title: 2026-01-20-论文阅读-Can-1B-LLM-Surpass-405B-LLM?
date: 2026-01-20
tags:
- 论文阅读
- TTS(推理侧缩放)
- LLM
《Can 1B LLM Surpass 405B LLM? Rethinking Compute-Optimal Test-Time Scaling》
一、论文基本信息
- 原文链接,翻译链接
- 作者:Runze Liu1,2,∗, Junqi Gao1,3, Jian Zhao4, Kaiyan Zhang2, Xiu Li2, Biqing Qi1,†, Wanli Ouyang1 and Bowen Zhou1,2,†
关键词:Test-Time Scaling (TTS),过程奖励模型(PRM),小语言模型(SLMs) 。
二、研究背景与问题定义
研究背景
近年来,大语言模型(LLMs)在复杂推理任务上取得了显著进步。随着 OpenAI o1 等模型的出现,研究界开始关注如何通过增加推理侧的计算投入来突破模型原有性能的上限,这一方向被称为测试时缩放(Test-Time Scaling, TTS)。目前的 TTS 主要分为两大路径:一是通过强化学习训练模型生成长思维链(Internal TTS);二是在预训练模型保持不变的情况下,利用外部搜索和验证机制(External TTS)来寻找最优解答。
现有的外部 TTS 研究仍面临诸多挑战。首先,虽然增加计算量能提升性能,但如何根据不同的问题难度、策略模型(Policy Model)和验证模型(PRM)来分配有限的算力,实现"计算最优(Compute-Optimal)"仍缺乏系统性分析。当前的验证器(PRM)在面对非其训练分布的模型输出时,往往会出现"分布外(OOD)"失效问题,导致推理过程被错误的奖励信号误导。业界对于小型模型(如 1B 或 3B 规模)在极端计算缩放下的潜力上限尚不明确。
问题定义
- 策略优化问题:在面对不同的策略模型、过程奖励模型(PRM)以及不同难度的任务时,如何选择并配置最优的 TTS 路径(如 Best-of-N、Beam Search 或 DVTS)以实现效率与性能的最佳平衡?
- 性能边界问题:通过极端的测试时计算缩放,小型语言模型在处理复杂数学和竞赛级任务(如 MATH-500, AIME24)时,性能提升的极限在哪里?它们是否真的能够通过算力补偿,在逻辑推理能力上跨越参数规模的鸿沟,甚至超越 405B 等级的巨型模型或现有的顶尖推理模型(如 o1-preview)?
三、核心方法与设计
A. 推理搜索算法的多样化设计
论文详细评估并对比了三类主流的外部测试时缩放(TTS)算法,以应对不同计算预算下的搜索需求:
- Best-of-N (BoN) :这是一种并行采样策略,模型针对同一问题生成 N N N 个完整的答案,再由验证器选出最优解。这种方法更适合逻辑推理链条较短或模型能力较强的场景。
- 束搜索 (Beam Search):这是一种逐步搜索策略,在推理的每个中间步骤生成多个分支,仅保留 PRM 评分最高的路径。这种方法能有效利用 PRM 的细粒度指导,适合逻辑严密且步骤较多的数学题。
