语音识别模型的神经网络中,部分权重参数数值极小,对模型的识别结果影响微乎其微,甚至部分神经元在多数输入样本的计算过程中均处于"休眠"状态,属于冗余结构。剪枝技术通过设定合理的阈值,筛选出这些冗余的权重和神经元并予以"剪掉",使模型结构更加精简高效。剪枝过程通常分为训练中剪枝与训练后剪枝两种方式:训练中剪枝会在模型训练过程中同步识别并移除冗余部分,同时通过重新训练优化剩余参数,保障模型精度;训练后剪枝则是在模型训练完成后,对冗余结构进行裁剪,再通过微调进一步恢复精度。剪枝后的语音识别模型,不仅存储体积进一步缩减,更重要的是运算量大幅降低,能够在低功耗、低运算能力的边缘设备(如工业现场的语音控制传感器)上流畅运行。例如,在智能家居的灯光语音控制模块中,剪枝后的模型可直接部署在小型控制器上,实现毫秒级的语音指令响应,且设备功耗极低,可通过电池长期供电。
2. 增量学习:应对新型语音的挑战
随着AI克隆技术的迭代和不断进步,语音的识别变得越来越困难。因此,为了应对这种挑战,我们引入了增量学习技术。增量学习允许模型在不重新训练的情况下,通过不断地获取新样本来更新模型参数,从而快速适应新型的语音。
这种方法的核心在于通过一个较小的"增量"更新模型,而不是每次都从零开始重新训练。这大大降低了计算和时间成本,保证了模型的实时性和准确性。例如,当检测到一个新的语音样本时,系统可以通过增量学习机制及时更新已有的模型,以保持对新型语音的高效识别。
3. 模型部署:确保高效部署和实时识别
在完成模型的优化和轻量化后,接下来的挑战是如何将这些优化后的模型高效地部署到各种设备上。通常,部署到移动端或边缘端设备时,我们可以使用以下技术:
TensorFlow Lite 和 ONNX Runtime:这些工具提供了专门针对移动端和嵌入式设备优化的模型部署方案,支持将训练好的模型转换为轻量级格式,能够在低计算能力的设备上进行快速推理。
边缘计算平台:将智能语音模型部署到边缘计算设备上,可以减少对云端计算资源的依赖,提高响应速度。例如,在实时语音识别中,通过边缘设备处理语音数据,能够显著降低延迟并减轻网络压力。
通过上述的模型压缩(量化、剪枝)、增量学习和高效部署策略,我们能够为移动端和边缘设备提供高效、实时的语音识别能力。随着技术的不断进步,这些优化方案将会在实际应用中发挥越来越重要的作用,推动智能语音识别技术的普及与发展。