🔥本期内容已收录至专栏《Python爬虫实战》,持续完善知识体系与项目实战,建议先订阅收藏,后续查阅更方便~持续更新中!!

全文目录:
-
-
- [🌟 开篇语](#🌟 开篇语)
- [📌 上期回顾](#📌 上期回顾)
- [🎯 本节目标](#🎯 本节目标)
- [一、requests 库快速入门](#一、requests 库快速入门)
-
- [1.1 为什么选择 requests?](#1.1 为什么选择 requests?)
- [1.2 最简单的请求](#1.2 最简单的请求)
- [1.3 requests 的核心方法](#1.3 requests 的核心方法)
- 二、编写第一个爬虫脚本
-
- [2.1 基础版本:最小可用](#2.1 基础版本:最小可用)
- [2.2 改进版本:添加异常处理](#2.2 改进版本:添加异常处理)
- [三、保存 HTML 到本地(核心技能)](#三、保存 HTML 到本地(核心技能))
-
- [3.1 为什么要保存原始 HTML?](#3.1 为什么要保存原始 HTML?)
- [3.2 基础保存方法](#3.2 基础保存方法)
- [3.3 文件命名规范(重要!)](#3.3 文件命名规范(重要!))
- [3.4 带元数据的保存方式](#3.4 带元数据的保存方式)
- 四、完整的爬虫脚本(可复用模板)
- 五、验证保存的文件
-
- [5.1 用浏览器打开](#5.1 用浏览器打开)
- [5.2 统计保存的文件](#5.2 统计保存的文件)
- 六、本节小结
- [📝 课后作业(必做,验收进入下一节)](#📝 课后作业(必做,验收进入下一节))
- [🔮 下期预告](#🔮 下期预告)
- 🌟文末
-
- [📌 专栏持续更新中|建议收藏 + 订阅](#📌 专栏持续更新中|建议收藏 + 订阅)
- [✅ 互动征集](#✅ 互动征集)
-
🌟 开篇语
哈喽,各位小伙伴们你们好呀~我是【喵手】。
运营社区: C站 / 掘金 / 腾讯云 / 阿里云 / 华为云 / 51CTO
欢迎大家常来逛逛,一起学习,一起进步~🌟
我长期专注 Python 爬虫工程化实战 ,主理专栏 👉 《Python爬虫实战》:从采集策略 到反爬对抗 ,从数据清洗 到分布式调度 ,持续输出可复用的方法论与可落地案例。内容主打一个"能跑、能用、能扩展 ",让数据价值真正做到------抓得到、洗得净、用得上。
📌 专栏食用指南(建议收藏)
- ✅ 入门基础:环境搭建 / 请求与解析 / 数据落库
- ✅ 进阶提升:登录鉴权 / 动态渲染 / 反爬对抗
- ✅ 工程实战:异步并发 / 分布式调度 / 监控与容错
- ✅ 项目落地:数据治理 / 可视化分析 / 场景化应用
📣 专栏推广时间 :如果你想系统学爬虫,而不是碎片化东拼西凑,欢迎订阅/关注专栏《Python爬虫实战》
订阅后更新会优先推送,按目录学习更高效~
📌 上期回顾
在第二章《网页基础》中,我们系统学习了网页基础知识:HTTP 请求响应机制、HTML 结构解析、JSON 数据处理,以及数据质量控制。现在,你已经掌握了爬虫的理论基础。
从本章开始,我们进入实战编码阶段!你将亲手编写真正可用的爬虫程序,从最简单的"抓取单个页面"开始,逐步构建工程化的采集系统。
🎯 本节目标
通过本节学习,你将能够:
- 使用 requests 库发起 HTTP 请求
- 正确处理响应内容(编码、状态码)
- 保存原始 HTML 到本地(便于调试复现)
- 设计合理的文件命名规范
- 实现基本的异常捕获和错误处理
- 交付验收:成功抓取一个网页并保存到本地,文件可用浏览器打开
一、requests 库快速入门
1.1 为什么选择 requests?