- 多样化验证器树搜索 (DVTS) :为了克服 PRM 可能存在的评分偏差(如对特定路径的过度偏好),DVTS 通过引入路径多样性机制,在广度优先的基础上探索更多潜在的逻辑路径,防止搜索陷入"局部最优"的错误解中。
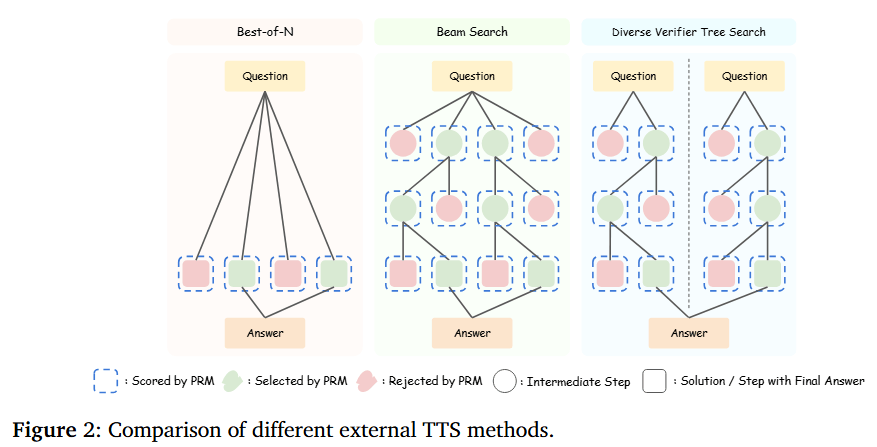
三种主流的外部推理侧缩放方法:Best-of-N (生成 N N N 个答案后由 PRM 筛选)、Beam Search (在每个推理步骤由 PRM 选出最优的分支继续搜索)以及 DVTS(分组搜索,强制多样性,在树搜索中引入多样性权重以防止 PRM 陷入逻辑偏差,即"不把鸡蛋放在同一个篮子里的搜索策略")。
B. 过程奖励模型(PRM)的适配与评估
研究重点考察了 PRM 在推理过程中的"判卷"效能。论文特别关注了 PRM 的分布外(OOD)问题,即当 PRM 用于验证一个它在训练阶段从未见过的小型策略模型时,其评分准确性会大幅下降。为此,设计中包含了多种参数规模(从 1.5B 到 72B)的 PRM,用于测试不同规模验证器对推理质量的影响。
C. 计算最优(Compute-Optimal)缩放策略
这是本文设计的核心创新点。研究者提出,最优的 TTS 策略并非固定不变,而是由以下三者决定的动态函数:
- 模型-验证器匹配:不同规模的 Policy Model 需要匹配相应强度的 PRM。
- 难度自适应:系统会根据题目难度自动切换搜索策略。例如,实验发现对于 3B 以下的小模型,Beam Search 这种"边走边查"的模式在处理难题时比直接生成完整答案(BoN)更为高效。
- 预算分配:研究通过大规模实验拟合出了计算预算与性能提升之间的缩放曲线,从而在特定推理资源下,指导模型选择生成答案的数量或搜索的深度。
四、实验
1. 实验设置与任务选择
两个权威的数学竞赛级基准测试:
- MATH-500:涵盖了从基础代数到复杂几何的五类难度等级,是评估模型分层推理能力的理想工具。
- AIME24:2024年美国数学邀请赛试题。这类题目对逻辑链条的长度和严谨性要求极高,目前大多数 70B 及以上规模的模型在不进行搜索的情况下表现极差。
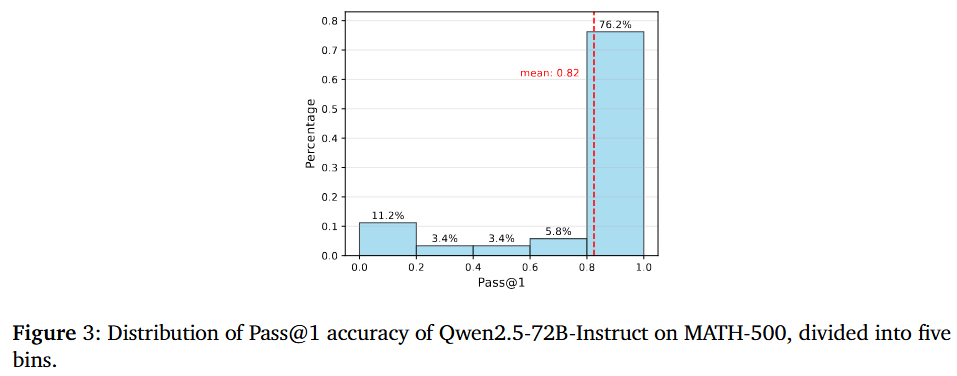
Qwen2.5-72B-Instruct 在 MATH-500 数据集上的准确率分布,其中超过 76.2% 的题目表现极佳(准确率 > 80%),证明了使用传统的"分位数"划分难度已不再适用,从而支持了论文提出改用绝对准确率阈值来重新定义题目难度的必要性。
2. 核心实验结果
实验结果刷新了业界对模型参数规模与能力之间关系的认知。通过采用"计算最优 TTS 策略",小型模型展现出了惊人的爆发力:
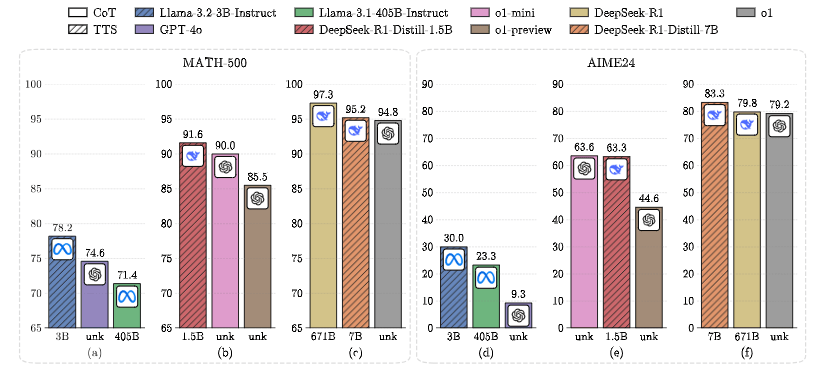
- 1B 级模型 :Llama-3.2-1B 在增加推理计算预算( N = 512 N=512 N=512)后,在 MATH-500 上的表现超越了参数量为其 400 余倍的 Llama-3.1-405B。
