什么是Lora微调
我们在使用LLM的时候,有些情况下需要改变LLM模型的特性,比如
1 按照某种格式输出
2 调整输出语气
3 让模型回答它是由谁构建的
4 增加专业领域知识
如果对模型的所有参数都进行更改,是一个非常大的工程,现存的需求非常高,所以就诞生了很多其他的微调方法,Lora是这些微调方法的优秀工具
使用什么工具进行lora微调
1 Perft项目 这个工具不仅可以进行lora微调,还可以进行其他方式的微调,而且可以控制的参数非常多
2LlamaFactory 在国内很活跃的一个工具,提供了网页的UI操作,号称可以一键微调.
本次主要使用Perft进行微调,毕竟掌握底层知识是好事情
数据获取
本次微调数据来源于网络,具体是通过一个Agent来自动打开APP的页面,然后使用图片识别把数据从页面读取输出,然后存储到数据库中,关于Agent如何实现,我会在未来通过博客发出.
app的界面如下图所示,都是一条条有趣的句子.

通过Agent,可以把内容存储到数据库中,数据库如下所示:

数据清洗
可以看到,content字段里面是一段一段的话,通过序号分隔,并且有的content还包括了文档的标题,这时我们需要把每段话单独分隔出来,通过AI生成一段python脚本,这一步不要照抄,每个人获取的数据不同,清洗方式也不同
python
#!/usr/bin/env python3
import re
from pathlib import Path
def process_file(path: str = "article.txt"):
p = Path(path)
if not p.exists():
print(f"Input file not found: {p}")
return
# regex to remove leading separator characters after the number
sep_re = re.compile(r'^[\s\.,,、::\)\(\(\)\]\[\{\}\'\".\------]+')
out_lines = []
with p.open(encoding="utf-8") as f:
for raw in f:
line = raw.rstrip("\n")
# strip only left-side whitespace for the start check
s = line.lstrip()
m = re.match(r'^(\d+)(.*)$', s)
if not m:
continue
rest = m.group(2)
# remove leading separators (commas, dots, '、', parentheses, etc.)
rest = re.sub(sep_re, '', rest)
if rest:
out_lines.append(rest)
out_path = p.with_name(p.stem + '_cleaned' + p.suffix)
with out_path.open('w', encoding='utf-8') as w:
for L in out_lines:
w.write(L + "\n")
print(f"Written {len(out_lines)} lines to {out_path}")
if __name__ == '__main__':
import sys
infile = sys.argv[1] if len(sys.argv) > 1 else 'article.txt'
process_file(infile)转换数据格式
我们在微调模型的时候,都是使用的用户提问,模型回答的方式进行交流.我们在上一步提取到的都是一个一个的句子,没有提问.这种数据我们是没有办法进行微调的.所以我们要按照内容生成对应的问题.(这一步我暂时没有很好的方法,如果大家有其他方法,可以在下方留言,很感谢)
我的解决办法是,把内容输给LLM,让LLM给我反向输出问题,这样做从结果来看其实AI生成的问题并不是特别好,但是不影响我们进行模型微调的训练操作本身,只是训练出来的模型效果堪忧.
下方代码最关键的部分就是提示词,由于免费的glm只允许有3个并发,所以下方代码使用了3并发对glm进行请求
问:不是说python 有全局GIL锁的存在,并发没有任何效果吗?
答:要看具体的任务,对计算任务,内存任务,由于全局锁存在确实并发没有效果,但是对与IO任务效果杠杠的.
python
from dataclasses import dataclass, asdict
import concurrent.futures
import itertools
import logging
import os
import argparse
from typing import List, Optional
from langchain_openai import ChatOpenAI
from langchain_core.messages import SystemMessage, HumanMessage
import json
@dataclass
class Instruction:
input: str
output: str
def to_dict(self):
# 使用 dataclasses.asdict 自动将dataclass转为字典
return asdict(self)
logger = logging.getLogger(__name__)
logging.basicConfig(level=logging.INFO, format="%(asctime)s %(levelname)s %(message)s")
def create_llm(api_key: Optional[str] = None,
model: Optional[str] = None,
base_url: Optional[str] = None,
max_tokens: int = 3000,
temperature: float = 0.0,
top_p: float = 0.85,
frequency_penalty: float = 0.2) -> ChatOpenAI:
"""Create and return a ChatOpenAI client, reading defaults from environment if not provided."""