对比标准库 urllib:
python
# ❌ urllib:代码冗长
import urllib.request
req = urllib.request.Request(url, headers={'User-Agent': '...'})
response = urllib.request.urlopen(req)
html = response.read().decode('utf-8')
# ✅ requests:简洁优雅
import requests
response = requests.get(url, headers={'User-Agent': '...'})
html = response.textrequests 的优势:
- ✅ 语法简洁,人类友好
- ✅ 自动处理编码
- ✅ 内置会话管理
- ✅ 强大的异常处理
- ✅ 社区活跃,文档完善
1.2 最简单的请求
python
import requests
# 最基础的 GET 请求
response = requests.get('https://httpbin.org/get')
# 查看响应信息
print(f"状态码: {response.status_code}")
print(f"内容类型: {response.headers['Content-Type']}")
print(f"响应内容: {response.text[:200]}") # 前 200 字符1.3 requests 的核心方法
python
import requests
# GET 请求(获取资源)
response = requests.get(url)
# POST 请求(提交数据)
response = requests.post(url, data={'key': 'value'})
# 带参数的请求
params = {'page': 1, 'size': 20}
response = requests.get(url, params=params)
# 带请求头
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64)',
'Referer': 'https://example.com/'
}
response = requests.get(url, headers=headers)
# 带超时设置(重要!)
response = requests.get(url, timeout=10) # 10秒超时二、编写第一个爬虫脚本
2.1 基础版本:最小可用
python
"""
第一个爬虫:抓取单个网页
文件名:spider_v1.py
"""
import requests
def fetch_page(url):
"""
抓取网页内容
Args:
url: 目标URL
Returns:
str: 网页HTML内容
"""
# 设置请求头(模拟浏览器)
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36'
}
# 发起请求
response = requests.get(url, headers=headers, timeout=10)
# 检查状态码
if response.status_code == 200:
return response.text
else:
print(f"请求失败,状态码:{response.status_code}")
return None
# 使用示例
if __name__ == "__main__":
url = "https://news.sina.com.cn/"
html = fetch_page(url)
if html:
print(f"✅ 成功获取网页,长度:{len(html)} 字符")
print(html[:500]) # 打印前 500 字符预览
else:
print("❌ 获取失败")运行测试:
bash
python spider_v1.py期望输出:
json
✅ 成功获取网页,长度:123456 字符
<!DOCTYPE html>
<html>
<head>
<meta charset="utf-8">
<title>新浪首页</title>
...2.2 改进版本:添加异常处理
python
"""
改进版爬虫:添加完整的错误处理
文件名:spider_v2.py
"""
import requests
from requests.exceptions import RequestException, Timeout, ConnectionError
def fetch_page(url, timeout=10):
"""
抓取网页内容(带错误处理)
Args:
url: 目标URL
timeout: 超时时间(秒)
Returns:
str: 网页HTML内容,失败返回 None
"""
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36'
}
try:
print(f"正在请求: {url}")
response = requests.get(url, headers=headers, timeout=timeout)
# 检查状态码
response.raise_for_status() # 4xx/5xx 会抛出异常
# 处理编码
if response.encoding == 'ISO-8859-1':
response.encoding = response.apparent_encoding
print(f"✅ 请求成功,状态码:{response.status_code}")
return response.text
except Timeout:
print(f"❌ 请求超时:{url}")
return None
except ConnectionError:
print(f"❌ 连接错误:{url}")
return None
except RequestException as e:
print(f"❌ 请求失败:{e}")
return None
except Exception as e:
print(f"❌ 未知错误:{e}")
return None
# 测试多个URL
if __name__ == "__main__":
test_urls = [
"https://news.sina.com.cn/",
"https://httpbin.org/status/404", # 测试 404
"https://httpbin.org/delay/15", # 测试超时
]
for url in test_urls:
print(f"\n{'='*60}")
html = fetch_page(url, timeout=5)
if html:
print(f"成功获取 {len(html)} 字符")
print(f"{'='*60}")三、保存 HTML 到本地(核心技能)
3.1 为什么要保存原始 HTML?