- 3B 级模型超越 GPT-4o:在 AIME24 这一极难任务中,Llama-3.2-3B 利用最优 TTS 策略取得了 30.0% 的准确率,不仅远超 Llama-3.1-405B(23.3%),更直接击败了 GPT-4o(9.3%)。
- 7B 级模型:经过 DeepSeek-R1 蒸馏的 7B 模型(DeepSeek-R1-Distill-7B)在 TTS 加持下,在 AIME24 上达到了 83.3% 的高分,超越了 OpenAI 的 o1 原生模型。
3. 计算效率分析(FLOPS 对比)
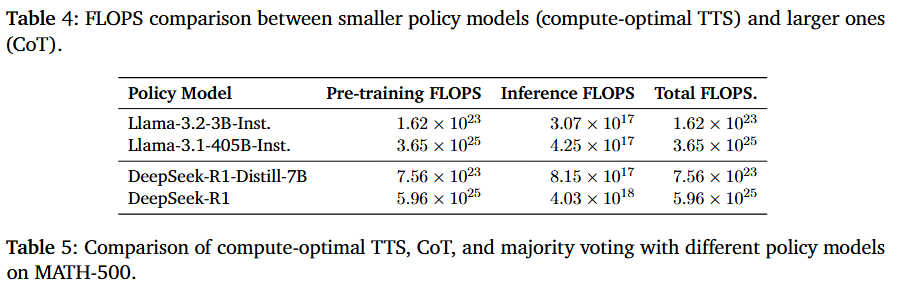
研究通过量化计算量(FLOPS)发现,小模型通过 TTS 提升性能的路径比单纯增大模型规模要经济得多。即便考虑了搜索过程中的额外采样开销,小模型的总计算开销(训练+推理)仍比大模型低 100左右的量级,且推理侧的 FLOPS 开销与 405B 级别的单次推理处于同一数量级。 (小模型重复推理百余次,也比大模型推理一次还省电)
4. 关键观察:不同难度的策略偏好
实验观察到 TTS 的收益曲线与题目难度高度相关:
- 简单题目:增加计算量边际收益递减极快,甚至可能因为 PRM 的误判引入噪声。
- 中等与高难度题目:TTS 的收益最为显著。对于此类题目,**Beam Search(束搜索)**在小模型上的表现显著优于 Best-of-N,证明了"分步验证"在处理复杂逻辑时的必要性。
5. 发现 PRM 的天花板
实验也揭示了限制 TTS 性能进一步提升的瓶颈------过程奖励模型(PRM)的局限性。研究人员在分析错误案例时发现,即使是 72B 规模的强力 PRM,在面对小模型的推理步骤时仍会出现"过度批评"(将正确步骤判为错误)或"长度偏见"等问题。
五、创新点、贡献与改进空间
1. 核心创新点:奖励感知的计算缩放 (Reward-Aware TTS)
论文跳出了"增加采样次数就能提升性能"的传统思维,提出 TTS 策略必须是奖励感知的。研究发现,由于过程奖励模型(PRM)存在打分偏见(如倾向于长答案)和分布外(OOD)问题,最优的计算缩放不仅要考虑计算量,还必须针对特定 PRM 的特性来动态调整搜索算法(如在小模型上更倾向于使用 Beam Search 而非简单的 Best-of-N)。
2. 主要贡献:打破"参数至上"的思维定式
- 跨级的性能飞跃:通过实证证明了 1B/3B 规模的模型在合理的 TTS 策略下可以超越 405B 等级的巨型模型。
- 多维度的系统分析:提供了一个覆盖 0.5B 至 72B 不同规模模型、多类 PRM 以及多种搜索算法的详尽评测框架,为后续研究如何针对不同难度任务选择最优 TTS 路径提供了指导原则。
- 极端任务的突破:在极难的 AIME24 任务上,通过 7B 蒸馏模型配合 TTS 击败了 o1 和 DeepSeek-R1。
3. 局限性与改进空间
