欢迎回到我们的 《零基础:100个小案例玩转Python软件开发!》 系列!在前面我们已经学了六节课,大家是否对PyMe开发软件有一定了解和掌握了呢?
在本节课,我将教大家如何利用PyMe 1.5.6.1 版本最新集成的图像训练与识别组件功能来对游戏中的角色进行识别,相信有些小伙伴学会后,打游戏可就....哈哈哈。
图像识别基本原理
要想对游戏图像上的NPC进行识别,首先需要对这些NPC的图像进行训练,提取图像特征生成模型。一般来说,训练的图片越多,特征提取的准确度越高,使用生成模型做识别的成功率也越高。
有了模型后,使用这个模型作为识别的依据,就可以对目标图像进行识别啦!
这就是基本原理,下面我们来实际操作一下。
第一步:图像训练
我们先在PyMe中创建一个空工程NPCRecognition,然后我们准备以下素材,包括三个类型的小怪物图片:

我们将要识别的图片按物体分类放置到Resources文件夹下,放置好如下:
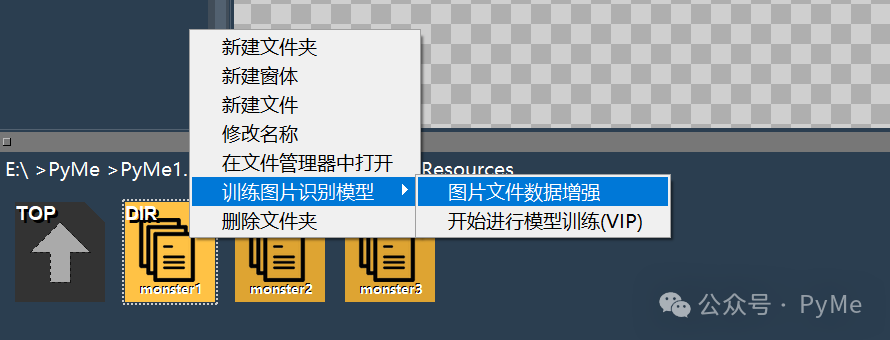
在工程的资源文件夹打开Resources文件夹后,我们对每个文件夹用右键单击,在弹出菜单里选择"训练图片识别模型"->"图片文件数据增强"。
进行数据增强后, 每个怪物的文件夹下会多出许多新的图片。
monster1文件夹:

monster2文件夹:
monster3文件夹:
有了更多的训练图素后,我们下面再为每个文件夹进行训练。
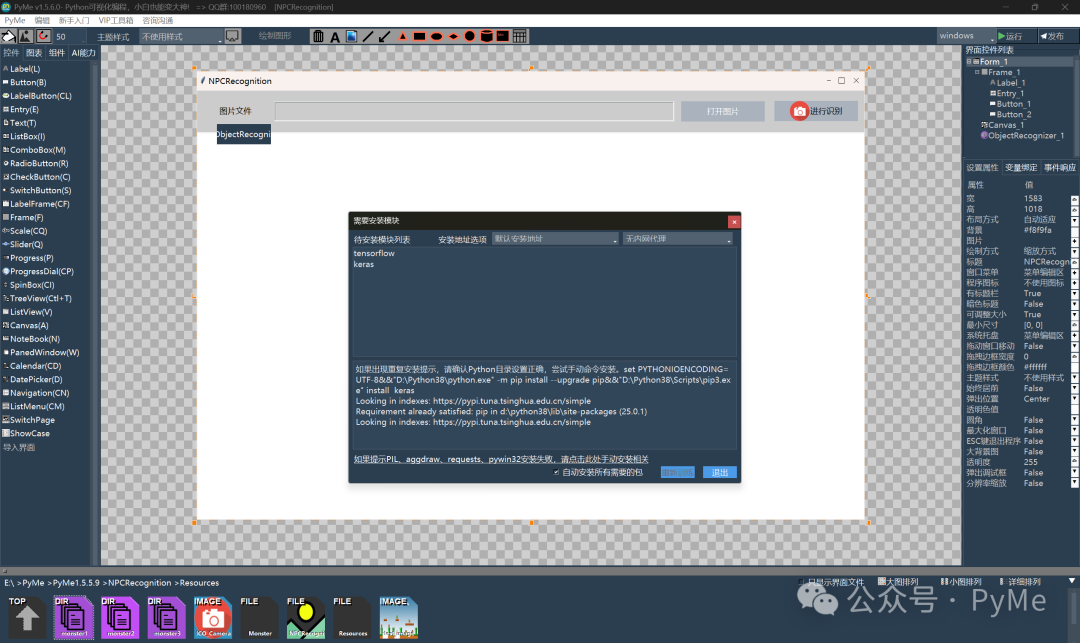
训练需要安装tensorflow和keras等机器学习相关框架支持,如果咱们电脑上尚未安装,会直接弹出,点击"安装"即可。