api_key = ""
model = model or os.getenv("LLM_MODEL", "glm-4.6v-flash")
base_url = base_url or os.getenv("LLM_BASE_URL", "https://open.bigmodel.cn/api/paas/v4/")
return ChatOpenAI(
api_key=api_key,
model=model,
base_url=base_url,
max_tokens=max_tokens,
temperature=temperature,
top_p=top_p,
frequency_penalty=frequency_penalty,
)
SYSTEM_PROMPT = (
"根据用户输入的内容生成对应的提问,要求问题简洁,具有针对性,只返回最符合要求的问题,不允许有多余的描述,解释或者符号。"
)
def get_instructions(llm: ChatOpenAI, text: str) -> str:
"""Send a single instruction request to the LLM and return text result."""
system = SystemMessage(content=SYSTEM_PROMPT)
human = HumanMessage(content=text)
messages = [system, human]
response = llm.invoke(messages)
return response.content
def process_cleaned(
llm: ChatOpenAI,
file_path: str = "article_cleaned.txt",
out_file: Optional[str] = None,
num_threads: int = 16,
limit: Optional[int] = None,
) -> List[Instruction]:
"""Process input lines with the LLM using a thread pool and stream results to `out_file`.
Results are written in the same order as input lines. Returns list of `Instruction`.
"""
# Read lines
lines: List[str] = []
try:
with open(file_path, encoding="utf-8") as f:
for raw in f:
line = raw.strip()
if line:
lines.append(line)
except FileNotFoundError:
logger.error("Input file not found: %s", file_path)
return []
if limit is not None:
lines = lines[:limit]
if not lines:
return []
counter = itertools.count(1)
def _fetch_index(idx: int, text: str):
call_no = next(counter)
logger.info("Call #%d: %s", call_no, text[:60])
try:
resp = get_instructions(llm, text).strip()
except Exception as e:
logger.exception("Error fetching for line %d", idx)
resp = f"ERROR: {e}"
return idx, resp
results: List[Optional[Instruction]] = [None] * len(lines)
# Open output file for streaming if requested
out_f = None
if out_file:
out_f = open(out_file, "w", encoding="utf-8")
try:
with concurrent.futures.ThreadPoolExecutor(max_workers=num_threads) as executor:
futures = [executor.submit(_fetch_index, i, t) for i, t in enumerate(lines)]
next_to_write = 0
for fut in concurrent.futures.as_completed(futures):
idx, resp = fut.result()
instr = Instruction(input=resp, output=lines[idx])
results[idx] = instr
# flush any contiguous ready items
while next_to_write < len(results) and results[next_to_write] is not None:
ready = results[next_to_write]
if out_f and ready:
out_f.write(json.dumps(ready.to_dict(), ensure_ascii=False) + "\n")
out_f.flush()
next_to_write += 1
finally:
if out_f:
out_f.close()
# mypy-friendly cast
return [r for r in results if r is not None]
def main():
parser = argparse.ArgumentParser(description="Generate instructions from cleaned article lines.")
parser.add_argument("--infile", default="article_cleaned.txt")
parser.add_argument("--outfile", default="instruct.txt")
parser.add_argument("--threads", type=int, default=3)
parser.add_argument("--limit", type=int, default=None)
args = parser.parse_args()
llm = create_llm()
results = process_cleaned(llm, file_path=args.infile, out_file=args.outfile, num_threads=args.threads, limit=args.limit)
logger.info("Completed: processed %d lines, wrote to %s", len(results), args.outfile)
if __name__ == "__main__":
main()经过这段代码之后,会形成最终的数据文档.这里只展示几行,在构建数据的时候,我也手动加入了调整身份的对话,比如让回答他是谁的时候,让他回答由bleuesprit创造,这个文件命名为下一节的train_format.jsonl
{"input": "你是谁", "output": "我是说废话的专家,由bleuesprit创造"}
{"input": "你好", "output": "我是说废话的专家,由bleuesprit创造"}
{"input": "睡觉不闭眼会睡不着吗?", "output": "睡觉的时候一定要闭上眼睛,不然会睡不着"}
{"input": "这是记忆提取困难的表现吗?", "output": "记是记住了,就是想不起来"}
{"input": "这个西红柿有番茄味,正常吗?", "output": "这个西红柿有一股番茄味"}
{"input": "为什么你不讨人厌的时候会招人喜欢?", "output": "你不讨人厌的时候,还挺招人喜欢的"}
{"input": "为什么看似很难实则不简单?", "output": "看似很难,其实一点也不简单"}执行lora
显卡资源
如果是你有A100,或者5090等高端显卡的富哥,可以在自己机器上微调,我只有一个4050 6G的移动端版本,所以微调会有压力,所以我选择租一个云显卡使用.
