目录
[2. 数据加载与清洗](#2. 数据加载与清洗)
[3. 构建中文 Tokenizer](#3. 构建中文 Tokenizer)
[3. 文本编码与数据保存](#3. 文本编码与数据保存)
[三、构建 DataLoader](#三、构建 DataLoader)
[四、构建 LSTM 模型](#四、构建 LSTM 模型)
[1. 训练配置](#1. 训练配置)
[2. 训练与验证](#2. 训练与验证)
LSTM 即长短期记忆网络,是 一种改进型循环神经网络(RNN),专为解决传统 RNN 处理长序列数据时的梯度消失和梯度爆炸问题而设计,在时序数据相关领域应用广泛,以下是其具体介绍及优缺点分析:
- 核心结构与工作原理
- 细胞状态:这是 LSTM 的核心,如同一条贯穿网络的 "信息高速公路",能长期存储关键信息并不受干扰地传递,是实现长期记忆的基础,可通过门控机制选择性更新信息。
- 三大门控单元:遗忘门、输入门和输出门通过输出 0 - 1 之间的值控制信息传递比例。遗忘门决定丢弃细胞状态中的哪些历史旧信息;输入门筛选当前时刻重要信息并生成候选信息,进而更新到细胞状态;输出门则筛选细胞状态内容,确定传递给下一时刻的信息。三者协同作用,让模型实现对信息的记忆、更新与筛选。
- 主要优点
- 高效捕捉长期依赖:这是 LSTM 最核心的优势。借助细胞状态的 "信息高速公路" 和三大门控机制,误差在反向传播时能有效在时间序列中传递,避免了梯度消失或爆炸,使得模型能精准记住长序列数据中的关键信息,比如在长文本翻译中记住前文的核心主语。
- 信息控制灵活:三大门控可动态调节信息流,遗忘门清理无用信息,输入门收纳新的有用信息,输出门按需提取信息。这种机制让模型能灵活适配不同任务,像在情感分析中,可着重保留否定词等对情感判断关键的信息。
- 主要缺点
- 计算复杂度高:门控机制和细胞状态的更新过程,使得 LSTM 的参数量远大于普通 RNN。若隐藏层维度为 d,其参数量达 4d² + 4d,大量的矩阵乘法和门控操作导致训练和推理时计算量剧增,训练速度远慢于普通神经网络。
- 并行化难度大:LSTM 需严格按照时间步顺序处理序列数据,必须等前一时刻的计算完成后,才能进行当前时刻的运算,无法像 Transformer 那样实现并行计算,在处理超长序列和大规模数据时效率受限。
在电商场景中,用户评论的情感倾向分析是商家了解产品口碑、优化服务的重要手段。本文将详细介绍如何基于 LSTM(长短期记忆网络)实现电商评论的情感二分类(正向 / 负向),从数据预处理、模型构建到训练预测,完整还原整个实战流程。
一、项目背景
情感分析的核心是让机器理解文本的情感倾向,而 LSTM 作为一种循环神经网络(RNN)的变体,能够有效捕捉文本序列的上下文依赖关系,非常适合处理文本类序列数据。
二、数据预处理
1.导入相关依赖
python
import pandas as pd
from sklearn.model_selection import train_test_split
import torch
import jieba
from tqdm import tqdm
from typing import List
import json
from torch.utils.data import Dataset, DataLoader
from torch import nn,optim
from torch.utils.tensorboard import SummaryWriter2. 数据加载与清洗
本次使用的数据集为online_shopping_10_cats.csv(电商评论数据集),首先进行基础清洗:

python
# 加载数据
data = pd.read_csv('./data/online_shopping_10_cats.csv')
# 去除空值、无关列
data.dropna(inplace=True)
data.drop(columns=['cat'], inplace=True)
# 分层划分训练集/测试集(保证正负样本比例)
train_data, test_data = train_test_split(data, test_size=0.2, stratify=data['label'])3. 构建中文 Tokenizer
中文文本需要先分词再编码,我们自定义JieBaTokenizer类,实现分词、词表构建、文本编码等功能:
python
class JieBaTokenizer:
unk_index = 1 # 未知词索引
pad_index = 0 # 填充词索引
def __init__(self, vocab_list):
self.vocab_list = vocab_list
self.vocab_size = len(vocab_list)
self.word2index = {v: i for i, v in enumerate(vocab_list)}
self.index2word = {i: v for i, v in enumerate(vocab_list)}
# 分词(静态方法)
@staticmethod
def tokenize(text: str) -> List[str]:
return jieba.lcut(text.replace(' ', '').strip())
# 文本编码(转为固定长度索引序列)
def encode(self, text: str, seq_len: int) -> List[int]:
tokens = self.tokenize(text)
tokens_index = [self.word2index.get(token, self.unk_index) for token in tokens]
# 截断或填充至固定长度
if len(tokens_index) > seq_len:
return tokens_index[:seq_len]
else:
tokens_index.extend([self.pad_index] * (seq_len - len(tokens_index)))
return tokens_index
# 构建词表并保存
@classmethod