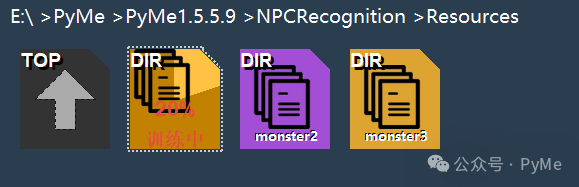
训练过程会有进度显示,训练完成后,文件夹图片会变成紫色,代表是有训练模型的图片文件夹。
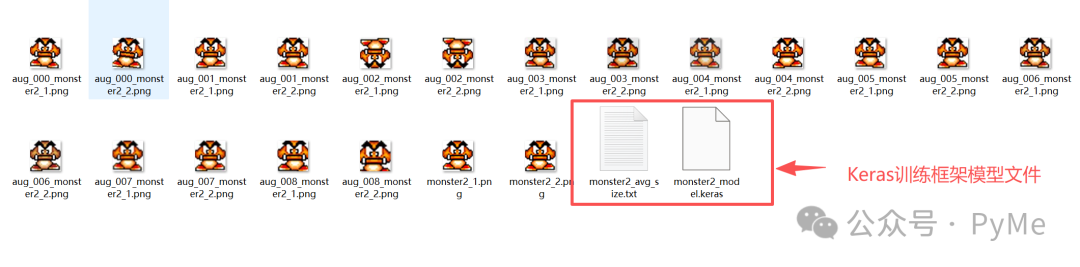
PyMe目前使用Keras训练,训练的模型包括了一个模型文件和一个大小信息文件。
有了这些模型,下面我们就可以用来识别啦~
第二步:界面设计
我们在PyMe中创建一个界面,能够打开一个图片并显示画布和识别结果。
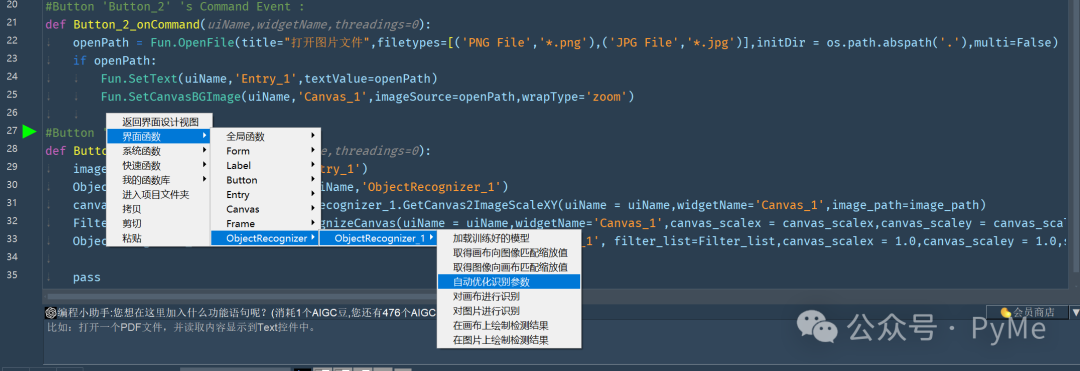
首先我们将Form_1的布局方式设置为"自动适应",在Form_1上放置一个Frame,布局方式也设为"自动适应",居上停靠,横向填充,高度设为100.然后从工具条拖动文本框Label,输入框Entry和两个按钮到Frame中,这里Button_1是"进行识别",Button_2是"打开图片"。
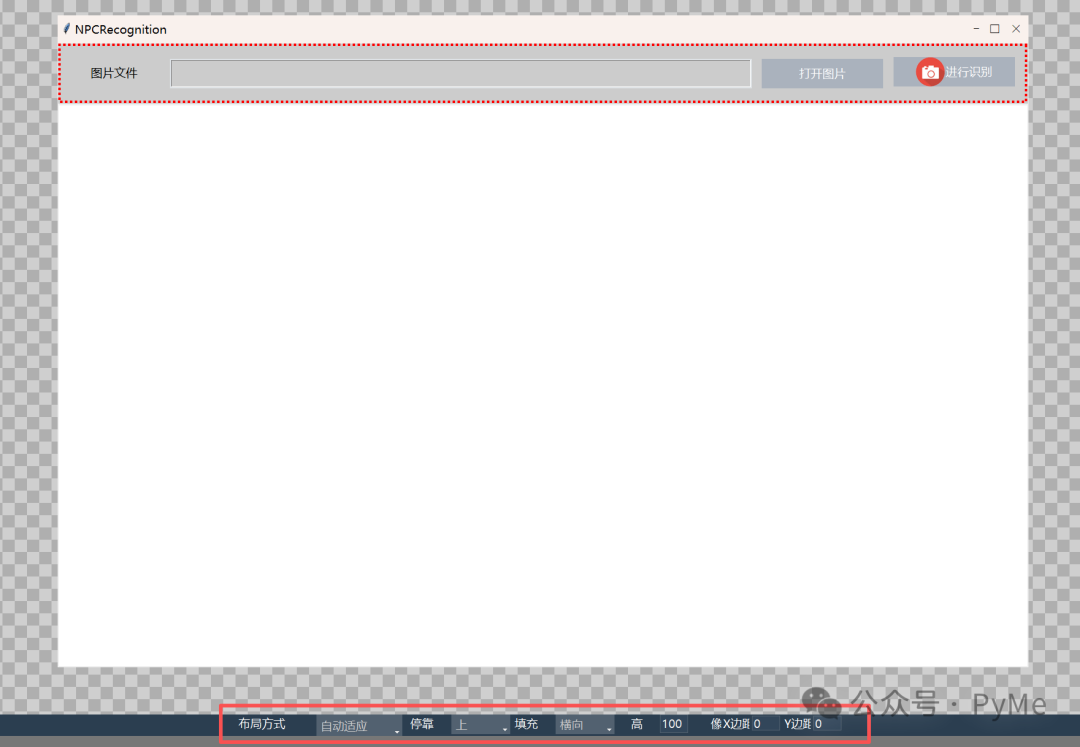
在下方再放置一个画布Canvas控件,布局方式同样设置为"自动适应",居下停靠,向四周填充以充满余下空间。在完成控件摆放后,从左边工具条里的"组件"页中拖动一个ObjectRecognizer到Form_1上,最终效果如下所示:
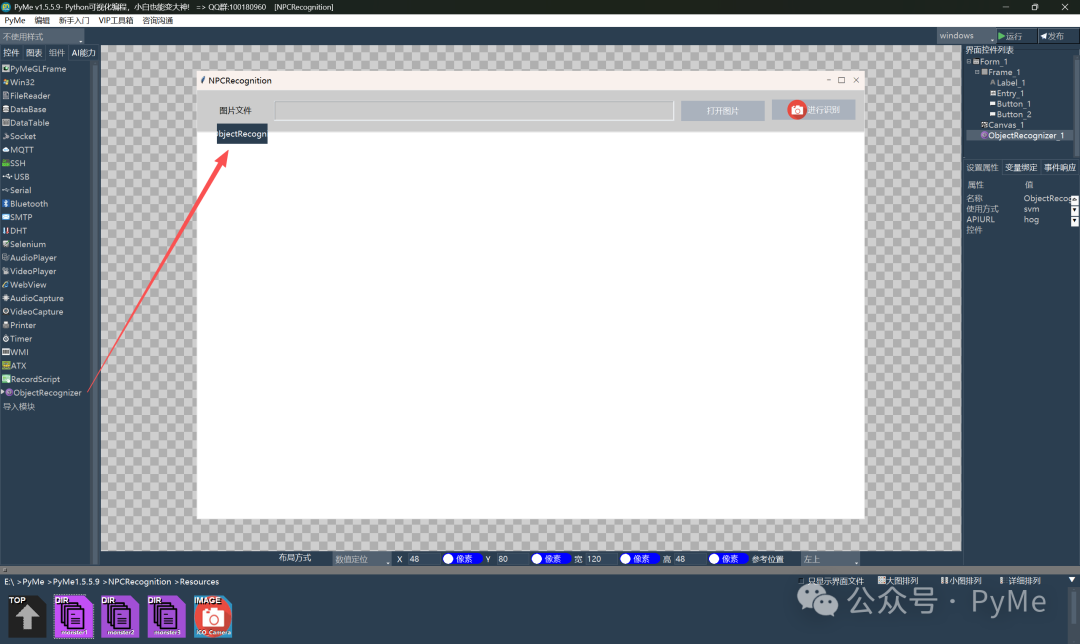
第三步:编写逻辑
双击"打开图片"按钮(Button_2),PyMe会为按钮的点击事件绑定函数,在当前按钮的绑定函数中用鼠标右键单击,在弹出菜单中选择"系统函数"=>"调用打开文件框"。
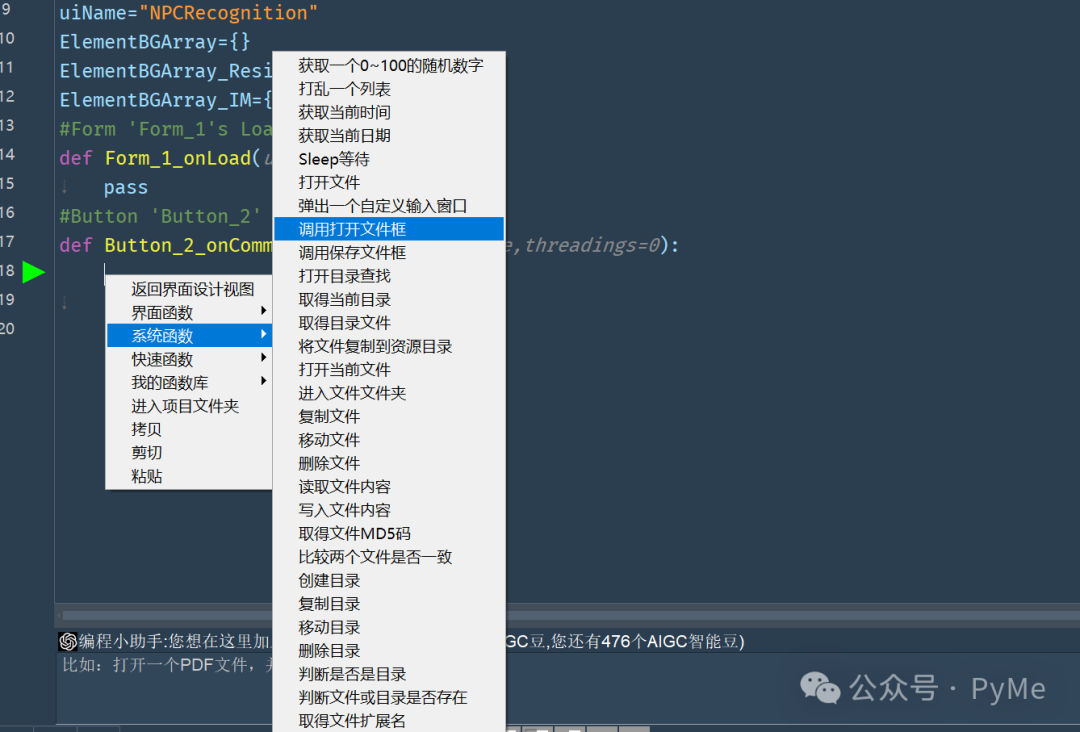