如果你已经有心仪的云平台可以自行使用,如果不想找,可以搜索一个平台叫做autodl ,上面的2080TI显卡1小时1元钱,当然他家价格是属于贵的那一档,我也是看了别人的文章被先入为主用了这个平台,不推荐长期使用.
构建数据集
使用下方的函数把train_format.jsonl的数据格式化成llm的输入,因为每个llm的chat_template不同,我下方的只是Qwen3 的template,其他模型的进行修改,这个template非常重要,如果template不对,我们微调出来的结果可能就是模型输出的都是乱码.
在代码中我们看到了三个非常重要的输出结果:
input_ids 这个是经过chat_template格式化后的提问和回答的的文本,再经过token后得到的可以直接进入大模型的输入,已经变成数字了
attention_mask:这个是告诉大模型,注意力机制生效token有哪些,在这里我看到是全1
labels :这个告诉大模型在计算loss的时候,哪些位不需要计算loss,因为提问部分我们不需要计算损失,只要对生成的部分计算损失
python
def build_samples_from_messages(messages: Dict, tokenizer, max_length: int):
"""
使用 Qwen3 对话模板显式构造样本:
<|im_start|>system ... <|im_end|>
<|im_start|>user ... <|im_end|>
<|im_start|>assistant ... <|im_end|>
规则:每个 assistant 回合生成 1 个样本;仅对该回合的回复位置计算 loss,其余为 -100。
"""
def render_block(role: str, content: str) -> str:
return f"<|im_start|>{role}\n{content}<|im_end|>\n"
# 仅保留 user/assistant,按顺序
conv = []
conv.append({"role": "system", "content": PROMPT})
conv.append({"role": "user", "content": messages["input"]})
conv.append({"role": "assistant", "content": messages["output"]})
samples = []
# 遍历每个 assistant 回合
for i, msg in enumerate(conv):
if msg["role"] != "assistant":
continue
# 上下文(到本轮 assistant 前)
context_msgs = conv[:i]
# 显式拼装 instruction(上下文完整块 + 本轮 assistant 头,不含回复)
prefix_text = ""
for cm in context_msgs:
prefix_text += render_block(cm["role"], cm["content"])
instruction_text = prefix_text + "<|im_start|>assistant\n" # 不加 <|im_end|>
# 回复部分(带结尾 <|im_end|>)
resp_text = f"{msg['content']}<|im_end|>"
# 分词
instruction_part = tokenizer(instruction_text, add_special_tokens=False)
response_part = tokenizer(resp_text, add_special_tokens=False)
input_ids = instruction_part["input_ids"] + response_part["input_ids"]
attention_mask = instruction_part["attention_mask"] + response_part["attention_mask"]
labels = [-100] * len(instruction_part["input_ids"]) + response_part["input_ids"]
# 长度截断(左截断,尽量保留结尾与完整回答)
if len(input_ids) > max_length:
input_ids = input_ids[-max_length:]
attention_mask = attention_mask[-max_length:]
labels = labels[-max_length:]
samples.append(
{"input_ids": input_ids, "attention_mask": attention_mask, "labels": labels}
)
return samples加载基础模型
既然要微调模型,肯定要有一个基础模型,我们使用model_scope下载qwen3 的1.7B的模型进行微调,因为1.7B属实小,微调起来压力小很多,使用2080Ti 11G的显存可以微调.