工程化理由:
- 调试便利:可以离线分析页面结构
- 可复现性:出问题时能回溯原始数据
- 法律保护:证明采集时的页面内容
- 版本对比:对比网站改版前后的变化
- 减少重复请求:避免频繁访问同一页面
3.2 基础保存方法
python
import os
from datetime import datetime
def save_html(html, filename):
"""
保存 HTML 到本地文件
Args:
html: HTML 内容
filename: 文件名
"""
# 确保目录存在
os.makedirs('data/raw', exist_ok=True)
# 完整路径
filepath = os.path.join('data/raw', filename)
# 写入文件
with open(filepath, 'w', encoding='utf-8') as f:
f.write(html)
print(f"✅ 已保存到:{filepath}")
# 使用示例
html = fetch_page("https://news.sina.com.cn/")
if html:
save_html(html, "sina_homepage.html")3.3 文件命名规范(重要!)
不好的命名:
python
# ❌ 太简单,容易覆盖
"page.html"
# ❌ 没有时间信息
"sina.html"
# ❌ 特殊字符会报错
"https://news.sina.com.cn/.html"推荐的命名规范:
python
def generate_filename(url, prefix="page"):
"""
生成标准化的文件名
Args:
url: 页面URL
prefix: 文件名前缀
Returns:
str: 文件名
格式:prefix_域名_时间戳.html
示例:page_sina.com.cn_20250121_103045.html
"""
from urllib.parse import urlparse
import re
# 提取域名
parsed = urlparse(url)
domain = parsed.netloc.replace('www.', '')
# 清理域名中的特殊字符
domain = re.sub(r'[^\w\.]', '_', domain)
# 生成时间戳
timestamp = datetime.now().strftime('%Y%m%d_%H%M%S')
# 组合文件名
filename = f"{prefix}_{domain}_{timestamp}.html"
return filename
# 使用示例
url = "https://news.sina.com.cn/"
filename = generate_filename(url, prefix="news")
print(filename)
# 输出:news_sina.com.cn_20250121_103045.html3.4 带元数据的保存方式
python
import json
def save_with_metadata(html, url, save_dir='data/raw'):
"""
保存 HTML 并附带元数据
Args:
html: HTML 内容
url: 原始URL
save_dir: 保存目录
"""
# 生成文件名
filename = generate_filename(url)
base_name = filename.replace('.html', '')
# 确保目录存在
os.makedirs(save_dir, exist_ok=True)
# 保存 HTML
html_path = os.path.join(save_dir, filename)
with open(html_path, 'w', encoding='utf-8') as f:
f.write(html)
# 保存元数据
metadata = {
'url': url,
'filename': filename,
'fetch_time': datetime.now().isoformat(),
'content_length': len(html),
'status': 'success'
}
meta_path = os.path.join(save_dir, f"{base_name}.json")
with open(meta_path, 'w', encoding='utf-8') as f:
json.dump(metadata, f, indent=2, ensure_ascii=False)
print(f"✅ HTML 保存到:{html_path}")
print(f"✅ 元数据保存到:{meta_path}")
return html_path
# 使用示例
url = "https://news.sina.com.cn/"
html = fetch_page(url)
if html:
save_with_metadata(html, url)保存后的文件结构:
json
data/
└── raw/
├── news_sina.com.cn_20250121_103045.html
└── news_sina.com.cn_20250121_103045.json元数据内容示例:
json
{
"url": "https://news.sina.com.cn/",
"filename": "news_sina.com.cn_20250121_103045.html",
"fetch_time": "2025-01-21T10:30:45.123456",
"content_length": 123456,
"status": "success"
}四、完整的爬虫脚本(可复用模板)
python
"""
标准爬虫模板 v1.0
功能:抓取单个页面并保存
"""
import requests
import os
import json
from datetime import datetime
from urllib.parse import urlparse
import re