def build_vocab(cls, sentences: List[str], unk_token='<unknown>', pad_token='<padding>', vocab_path='./vocab.json'):
vocab_set = set()
for sentence in tqdm(sentences, desc='构建词表:'):
vocab_set.update(jieba.lcut(sentence.replace(' ', '')))
vocab_list = [pad_token, unk_token] + sorted(list(vocab_set))
vocab_dict = {i: v for i, v in enumerate(vocab_list)}
with open(vocab_path, 'w', encoding='utf-8') as f:
json.dump(vocab_dict, f, ensure_ascii=False, indent=2)
# 加载词表
@classmethod
def read_vocab(cls, vocab_path='./vocab.json'):
with open(vocab_path, 'r', encoding='utf-8') as f:
json_dict = json.load(f)
vocab_list = [v for _, v in json_dict.items()]
return cls(vocab_list)3. 文本编码与数据保存
基于训练集构建词表,并将训练集 / 测试集的评论转为固定长度的索引序列,保存为 JSONL 格式方便后续加载:
python
# 构建词表
JieBaTokenizer.build_vocab(train_data['review'].tolist())
# 加载词表
tokenizer = JieBaTokenizer.read_vocab(vocab_path='./vocab.json')
print(f"词表大小:{tokenizer.vocab_size}")
# 编码文本(固定长度128)
train_data['review'] = train_data['review'].apply(lambda x: tokenizer.encode(x, 128))
test_data['review'] = test_data['review'].apply(lambda x: tokenizer.encode(x, 128))
# 保存处理后的数据
train_data.to_json('train_data.jsonl', orient='records', lines=True)
test_data.to_json('test_data.jsonl', orient='records', lines=True)三、构建 DataLoader
自定义Dataset类,加载处理后的数据集,并通过DataLoader实现批量加载:
python
class CommentDataset(Dataset):
def __init__(self, path):
self.data = pd.read_json(path, orient='records', lines=True).to_dict(orient='records')
def __len__(self):
return len(self.data)
def __getitem__(self, index):
# 转为张量
input_tensor = torch.tensor(self.data[index]['review'], dtype=torch.long)
target_tensor = torch.tensor(self.data[index]['label'], dtype=torch.float32)
return input_tensor, target_tensor
# 构建DataLoader
train_dataset = CommentDataset('train_data.jsonl')
test_dataset = CommentDataset('test_data.jsonl')
train_dataloader = DataLoader(dataset=train_dataset, batch_size=16, drop_last=True)
test_dataloader = DataLoader(dataset=test_dataset, batch_size=16, drop_last=True)四、构建 LSTM 模型
定义包含嵌入层、LSTM 层、全连接层的情感分析模型,核心思路是:
-
嵌入层:将词索引转为稠密向量;
-
LSTM 层:捕捉文本序列的上下文特征;
-
全连接层:将 LSTM 输出的特征映射为情感分类结果。
python
class Network(nn.Module):
def __init__(self, vocab_size, padding_idx):
super(Network, self).__init__()
# 嵌入层
self.embedding = nn.Embedding(
num_embeddings=vocab_size,
embedding_dim=128,
padding_idx=padding_idx # 忽略填充词的梯度
)
# LSTM层
self.lstm = nn.LSTM(
input_size=128,
hidden_size=256,
num_layers=2,
batch_first=True, # 输入格式:[batch_size, seq_len, input_size]
bidirectional=False
)
# 全连接层(二分类)
self.linear = nn.Linear(in_features=256, out_features=1)
def forward(self, x: torch.Tensor):
# 嵌入层输出:[batch_size, seq_len, 128]
embedding = self.embedding(x)
