系列文章见CRN源码详细解析(1)-- 框架
模型在camera_radar_net_det.py文件中定义,入口在CRN_r18_256*704_128*128_4key.py中,模型类的最后几行代码
python
self.model = CameraRadarNetDet(self.backbone_img_conf,
self.backbone_pts_conf,
self.fuser_conf,
self.head_conf)进入模型,可以看到CameraRadarNetDet继承了BaseBEVDepth,初始化的时候可以看到4个主要网络模块,分别如下:
python
self.backbone_img = RVTLSSFPN(**backbone_img_conf) # 图像骨干网络
self.backbone_pts = PtsBackbone(**backbone_pts_conf) # 点云骨干网络
self.fuser = MFAFuser(**fuser_conf) # 多模态特征融合模块
self.head = BEVDepthHead(**head_conf) # 检测头这里看第一个模块,RVTLSSFPN,参数是backbone_img_conf。
进入RVTLSSFPN模块,跳转到rvt_lss_fpn.py文件,可以看到RVTLSSFPN继承了BaseLSSFPN,图像骨干网络的resnet18,代码中为self.img_backbone是在BaseLSSFPN中初始化,RVTLSSFPN初始化时直接继承使用,因此我们进入bass_lss_fpn.py查看。
可以看到,模型是基于mmcv框架生成的:
python
self.img_backbone = build_backbone(img_backbone_conf)这里调用mmcv的库,没有现成的源代码。
我们通过运行模型并打断点生成模型结构的方式来复现源代码。
首先,在rvt_lss_fpn.py中的RVTLSSFPN类在初始化后增加如下测试代码:
python
####### 测试代码,查看模型结构
# dummy_input = torch.randn(1, 3, 224, 224)
# # 前向传播
# with torch.no_grad():
# features = self.img_backbone(dummy_input)
# # 计算模型参数总数
# total_params = sum(p.numel() for p in self.img_backbone.parameters())
# print(f"输入形状: {dummy_input.shape}")
# for i, feat in enumerate(features):
# print(f"输出特征图{i+1}形状: {feat.shape}")
# print(f'模型参数总数: {total_params}')
# # 导出为onnx格式
# torch.onnx.export(
# self.img_backbone, # 要导出的模型
# dummy_input, # 模型的输入张量
# "crn_img_backbone.onnx", # 导出文件名
# export_params=True, # 是否导出训练好的参数
# opset_version=11, # ONNX算子集版本
# )
############ 测试代码结束 #############窗口会打印如下结果:
python
输入形状: torch.Size([1, 3, 224, 224])
输出特征图1形状: torch.Size([1, 64, 56, 56])
输出特征图2形状: torch.Size([1, 128, 28, 28])
输出特征图3形状: torch.Size([1, 256, 14, 14])
输出特征图4形状: torch.Size([1, 512, 7, 7])
模型参数总数: 11176512直接打印模型则会输出如下网络结构:
python
ResNet(
(conv1): Conv2d(3, 64, kernel_size=(7, 7), stride=(2, 2), padding=(3, 3), bias=False)
(bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(maxpool): MaxPool2d(kernel_size=3, stride=2, padding=1, dilation=1, ceil_mode=False)
(layer1): ResLayer(
(0): BasicBlock(
(conv1): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
)
(1): BasicBlock(
(conv1): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
)
)
(layer2): ResLayer(
(0): BasicBlock(
(conv1): Conv2d(64, 128, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(downsample): Sequential(
(0): Conv2d(64, 128, kernel_size=(1, 1), stride=(2, 2), bias=False)
(1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(1): BasicBlock(
(conv1): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
)
)
(layer3): ResLayer(
(0): BasicBlock(
(conv1): Conv2d(128, 256, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(downsample): Sequential(
(0): Conv2d(128, 256, kernel_size=(1, 1), stride=(2, 2), bias=False)
(1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(1): BasicBlock(
(conv1): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
)
)
(layer4): ResLayer(
(0): BasicBlock(
(conv1): Conv2d(256, 512, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(downsample): Sequential(
(0): Conv2d(256, 512, kernel_size=(1, 1), stride=(2, 2), bias=False)
(1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(1): BasicBlock(
(conv1): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
)
)
)
init_cfg={'type': 'Pretrained', 'checkpoint': 'torchvision://resnet18'}网络结构也可以通过生成的onnx文件查看:
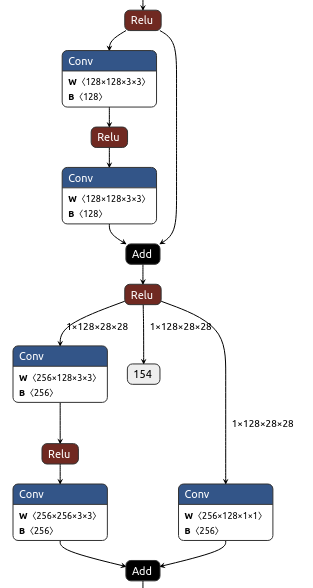
torchvision中自带resnet18,可以直接调用
python
from torchvision.models import resnet18
# 加载预训练的ResNet-18模型,这个模型和mmcv定义的不一致
# crn_img_backbone = resnet18(pretrained=True)
# 删除最后两层(全局平均池化层和全连接层)
# crn_img_backbone = nn.Sequential(*list(crn_img_backbone.children())[:-2])
# 打印修改后的模型结构
# print(crn_img_backbone)但这个模型和mmcv的配置不太一样,主要是两点,一是BasicBlock中ReLU模块的不同,二是输出特征维度不同。

mmcv的resnet18每一层特征都输出,而默认模型只输出最后一层特征。