class SimpleFetcher:
"""简单的网页抓取器"""
def __init__(self, save_dir='data/raw'):
"""
初始化
Args:
save_dir: HTML 保存目录
"""
self.save_dir = save_dir
self.headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 '
'(KHTML, like Gecko) Chrome/120.0.0.0 Safari/537.36'
}
# 确保保存目录存在
os.makedirs(save_dir, exist_ok=True)
def fetch(self, url, timeout=10):
"""
抓取网页
Args:
url: 目标URL
timeout: 超时时间
Returns:
str: HTML内容,失败返回 None
"""
try:
print(f"📡 正在请求: {url}")
response = requests.get(
url,
headers=self.headers,
timeout=timeout
)
# 检查状态码
response.raise_for_status()
# 处理编码
if response.encoding == 'ISO-8859-1':
response.encoding = response.apparent_encoding
print(f"✅ 请求成功 (状态码: {response.status_code})")
return response.text
except requests.exceptions.Timeout:
print(f"⏱️ 请求超时: {url}")
except requests.exceptions.ConnectionError:
print(f"🔌 连接错误: {url}")
except requests.exceptions.HTTPError as e:
print(f"❌ HTTP 错误: {e}")
except Exception as e:
print(f"❌ 未知错误: {e}")
return None
def generate_filename(self, url, prefix="page"):
"""生成标准文件名"""
parsed = urlparse(url)
domain = parsed.netloc.replace('www.', '')
domain = re.sub(r'[^\w\.]', '_', domain)
timestamp = datetime.now().strftime('%Y%m%d_%H%M%S')
return f"{prefix}_{domain}_{timestamp}.html"
def save(self, html, url, prefix="page"):
"""
保存 HTML 及元数据
Args:
html: HTML 内容
url: 原始URL
prefix: 文件名前缀
Returns:
str: 保存的文件路径
"""
# 生成文件名
filename = self.generate_filename(url, prefix)
base_name = filename.replace('.html', '')
# 保存 HTML
html_path = os.path.join(self.save_dir, filename)
with open(html_path, 'w', encoding='utf-8') as f:
f.write(html)
# 保存元数据
metadata = {
'url': url,
'filename': filename,
'fetch_time': datetime.now().isoformat(),
'content_length': len(html),
'html_path': html_path
}
meta_path = os.path.join(self.save_dir, f"{base_name}.json")
with open(meta_path, 'w', encoding='utf-8') as f:
json.dump(metadata, f, indent=2, ensure_ascii=False)
print(f"💾 已保存: {html_path}")
print(f"📝 元数据: {meta_path}")
return html_path
def fetch_and_save(self, url, prefix="page"):
"""
抓取并保存(一站式)
Args:
url: 目标URL
prefix: 文件名前缀
Returns:
str: 保存的文件路径,失败返回 None
"""
html = self.fetch(url)
if html:
return self.save(html, url, prefix)
return None
# ========== 使用示例 ==========
if __name__ == "__main__":
# 创建抓取器
fetcher = SimpleFetcher(save_dir='data/raw')
# 测试URL列表
urls = [
("https://news.sina.com.cn/", "sina_news"),
("https://www.people.com.cn/", "people_news"),
]
print("=" * 60)
print("🕷️ 开始爬取...")
print("=" * 60)
# 批量抓取
for url, prefix in urls:
print(f"\n【任务】{prefix}")
filepath = fetcher.fetch_and_save(url, prefix)
if filepath:
print(f"✅ 成功!文件:{filepath}\n")
else:
print(f"❌ 失败!\n")
# 礼貌延迟
import time
time.sleep(2)
print("=" * 60)
print("🎉 爬取完成!")
