前面我们介绍的主从复制 + 哨兵解决了 Redis 的 "高可用"(主节点宕机自动切换)和 "读负载分担",但有两个致命缺陷:
存储容量有限:所有节点都存全量数据,单台机器内存撑不住海量数据(比如 1TB 热数据);
写负载集中:所有写操作都落在主节点,单主节点扛不住高并发写请求。
而 Redis 集群(Redis Cluster)的核心作用,就是在高可用基础上,实现 "分布式存储" 和 "写负载分担"------ 把数据拆分到多个主节点,每个主节点负责一部分数据,既扩容了存储容量,又分散了写压力。
目录
一、集群概念
1.1、本质
Redis 集群(Cluster)是 Redis 官方提供的分布式数据库方案,通过多组分片(Sharding) 存储数据的不同部分,从而实现数据水平扩展 与高可用性 。每个分片由一个主节点和若干从节点组成,数据通过哈希槽(Hash Slot) 均匀分布在不同分片上。
简单理解:就像把一个大型图书馆分成多个区域,每个区域由专人管理,共同构成一个完整的图书系统。
主从分片:多个 "主节点 + 从节点" 组成分片,每个主节点负责一部分数据,从节点备份主节点数据(类似主从复制);哈希槽(Hash Slot):Redis 把所有数据映射到 16384 个槽位(0-16383),每个主节点负责一部分槽位,数据按槽位分配到对应分片 ------ 相当于 "快递分区",槽位是分区编号,主节点是分区快递站。
1.2、集群架构
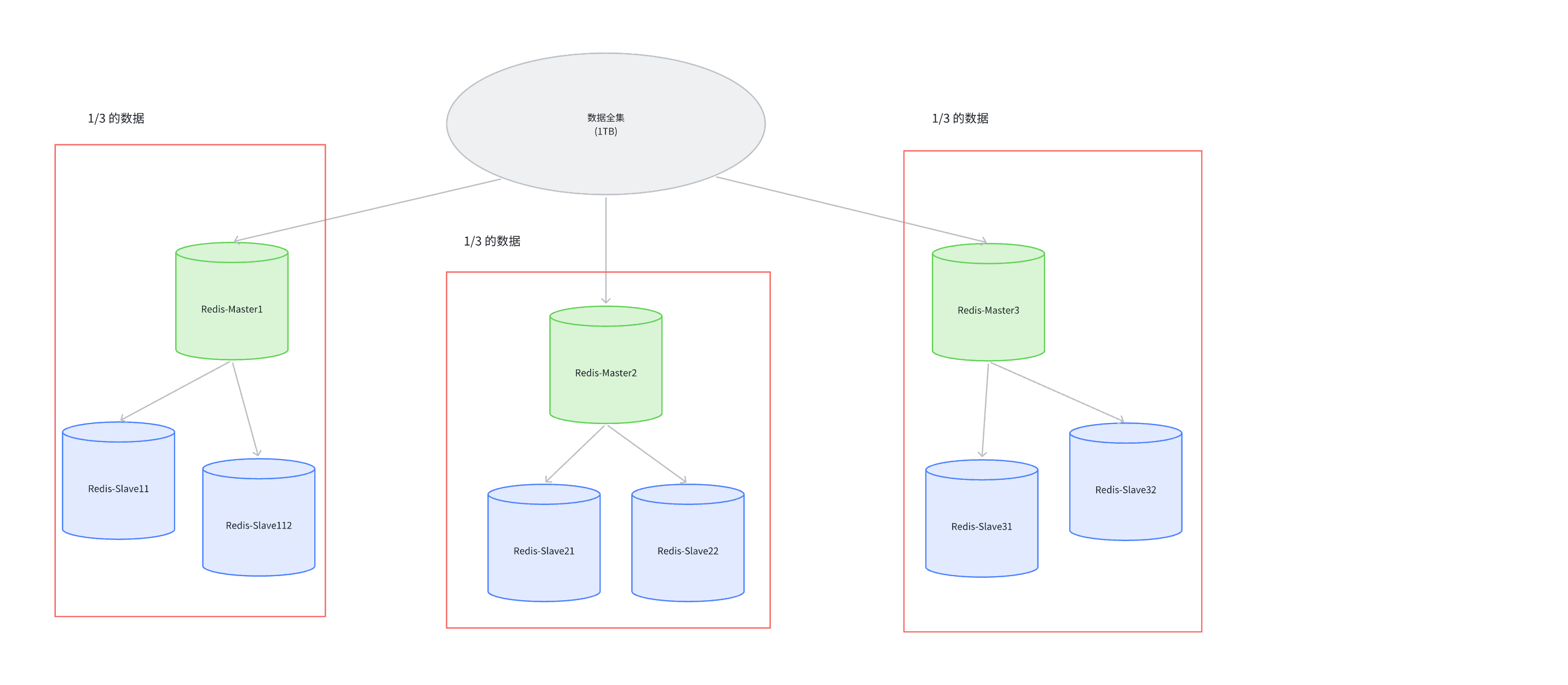
Master1和Slave11和Slave12保存的是同样的数据.占总数据的1/3
Master2和Slave21和Slave22保存的是同样的数据.占总数据的1/3
Master3和Slave31和Slave32保存的是同样的数据.占总数据的1/3
核心特点
每个主节点独立负责一部分槽位,写操作分散在多个主节点,解决单主写压力;
从节点只负责备份和读请求,主节点宕机后从节点自动上位,保证高可用;
客户端连接任意节点即可访问整个集群,节点间通过 Gossip 协议同步集群信息(比如槽位分配、节点状态)。
二、数据分片算法
集群的核心思想是用多组机器来存储数据的每个部分,那我们就需要考虑给定一个数据,这个数据应该存储在哪个分片上,读取的时候又应该去哪个分片上,业界有三种方式,Redis采用的是哈希槽。
2.1、哈希求余
设有N个分片,使用0,N-1这样序号进行编号.
