redis是内存数据库,所有的操作都是基于内存的,所以它执行起来非常快。我们可以通过配置maxmemory参数来设置redis能够使用的内存大小。在64位操作系统下默认的最大值是机器的最大内存,在32位的操作系统下,默认最大值是3gb,可以根据情况合理调整。
redis本身对内存也设计了一套管理策略,主要表现在过期策略和淘汰策略
1、过期策略
redis的过期策略是指为了保证内存的利用率,对设置了过期时间的key中已经过期的key的回收策略,类似与垃圾回收释放空间再利用
1.1、惰性过期
redis在我们每次使用某个key的时候,都会去判断一下这个key有没有过期。也就是调用下面这个expireIfNeeded方法:
c
int expireIfNeeded(redisDb *db, robj *key) {
if (!keyIsExpired(db,key)) return 0;
/* If we are running in the context of a slave, instead of
* evicting the expired key from the database, we return ASAP:
* the slave key expiration is controlled by the master that will
* send us synthesized DEL operations for expired keys.
*
* Still we try to return the right information to the caller,
* that is, 0 if we think the key should be still valid, 1 if
* we think the key is expired at this time.
*/
//如果配置有masterhost,说明是从节点,那么不操作删除
if (server.masterhost != NULL) return 1;
/* Delete the key */
server.stat_expiredkeys++;
propagateExpire(db,key,server.lazyfree_lazy_expire);
notifyKeyspaceEvent(NOTIFY_EXPIRED, "expired",key,db->id);
//是否是异步删除,防止单个Key的数据量很大阻塞主线程,是4.0之后添加的新功能,默认关闭lazyfree-lazy-expire
int retval = server.lazyfree_lazy_expire ?dbAsyncDelete(db,key) : dbSyncDelete(db,key);
if (retval) signalModifiedKey(NULL,db,key);
return retval;
}因为这种方式是被动的,只有在对对应的key进行操作的时候才会去判断,所以叫"惰性过期"。因为不用一直盯着处理这些过期的key,虽然该策略最大化地节省了cpu的资源,但很明显惰性过期是有一定的问题的,比如空间释放不及时,如果这些key长时间没有使用,那它们很可能就会成为"僵尸"不会被清除,长时间占用内存空间
所以这就需要另外一个策略:定期主动过期
1.2、定期过期
定期过期策略是为了弥补惰性过期策略的不足。我们在之前分析redis的数据结构中提到过redis的rehash过程,当时有一个方法serverCron,其实从名字看就是一个定时任务,具体执行频率可以在redis.conf中通过设置server.hz来配置。此外,serverCron除了做rehash之外,还做了其它事情,比如:
- 清理数据库中过期的键值对
- 更细那数据库的各类统计信息,比如时间、内存占用、数据库占用情况等
- 关闭和清理连接失效的客户端
- 尝试进行持久化操作
那么redis是怎么来扫描这些过期的key的呢?redis为了追求极致的性能,所以不可能将所有的key遍历一遍,就跟它的扩容一样,还是采用了渐进式思想,具体流程如下:
- 1、
serverCron定时去执行清理方法,具体的定时频率可配置,默认100ms - 2、执行清理的时候不是扫描所有的key,而是扫描了设置了过期时间的key。也不是每次把所有过期的key都拿过来进行清理,因为如果过期的key比较多的时候,这个过程就会很慢
- 3、redis根据hash桶的维度来扫描,一次扫20个(默认值,可配)为止,如果第一个hash桶只扫到15个,则继续扫第二个hash桶。但是如果第二个桶不止5个,redis仍然会将第二个桶扫描完(秉承着来都来了的原则)
- 4、找到扫描到的key里边过期的key,进行删除
- 5、如果连续取了400个空桶,或者扫描到的过期key跟扫描的总数比例达到10%(可配),则继续循环执行3、4步
- 6、循环次数达到16次后,会进行时间检测,如果这个时间超过了指定的时间,则跳出。本次定时任务执行结束
核心方法在expire.c的activeExpireCycle方法:
c
#define ACTIVE_EXPIRE_CYCLE_KEYS_PER_LOOP 20 /* Keys for each DB loop. */
#define ACTIVE_EXPIRE_CYCLE_FAST_DURATION 1000 /* Microseconds. */
#define ACTIVE_EXPIRE_CYCLE_SLOW_TIME_PERC 25 /* Max % of CPU to use. */
#define ACTIVE_EXPIRE_CYCLE_ACCEPTABLE_STALE 10 /* % of stale keys after which we do extra efforts. */
void activeExpireCycle(int type) {
/* Adjust the running parameters according to the configured expire
* effort. The default effort is 1, and the maximum configurable effort
* is 10.