在生成的打开文件代码中将Python文件改为图片文件,这样就可以打开图片文件了,判断一下是否有效,如果有效设置到输入框中显示,并将图像显示到画布上:
python
openPath = Fun.OpenFile(title="打开图片文件",filetypes=[('PNG File','*.png'),('JPG File','*.jpg')],initDir = os.path.abspath('.'),multi=False)
if openPath:
Fun.SetText(uiName,'Entry_1',textValue=openPath)
Fun.SetCanvasBGImage(uiName,'Canvas_1',imageSource=openPath,wrapType='zoom')完成第一个按钮后,在右上角选择"进行识别"按钮(Button_1),然后在中间"控件事件类型列表"选择"按钮点击"事件,点击"绑定函数"按钮,即可在代码区生成对应的函数。
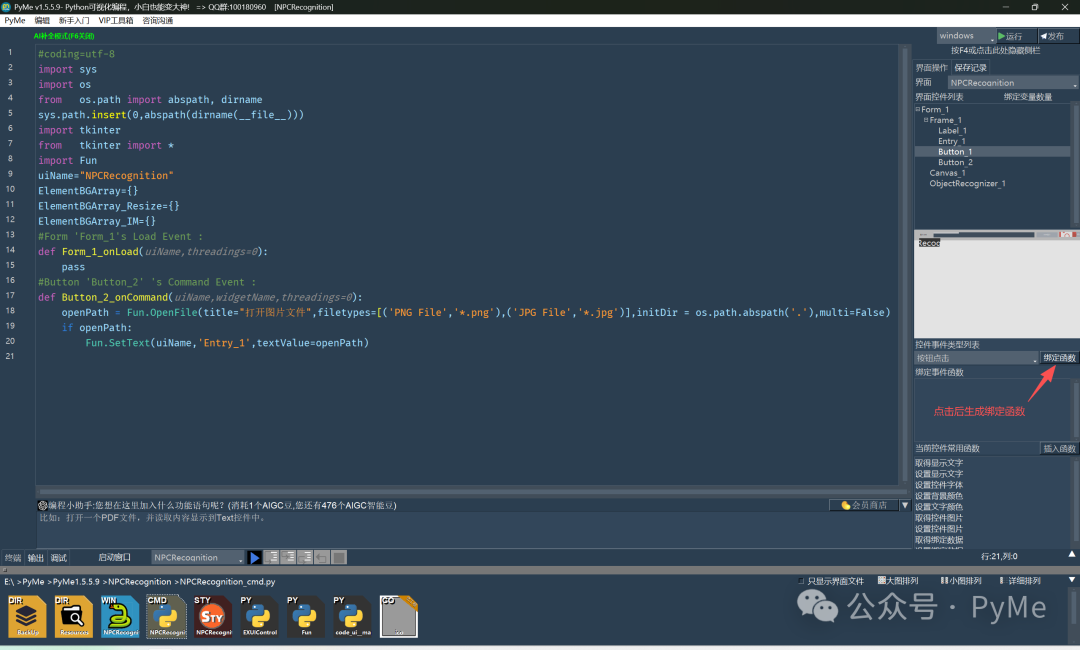
有了函数后,我们可以首先在Form_1的onLoad事件函数中,用鼠标右键单击,通过弹出菜单下的"界面函数"菜单项,找到ObjectRecognizer_1,选择"加载训练好的模型",这样就会生成对应的代码,让我们在界面初始化时就加载对应的模型。
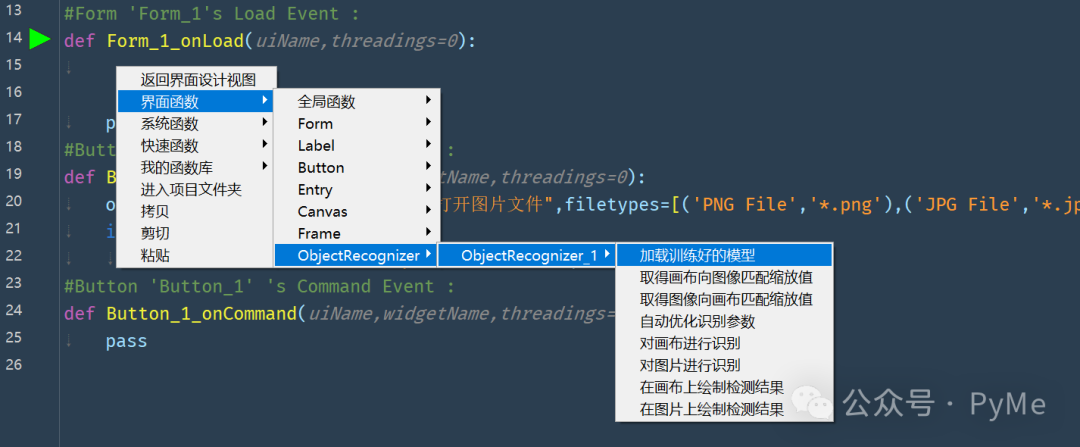
我们填写model_path为monster1,并多复制两行,加载monster2,monster3的模型,具体代码实现为:
python
