一、核心知识总结
1.1. 基本概念
- 数据层级 :域 (基本数据单元)→ 记录 (一组相关域的集合)→ 文件 (一组相似记录的集合,支持按名访问)→ 数据库(更复杂的结构化数据集合)。
- 文件管理系统(FMS) :是用户 /
应用程序访问文件的唯一接口,负责实现按名存取和存取控制,核心作用是屏蔽底层存储细节,提供安全、高效的文件操作能力。
1.2. 文件组织与访问
| 文件组织类型 | 核心特点 | 适用场景 | 局限性 |
|---|---|---|---|
| 堆(Heap) | 数据按到达时间无序存储,记录长度可变;查找特定记录需全量遍历 | 临时数据存储、批量导入场景 | 随机查询效率极低 |
| 顺序文件 | 记录按关键字排序,长度固定;依赖顺序扫描访问 | 批处理(如日志、账单处理) | 增删改查性能差,仅适合静态数据 |
| 索引顺序文件 | 保留顺序文件的有序性,增加索引表加速查找;支持多级索引 | 需频繁范围查询且数据相对稳定的场景(如员工信息表) | 索引维护开销较大,高并发写入性能受限 |
| 索引文件 | 为每个记录建立索引,支持多域组合索引;随机访问效率高 | 需频繁随机查询的场景(如电商商品库) | 索引占用额外存储空间 |
| 直接 / 散列文件 | 基于关键字哈希直接定位记录,访问时间恒定 | 高频单点查询场景(如用户登录验证) | 哈希冲突会影响性能,范围查询效率低 |
二、知识拓展
2.1. 索引文件(Indexed File)
核心特征
- 存储结构:由数据文件和索引表两部分组成。数据文件中的记录可以是无序的,索引表存储 "关键字→记录地址" 的映射。
- 索引类型:支持单级索引、多级索引(如 Ext4 的间接索引),也可针对多个字段建立辅助索引(如同时按 "姓名" 和 "工号" 索引)。
- 访问方式:先在索引表中查找关键字,得到记录地址,再直接访问数据文件,随机查询效率高(时间复杂度 O (log n))。
适用场景
- 需要频繁进行随机查询,且查询条件多样的场景(如电商商品库、用户信息表)。
- 数据增删频繁,需动态维护索引的场景。
优缺点
- ✅ 优点:随机访问效率高,支持多条件查询,数据无需有序存储。
- ❌ 缺点:索引占用额外存储空间,增删记录时需维护索引,存在一定开销。
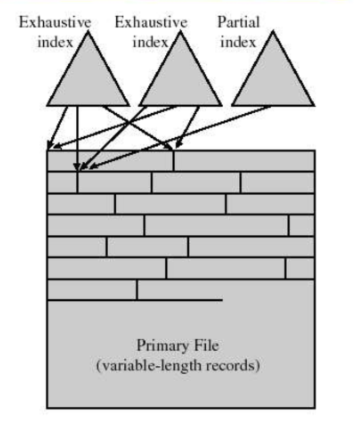
图1:索引文件
2.2. 索引顺序文件(Indexed Sequential File)
核心特征
- 存储结构:是顺序文件与索引文件的结合。数据文件中的记录按关键字有序存储,同时为数据文件建立稀疏索引(仅为部分关键记录建立索引,如每 100条记录建一个索引项)。
- 索引类型:通常采用多级索引,顶层索引指向底层索引,底层索引指向数据块,适合处理大文件。
- 访问方式:先通过索引表定位到目标记录所在的数据块,再在块内顺序扫描,兼顾了顺序访问和随机访问的效率。
适用场景
- 需频繁进行范围查询(如 "查询年龄 20-30 岁的用户"),且数据相对稳定的场景(如员工档案、订单流水)。
- 批处理与随机查询混合的场景。
优缺点
- ✅ 优点:范围查询效率高,索引占用空间比索引文件小,顺序访问性能接近顺序文件。
- ❌ 缺点:数据插入 / 删除需维护有序性,可能需要移动记录或拆分数据块,高并发写入性能受限。
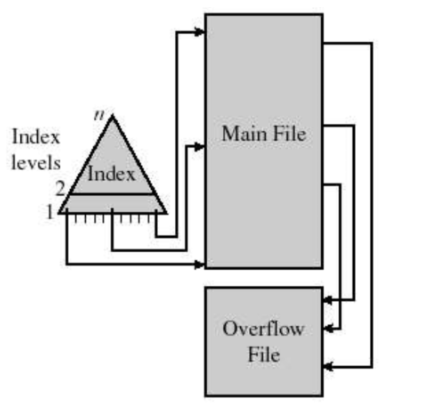
图2:索引顺序文件
3.3. 散列文件(Hashed/Direct File)
核心特征
- 存储结构:基于哈希函数将关键字映射为记录的存储地址,数据文件按哈希地址分布存储,无需额外索引表(或仅需冲突处理表)。
- 冲突处理:通过开放寻址法(如线性探测)或链地址法解决哈希冲突,保证关键字与地址的唯一映射。
- 访问方式:对关键字计算哈希值,直接定位到存储地址,访问时间恒定(理想情况下 O (1))。
适用场景
- 高频单点查询(如用户登录验证、字典查询),且查询条件为精确匹配的场景。
- 对响应时间要求极高的场景(如缓存系统、实时交易系统)。
优缺点
- ✅ 优点:单点查询速度最快,无需维护索引,存储开销小。
- ❌ 缺点:不支持范围查询,哈希冲突会降低性能,数据增删可能导致哈希重排。
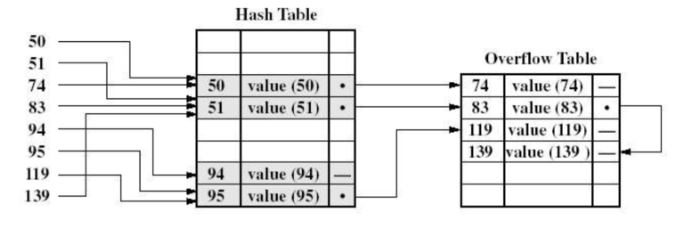
图3:散列文件