**文章标题:**Foundation Models in Autonomous Driving: A Survey on Scenario Generation and Scenario Analysis
(翻译)自动驾驶中的基础模型:场景生成与场景分析综述
文章发表于预印本:Foundation Models in Autonomous Driving: A Survey on Scenario Generation and Scenario Analysis
续:文献阅读篇#10:自动驾驶中的基础模型:场景生成与场景分析综述(1)-CSDN博客 &文献阅读篇#11:自动驾驶中的基础模型:场景生成与场景分析综述(2)-CSDN博客
4、四、视觉语言模型(VLMs)
本节介绍了视觉语言模型(VLMs),总结了其关键的适应技术,并回顾了基于VLMs的情景生成在安全关键、真实世界以及高级驾驶辅助系统(ADAS)测试应用和图像数据集生成中的应用。此外,还探讨了VLMs如何支持情景分析任务,如视觉问答(VQAs)、场景理解、基准测试和风险评估。++(总结)++
A. VLMs的发展
大规模视觉语言模型的演变:
在2020年,视觉转换器(Vision Transformer,ViT)16 将Transformer架构从自然语言处理(NLP)扩展到计算机视觉,通过将图像分割为固定大小的图块,从而将图像嵌入为一个个标记,并使用标准的转换器编码器处理这些标记序列。这一成功激发了研究人员将视觉和文本模态结合起来,促使了视觉语言模型(VLMs)的发展,这些模型现在能够同时处理图像和文本。一个里程碑事件是CLIP 28 的开发,它通过对数亿对图像--文本对进行对比学习训练,实现了在没有任务特定监督的情况下的有效零样本性能。ALIGN 109 将这一方法扩展到数十亿对噪声网络爬取数据。BLIP 110 将生成描述和检索的多任务统一到单一训练框架中。Flamingo 111 引入了少样本多模态提示,通过冻结骨干网络和交叉注意力层实现快速适应。++(ViT到VLM的发展)++
通过利用视觉语言模型(VLMs)在图像和文本上进行联合推理的能力,研究人员探索了用于自动驾驶任务的新概念。正如近期综述56,57所总结的,VLMs能够构建可解释且可适应的系统,支持开放式交互、提升对未知场景的泛化能力,并促进多模态推理。这些进展标志着向更智能、更可解释的自动驾驶车辆的转变,为更安全、更符合人类需求的驾驶代理奠定了基础。++(VLM对自动驾驶的作用)++
VLM 提供三项核心功能:多模态理解可以联合处理图像和文本,例如图像描述和视觉问答(如 Flamingo、BLIP);图文匹配涉及评估图像与标题之间的语义一致性(如 ALIGN、CLIP);文本生成图像则是根据自然语言提示合成新的视觉内容,由 DALL-E 112 首创。在这些基础上,VLM 可以被应用于支持单独的自动驾驶模块(感知、预测、规划),甚至端到端的视觉-语言-行动(VLA)框架,能够将视觉和语言输入直接映射到驾驶行为。在本次综述中,我们特别关注基于视觉语言模型(VLM)的驾驶场景生成和场景分析,如图5概念性示意所示。++(VLM 提供三项核心功能)++
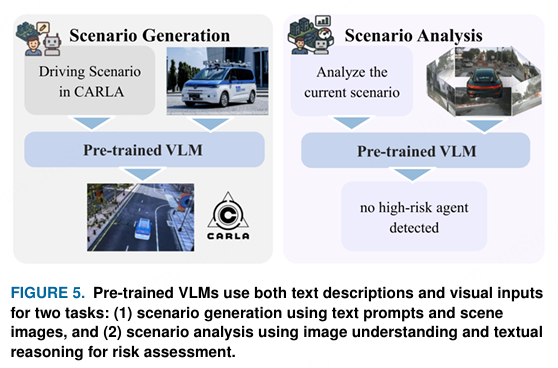