- PRM 的鲁棒性瓶颈:实验暴露了当前 PRM 普遍存在"过度批评"和"错误忽视"等致命弱点,这直接限制了搜索算法的上限。未来需要开发更具泛化能力、对步骤逻辑更敏感的验证模型。
- 推理延迟与实时性:虽然 TTS 大幅提升了准确率,但多路径搜索和重复采样显著增加了推理延迟。如何在保证性能的前提下,通过并行优化或动态提早停止(Early Stopping)来降低延迟是实际应用的关键。
- 任务覆盖范围:目前的研究集中在数学和逻辑竞赛,TTS 策略在代码生成、科学发现或多模态推理等更广泛领域是否具有适用性。
六、我的思考
-
论文验证了"小模型+重(重复+重视)推理"可以跨级对标巨型模型,未来 AI 竞争将从参数规模竞赛转向推理算法的效率竞赛(参数规模增大的带来的边际效益性价比越来越低,上下文窗口和记忆检索也越来越重要)。
-
如果 3B 开源模型配合 TTS 就能在逻辑任务上超越 GPT-4o,那么如果一个有效的推理算法被提出,开源社区在推理能力上与顶尖大厂的差距将很快被填平。
-
既然 1B 模型能解决竞赛级数学题,未来在手机或电脑本地离线运行具备极强逻辑能力的 AI 是可能的(边缘端运行复杂推理),并且想数学等理化教育方面的突破可能会非常大。
-
未来最强的系统或许是像 DeepSeek-R1 这样既具备长思维能力,又在外部通过算法进行大规模验证的复合体。
- Internal CoT:模型在训练时就被教会了"在心里打草稿",它吐出的每一段话都包含很长的思考过程。这种能力是模型自带的基因。
- External Search / TTS:通过外部算法,让模型多写几个版本,或者每走一步都让"验证器"审视一遍。这种能力是靠外部工具和计算量堆出来的。
- 虽然 TTS 性能惊人,但在需要实时交互的场景下,如何平衡搜索带来的数分钟延迟与答案准确性将是产品化的核心难题,因为有的简单的工具调用或者命令运行是不需要推理的,感觉这也是为什么各家推理模型都提供了长短思考的选择。
现在大模型都在研究"路由器模型(Router Model)"来决定何时开启重推理
七、其他
可跟进的文献
- Scaling LLM Test-Time Compute Optimally can be More Effective than Scaling Model Parameters(证明了在某些任务中,扩展推理计算资源所带来的收益可以超过将模型参数规模扩大14倍的效果。)
- A Survey of Test-Time Compute: From Intuitive Inference to Deliberate Reasoning(综述了大语言模型从"系统1"(直觉快思考)向"系统2"(深思熟虑的慢思考)转型的技术路径。)
- Do NOT Think That Much for 2+3=? On the Overthinking of o1-Like LLMs("过度思考"问题,模型在处理简单任务时消耗了过多不必要的计算资源)
- Video-T1: Test-Time Scaling for Video Generation(将测试时缩放(TTS)从文本领域延伸到视频生成)