def Form_1_onLoad(uiName,threadings=0):
ObjectRecognizer_1=Fun.GetElement(uiName,'ObjectRecognizer_1')
ObjectRecognizer_1.LoadModel(model_path='monster1')
ObjectRecognizer_1.LoadModel(model_path='monster2')
ObjectRecognizer_1.LoadModel(model_path='monster3')下面进入到"进行识别"按钮的点击事件函数中,通过鼠标右键选择OjbectRecognizer_1的"取得画布向图像匹配缩放值",通过生成这个函数,取得画布大小向图片大小的缩放倍数。
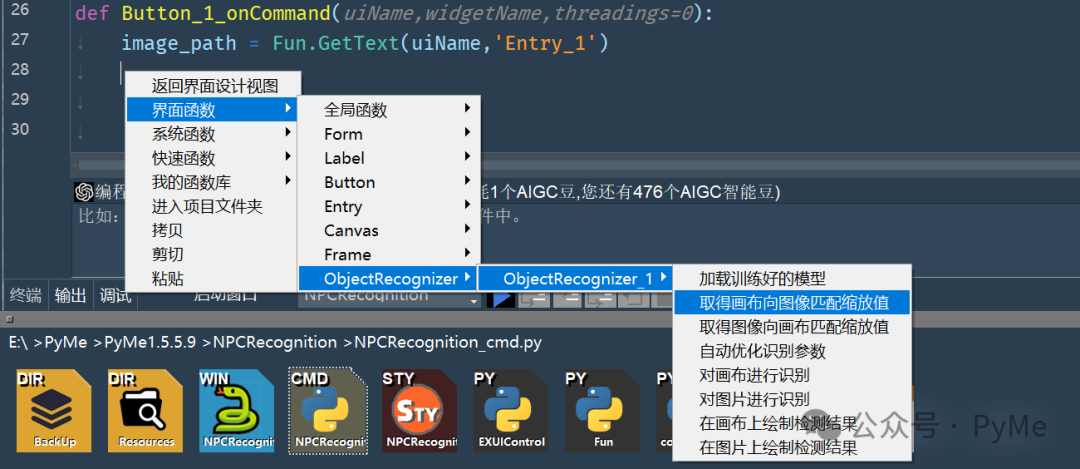
在生成代码后,需要在函数调用前取得目标图片文件作为参数填入函数中,具体逻辑代码如下:
python
#Button 'Button_1' 's Command Event :
def Button_1_onCommand(uiName,widgetName,threadings=0):
image_path = Fun.GetText(uiName,'Entry_1')
ObjectRecognizer_1=Fun.GetElement(uiName,'ObjectRecognizer_1')