*/
unsigned long effort = server.active_expire_effort-1, /* Rescale from 0 to 9. */
config_keys_per_loop = ACTIVE_EXPIRE_CYCLE_KEYS_PER_LOOP + ACTIVE_EXPIRE_CYCLE_KEYS_PER_LOOP/4*effort,
config_cycle_fast_duration = ACTIVE_EXPIRE_CYCLE_FAST_DURATION + ACTIVE_EXPIRE_CYCLE_FAST_DURATION/4*effort,
config_cycle_slow_time_perc = ACTIVE_EXPIRE_CYCLE_SLOW_TIME_PERC + 2*effort,
config_cycle_acceptable_stale = ACTIVE_EXPIRE_CYCLE_ACCEPTABLE_STALEeffort;
/* This function has some global state in order to continue the work
* incrementally across calls. */
static unsigned int current_db = 0; /* Last DB tested. */
static int timelimit_exit = 0; /* Time limit hit in previous call? */
static long long last_fast_cycle = 0; /* When last fast cycle ran. */
int j, iteration = 0;
int dbs_per_call = CRON_DBS_PER_CALL;
long long start = ustime(), timelimit, elapsed;
/* When clients are paused the dataset should be static not just from the
* POV of clients not being able to write, but also from the POV of
* expires and evictions of keys not being performed.
*/
if (clientsArePaused()) return;
if (type == ACTIVE_EXPIRE_CYCLE_FAST) {
/* Don't start a fast cycle if the previous cycle did not exit
* for time limit, unless the percentage of estimated stale keys is
* too high. Also never repeat a fast cycle for the same period
* as the fast cycle total duration itself. */
if (!timelimit_exit && server.stat_expired_stale_perc < config_cycle_acceptable_stale)
return;
if (start < last_fast_cycle + (longlong)config_cycle_fast_duration*2)
return;
last_fast_cycle = start;
}
/* We usually should test CRON_DBS_PER_CALL per iteration, with
* two exceptions:
*
* 1) Don't test more DBs than we have.
* 2) If last time we hit the time limit, we want to scan all DBs
* in this iteration, as there is work to do in some DB and we don't want
* expired keys to use memory for too much time. */
if (dbs_per_call > server.dbnum || timelimit_exit)
dbs_per_call = server.dbnum;
/* We can use at max 'config_cycle_slow_time_perc' percentage of CPU
* time per iteration. Since this function gets called with a frequency of
* server.hz times per second, the following is the max amount of
* microseconds we can spend in this function. */
timelimit = config_cycle_slow_time_perc*1000000/server.hz/100;
timelimit_exit = 0;
if (timelimit <= 0) timelimit = 1;
if (type == ACTIVE_EXPIRE_CYCLE_FAST)
timelimit = config_cycle_fast_duration; /* in microseconds. */
/* Accumulate some global stats as we expire keys, to have some idea
* about the number of keys that are already logically expired, but still
* existing inside the database. */
long total_sampled = 0;
long total_expired = 0;
//循环DB,可配,默认16
for (j = 0; j < dbs_per_call && timelimit_exit == 0; j++) {
/* Expired and checked in a single loop. */
unsigned long expired, sampled;
redisDb *db = server.db+(current_db % server.dbnum);
/* Increment the DB now so we are sure if we run out of time
* in the current DB we'll restart from the next. This allows to
* distribute the time evenly across DBs. */
current_db++;
/* Continue to expire if at the end of the cycle there are still
* a big percentage of keys to expire, compared to the number of keys
* we scanned. The percentage, stored in config_cycle_acceptable_stale
* is not fixed, but depends on the Redis configured "expire effort". */
do {
unsigned long num, slots;
long long now, ttl_sum;
int ttl_samples;
iteration++;
/* If there is nothing to expire try next DB ASAP. */
//如果没有过期key,循环下一个DB
if ((num = dictSize(db->expires)) == 0) {
db->avg_ttl = 0;
break;
}
slots = dictSlots(db->expires);
now = mstime();
/* When there are less than 1% filled slots, sampling the key
* space is expensive, so stop here waiting for better times...