下面的代码意思就是把模型下载到本地,然后从本地加载模型的tokenizer和model
python
# 自动下载模型(若本地目录不存在则下载,并使用返回路径)
model_path = snapshot_download("Qwen/Qwen3-1.7B", cache_dir="./", revision="master")
tokenizer = AutoTokenizer.from_pretrained(model_path, use_fast=False, trust_remote_code=True)
if tokenizer.pad_token_id is None:
tokenizer.pad_token = tokenizer.eos_token
model = AutoModelForCausalLM.from_pretrained(
model_path,
device_map="auto",
torch_dtype=torch.bfloat16 if torch.cuda.is_available() else torch.float32,
trust_remote_code=True,
)模型下载的本地的效果如下:
图中箭头部分,就是模型的权重文件
创建lora初始模型
lora_config是非常重要的配置,
r:代表了低秩的具体的维度,一般是4,8,16,32维度,维度越需要训练的参数越多
通常需要通过实验来确定合适的lora_rank。可以从一个较小的值开始,如16或32,然后逐渐增加,观察模型在验证集上的性能(如准确率、F1 - score等)和训练效率(如训练时间、资源占用)之间的平衡。
lora_alpha:对原有矩阵修改的程度,大的值会增加lora的影响能力,lora_alpha需要通过实验来选择合适的值。一般可以先将其设置为与lora_rank相同的值,然后根据模型的训练情况进行调整。如果模型训练过程中出现过拟合迹象,可以减小lora_alpha;如果模型收敛过慢,可以适当增大lora_alpha
lora_dropout::每一次处理一个 batch 的数据时,lora_dropout都会随机选择部分激活值置 0(概率等于参数值,如 0.1 就是 10%),且不同 batch 的失活位置不同.核心作用是避免数据量小时放置过拟合...数值在0到1之间,0.1代表10%的概率.
target_modules:要对哪些层进行lora.不同的基础模型的名字都不一样,但是每个模型都有权重层,
轻量任务(如文本分类、短文本生成):仅选注意力层的 Q/K/V(如"q_proj", "k_proj", "v_proj"),参数少、训练快,效果足够;
复杂任务(如长文本生成、多轮对话、代码生成):在 Q/K/V 基础上,增加 O_proj(输出层)和 FFN 层(gate_proj/up_proj/down_proj),覆盖更多语义层;
容易出错的点:
不要选非线层(如 ReLU、LayerNorm、embedding 层):LoRA 仅对线性层有效,选这些层会无效;
不要盲目全选:比如把所有线性层都加入,会导致训练参数暴增(失去 LoRA 轻量的优势),且容易过拟合;
不同模型的模块命名可能有细微差异:比如有些模型是q_proj,有些是query_proj,需以实际打印结果为准;
部分框架(如 peft)支持模糊匹配:比如写"\*proj"可匹配所有以proj结尾的模块,但建议精准匹配,避免误选。
python
# LoRA 配置(r=8)
lora_config = LoraConfig(
task_type=TaskType.CAUSAL_LM,
r=8,
lora_alpha=32,
lora_dropout=0.1,
target_modules=["q_proj", "k_proj", "v_proj", "o_proj", "gate_proj", "up_proj", "down_proj"],
inference_mode=False,
)
model = get_peft_model(model, lora_config)创建训练参数
这里有非常重要的训练参数:
learning_rate 控制每次梯度更新的幅度,我这里使用了1e-4,通常学习率在 1e-4 ~ 5e-4之间
我这里没有使用学习率调度器,采用的固定学习率,如果需要使用调度器可以看看线性衰减、余弦衰减,余弦退火等调度器
关于学习率的选择是机器学习里面一个很长的话题,
num_train_epochs:训练轮次,训练集完成进入模型多少次.那是不是次数越多越好?并不是,次数多了会过拟合.次数一般在3-20次之间.
output_dir: lora训练完成之后的参数保存在哪里
python
kwargs = dict(
output_dir=args.output_dir,
per_device_train_batch_size=args.per_device_train_batch_size,
per_device_eval_batch_size=args.per_device_eval_batch_size,
gradient_accumulation_steps=args.gradient_accumulation_steps,
num_train_epochs=args.num_train_epochs,
learning_rate=args.learning_rate,
logging_steps=args.logging_steps,
save_steps=args.save_steps,
eval_steps=args.eval_steps,
gradient_checkpointing=True,
)
# 新增:每个 epoch 结束保存一次 checkpoint
kwargs["save_strategy"] = "epoch"
ta_sig = signature(TrainingArguments.__init__)
if "evaluation_strategy" in ta_sig.parameters:
kwargs["evaluation_strategy"] = "epoch" if (args.do_eval and eval_dataset is not None) else "no"
elif "eval_strategy" in ta_sig.parameters:
kwargs["eval_strategy"] = "epoch" if (args.do_eval and eval_dataset is not None) else "no"
if "save_on_each_node" in ta_sig.parameters:
kwargs["save_on_each_node"] = True
if "bf16" in ta_sig.parameters and torch.cuda.is_available():
kwargs["bf16"] = True
if "report_to" in ta_sig.parameters:
kwargs["report_to"] = "swanlab"
if "run_name" in ta_sig.parameters:
kwargs["run_name"] = args.swanlab_run_name
training_args = TrainingArguments(**kwargs)触发训练
经过了上面的参数准备就可以进行参数训练了
python
trainer = Trainer(
model=model,
args=training_args,
train_dataset=train_dataset,
eval_dataset=eval_dataset if (args.do_eval and eval_dataset is not None) else None,
data_collator=data_collator,
)
print(">>> 开始训练...")
trainer.train()训练之后的参数lora保存.