print("=" * 60)实际运行结果展示如下:
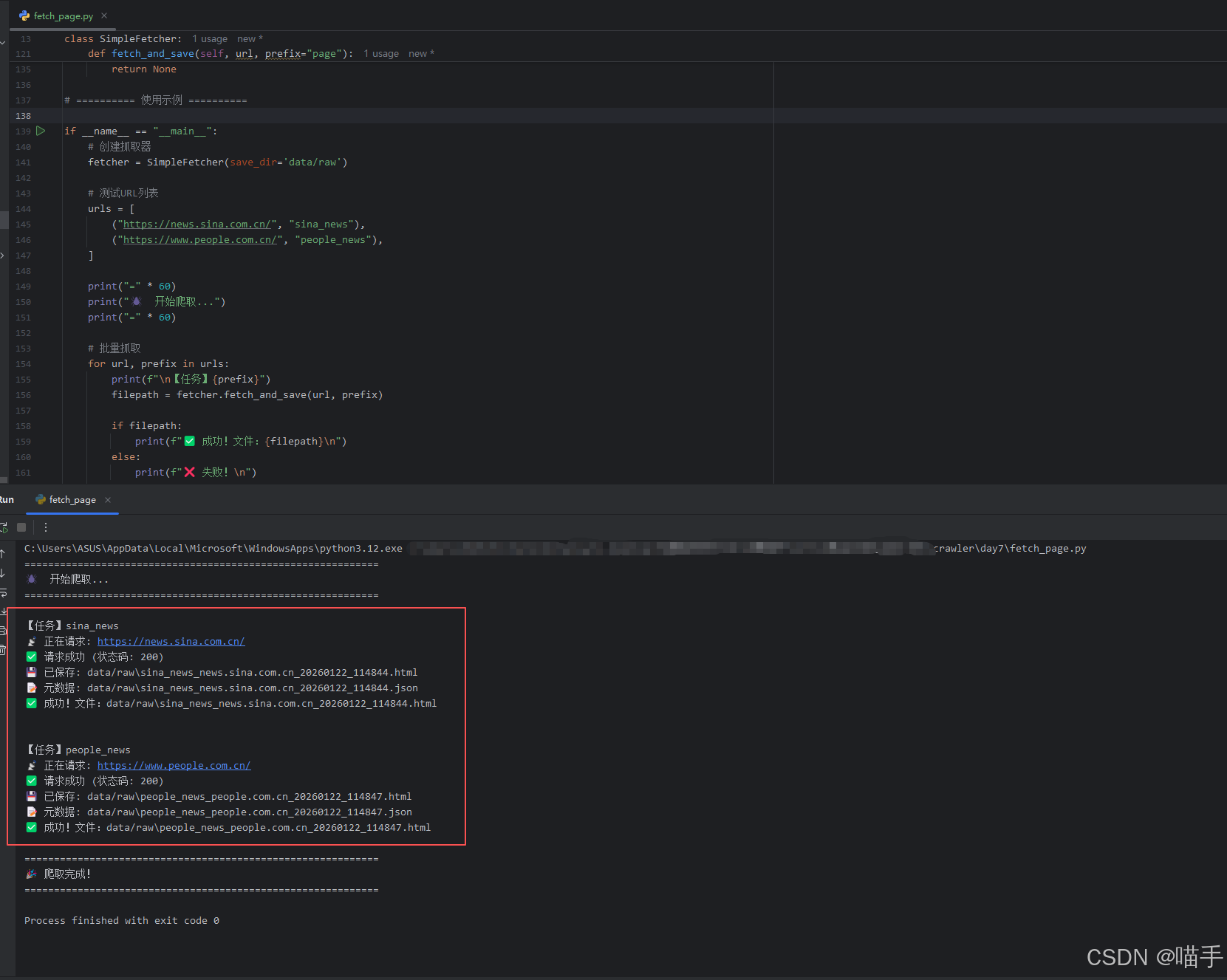
实际保存文件于当前data文件夹,效果截图展示如下:
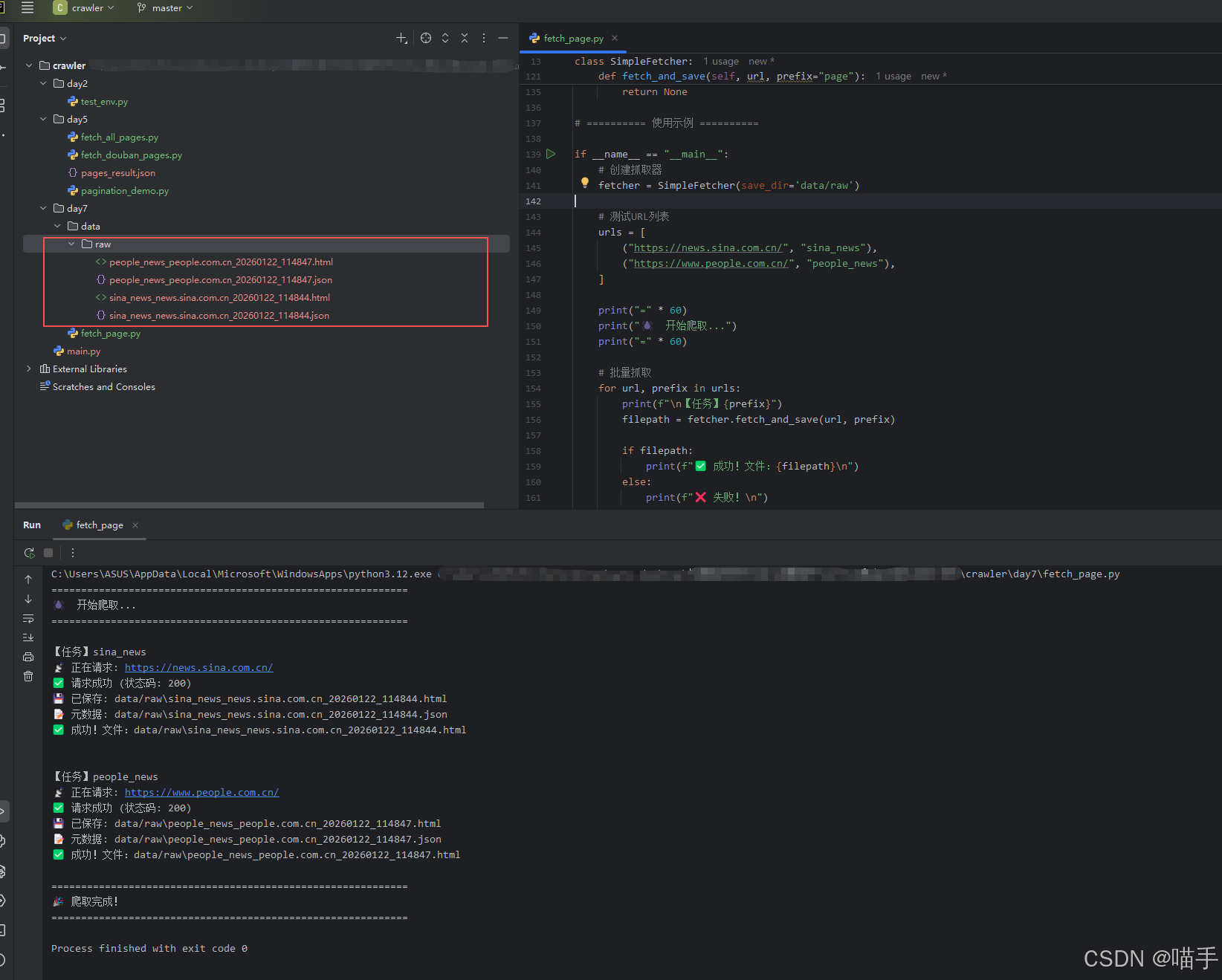
五、验证保存的文件
5.1 用浏览器打开
python
import webbrowser
# 打开保存的 HTML 文件
html_path = "data/raw/sina_news_20250121_103045.html"
webbrowser.open(f'file://{os.path.abspath(html_path)}')5.2 统计保存的文件
python
def list_saved_files(directory='data/raw'):
"""列出已保存的所有文件"""
html_files = []
for filename in os.listdir(directory):
if filename.endswith('.html'):
filepath = os.path.join(directory, filename)
size = os.path.getsize(filepath)
html_files.append({
'filename': filename,
'size': size,
'size_kb': round(size / 1024, 2)
})
print(f"\n📂 目录:{directory}")
print(f"📊 共 {len(html_files)} 个 HTML 文件\n")
for file_info in html_files:
print(f" {file_info['filename']} ({file_info['size_kb']} KB)")