* The dictionary will be resized asap. */
if (num && slots > DICT_HT_INITIAL_SIZE && (num*100/slots < 1)) break;
/* The main collection cycle. Sample random keys among keys
* with an expire set, checking for expired ones. */
expired = 0;
sampled = 0;
ttl_sum = 0;
ttl_samples = 0;
//最多拿20个
if (num > config_keys_per_loop)
num = config_keys_per_loop;
/* Here we access the low level representation of the hash table
* for speed concerns: this makes this code coupled with dict.c,
* but it hardly changed in ten years.
*
* Note that certain places of the hash table may be empty,
* so we want also a stop condition about the number of
* buckets that we scanned. However scanning for free buckets
* is very fast: we are in the cache line scanning a sequential
* array of NULL pointers, so we can scan a lot more buckets
* than keys in the same time. */
long max_buckets = num*20;
long checked_buckets = 0;
//如果拿到的key大于20 或者 循环的checked_buckets大于400,跳出
while (sampled < num && checked_buckets < max_buckets) {
//遍历ht[0]、ht[1]
for (int table = 0; table < 2; table++) {
if (table == 1 && !dictIsRehashing(db->expires)) break;
unsigned long idx = db->expires_cursor;//扫描到的位置
idx &= db->expires->ht[table].sizemask;
//根据index拿到hash桶
dictEntry *de = db->expires->ht[table].table[idx];
long long ttl;
/* Scan the current bucket of the current table. */
checked_buckets++;
//循环hash桶里的所有key
while(de) {
/* Get the next entry now since this entry may get
* deleted. */
dictEntry *e = de;
de = de->next;
ttl = dictGetSignedIntegerVal(e)-now;
if(activeExpireCycleTryExpire(db,e,now)) expired++;
if (ttl > 0) {
/* We want the average TTL of keys yet
* not expired.
*/
ttl_sum += ttl;
ttl_samples++;
}
sampled++;
}
}
db->expires_cursor++;
}
total_expired += expired; //过期的key数量
total_sampled += sampled; //扫描的key数量
/* Update the average TTL stats for this database. */
if (ttl_samples) {
long long avg_ttl = ttl_sum/ttl_samples;
/* Do a simple running average with a few samples.
* We just use the current estimate with a weight of 2%
* and the previous estimate with a weight of 98%. */
if (db->avg_ttl == 0) db->avg_ttl = avg_ttl;
db->avg_ttl = (db->avg_ttl/50)*49 + (avg_ttl/50);
}
/* We can't block forever here even if there are many keys to
* expire. So after a given amount of milliseconds return to the
* caller waiting for the other active expire cycle. */
if ((iteration & 0xf) == 0) { /* check once every 16 iterations. */
//16次循环判断一次时间,看有没有超过设置的时间阈值
elapsed = ustime()-start;
if (elapsed > timelimit) {
timelimit_exit = 1;
server.stat_expired_time_cap_reached_count++;
break;
}
}
/* We don't repeat the cycle for the current database if there are
* an acceptable amount of stale keys (logically expired but yet
* not reclaimed). */
} while (sampled == 0 || (expired*100/sampled) > config_cycle_acceptable_stale); // 过期的数量 * 100/扫描的数量 = 配置的过期比例,默认10%
}
elapsed = ustime()-start; //前面的循环里的时间检测用到
server.stat_expire_cycle_time_used += elapsed;
latencyAddSampleIfNeeded("expire-cycle",elapsed/1000);
/* Update our estimate of keys existing but yet to be expired.
* Running average with this sample accounting for 5%.