图5. 预训练视觉语言模型(VLMs)同时使用文本描述和视觉输入来完成两项任务:(1)使用文本提示和场景图像进行场景生成;(2)利用图像理解和文本推理进行场景分析,以进行风险评估。
VLM 的适应技术:
当前的紧凑型视觉语言模型(VLMs)使用大型语言模型(LLMs)作为骨干,通过添加文本分词器和视觉编码器来实现。像大型语言模型一样,VLMs 也是预训练的,然后再针对下游任务进行适配。除了 LLMs 的标准提示工程技术外,在自动驾驶(AD)中的场景生成和分析中,通常还会使用以下适配策略。++(VLM的结构和作用)++
模态对齐模块是额外的可训练模块,用于将视觉输入转换为与语言模型兼容的格式。常见的方法包括:
(I) 查询变换器(Q-Former) :一种带有可学习查询的变换器,通过交叉注意力将图像特征与语言模型输入空间对齐(例如,BLIP-2 113)。(II) 交叉注意力 :用于将可变长度的图像或视频标记重新采样为固定大小的潜在表示,从而实现一致的语言交互(例如,Flamingo 111)。(III) 多层感知机(MLP)映射 :通过线性映射或多层感知机将视觉编码器输出投射,以匹配语言模型所需的维度 114,115。(IV) 结构感知编码器 (先验分词器):一种感知结构的模块,将结构化检测输出(如语义属性)编码为下游推理使用的标记嵌入。例如,Reason2Drive 116 引入了一个称为先验分词器的模块,用于融合区域特征与对象级语义。++(四种模态对齐模块)++
微调技术通过在包含视觉和文本输入的指令--响应对的数据集上训练视觉语言模型(VLMs),以提高其执行多模态指令的能力。主要使用两种策略:
(I)FFT:所有模型权重都在目标数据集上进行更新。它通常能够获得最高的任务性能,但会带来较高的计算成本和过拟合风险。多项已回顾的研究在较小的视觉-语言模型上采用了全量微调,以实现在效率和效能之间的实际平衡 114,117。
(II) PEFT:这些方法通过仅更新少量额外参数来实现适配。最常见的方法之一是 LoRA 矩阵,它们被注入到注意力层或前馈层中,以实现高效适配并且参数开销最小65。这一想法的一个扩展是 QLoRA,它通过在适配器训练期间对基础模型应用量化,进一步减少内存使用。++(FFT和PEFT两种微调策略)++
B. 基于VLM的场景生成
本小节回顾了视觉语言模型(VLMs)如何通过利用其对视觉和文本输入的理解来生成驾驶场景。我们将近期的工作分为四类,并在表4中展示:
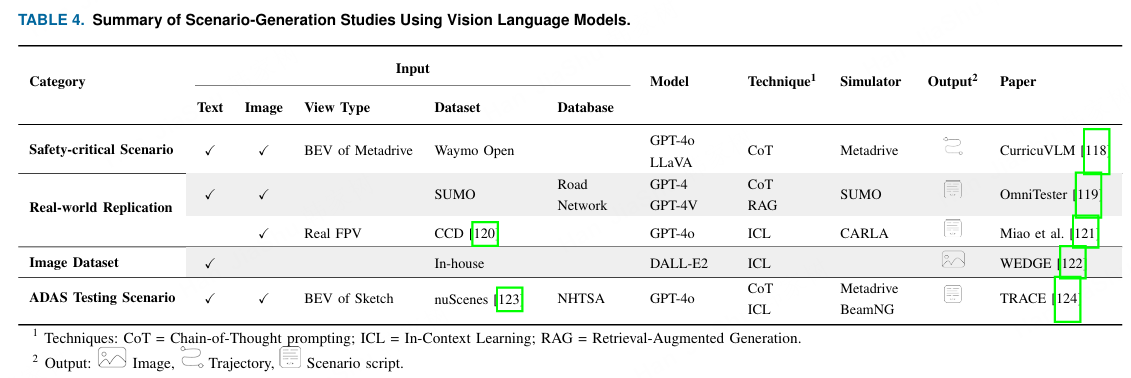
安全关键情景生成:
安全关键场景生成是视觉语言模型在自动驾驶中快速发展的应用。它能够合成罕见但相关的情景,这对于评估系统的鲁棒性至关重要。通过将视觉感知与语义理解相结合,视觉语言模型可以检测故障并生成有针对性且可解释的场景。++(安全关键场景)++
最近的框架如 CurricuVLM 118 展示了 VLM 的潜力。CurricuVLM 将 VLM(如 LLaVA)整合到在线课程学习循环中。VLM 分析鸟瞰图(BEV)图像和任务描述以检测安全关键事件,而 GPT-4o 则进行批量模式分析以揭示行为弱点。这些洞见指导一个预训练的 DenseTNT 模型生成定制的智能体轨迹,强化学习则自适应地选择下一个场景。++(几个例子)++