# 使用
list_saved_files()六、本节小结
本节我们完成了第一个实用爬虫:
✅ requests 使用 :掌握 GET 请求的基本用法
✅ 异常处理 :捕获超时、连接错误等异常
✅ 编码处理 :正确解码不同编码的网页
✅ 文件保存 :规范化的文件命名和目录结构
✅ 元数据管理 :保存抓取时间、URL 等信息
✅ 可复用模板:SimpleFetcher 类可用于后续项目
核心原则:
- 永远设置超时(避免程序卡死)
- 永远捕获异常(避免程序崩溃)
- 永远保存原始数据(便于调试和复现)
- 使用标准化的文件命名(便于管理)
📝 课后作业(必做,验收进入下一节)
任务1:运行模板脚本
-
复制本节的
SimpleFetcher类 -
抓取以下三个网站的首页:
-
检查
data/raw目录,确认文件已保存 -
用浏览器打开保存的 HTML,验证内容正确
任务2:扩展功能
为 SimpleFetcher 添加以下方法:
python
def fetch_with_retry(self, url, max_retries=3):
"""带重试机制的抓取(下一节会详细讲)"""
pass
def get_save_stats(self):
"""统计已保存的文件数量和总大小"""
pass任务3:真实场景练习
选择一个你感兴趣的新闻网站,完成:
- 抓取首页并保存
- 打开保存的 HTML,找到新闻列表
- 记录新闻标题所在的 CSS 选择器
- 为下一步的解析做准备
验收方式:在留言区提交:
- 保存文件的目录结构截图
- 浏览器打开 HTML 文件的截图
- 扩展功能的代码
- 你选择的网站和分析结果
🔮 下期预告
下一节《伪装与会话:Headers、Session、Cookie》,我们将学习:
- 如何设置完整的请求头(User-Agent、Referer等)
- 使用 Session 对象管理会话
- 处理需要 Cookie 的网站
- 合规使用身份验证(不涉及破解)
- 避免被识别为"机器人"
预习建议 :
打开浏览器开发者工具,观察一个请求的完整请求头,特别关注 User-Agent、Referer、Cookie 字段。
💬 恭喜完成第一个爬虫!从此开启工程化之路! 🚀✨
记住:保存原始数据是工程师的好习惯。今天的麻烦,可能是明天的救命稻草。养成规范,受益终身!💪😊
🌟文末
好啦~以上就是本期 《Python爬虫实战》的全部内容啦!如果你在实践过程中遇到任何疑问,欢迎在评论区留言交流,我看到都会尽量回复~咱们下期见!
小伙伴们在批阅的过程中,如果觉得文章不错,欢迎点赞、收藏、关注哦~
三连就是对我写作道路上最好的鼓励与支持! ❤️🔥
📌 专栏持续更新中|建议收藏 + 订阅
专栏 👉 《Python爬虫实战》,我会按照"入门 → 进阶 → 工程化 → 项目落地"的路线持续更新,争取让每一篇都做到:
✅ 讲得清楚(原理)|✅ 跑得起来(代码)|✅ 用得上(场景)|✅ 扛得住(工程化)
📣 想系统提升的小伙伴:强烈建议先订阅专栏,再按目录顺序学习,效率会高很多~

✅ 互动征集
想让我把【某站点/某反爬/某验证码/某分布式方案】写成专栏实战?
评论区留言告诉我你的需求,我会优先安排更新 ✅
⭐️ 若喜欢我,就请关注我叭~(更新不迷路)
⭐️ 若对你有用,就请点赞支持一下叭~(给我一点点动力)
⭐️ 若有疑问,就请评论留言告诉我叭~(我会补坑 & 更新迭代)
免责声明:本文仅用于学习与技术研究,请在合法合规、遵守站点规则与 Robots 协议的前提下使用相关技术。严禁将技术用于任何非法用途或侵害他人权益的行为。