因此这里通过修改resnet18的底层代码实现,如下:
python
# resnet18的模型代码
import torch
import torch.nn as nn
import torch.nn.functional as F
class BasicBlock(nn.Module):
"""搭建BasicBlock模块"""
expansion = 1 # 不做扩展
def __init__(self, in_channels, out_channels, stride=1, downsample=None):
super(BasicBlock, self).__init__() # 调用父类 nn.Module的构造函数
# 使用BN层是不需要使用bias的,bias最后会抵消掉
self.conv1 = nn.Conv2d(in_channels, out_channels, kernel_size=3,stride=stride, padding=1, bias=False)
self.bn1 = nn.BatchNorm2d(out_channels) # BN层, BN层放在conv层和relu层中间使用
self.relu = nn.ReLU(inplace=True)
self.conv2 = nn.Conv2d(out_channels, out_channels, kernel_size=3,stride=1, padding=1, bias=False)
self.bn2 = nn.BatchNorm2d(out_channels)
self.downsample = downsample
def forward(self, x):
identity = x
out = self.conv1(x)
out = self.bn1(out)
# out = self.relu(out)
out = self.conv2(out)
out = self.bn2(out)
out = self.relu(out)
if self.downsample is not None: # 保证原始输入X的size与主分支卷积后的输出size叠加时维度相同
identity = self.downsample(x)
out += identity
out = self.relu(out)
return out
"""神经网络的前向传播函数:
它接受一个输入张量X,然后通过一些卷积层和批量归一化层来计算输出张量Y。
如果存在下采样层,它将对输入张量进行下采样以使其与输出张量的尺寸相同。
最后,输出张量Y和输入张量X的恒等映射相加并通过ReLU激活函数进行激活。"""
class ResNet18(nn.Module):
# num_classes是训练集的分类个数
def __init__(self, num_classes=2):
super(ResNet18, self).__init__()
self.in_channels = 64 # 输出通道数(即卷积核个数),会生成与设定的输出通道数相同的卷积核个数
self.conv1 = nn.Conv2d(3, 64, kernel_size=7, stride=2, padding=3, bias=False)
self.bn1 = nn.BatchNorm2d(64)
self.relu = nn.ReLU(inplace=True)
self.maxpool = nn.MaxPool2d(kernel_size=3, stride=2, padding=1)
self.layer1 = self.residual_layer(64, 2)
self.layer2 = self.residual_layer(128, 2, stride=2)
self.layer3 = self.residual_layer(256, 2, stride=2)
self.layer4 = self.residual_layer(512, 2, stride=2)
# self.avgpool = nn.AdaptiveAvgPool2d((1, 1))
# self.fc = nn.Linear(512 * BasicBlock.expansion, num_classes)
# 创建残差网络层
def residual_layer(self, out_channels, blocks, stride=1):
downsample = None
if stride !=1 or self.in_channels != out_channels * BasicBlock.expansion:
downsample = nn.Sequential(
nn.Conv2d(self.in_channels, out_channels * BasicBlock.expansion, kernel_size=1, stride=stride, bias=False),
nn.BatchNorm2d(out_channels * BasicBlock.expansion),
)
layers = []
# layers列表保存某个layer_x组块里for循环生成的所有层
# 添加每一个layer_x组块里的第一层,第一层决定此组块是否需要下采样(后续层不需要)
layers.append(BasicBlock(self.in_channels, out_channels, stride, downsample))
self.in_channels = out_channels * BasicBlock.expansion
for _ in range(1, blocks):
layers.append(BasicBlock(self.in_channels, out_channels))
# 非关键字参数的特征是一个星号*加上参数名,比如*number,定义后,number可以接收任意数量的参数,并将它们储存在一个tuple中
return nn.Sequential(*layers)
def forward(self, x):
x = self.conv1(x)
x = self.bn1(x)
x = self.relu(x)
x = self.maxpool(x)
x1 = self.layer1(x) # x = self.layer1(x)
x2 = self.layer2(x1) # x = self.layer2(x)
x3 = self.layer3(x2) # x = self.layer3(x)
x4 = self.layer4(x3) # x = self.layer4(x)
# x = self.avgpool(x4)
# x = torch.flatten(x, 1)
# x = self.fc(x)
return x1, x2, x3, x4 # return x
# 测试ResNet18模型
if __name__ == "__main__":
model = ResNet18(num_classes=1000)
print(model)
# 创建一个随机输入张量(模拟图像批次)
dummy_input = torch.randn(1, 3, 224, 224)
# 前向传播
with torch.no_grad():
features = model(dummy_input)
# 计算模型参数总数
total_params = sum(p.numel() for p in model.parameters())
print(f"输入形状: {dummy_input.shape}")
for i, feat in enumerate(features):
print(f"输出特征图{i+1}形状: {feat.shape}")
print(f'模型参数总数: {total_params}') 核心修改点有是在ResNet18类中的forward函数中,将每层的特征图均进行输出,同时删除最后的池化层和全连接层。最后打印模型,生成onnx,和mmcv的结果一致。