然而,CurricuVLM 使用了预训练的 VLM,因此其在识别安全关键代理方面的性能有限。未来的工作可以探索将这些框架与具备安全意识、经过微调的 VLM 结合,并引入时间和多传感器的上下文,以提高可靠性。++(局限和未来)++
真实场景复现:
VLMs 通过将语言理解与视觉模态(如情景图像)结合,为现实驾驶场景的复制提供了新的机会,从而能够基于真实世界的记录数据集或地图创建逼真的交通场景。++(场景复现)++
OmniTester 119 提出了一种结合大型语言模型(LLM)和视觉语言模型(VLM)的框架,用于在 SUMO 中创建真实且多样的交通场景。用户输入和来自 RAG 的上下文信息(结合外部知识和 OSM 地图库)通过 GPT-4 处理,以生成 SUMO 场景脚本。GPT-4V 使用图像和代码分析生成的场景,并以自然语言提供反馈。随后,GPT-4 评估器将此反馈与预期描述进行比较,以改进场景生成。除了现实世界地图之外,121 的作者还提出了一个完全自动化的流程,将来自 Car Crash Dataset (CCD) 120 的行车记录仪碰撞视频样本帧转换为用于 ADAS 测试的仿真场景。系统使用带有 ICL 的 GPT-4o 生成 CARLA 的 SCENIC 脚本,而第二个 GPT-4o 则根据预定义的行为特征比较真实与模拟视频帧,通过视觉反馈实现迭代优化。++(几个例子)++
目前使用地图和录像的视频的方法缺乏对现实世界日志重放的使用,而后者有望增强真实感。
数据集生成:
VLM 的一个重要应用是文本到图像的生成,用于构建定制的驾驶数据集,特别是为了在各种条件下提升感知系统的性能。
WEDGE 122 展示了使用视觉语言模型(VLM),特别是 DALL-E 2,合成描绘 16 种与自动驾驶相关的多样化极端天气条件的图像。他们的数据集包括手动标注的二维边界框,用于微调目标检测器。在真实世界的数据集上评估时,在 WEDGE 上训练的目标检测器表现出更好的检测性能,突显了 VLM 生成数据在提升恶劣条件下感知鲁棒性方面的潜力。++(几个例子)++
目前,结合真实数据和合成数据的混合训练尚未得到充分探索。这种方法非常关键,因为现实世界的数据集通常仅包含极少的安全关键边缘情况,而合成数据则可以控制生成罕见事件,例如碰撞、遮挡,以及异常情况------从而改善长尾覆盖,并在高风险场景下增强模型的鲁棒性。++(问题)++
ADAS 测试场景生成:
VLMs 通过将语言与视觉内容相结合,扩展了 ADAS 场景生成,使复杂驾驶事件的重建在语义上更丰富、在视觉上更真实。这有助于从事故报告或驾驶日志等来源进行逼真的重建,以测试 ADAS 性能。++(场景生成)++
TRACE 124 从非结构化的多模态碰撞报告中重建ADAS测试场景,包括文本摘要和视觉草图。它使用带有ICL和CoT的GPT-4o,从草图中提取道路类型和环境细节。一个基于GPT的语言模型,并结合来自nuScenes 123 的轨迹数据,生成真实的车辆行驶路径。这些组件通过基于规则的编码器转换为与MetaDrive等模拟器兼容的基于DSL的场景,这些场景进一步用于测试多种ADAS算法。++(一个具体的例子)++
TRACE 缺乏在线互动场景编辑功能,用户可以通过绘图或对视频帧进行标注来修改场景,而 VLM 可以动态更新模拟代码。这将实现人机协作控制和更灵活的场景优化。++(反思)++
C. 基于VLM的情景分析