*/
double current_perc;
if (total_sampled) {
current_perc = (double)total_expired/total_sampled;
} else
current_perc = 0;
server.stat_expired_stale_perc = (current_perc*0.05)+(server.stat_expired_stale_perc*0.95);
}2、淘汰策略
redis的淘汰策略是指在内存不够用的情况下,内存释放的一种策略,这个情况可能会涉及到已经设置了过期时间的和没有设置过期时间的,总之就是在这些key都是可用状态下因为内存不足不得已释放空间的时候让用户选择的一个策略。
内存的释放也不是一次性把所有的都释放,而是释放到满足放下新的key的的条件为止
redis的淘汰策略通过maxmemory-policy在redis.conf配置文件中进行配置
2.1、淘汰策略类型
2.1.1、noeviction(默认)
redis默认不会擅自删除有效的key,如果内存空间不足了,再写新的key的化直接oom,新数据不会写入
2.1.2、allkeys-lru
从所有的key中,删除最久没有被使用的key
2.1.3、allkeys-lfu
从所有的key中,删除使用频率最少的
2.1.4、allkeys-random
从所有的key中随机删除一些key
2.1.5、volatile-lru
从设置了过期时间的所有key中,删除最久没有被使用的key
2.1.6、volatile-lfu
从所有设置了过期时间的key中,删除最少使用的key
2.1.7、volatile-random
从所有设置了过期时间的key中,随机删除一些key
2.1.8、volatile-ttl
从所有设置了过期时间的key中,删除最近要过期的key
2.2、淘汰流程
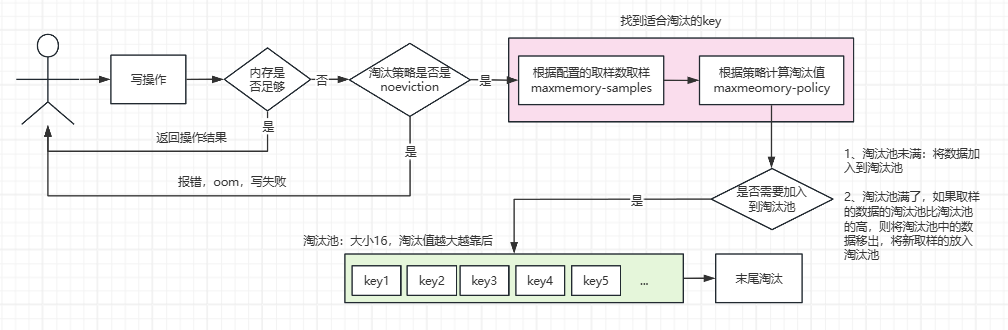
上图展示了redis在内存不足的时候的淘汰流程,简单概述一下:
-
1、用户在进行写操作的时候,首先会判断一下redis可用内存是否足够写新的数据,如果充足,直接执行,并返回执行结果
-
2、如果内存不够,则会触发redis的淘汰流程,redis会先判断一下用户有没有配置其它的淘汰策略,如果没有配置而是采用默认的
noeviction,则本次写失败,报oom,只能读不能写 -
3、如果用户配置了其它的淘汰策略,则会根据对应的策略找出适合淘汰的key
- ① 根据
maxmemory-samples采样指定的数据 - ② 根据
maxmemory-policy配置的策略,按照对应的算法计算采样数据的各个淘汰值
- ① 根据
-
4、计算出采样数据的淘汰值之后,会跟淘汰池里边的"待淘汰"的数据进行比较。来判断是否需要也加入到淘汰池里边去
淘汰池是一个容量为16的有序列表,进入淘汰池说明这些key是待淘汰的
- ① 如果淘汰池没有满,则将采样的数据加入到淘汰池中去
- ② 如果淘汰池满了,则用采样的数据的淘汰值跟淘汰池中的数据的淘汰值进行比较,如果发现有比自己的淘汰值小的,则将其从淘汰池移除,将自己放进去,并且按照顺序做好排序,淘汰值越大越往后
-
5、从最末尾开始删除对应的key,然后将其从淘汰池移除
具体的源码在evict.c的freeMemoryIfNeeded方法:
c
int freeMemoryIfNeeded(void) {
int keys_freed = 0;
/* By default replicas should ignore maxmemory
* and just be masters exact copies. */
//从库是否忽略内存淘汰限制
if (server.masterhost && server.repl_slave_ignore_maxmemory) return C_OK;
size_t mem_reported, mem_tofree, mem_freed;
mstime_t latency, eviction_latency, lazyfree_latency;
long long delta;
int slaves = listLength(server.slaves);
int result = C_ERR;
/* When clients are paused the dataset should be static not just from the
* POV of clients not being able to write, but also from the POV of
* expires and evictions of keys not being performed.