# LSTM输出:output [batch_size, seq_len, 256];hn/cn [num_layers, batch_size, 256]
output, (_hn, _cn) = self.lstm(embedding)
# 获取每个样本最后一个非填充token的隐藏状态
batch_indexs = torch.arange(0, output.shape[0])
length = (x != self.embedding.padding_idx).sum(dim=1) # 每个样本的真实长度
output = self.linear(output[batch_indexs, length-1]).squeeze(-1)
return output五、模型训练
1. 训练配置
设置训练设备(GPU/CPU)、损失函数、优化器、训练轮数等:
python
# 日志保存
writer = SummaryWriter('./logs')
# 设备选择
device = 'cuda' if torch.cuda.is_available() else 'cpu'
# 模型初始化
model = Network(vocab_size=tokenizer.vocab_size, padding_idx=0).to(device)
# 训练参数
epochs = 5
loss_fn = nn.BCEWithLogitsLoss() # 适用于二分类的交叉熵损失(内置sigmoid)
optimizer = optim.Adam(model.parameters(), lr=0.001)2. 训练与验证
训练过程中同时验证模型性能,保存验证集损失最低的模型:
python
best_loss = float('inf')
for epoch in range(epochs):
print(f'==========第{epoch+1}轮============')
# 训练阶段
model.train()
train_total_loss = 0
train_correct_count = 0
train_total_count = 0
for train_x, train_y in tqdm(train_dataloader, desc='训练'):
train_x, train_y = train_x.to(device), train_y.to(device)
pred_y = model(train_x)
loss = loss_fn(pred_y, train_y)
# 反向传播
optimizer.zero_grad()
loss.backward()
optimizer.step()
# 统计训练损失与准确率
train_total_loss += loss.item()
batch_pred = torch.sigmoid(pred_y) # 转为0-1概率
pred_label = (batch_pred > 0.5)
train_correct_count += (pred_label == train_y).sum().item()
train_total_count += train_y.size(0)
# 验证阶段(无梯度计算)
model.eval()
test_total_loss = 0
test_correct_count = 0
test_total_count = 0
with torch.no_grad():
for test_x, test_y in tqdm(test_dataloader, desc='验证'):
test_x, test_y = test_x.to(device), test_y.to(device)
pred_y = model(test_x)
loss = loss_fn(pred_y, test_y)
test_total_loss += loss.item()
batch_pred = torch.sigmoid(pred_y)
pred_label = (batch_pred > 0.5)
test_correct_count += (pred_label == test_y).sum().item()
test_total_count += test_y.size(0)
# 计算平均损失与准确率
train_avg_loss = train_total_loss / len(train_dataloader)
test_avg_loss = test_total_loss / len(test_dataloader)
train_acc = train_correct_count / train_total_count
test_acc = test_correct_count / test_total_count
print(f'训练集损失:{train_avg_loss:.4f},训练集准确率:{train_acc:.4f}')
print(f'验证集损失:{test_avg_loss:.4f},验证集准确率:{test_acc:.4f}')
# 记录日志
writer.add_scalar('loss/train', train_avg_loss, epoch)
writer.add_scalar('loss/val', test_avg_loss, epoch)
# 保存最优模型
if test_avg_loss < best_loss:
best_loss = test_avg_loss
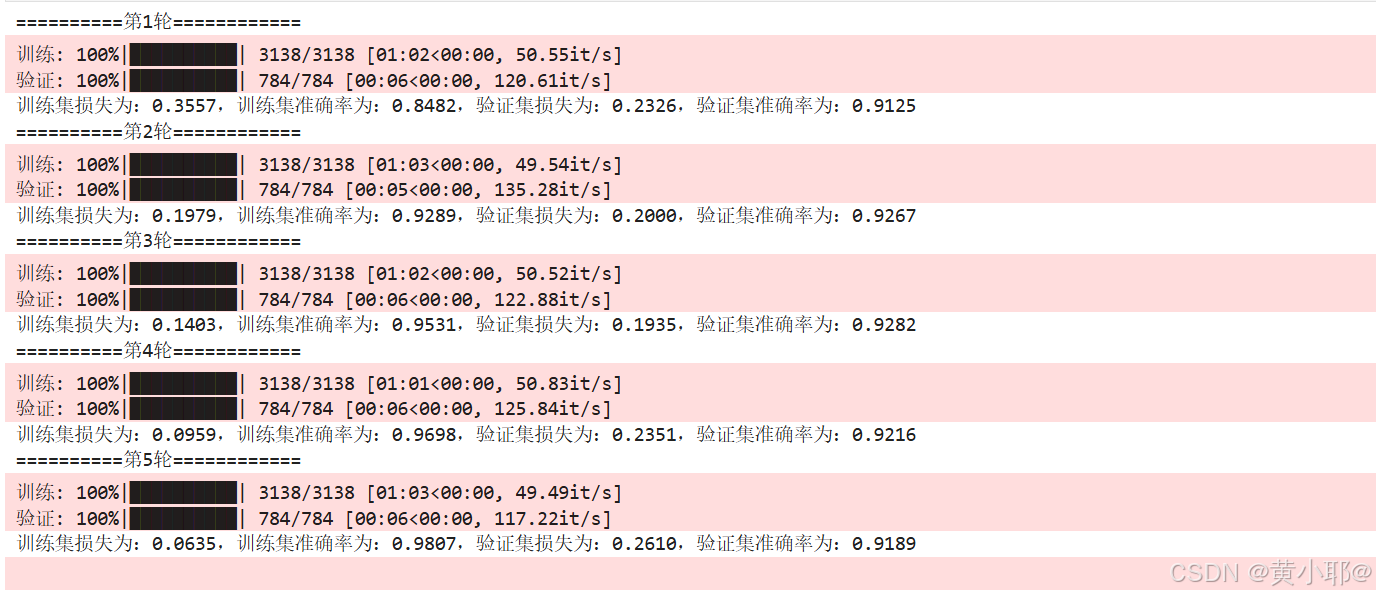
torch.save(model, 'best_model.pt')如下图可以看到,训练集准确率持续提升,但验证集在第 3 轮后损失上升,出现轻微过拟合,可通过调整 LSTM 层数、添加 dropout、降低学习率等方式优化。
六、模型预测
加载最优模型,实现交互式评论情感预测:
python
def predict(model, text):
# 文本编码
text_encoded = tokenizer.encode(text, 128)
# 转为张量并添加batch维度
text_tensor = torch.tensor(text_encoded, dtype=torch.long).unsqueeze(0).to(device)