使用VLM进行场景生成的当前进展仍处于初级阶段,但VLM在自动驾驶(AD)中的场景分析方面已经展现出很大的潜力。例子包括NuScenes-QA 130用于视觉问答(VQAs),VLM可以回答基于驾驶场景的自然语言问题以支持场景分析;NuPrompt 161用于语言引导的跟踪和预测;以及Refer-KITTI 162用于多目标引用跟踪任务。然而,这些模型并不被认为是基础模型,因为它们没有使用完全预训练的基础架构。相反,它们是基于LLM骨干组件构建的面向任务的框架。++(迫不及待的举例,更成熟的应用)++
在本节中,我们重点讨论在大规模、多样化图文数据集上预训练的基础视觉语言模型(VLMs),以及它们在跨领域泛化方面的能力。我们考察它们在提高复杂AD场景分析的可迁移性、可解释性和效率方面的潜力。我们围绕四个关键应用领域结构化地展开讨论,并在表5中展示它们的技术和应用。++(内容总结)++
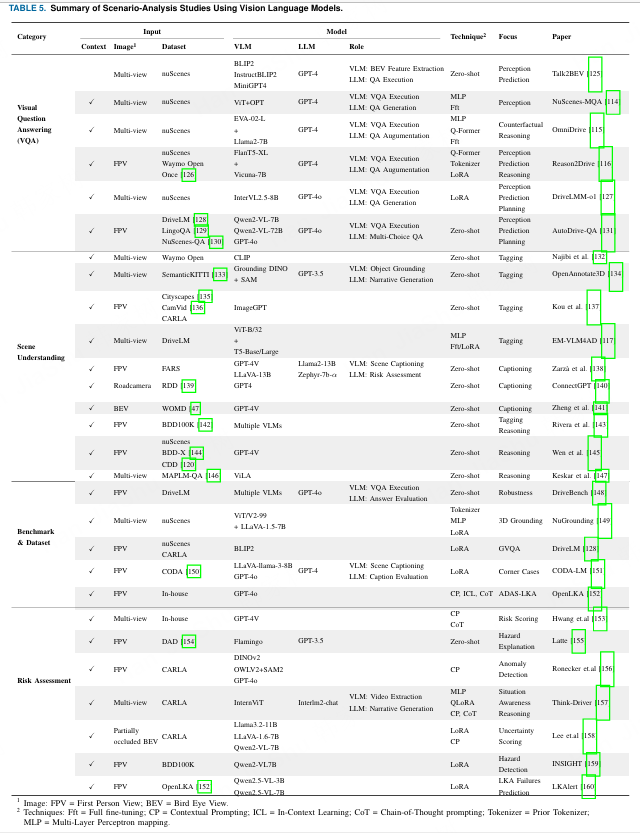
1 图像:FPV=第一人称视角;BEV=鸟瞰视角。 2 技术:Fft=全精调;CP=上下文提示;ICL=上下文学习;CoT=链式思维提示;Tokenizer=先验分词器;MLP=多层感知器映射。
视觉问答(VQA):
用于自动驾驶的 VQA 数据集将视觉输入与自然语言查询配对,以评估跨感知、预测和规划等任务的场景理解能力。虽然近期的研究提出了 VQA 数据集,但一些问答仍然是概念性的或在创建过程中需要人工推理,而其他一些则利用大语言模型(LLM)进行自动生成。本节重点介绍涉及 VLM 执行的基于 VQA 的场景分析方法。++(总起介绍现状)++
早期的工作通过在现有场景表示中加入感知任务来开展。Talk2BEV 125 14 使用感知堆栈通过融合多视角图像和 LiDAR 来生成 BEV 地图,然后应用 BLIP-2 为这些地图增添对象级的语言描述。随后,这些描述被传递给带有链式思维提示的 GPT-4,以回答空间和语义问题,从而实现零样本的视觉问答(VQA),并使用专注于感知和预测的标注问答对。类似地,NuScenes-MQA 114 使用 GPT-4 在 Markup-QA 框架内自动生成多样化的问题模板。作者完全微调了一个结合 CLIP 预训练 ViT 作为视觉编码器和 OPT 作为语言模型的视觉语言模型(VLM),并使用 MLP 将多摄像头视觉特征与文本对齐。该设置能够在驾驶场景中对图像描述生成和视觉问答进行联合评估,以支持感知任务。++(VLM感知的示例)++
后续的研究工作转向了更高级的推理任务。OmniDrive 115 引入了用于自动驾驶反事实推理的第一个 3D VQA 数据集,评估了使用冻结的 EVA-02-L 和 Llama2--7B 主干的 VLM,并使用 MLP 投影器(Omni-L)或 Q-Former(Omni-Q)作为可训练的模态桥梁。Reason2Drive 116 提出了一个视频-文本 VQA 数据集,由 nuScenes、Waymo 和 ONCE 126 的连续图像组成,涵盖感知、预测和推理任务。作者通过使用 LoRA 对由 FlanT5-XL 和 Vicuna-7B 构成的 VLM 进行微调,利用了先前的分词器和指令式视觉解码器。Q-Former 模块被用来联合预测答案和感知线索。++(VLM深度推理的示例)++