*/
if (clientsArePaused()) return C_OK;
//判断内存是否满,如果没有超过内存,直接返回
if(getMaxmemoryState(&mem_reported,NULL,&mem_tofree,NULL) == C_OK)
return C_OK;
mem_freed = 0;
latencyStartMonitor(latency);
if (server.maxmemory_policy == MAXMEMORY_NO_EVICTION)
//如果策略为不淘汰数据,直接报错OOM
goto cant_free; /* We need to free memory, but policy forbids. */
//到这一步肯定是内存不够 如果释放的内存不够 一直自旋释放内存
while (mem_freed < mem_tofree) {
int j, k, i;
static unsigned int next_db = 0;
sds bestkey = NULL; //定义最好的删除的key
int bestdbid;
redisDb *db;
dict *dict;
dictEntry *de;
if (server.maxmemory_policy & (MAXMEMORY_FLAG_LRU|MAXMEMORY_FLAG_LFU) || server.maxmemory_policy == MAXMEMORY_VOLATILE_TTL{
//如果淘汰算法是LRU | LFU | TTL
struct evictionPoolEntry *pool = EvictionPoolLRU; //淘汰池 默认大小16
//自旋找到合适的要淘汰的key为止
while(bestkey == NULL) {
unsigned long total_keys = 0, keys;
/* We don't want to make local-db choices when expiring keys,
* so to start populate the eviction pool sampling keys from
* every DB. */
for (i = 0; i < server.dbnum; i++) { //去不同的DB查找
db = server.db+i;
//判断需要淘汰的范围 是所有数据还是过期的数据
dict = (server.maxmemory_policy & MAXMEMORY_FLAG_ALLKEYS) ? db->dict : db->expires;
if ((keys = dictSize(dict)) != 0) {
evictionPoolPopulate(i, dict, db->dict, pool); //关键方法:去从范围中取样拿到最适合淘汰的数据
(i, dict, db->dict, pool);
total_keys += keys;
}
}
if (!total_keys) break; /* No keys to evict. */ //没有key过期
/* Go backward from best to worst element to evict. */
for (k = EVPOOL_SIZE-1; k >= 0; k--) {
if (pool[k].key == NULL) continue;
bestdbid = pool[k].dbid;
if (server.maxmemory_policy & MAXMEMORY_FLAG_ALLKEYS) {
de = dictFind(server.db[pool[k].dbid].dict, pool[k].key);
} else {
de = dictFind(server.db[pool[k].dbid].expires, pool[k].key);
}
/* Remove the entry from the pool. */
if (pool[k].key != pool[k].cached)
sdsfree(pool[k].key);
pool[k].key = NULL;
pool[k].idle = 0;
/* If the key exists, is our pick. Otherwise it is
* a ghost and we need to try the next element. */
if (de) {
bestkey = dictGetKey(de);
break;
} else {
/* Ghost... Iterate again. */
}
}
}
}
/* volatile-random and allkeys-random policy */
else if (server.maxmemory_policy == MAXMEMORY_ALLKEYS_RANDOM || server.maxmemory_policy == MAXMEMORY_VOLATILE_RANDOM) {
/* When evicting a random key, we try to evict a key for
* each DB, so we use the static 'next_db' variable to
* incrementally visit all DBs. */
for (i = 0; i < server.dbnum; i++) {
j = (++next_db) % server.dbnum;
db = server.db+j;
dict = (server.maxmemory_policy == MAXMEMORY_ALLKEYS_RANDOM) ? db->dict : db->expires;
if (dictSize(dict) != 0) {
de = dictGetRandomKey(dict);
bestkey = dictGetKey(de);
bestdbid = j;
break;
}
}
}
/* Finally remove the selected key. */ // 移除这个key
if (bestkey) {
db = server.db+bestdbid;
robj *keyobj = createStringObject(bestkey,sdslen(bestkey));
propagateExpire(db,keyobj,server.lazyfree_lazy_eviction);
/* We compute the amount of memory freed by db*Delete() alone.
* It is possible that actually the memory needed to propagate
* the DEL in AOF and replication link is greater than the one
* we are freeing removing the key, but we can't account for
* that otherwise we would never exit the loop.