canvas_scalex,canvas_scaley=ObjectRecognizer_1.GetCanvas2ImageScaleXY(uiName = uiName,widgetName='Canvas_1',image_path=image_path)因为图片与画布的尺寸不同,而画布显示图片时默认使用缩放处理将图片匹配画布大小,为了更准确的进行识别,所以在识别组件中有两个缩放值函数的获取,如果是获取画布大小向图片大小缩放值,就用GetCanvas2ImageScaleXY函数,如果是获取当前图片大小向画布大小缩放值,就是用这个GetImage2CanvasScaleXY函数,在图像识别OjbectRecognizer_1组件中,即可以对图片进行识别,也可以直接对画布进行识别。因为当前案例对Canvas_1进行识别,所以下面要调用识别画布函数时,需要传入canvas_scalex,canvas_scaley。
python
Filter_list=ObjectRecognizer_1.RecognizeCanvas(uiName = uiName,widgetName='Canvas_1',canvas_scalex = canvas_scalex,canvas_scaley = canvas_scaley, show_result=False, save_result=False, result_path=None, conf_threshold=0.05, use_template_matching=True, area_ratio_threshold=0.3, fast_mode=False)在获取识别结果后,我们需要将识别结果显示到画布上,这时可以用鼠标右键,在弹出菜单里选择识别组件OjbectRecognizer_1的"在画布上绘制检索结果"。
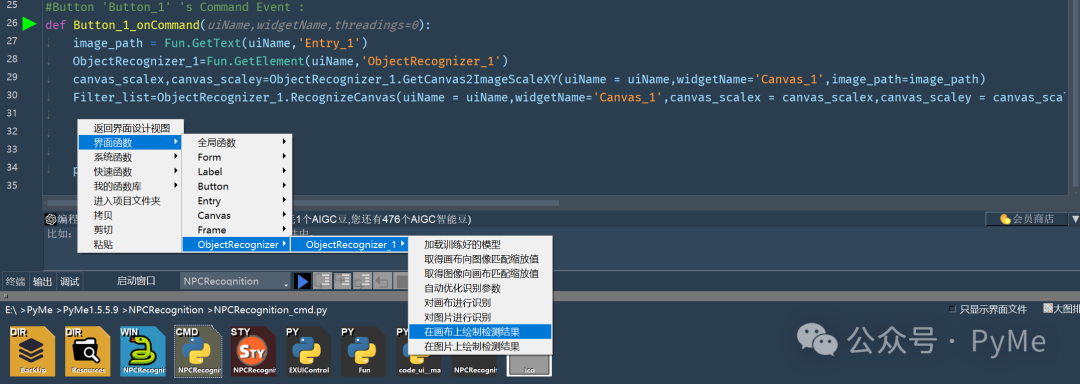