基于VQA的场景分析的最新研究主要集中在提升自动驾驶中跨感知、预测和规划任务的多模态推理与评估。DriveLMM-o1 127 引入了一个基于nuScenes的逐步推理数据集,将图像和LiDAR点云都纳入问答上下文中。他们的问答对最初由GPT-4生成,随后通过人工注释进行优化。作者使用LoRA微调InternVL2.5-8B,展示了在感知、预测和规划任务中的推理能力及最终答案准确率提升。AutoDrive-QA 131 使用GPT-4o将DriveLM 128、LingoQA 129 和NuScenes-QA 130 的开放式问答对转换为多项选择题,添加干扰项(即合理但错误的答案选项),以模拟真实的领域特定错误。这形成了一个标准化的基准,用于评估预训练视觉语言模型在感知、预测和规划等关键场景分析任务中的表现。++(VLM的多模态推理与评估)++
尽管取得了这些进展,目前大多数视觉问答(VQA)仍然忽略了交通规则和现实驾驶惯例。未来的工作应结合交通规则感知的问答,基于道路语义(例如,优先通行规则和道路信号遵守),以实现更现实且与安全相关的情景推理。++(仍存在问题)++
场景理解:
VLMs 被广泛用于解释复杂的驾驶场景。最近的研究工作利用 VLMs 进行场景标注,这代表了最基本的场景理解水平,涉及二元或类别分配。场景标注在场景级别(例如,用于分析天气状况)或像素级别(语义分割)分配预定义标签,以表征视觉内容以用于下游任务。Najibi 等人 132 利用预训练的 CLIP 对摄像机图像进行零-shot 场景标注,将语义标签投射到 LiDAR 点上。这些标签指导生成 3D 伪标签,然后用于训练无需人工标注的 3D 目标检测器。OpenAnnotate3D 134 引入了一种用于多模态 3D 数据的自动标注系统,使用 GPT-3.5 解析自然语言场景描述,并使用带有 Grounding DINO 和 SAM 的 VLM 生成密集 2D 掩码,随后将其在时空上融合并投影为 3D 注释。Kou 等人 137 提出了一种增强 VLM 对街景语义理解的框架。他们使用预训练的 ImageGPT 从第一视角(FPV)图像中提取语义特征,并训练一个轻量感知头,将语义特征映射到像素级语义分割掩码。EM-VLM4AD 117 提出了一种轻量级 VLM,在 DriveLM 128 数据集上训练,主要用于场景标注。它使用 ViT 图像编码器,并探索两种适配策略:T5-base 的全量微调以及基于 LoRA 的 T5-large 微调。该模型在参数数量、浮点运算次数(FLOPs)和内存使用方面与基线模型进行基准测试,展示了在资源受限环境中部署的高效性。++(VLM被使用在复杂交通场景理解中)++
在场景标注的基础上,近期的研究工作已经向中级任务------场景描述(scene captioning)发展,该任务通过生成开放形式的描述,将感知与语言连接起来。场景描述生成对可见元素的简明自然语言描述。Zarzà 等人 138 提出了一个使用结构化输入和主成分分析的框架,并采用 Llama2-13B 搭配 CoT 和 CP 来评估场景中的风险,从而提出驾驶调整建议。他们使用 FARS 数据集进行框架测试。此外,他们利用视觉语言模型(VLM),具体为带 CP 的 LLaVA-13B,来进行基于图像的场景描述,通过自然语言描述增强对场景的理解。