*
* AOF and Output buffer memory will be freed eventually so
* we only care about memory used by the key space. */
delta = (long long) zmalloc_used_memory();
latencyStartMonitor(eviction_latency);
//如果是异步淘汰 会进行异步淘汰
if (server.lazyfree_lazy_eviction)
dbAsyncDelete(db,keyobj);
else
//同步淘汰
dbSyncDelete(db,keyobj);
signalModifiedKey(NULL,db,keyobj);
latencyEndMonitor(eviction_latency);
latencyAddSampleIfNeeded("evictiondel",eviction_latency);
delta -= (long long) zmalloc_used_memory();
mem_freed += delta;
server.stat_evictedkeys++;
notifyKeyspaceEvent(NOTIFY_EVICTED, "evicted", keyobj, db->id);
decrRefCount(keyobj);
keys_freed++;
/* When the memory to free starts to be big enough, we may
* start spending so much time here that is impossible to
* deliver data to the slaves fast enough, so we force the
* transmission here inside the loop. */
if (slaves) flushSlavesOutputBuffers();
/* Normally our stop condition is the ability to release
* a fixed, pre-computed amount of memory. However when we
* are deleting objects in another thread, it's better to
* check, from time to time, if we already reached our target
* memory, since the "mem_freed" amount is computed only
* across the dbAsyncDelete() call, while the thread can
* release the memory all the time. */
if (server.lazyfree_lazy_eviction && !(keys_freed % 16)) {
if (getMaxmemoryState(NULL,NULL,NULL,NULL) == C_OK) {
/* Let's satisfy our stop condition.*/
mem_freed = mem_tofree;
}
}
} else {
goto cant_free; /* nothing to free... */
}
}
result = C_OK;
cant_free:
/* We are here if we are not able to reclaim memory. There is only one
* last thing we can try: check if the lazyfree thread has jobs in queue
* and wait... */
if (result != C_OK) {
latencyStartMonitor(lazyfree_latency);
while(bioPendingJobsOfType(BIO_LAZY_FREE)) {
if (getMaxmemoryState(NULL,NULL,NULL,NULL) == C_OK) {
result = C_OK;
break;
}
usleep(1000);
}
latencyEndMonitor(lazyfree_latency);
latencyAddSampleIfNeeded("evictionlazyfree",lazyfree_latency);
}
latencyEndMonitor(latency);
latencyAddSampleIfNeeded("eviction-cycle",latency);
return result;
}
}其中evictionPoolPopulate方法如下:
c
void evictionPoolPopulate(int dbid, dict *sampledict, dict *keydict, struct evictionPoolEntry *pool) {
int j, k, count;
//需要取样的数据
dictEntry *samples[server.maxmemory_samples];
//随机从需要取样的范围中得到取样的数据
count = dictGetSomeKeys(sampledict,samples,server.maxmemory_samples);
//循环取样数据
for (j = 0; j < count; j++) {
unsigned long long idle;
sds key;
robj *o;
dictEntry *de;
de = samples[j];
key = dictGetKey(de);
/* If the dictionary we are sampling from is not the main
* dictionary (but the expires one) we need to lookup the key
* again in the key dictionary to obtain the value object. */
if (server.maxmemory_policy != MAXMEMORY_VOLATILE_TTL) {
//如果是ttl,只能从带有过期时间的数据中获取,所以不需要获取对象,其他的淘汰策略都需要去我们的键值对中获取值对象
if (sampledict != keydict) de = dictFind(keydict, key);
o = dictGetVal(de);
}
/* Calculate the idle time according to the policy. This is called
* idle just because the code initially handled LRU, but is in fact
* just a score where an higher score means better candidate. */
if (server.maxmemory_policy & MAXMEMORY_FLAG_LRU){
//如果是LRU算法,采用LRU算法得到最长时间没访问的
idle = estimateObjectIdleTime(o);
} else if (server.maxmemory_policy & MAXMEMORY_FLAG_LFU) {
//如果是LFU算法,根据LRU算法得到最少访问的,但是用255-值 所以idle越大,越容易淘汰
/* When we use an LRU policy, we sort the keys by idle time
* so that we expire keys starting from greater idle time.