针对某个给定的key,先计算hash值,再把得到的结果%N,得到的结果即为分片编号.
优点:逻辑简单、实现成本低,数据初始分配均匀;
缺点:扩容 / 缩容时(N 变化),所有 key 的映射关系都会失效,需要全量数据迁移,开销极大(比如 N 从 3 扩到 4,大部分 key 的余数会变)。

2.2、一致性算法
针对哈希求余的改进,降低搬运开销
构建一个 0~2³²-1 的 "哈希圆环",哈希值按顺时针分布;
把每个分片节点映射到圆环的某个位置(比如计算节点 IP 的哈希值);
对 key 计算哈希值,在圆环上顺时针找到第一个分片节点,就是存储节点。
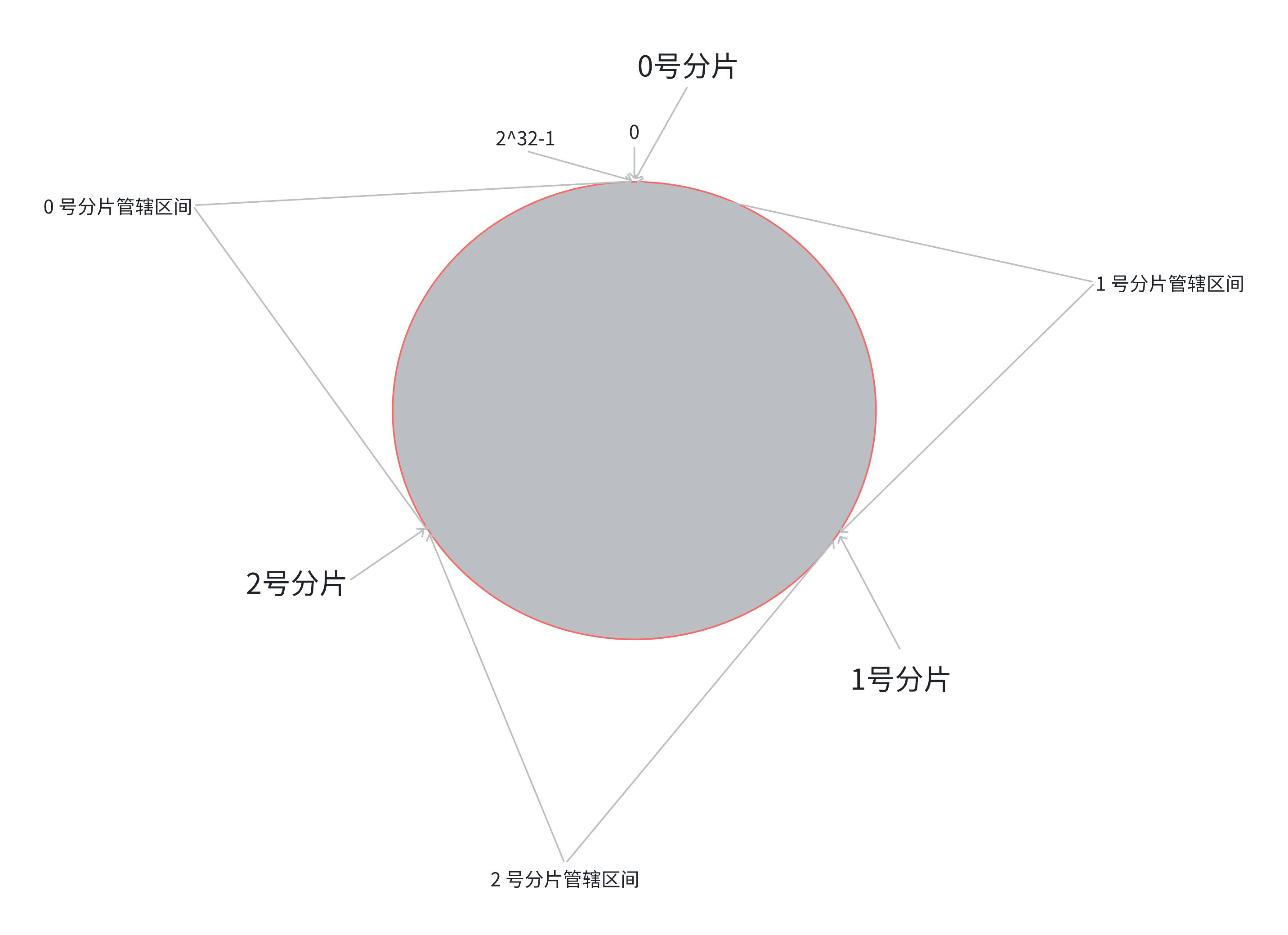
优点:扩容 / 缩容时,只需要迁移相邻分片的部分数据(比如新增一个分片,只迁移该分片在圆环上 "管辖" 的区间数据),开销远低于哈希求余;

新增3号分片,此时只需要把0号分片上的部分数据,搬运给3号分片即可,1号分片和2号分片管理的区间都是不变的
缺点:数据容易倾斜(比如部分分片在圆环上分布过密,导致某几个分片数据过多),需要手动调整节点位置(比如虚拟节点)来优化,复杂度高。
2.3、哈希槽分区算法(Redis使用)
1、哈希槽的核心机制
总槽数:16384 个(0-16383)
分配规则:集群创建时,槽位会比较平均分配给各个主节点(比如 3 主节点各分 5461/5462/5461 个槽);
数据映射流程
客户端计算 key 的哈希值:crc16(key) % 16384 → 得到对应的槽位;
集群根据槽位找到对应的主节点;
数据存储 / 读取到该主节点(从节点同步数据)。
2、为什么选哈希槽
Redis 集群没有用传统的 "哈希求余" 或 "一致性哈希",而是选了哈希槽,核心原因是解决前两种算法的痛点
|--------|-------------------------|------------------------|
| 算法 | 核心问题 | 哈希槽的解决方式 |
| 哈希求余 | 扩容时 N 变化,所有数据需重新映射,搬运量大 | 槽位固定 16384 个,扩容只迁移部分槽位 |