训练完成之后会保存成一个safetensors的文件,这个文件不能单独运行,需要和基础模型一起才能启动
完整的代码
在这里,由于我准备的微调的数据并不是很多,所以我把所有的数据都用来训练,并没有准备验证集,在实际生产中需要有验证集的存在,用来判断模型的泛化效果,
我们在下面的脚本使用swanlab 记录训练过程,loss,梯度等信息,用来对训练结果进行分析.
python
# LLM_fine_turning/train_psydt_lora.py
# YIRONGCHEN/PsyDTCorpus/train_psydt_lora.py
import os
import json
import argparse
from typing import List, Dict
from inspect import signature
import torch
from datasets import Dataset
from transformers import (
AutoModelForCausalLM,
AutoTokenizer,
TrainingArguments,
Trainer,
DataCollatorForSeq2Seq,
)
from peft import LoraConfig, TaskType, get_peft_model
from modelscope import snapshot_download
import swanlab
swanlab.login(api_key="apikey", save=True)
PROMPT = "你是一个说废话的专家,给出带有思考的回答"
def build_samples_from_messages(messages: Dict, tokenizer, max_length: int):
"""
使用 Qwen3 对话模板显式构造样本:
<|im_start|>system ... <|im_end|>
<|im_start|>user ... <|im_end|>
<|im_start|>assistant ... <|im_end|>
规则:每个 assistant 回合生成 1 个样本;仅对该回合的回复位置计算 loss,其余为 -100。
"""
def render_block(role: str, content: str) -> str:
return f"<|im_start|>{role}\n{content}<|im_end|>\n"
# 仅保留 user/assistant,按顺序
conv = []
conv.append({"role": "system", "content": PROMPT})
conv.append({"role": "user", "content": messages["input"]})
conv.append({"role": "assistant", "content": messages["output"]})
samples = []
# 遍历每个 assistant 回合
for i, msg in enumerate(conv):
if msg["role"] != "assistant":
continue
# 上下文(到本轮 assistant 前)
context_msgs = conv[:i]
# 显式拼装 instruction(上下文完整块 + 本轮 assistant 头,不含回复)
prefix_text = ""
for cm in context_msgs:
prefix_text += render_block(cm["role"], cm["content"])
instruction_text = prefix_text + "<|im_start|>assistant\n" # 不加 <|im_end|>
# 回复部分(带结尾 <|im_end|>)
resp_text = f"{msg['content']}<|im_end|>"
# 分词
instruction_part = tokenizer(instruction_text, add_special_tokens=False)
response_part = tokenizer(resp_text, add_special_tokens=False)
input_ids = instruction_part["input_ids"] + response_part["input_ids"]
attention_mask = instruction_part["attention_mask"] + response_part["attention_mask"]
labels = [-100] * len(instruction_part["input_ids"]) + response_part["input_ids"]
# 长度截断(左截断,尽量保留结尾与完整回答)
if len(input_ids) > max_length:
input_ids = input_ids[-max_length:]
attention_mask = attention_mask[-max_length:]
labels = labels[-max_length:]
samples.append(
{"input_ids": input_ids, "attention_mask": attention_mask, "labels": labels}
)
return samples
def load_psydt_dataset(train_path: str, eval_path: str, tokenizer, max_length: int, max_train_items: int = None, max_eval_items: int = None):
"""
读取 PsyDTCorpus 的 JSON 文件(数组),展开为样本列表:
- 每条对话 -> 多个样本(每个 assistant 回合一个样本)
"""
def load_file(path, max_items=None):
# 读取旧的JSONL文件
messages =[]
with open(path, "r",encoding='utf-8') as file:
for line in file:
# 解析每一行的json数据
data = json.loads(line)
messages.append(data)
messages = messages[:max_items] if max_items else messages
all_samples = []
for item in messages:
samples = build_samples_from_messages(item, tokenizer, max_length)
all_samples.extend(samples)
return all_samples
train_samples = load_file(train_path, max_items=max_train_items)
eval_samples = load_file(eval_path, max_items=max_eval_items) if eval_path and os.path.exists(eval_path) else []
train_dataset = Dataset.from_list(train_samples)
eval_dataset = Dataset.from_list(eval_samples) if len(eval_samples) > 0 else None
return train_dataset, eval_dataset
def predict(messages, model, tokenizer):