ConnectGPT 140 利用 VLM 为车联自动驾驶车辆生成标准化的合作智能交通系统信息。具体来说,他们在 RDD(道路损坏数据集) 139 上评估 GPT-4,以执行如事件检测和车道状态描述的场景标注和描述任务。Zheng 等人 141 提出了一种使用 VLM 的上下文感知运动预测框架。他们使用 GPT-4V 从交通上下文地图中提取交通上下文,结合矢量地图数据和历史轨迹,将生成的场景描述输入运动变换器,从而改进轨迹预测。++(VLM被使用再交通场景的描述中)这跟前面的区别是??++
一些研究涉及场景理解的最先进形式:场景推理,这需要解释交互、因果关系和抽象的情境背景。场景推理在生成连贯叙述的同时,解释代理之间的关系和互动,这些叙述捕捉了意图、因果关系和情境背景。Rivera 等人 143 提出了一种可扩展的交通场景分类流程,使用现成的视觉语言模型(VLMs),如 GPT-4V、LLaVA 和 CogAgent-VQA 163。这些模型在零样本情况下评估,用于推理预定义的场景元素,如车道标线和车辆动作,使用自建数据集和 BDD100K 142 数据集。Wen 等人 145 探索了 GPT-4V 从行车记录仪视频进行道路场景解释的零样本能力,对模型在目标检测、场景描述、视觉问答(VQA)和因果推理方面进行评估,同时强调其在自动驾驶中的潜力和局限性。Keskar 等人 147 在 MAPLM-QA 146 基准上评估了 NVIDIA 的 ViLA 在交通场景理解中的表现。通过上下文提示,他们对 ViLA 进行了多项选择 VQA 任务的评估,包括车道计数、路口检测、场景分类和点云质量评估。ViLA 在高级 VQA 任务中表现出强大的性能,但在细粒度空间推理方面存在困难。++(VLM最新的研究成果,场景推理)++
基准与数据集:
为了支持自动驾驶中视觉语言模型(VLM)的开发和评估,近期的研究工作引入了专门的基准测试和精心策划的数据集,涵盖了感知、预测、规划和情境推理等关键任务,并考虑了真实世界和安全关键的条件。++(数据集)++
为了实现标准化评估,几项工作提出了与多种驾驶场景相对应的基准。DriveBench 148 提出了一个用于评估多任务驾驶场景推理的基准。它扩展了 DriveLM 128 的 VQA 数据集,并添加了各种视觉损坏类别,以评估模型的鲁棒性。利用该基准,作者评估了一系列预训练和微调的视觉语言模型(如 GPT-4o、Qwen2-VL、Dolphins)在干净、损坏和仅文本条件下的鲁棒性。GPT-4o 还被用作开放式答案的自动评估器。nuGrounding 149 提出首个基于 nuScenes 的 3D 视觉定位基准,并进行了人工标注的目标定位。作者使用 LoRA 对 LLaVA-1.5 进行微调,并选用 ViT 或 V2-99 作为视觉编码器。为了引入 3D 理解,他们通过基于 BEV 的检测器提取 BEV 特征,将其映射到 LLM 适配器中,并通过查询融合器与 VLM 输出融合,以实现准确的目标检测和定位。++(几个数据集基准的例子)++