* However when the policy is an LFU one, we have a frequency
* estimation, and we want to evict keys with lower frequency
* first. So inside the pool we put objects using the inverted
* frequency subtracting the actual frequency to the maximum
* frequency of 255. */
idle = 255-LFUDecrAndReturn(o);
} else if (server.maxmemory_policy == MAXMEMORY_VOLATILE_TTL) {
//ttl 直接根据时间来
/* In this case the sooner the expire the better. */
idle = ULLONG_MAX - (long)dictGetVal(de);
} else {
serverPanic("Unknown eviction policy in evictionPoolPopulate()");
}
/* Insert the element inside the pool.
* First, find the first empty bucket or the first populated
* bucket that has an idle time smaller than our idle time. */
//讲取样的数据,计算好淘汰的idle后,放入淘汰池中
k = 0;
while (k < EVPOOL_SIZE && pool[k].key && pool[k].idle < idle) k++;
//自旋,找到淘汰池中比当前key的idle小的最后一个下标
//k=0说明上面循环没进,也就是淘汰池中的所有数据都比当前数据的idle大,并且淘汰池的最后一个不为空,说明淘汰池也是满的。优先淘汰淘汰池的
if (k == 0 && pool[EVPOOL_SIZE-1].key != NULL) {
/* Can't insert if the element is < the worst element we have
* and there are no empty buckets. */
continue;
} else if (k < EVPOOL_SIZE && pool[k].key == NULL) { //插入到桶后面 不管
/* Inserting into empty position. No setup needed before insert. */
} else { //插入到中间 会进行淘汰池的数据移动
/* Inserting in the middle. Now k points to the first element
* greater than the element to insert. */
if (pool[EVPOOL_SIZE-1].key == NULL) {
/* Free space on the right? Insert at k shifting
* all the elements from k to end to the right. */
/* Save SDS before overwriting. */
sds cached = pool[EVPOOL_SIZE-1].cached;
memmove(pool+k+1,pool+k, sizeof(pool[0])*(EVPOOL_SIZE-k-1));
pool[k].cached = cached;
} else {
/* No free space on right? Insert at k-1 */
k--;
/* Shift all elements on the left of k (included) to the
* left, so we discard the element with smaller idle time. */
sds cached = pool[0].cached; /* Save SDS before overwriting. */
if (pool[0].key != pool[0].cached)
sdsfree(pool[0].key);
memmove(pool,pool+1,sizeof(pool[0])*k);
//假如当前数据比淘汰池的有些数据大,那么淘汰最小的
pool[k].cached = cached;
}
}
/* Try to reuse the cached SDS string allocated in the pool entry,
* because allocating and deallocating this object is costly
* (according to the profiler, not my fantasy. Remember:
* premature optimizbla bla bla bla. */
//以下所及,将当前的放入淘汰池
int klen = sdslen(key);
if (klen > EVPOOL_CACHED_SDS_SIZE) {
pool[k].key = sdsdup(key);
} else {
memcpy(pool[k].cached,key,klen+1);
sdssetlen(pool[k].cached,klen);
pool[k].key = pool[k].cached;
}
pool[k].idle = idle;
pool[k].dbid = dbid;
}
}2.3、LRU算法
LRU(Least Recently Used),顾名思义,就是找久未被使用的数据,越最近使用越靠前,是一个时间维度的度量衡。在redis的淘汰策略中,LRU算法会先计算key多久未被使用了,越久未被使用,淘汰值就会越大,也就越优先被淘汰
原理:
- ① 所有的value在redis中都会被封装成一个RedisObject对象,在这个对象中,有一个属性lru
c
typedef struct redisObject {
unsigned type:4; //数据类型,string、hash、list、set...