device = "cuda"
text = tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True
)
model_inputs = tokenizer([text], return_tensors="pt").to(device)
generated_ids = model.generate(
model_inputs.input_ids,
max_new_tokens=3200,
)
generated_ids = [
output_ids[len(input_ids):] for input_ids, output_ids in zip(model_inputs.input_ids, generated_ids)
]
response = tokenizer.batch_decode(generated_ids, skip_special_tokens=True)[0]
return response
def main():
parser = argparse.ArgumentParser()
# 模型与数据集参数
parser.add_argument("--model_repo", default="Qwen/Qwen3-1.7B")
parser.add_argument("--model_local_dir", default="./Qwen/Qwen3-1.7B")
# 训练/评估文件名(若不存在将自动下载)
parser.add_argument("--train_file", default="./train_format.jsonl")
parser.add_argument("--eval_file", default="./val_format.jsonl")
# 训练超参
parser.add_argument("--output_dir", default="./output/qwen3-1_7b-psydt-lora")
parser.add_argument("--max_length", type=int, default=2048)
parser.add_argument("--per_device_train_batch_size", type=int, default=1)
parser.add_argument("--per_device_eval_batch_size", type=int, default=1)
parser.add_argument("--gradient_accumulation_steps", type=int, default=4)
parser.add_argument("--num_train_epochs", type=int, default=2)
parser.add_argument("--learning_rate", type=float, default=1e-4)
parser.add_argument("--save_steps", type=int, default=400)
parser.add_argument("--logging_steps", type=int, default=10)
parser.add_argument("--eval_steps", type=int, default=200)
# 开启评估,并限制数据量:训练集300条对话,测试集20条对话
parser.add_argument("--do_eval", action="store_true", default=True)
parser.add_argument("--max_train_items", type=int, default=3000, help="限制读取训练对话条数(默认300)")
parser.add_argument("--max_eval_items", type=int, default=20, help="限制读取评估对话条数(默认20)")
# SwanLab 相关
parser.add_argument("--swanlab_project", default="qwen3-psydt-lora", help="SwanLab 项目名")
parser.add_argument("--swanlab_run_name", default="qwen3-1_7b-psydt-lora", help="SwanLab 运行名")
args = parser.parse_args()
os.makedirs(args.output_dir, exist_ok=True)
# SwanLab 环境与配置(与 HF-Trainer 集成)
os.environ["SWANLAB_PROJECT"] = args.swanlab_project
swanlab.config.update({
"model": args.model_repo,
"max_length": args.max_length,
"lora_r": 8,
"learning_rate": args.learning_rate,
"per_device_train_batch_size": args.per_device_train_batch_size,
"gradient_accumulation_steps": args.gradient_accumulation_steps,
"train_file": args.train_file,
"eval_file": args.eval_file if args.do_eval else "",
"max_train_items": args.max_train_items,
"max_eval_items": args.max_eval_items
})
# 自动下载模型(若本地目录不存在则下载,并使用返回路径)
model_path = snapshot_download("Qwen/Qwen3-1.7B", cache_dir="./", revision="master")
tokenizer = AutoTokenizer.from_pretrained(model_path, use_fast=False, trust_remote_code=True)
if tokenizer.pad_token_id is None:
tokenizer.pad_token = tokenizer.eos_token
model = AutoModelForCausalLM.from_pretrained(
model_path,
device_map="auto",
torch_dtype=torch.bfloat16 if torch.cuda.is_available() else torch.float32,
trust_remote_code=True,
)
model.enable_input_require_grads()
# LoRA 配置(r=8)
lora_config = LoraConfig(
task_type=TaskType.CAUSAL_LM,
r=8,
lora_alpha=32,
lora_dropout=0.1,
target_modules=["q_proj", "k_proj", "v_proj", "o_proj", "gate_proj", "up_proj", "down_proj"],
inference_mode=False,
)
model = get_peft_model(model, lora_config)
# 加载数据(限制条数:训练300,对应 --max_train_items;评估20,对应 --max_eval_items)
print(">>> 开始读取数据集...")