为了补充这些基准测试,其他研究工作提供了高质量的数据集,用于训练和适应 VLMs 以应对复杂的驾驶环境。DriveLM 128 引入了一种图结构视觉问答(GVQA),利用基于图的场景表示来回答自动驾驶场景中的结构化感知、预测和规划问题,使用了人工策划的 QA VOLUME、来自 nuScenes 的 OJ Logo 图,以及来自 CARLA 的基于规则的标注。基于 BLIP-2 的 VLM 通过 LoRA 微调,并由基于图的问答提示引导,使其能够在感知、预测和规划中进行零样本可解释的场景推理。CODA-LM 151 引入了一个源自 CODA 数据集 150 的角落案例图文数据集。作者使用 GPT-4V 为每张图像生成跨感知、预测和规划的多任务描述。这些描述随后通过 GPT-4 进行评估和优化。在构建数据集之后,他们微调了 LLaVA-llama-3-8B 模型,以增强角落案例驾驶场景中的视觉语言理解能力。OpenLKA 152 引入了一个大规模真实世界的车道保持辅助数据集,涵盖多种驾驶条件。GPT-4o 与 CP、CoT 和 ICL 结合使用,用于生成描述车道质量、天气和交通环境的结构化场景标注。++(又几个例子)++
然而,现有的基准测试和数据集仍然缺乏现实性和多样性。例如,DriveBench 暴露了 VLM 对干扰的脆弱性,这表明需要更真实的扰动(例如遮挡、夜间情况)。CODA-LM 依赖于过滤后的 GPT 描述,这突显了在现实边缘情况覆盖上的差距。++(现有问题)++
风险评估:
VLM 正越来越多地应用于自动驾驶风险评估,处理诸如危险检测、不确定性评估和故障预测等任务。近期的方法结合了提示(prompting)和微调(fine-tuning),并使用多种视觉输入,包括鸟瞰图(BEV)地图、多视角图像以及分割掩码。这些方法旨在通过可解释的推理和上下文感知的决策支持来提升安全性。++(VLM可用于风险评估)++
最近的进展探索了用于风险分析的提示技术。Hwang 等人 153 在街道过马路场景中,利用 GPT-4V 在零样本设置下进行风险评分。模型接收结构化的视觉输入,包括边界框、分割掩码和光流,同时结合使用 CoT 制定的上下文提示。GPT-4V 并非直接处理原始图像,而是在增强的视觉特征上进行推理,以评估安全等级并提供自然语言的理由。类似地,LATTE 155 提出了一个实时危险检测框架,该框架利用现成的计算机视觉模块和三个用于空间推理、时间建模及风险预测的轻量级注意力模块。在检测到危险时,会触发 Flamingo 和 GPT-3.5 来生成场景描述和口头解释。该系统通过利用上下文提示进行情境推理,以零样本方式运行。对于异常物体检测,Ronecker 等人 156 提出了基于补丁和基于实例的嵌入方法,采用视觉基础模型,并在基于 CARLA 的数据集上进行评估。他们利用 DINOv2 的零样本视觉嵌入能力,并将 OWLv2 与 SAM2 结合用于对象级实例分割。他们的基于实例的方法在结果上稍微优于使用上下文提示的 GPT-4o。++(VLM用于风险评估的提示技术)++
Think-Driver 157 提出了一种使用多视角图像来评估感知交通状况并评估当前驾驶操作风险的 VLM。它采用多视角 RGB 输入和自车状态数据,分别由 InternViT 和 InterLM2-chat 处理。该模型通过量化低秩适配(QLoRA)进行微调,并在覆盖场景理解、危险推理和动作预测的 CoT 风格问答数据上训练。在考虑遮挡感知 BEV 表示的情况下,Lee 等人 158 首先研究了 VLM 在自动驾驶中用于不确定性预测的应用。