| 一致性哈希 | 数据容易倾斜(节点分布不均) | 槽位平均分配,天然避免数据倾斜 |
哈希槽 ="固定分区 + 灵活迁移",兼顾扩容效率和数据均衡,这是 Redis 集群的设计精髓。
3、为什么是16384个槽位
槽位数量太少会导致单个槽数据量大,迁移慢,槽位数量太多的话会增加节点之间的心跳包开销(心跳包需要携带槽位位图,16384个槽仅需2KB,65536个仅需8KB)
注意:集群的最大分片数理论上是16384,但实际上建议不超过1000个,太大会增加复杂度,出现故障的概率也越大
三、集群关键流程
3.1、故障判定
集群中的所有节点,会周期性的使用心跳包进行通信
主观下线(PFAIL):节点A认为节点B不可达。
客观下线(FAIL):A通过Redis内置的Gossip协议和其他节点沟通,确认B的状态,如果超过半数主节点认为B不可达,A就把B标记为FAIL。
出现集群宕机情况:
某个分片所有的主节点和从节点都挂了
某个分片主节点挂了,但是没有从节点
超过半数的master节点都挂了
3.2、故障转移
上面的例子中,B FAIL,并且A把B FAIL的消息告诉集群中其他节点
(1)如果B是从节点,就不需要故障转移;
(2)如果B是主节点,那就会由B的从节点触发故障转移
流程如下:
主节点宕机后,其从节点通过投票(类似Raft 算法)竞选新主;
胜出的从节点晋升为主节点,接管原主节点的所有槽位;
集群通过 Gossip 协议同步新的槽位分配信息,客户端后续访问自动路由到新主节点;
原主节点恢复后,自动成为新主节点的从节点。
注意:
(1)这里投票的时候,只有主节点才具有投票权,和标准的Raft算法有不同之处
(2)和哨兵机制不同的是,哨兵机制需要选举Leader,然后由Leader选出一个节点作为主节点,而集群是从节点直接竞选主节点,无额外进程
3.3、集群扩容
新增主节点(add-node),加入集群;
执行 reshard 命令,把现有主节点的部分槽位迁移到新主节点;
新增从节点,关联新主节点(--cluster-slave --cluster-master-id);
槽位迁移完成后,新主节点开始承担对应槽位的数据读写。