train_dataset, eval_dataset = load_psydt_dataset(
args.train_file,
args.eval_file if args.do_eval else "",
tokenizer,
max_length=args.max_length,
max_train_items=args.max_train_items,
max_eval_items=args.max_eval_items,
)
print(f">>> 训练样本数: {len(train_dataset)}",
f"评估样本数: {len(eval_dataset) if eval_dataset else 0}")
# 训练参数(启用 SwanLab,兼容不同 transformers 版本)
strat_val = "steps" if (args.do_eval and eval_dataset is not None) else "no"
kwargs = dict(
output_dir=args.output_dir,
per_device_train_batch_size=args.per_device_train_batch_size,
per_device_eval_batch_size=args.per_device_eval_batch_size,
gradient_accumulation_steps=args.gradient_accumulation_steps,
num_train_epochs=args.num_train_epochs,
learning_rate=args.learning_rate,
logging_steps=args.logging_steps,
save_steps=args.save_steps,
eval_steps=args.eval_steps,
gradient_checkpointing=True,
)
# 新增:每个 epoch 结束保存一次 checkpoint
kwargs["save_strategy"] = "epoch"
ta_sig = signature(TrainingArguments.__init__)
if "evaluation_strategy" in ta_sig.parameters:
kwargs["evaluation_strategy"] = "epoch" if (args.do_eval and eval_dataset is not None) else "no"
elif "eval_strategy" in ta_sig.parameters:
kwargs["eval_strategy"] = "epoch" if (args.do_eval and eval_dataset is not None) else "no"
if "save_on_each_node" in ta_sig.parameters:
kwargs["save_on_each_node"] = True
if "bf16" in ta_sig.parameters and torch.cuda.is_available():
kwargs["bf16"] = True
if "report_to" in ta_sig.parameters:
kwargs["report_to"] = "swanlab"
if "run_name" in ta_sig.parameters:
kwargs["run_name"] = args.swanlab_run_name
training_args = TrainingArguments(**kwargs)
data_collator = DataCollatorForSeq2Seq(tokenizer=tokenizer, padding=True)
trainer = Trainer(
model=model,
args=training_args,
train_dataset=train_dataset,
eval_dataset=eval_dataset if (args.do_eval and eval_dataset is not None) else None,
data_collator=data_collator,
)
print(">>> 开始训练...")
trainer.train()
# 仅保存 LoRA 适配器
model.save_pretrained(os.path.join(args.output_dir, "lora_adapter"))
value_messages = [
{"role": "system", "content": PROMPT},