他们使用 CARLA 构建了一个数据集,包含带遮挡掩码的 BEV 图像,并配有驾驶操作和不确定性评分。三个 VLM 使用 LoRA 微调,以比较它们在遮挡条件下的性能。为了进行危险检测和解释,INSIGHT 159 通过 LoRA 对 Qwen2-VL-7B 进行微调。利用 BDD100K 图像中标注的危险位置,模型被训练来定位高风险区域并生成自然语言描述。在空间定位和可解释性任务中,它优于多个预训练 VLM。最后,LKAlert 160 开发了一个基于 VLM 的车道保持辅助失效预测框架。它集成了 RGB 行车记录仪图像、CAN 总线信号以及来自 LaneNet 的车道分割掩码。通过 LoRA 微调 Qwen2.5-VL 模型,以车道掩码作为空间引导。该模型输出二元警报和可解释的说明,以增强安全透明性。++(几个案例,感觉这里没什么逻辑)++
为了实现现实世界的部署,需要通过模型压缩、高效提示以及针对自动驾驶车辆板载执行优化的轻量级VLM架构,进一步降低推理延迟和资源需求。++(要求)++
D. 局限性与未来方向
基于VLM的场景生成:
与基于大型语言模型(LLM)的场景生成(B节)相比,视觉语言模型(VLM)在用于训练驾驶策略的场景合成和闭环场景生成等领域仍然探索不足。凭借处理视觉和文本输入的能力,VLM为现有框架提供了强有力的扩展。一个有前景的方向是将其用作辅助分析模块,以提高生成场景的可解释性和真实度,同时提供反馈信号以迭代地提升场景质量。++(探索不足,一个前景方向)++
此外,开发更复杂、跨学科的流程以充分利用VLM的多模态推理能力具有很大的潜力。例如,在基于场景的测试中,VLM可以解读真实世界的交通视频,并生成详细的场景描述。这些描述可以作为结构化条件,让DM重新生成逼真的驾驶场景或视频。这样一个多阶段流程,将感知、语义理解和模拟联系起来,代表了构建整体性且可扩展的场景生成系统的一个有前景的方向。++(其他的潜力,与DM协作)++
基于VLM的情景分析:
在场景分析领域,VLM在某些方面优于仅基于文本的LLM框架。目前的研究遵循两大主要趋势。
第一个趋势集中在开发任务特定的框架,这些框架通常会配合外部计算机视觉模块(例如用于三维定位或危险检测)。与此同时,通用预训练视觉-语言模型的快速发展提出了一个关键的研究问题:这些模型在多大程度上能够在不依赖外部工具(如目标检测器、深度估计器或三维定位器)的情况下,进行有效的场景分析?研究这类端到端视觉-语言模型的能力和局限性,可能有助于开发更简化、可扩展的解决方案,从而在降低系统复杂性的同时,保持甚至提升其分析性能。++(配合外部计算机视觉模块,这不是废话吗????)++
另一个趋势强调视觉问答(VQA),设计量身定制的VQA任务,以微调视觉语言模型(VLMs),从而提升面向任务的性能。尽管最近取得了一些进展,但仍存在若干挑战。虽然大规模预训练的VLM显示出强大的潜力,但自动驾驶中的场景分析流程仍然高度复杂且缺乏标准化。具体而言,缺乏基准数据集、VQA任务的一致标注框架以及针对场景分析的统一评估指标。解决这些问题对于开发能够应对真实自动驾驶场景的、更稳健且针对特定任务的VLM至关重要。++(强调视觉问答(VQA))++
**分析:**该文章极有可能是团队使用AI论文工具生成的,部分地方牵强附会,逻辑不清晰,但是结构非常完整,内容非常多,具体如何我们后面继续看!