unsigned encoding:4; //底层的数据结构,比如skiplist
unsigned lru:LRU_BITS;
/* LRU time (relative to global lru_clock) or
* LFU data (least significant 8 bits frequency
* and most significant 16 bits access time). */
int refcount;
void *ptr;
} robj;lru是24位:代表对象最后被访问的秒单位的最后24位:秒单位 & ((1<<24)-1)
如果是lru的时候,这个属性记录的就是lru时钟
如果是lru的时候,低8位记录的就是使用的次数,高16位代表的是时间
-
② 计算当前key多久未被使用
- 假如我们lruclock=当前时间的秒单位的最后24bit
- 如果当前时间的低24位比这个redis对象的lru大:lru_clock-redisObject.lru
- 如果当前时间的低24位比这个redis对象的lru小:lru_clock+(24位最大值-redisObject.lru)
参考
evict.c的estimateObjectIdleTime方法javaunsigned long long estimateObjectIdleTime(robj *o) { //获取秒单位时间的最后24位 unsigned long long lruclock = LRU_CLOCK(); //因为只有24位,所有最大的值为2的24次方-1 //超过最大值从0开始,所以需要判断lruclock(当前系统时间)跟缓存对象的lru字段的大小 if (lruclock >= o->lru) { //如果lruclock>=robj.lru,返回lruclock-o->lru,再转换单位 return (lruclock - o->lru) * LRU_CLOCK_RESOLUTION; } else { //否则采用lruclock + (LRU_CLOCK_MAX - o->lru),得到对象的值越小,返回的值越大,越大越容易被淘汰 return (lruclock + (LRU_CLOCK_MAX - o->lru)) * LRU_CLOCK_RESOLUTION; } }
2.4、LFU算法
LFU(文 Least Frequently Used),故名思意,就是最不经常使用的,是一个频率或次数维度的度量衡。换句话说就是使用的次数越多,就越靠前,即使很久很久没有被使用了。很显然,这在我们的业务场景可能会存在一定的问题,比如之前的热度key,但是现在已经凉凉了,没什么人用了。这就是 **LFU的时效性问题 **
在redis中,redis既记录了key最后被访问的分钟单位的最后16bit(高16位),也记录了key被使用的次数(低8位)
原理:
- ① 高16位记录的最后被访问的分钟单位的最后16位,然后计算出这个对象多少分钟没有被访问了
- ② 然后redis根据配置的
lfu-decay-time(多少分钟没有被访问,次数就减1)的值,计算出来一个值
参考evict.c的LFUDecrAndReturn方法:
c
unsigned long LFUDecrAndReturn(robj *o) {
//lru字段右移8位,得到前面16位的时间
unsigned long ldt = o->lru >> 8;
//lru字段与255进行&运算(255代表8位的最大值),
//得到8位counter值
unsigned long counter = o->lru & 255;
//如果配置了lfu_decay_time,用LFUTimeElapsed(ldt) 除以配置的值
//LFUTimeElapsed(ldt)源码见下
//总的没访问的分钟时间/配置值,得到每分钟没访问衰减多少
unsigned long num_periods = server.lfu_decay_time ? LFUTimeElapsed(ldt) / server.lfu_decay_time : 0;
if (num_periods)
//不能减少为负数,非负数用couter值减去衰减值
counter = (num_periods > counter) ? 0 : counter - num_periods;
return counter;
}注意:
-
因为次数是用低8位来记录的,最大值是255
-
如果当前次数小于等于5,每次访问必加1
-
如果当前次数大于5,小于255,则越往上,次数加1的概率越低
参考evict.c的计算次数的方法LFULogIncr:
c
uint8_t LFULogIncr(uint8_t counter) {
//如果已经到最大值255,返回255 ,8位的最大值
if (counter == 255) return 255;
//得到随机数(0-1)
double r = (double)rand()/RAND_MAX;
//LFU_INIT_VAL表示基数值(在server.h配置),5
double baseval = counter - LFU_INIT_VAL;
//如果达不到基数值,表示快不行了,baseval =0
if (baseval < 0) baseval = 0;
//如果快不行了,肯定给他加counter
//不然,按照几率是否加counter,同时跟baseval与
lfu_log_factor相关
//都是在分子,所以2个值越大,加counter几率越小
double p = 1.0/(baseval*server.lfu_log_factor+1);
if (r < p) counter++;
return counter;
}这就是官网factor配置和使用次数这两个因素对计算出来的结果的影响。简单总结就是factor越大,计算出来的次数结果就增长的越慢,也就是需要key使用更多次才能达到小factor同样的效果
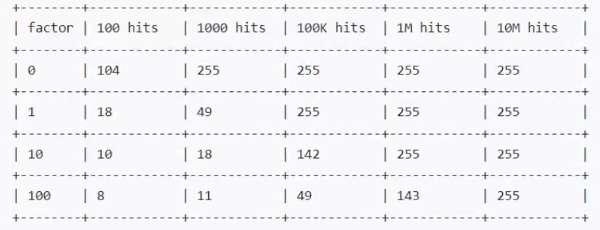
因此,redis通过这个方法,就巧妙地规避了LFU的时效性问题