{"role": "user", "content": "你好"}
]
response = predict(value_messages, model, tokenizer)
response_text = f"""
Question: 你好
LLM:{response}
"""
swanlab.log("Prediction",swanlab.Text(response_text))
print(response_text)
# 结束 SwanLab 任务
swanlab.finish()
if __name__ == "__main__":
main()训练过程查看
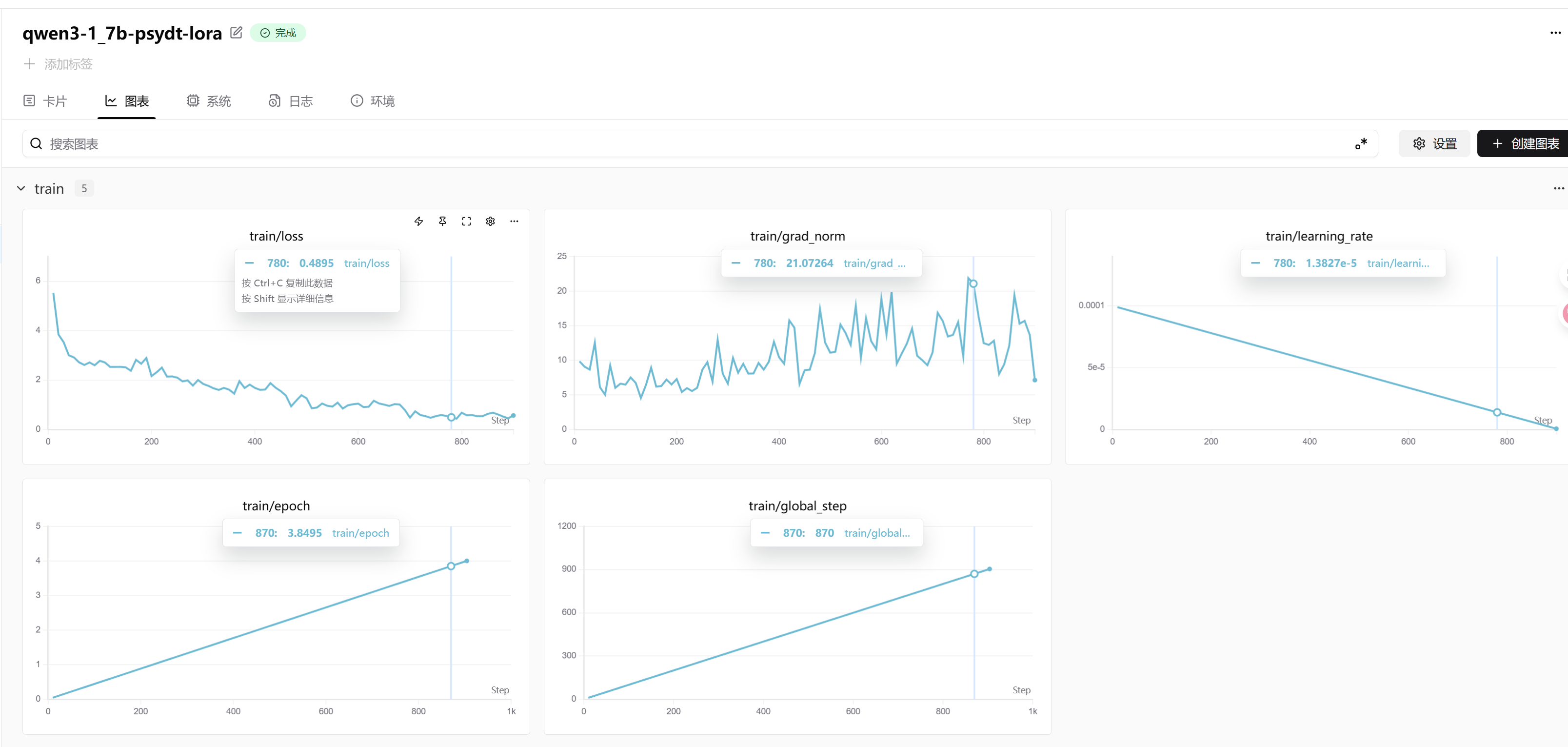
由于我们使用了swanlab记录了训练过程,我们可以在它的界面看到本次训练的过程,通过这个界面可以判断出模型是否收敛,是否发生了过拟合
使用训练后的模型进行推理
关键代码
最重要的代码是模型加载部分,前两行是加载基础模型,后一行就是加载刚刚训练出来的lora模型.
python
tokenizer = AutoTokenizer.from_pretrained("./Qwen/Qwen3-1___7B", use_fast=False, trust_remote_code=True)
model = AutoModelForCausalLM.from_pretrained("./Qwen/Qwen3-1___7B", device_map="auto", torch_dtype=torch.bfloat16)
# 加载lora模型
model = PeftModel.from_pretrained(model, model_id="./lora_adapter/")完整代码
python
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer
from peft import PeftModel
def predict(messages, model, tokenizer):
if torch.backends.mps.is_available():
device = "mps"
elif torch.cuda.is_available():
device = "cuda"
else:
device = "cpu"
text = tokenizer.apply_chat_template(messages, tokenize=False, add_generation_prompt=True)
model_inputs = tokenizer([text], return_tensors="pt").to(device)
generated_ids = model.generate(model_inputs.input_ids, max_new_tokens=2048)
generated_ids = [output_ids[len(input_ids):] for input_ids, output_ids in zip(model_inputs.input_ids, generated_ids)]
response = tokenizer.batch_decode(generated_ids, skip_special_tokens=True)[0]
return response
# 加载原下载路径的tokenizer和model
tokenizer = AutoTokenizer.from_pretrained("./Qwen/Qwen3-1___7B", use_fast=False, trust_remote_code=True)
model = AutoModelForCausalLM.from_pretrained("./Qwen/Qwen3-1___7B", device_map="auto", torch_dtype=torch.bfloat16)
# 加载lora模型
model = PeftModel.from_pretrained(model, model_id="./lora_adapter/")
input_value = input("请输入一行内容:")
while input_value.strip() != "q":
messages = [
{"role": "system", "content": "你是一个助手,给出对应的回答。"},
{"role": "user", "content": f"{input_value}"}
]
response = predict(messages, model, tokenizer)
print(response)
input_value = input("请输入一行内容:")