python
ObjectRecognizer_1.DrawResultToCanvas(uiName = uiName,widgetName='Canvas_1', filter_list=Filter_list,canvas_scalex = 1.0,canvas_scaley = 1.0,save_image_path='')这里因为识别的画布得出的结果是基于画布的,所以不用再做缩放处理,最终代码如下:
python
#Button 'Button_1' 's Command Event :
def Button_1_onCommand(uiName,widgetName,threadings=0):
image_path = Fun.GetText(uiName,'Entry_1')
ObjectRecognizer_1=Fun.GetElement(uiName,'ObjectRecognizer_1')
canvas_scalex,canvas_scaley=ObjectRecognizer_1.GetCanvas2ImageScaleXY(uiName = uiName,widgetName='Canvas_1',image_path=image_path)
Filter_list=ObjectRecognizer_1.RecognizeCanvas(uiName = uiName,widgetName='Canvas_1',canvas_scalex = canvas_scalex,canvas_scaley = canvas_scaley, show_result=False, save_result=False, result_path=None, conf_threshold=0.05, use_template_matching=True, area_ratio_threshold=0.3, fast_mode=False)
ObjectRecognizer_1.DrawResultToCanvas(uiName = uiName,widgetName='Canvas_1', filter_list=Filter_list,canvas_scalex = 1.0,canvas_scaley = 1.0,save_image_path='')如果想要保存出一个图片文件,可以为save_image_path设置一个文件名,识别时就会将识别后的结果保存为图片。
第四步:测试结果
现在我们的基本工作已经完成,找一张游戏画面图片来识别一下:

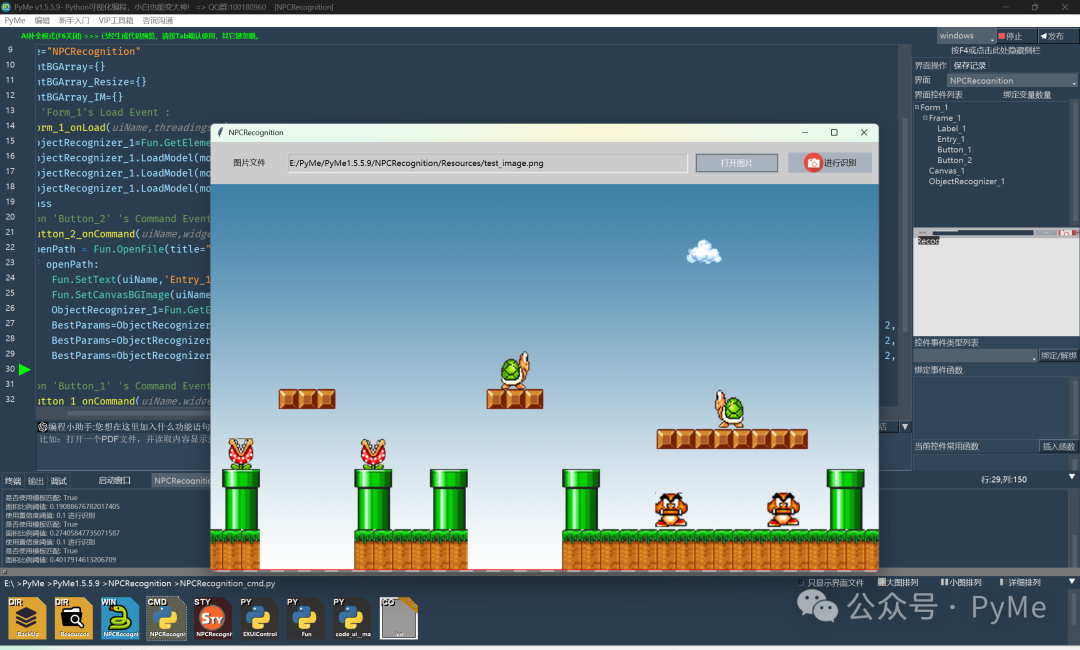
我们希望在这张图上识别出这些小怪物,运行程序后,点击"打开图片"按钮,将图片加载并显示到画布上,再点击"进行识别"。
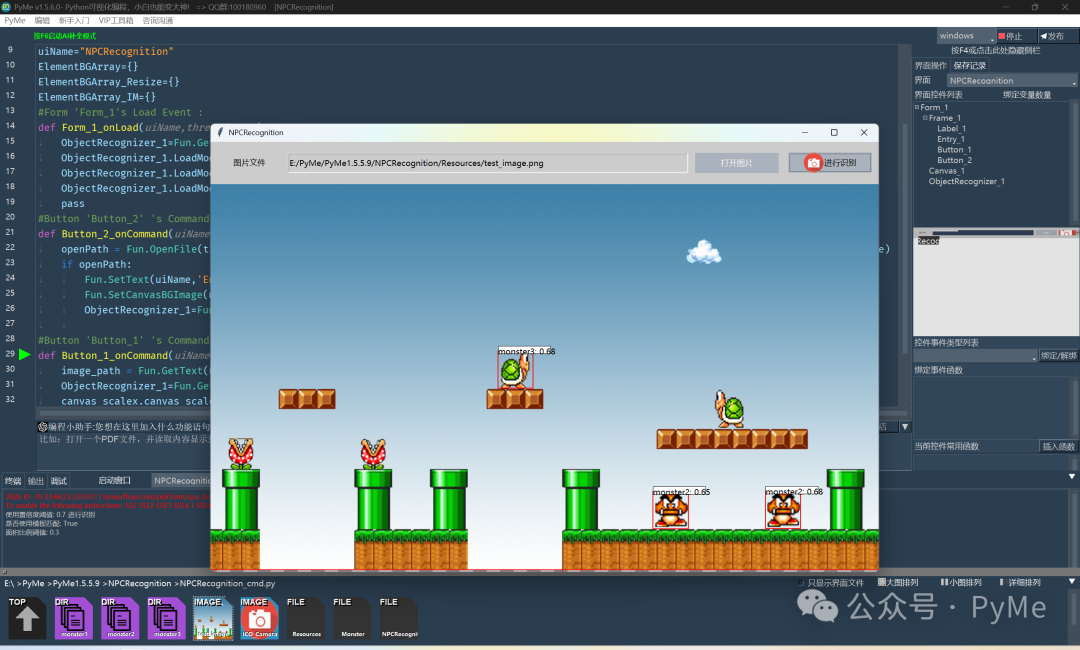
可以看到,已经能识别到一些小怪物啦!但还有一些小怪物识别不成功,这个准确度就需要我们来增强训练数据的同时,对有些阈值参数(置信度、面积)进行优化,下面我们可以对这些参数进行自动优化,我们在点击"打开图片"按钮的函数中,追加"自动优化识别参数"。
这个"自动优化识别参数"可以让图像识别组件根据图像上的目标数来自动调整和优化参数。在这里我们将model_index分别填0,1,2,因为每个小怪物的数量都是2,所以target_count都填2.
python
BestParams=ObjectRecognizer_1.OptimizeRecognition(image_path=openPath,image_scalex = 1.0,image_scaley = 1.0, model_index = 0, target_count = 2, save_to_model = True)
BestParams=ObjectRecognizer_1.OptimizeRecognition(image_path=openPath,image_scalex = 1.0,image_scaley = 1.0, model_index = 1, target_count = 2, save_to_model = True)
BestParams=ObjectRecognizer_1.OptimizeRecognition(image_path=openPath,image_scalex = 1.0,image_scaley = 1.0, model_index = 2, target_count = 2, save_to_model = True)再次运行时,在加载完目标大图后,会对每个模型基于数量来进行参数优化,最后将优化后的模型信息保存。
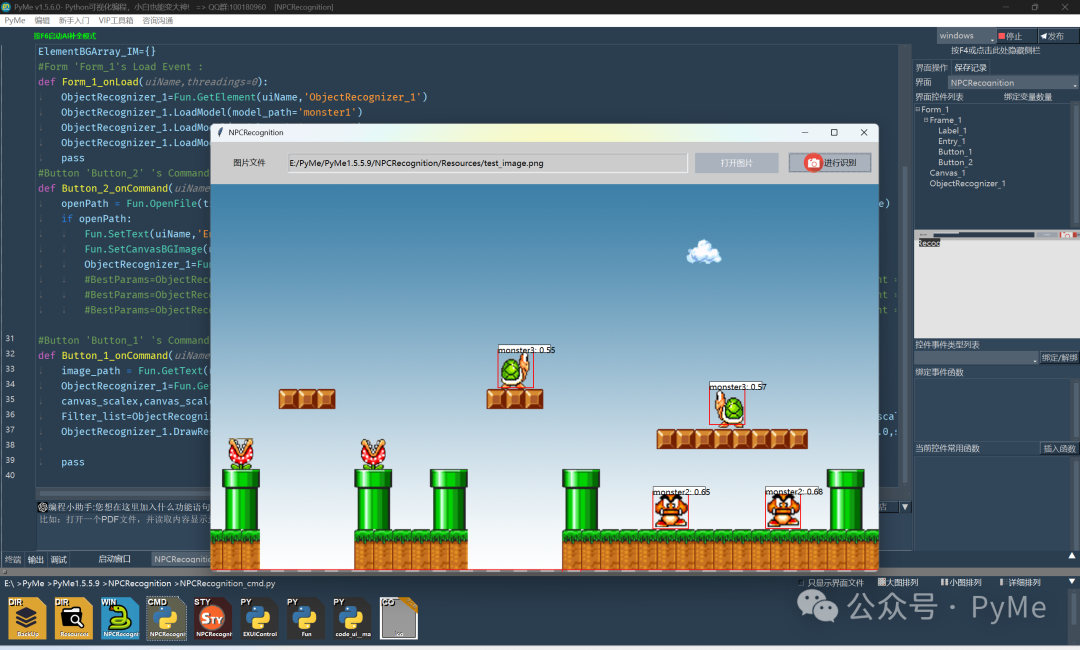
等优化完成后,再次点击"运行识别"按钮,可以看到小乌龟就都识别出来了,不过花怪还没有识别出来,说明有一些训练还是不够,后续可通过增加素材训练和优化参数来增强识别成功率。
OK,你学会了么?