model.eval()
with torch.no_grad():
pred_y = model(text_tensor)
pred_prob = torch.sigmoid(pred_y) # 转为概率值
return pred_prob[0]
# 加载模型
model = torch.load('best_model.pt').to(device)
# 交互式预测
while True:
input_text = input('请输入评论(输入q退出):')
if input_text == 'q':
break
pred_prob = predict(model, input_text)
if pred_prob > 0.5:
print(f'正向评论,概率:{pred_prob:.4f}')
else:
print(f'负向评论,概率:{pred_prob:.4f}')如图,测试模型的效果

七、完整代码如下
python
# 导入依赖
import pandas as pd
from sklearn.model_selection import train_test_split
import torch
import jieba
from tqdm import tqdm
from typing import List
import json
from torch.utils.data import Dataset, DataLoader
from torch import nn,optim
from torch.utils.tensorboard import SummaryWriter
data=pd.read_csv('./data/online_shopping_10_cats.csv')
# 数据预处理
data.dropna(inplace=True)
data.drop(columns=['cat'],inplace=True) # 去除空值
# 划分训练集和验证集
train_data,test_data=train_test_split(data,test_size=0.2,stratify=data['label'])
class JieBaTokenizer: # 构建tokenizer
unk_index=1
pad_index=0
def __init__(self,vocab_list):
self.vocab_list=vocab_list
self.vocab_size = len(vocab_list)
self.world2index={value:index for index,value in enumerate(vocab_list)}
self.index2world={index:value for index,value in enumerate(vocab_list)}
@staticmethod
def tokenize(text:str)->List[str]:
return jieba.lcut(text.replace(' ','').strip())
def encode(self,text:str,seq_len:int)->List[int]:
tokens=self.tokenize(text)
tokens_index=[self.world2index.get(token,self.unk_index) for token in tokens]
if len(tokens_index)>seq_len:
tokens_index=tokens_index[:seq_len]
return tokens_index
else:
need=seq_len-len(tokens_index)
tokens_index.extend([self.pad_index for _ in range(need)])
return tokens_index
@classmethod
def build_vocab(
cls,sentences:List[str],
unk_token:str='<unknown>',
pad_token:str='<padding>',
vocab_path:str='./vocab.json'
):
vocab_set=set()
for sentence in tqdm(sentences,desc='构建词表:'):
vocab_set.update(jieba.lcut(sentence.replace(' ','')))
vocab_list = [pad_token, unk_token] + sorted(list(vocab_set))
vocab_dict={index:value for index,value in enumerate(vocab_list)}
with open(vocab_path,'w',encoding='utf-8') as f:
json.dump(vocab_dict, f, ensure_ascii=False, indent=2)
@classmethod
def read_vocab(cls,vocab_path:str='./vocab.json'):
with open(vocab_path,'r',encoding='utf-8') as f:
json_dict=json.load(f)
sentences=[value for key,value in json_dict.items()]
return cls(sentences)
# 根据词表
JieBaTokenizer.build_vocab(train_data['review'].tolist())
tokenizer=JieBaTokenizer.read_vocab(vocab_path='./vocab.json')
print(tokenizer.vocab_size)
train_data['review']=train_data['review'].apply(lambda x:tokenizer.encode(x,128))
test_data['review']=test_data['review'].apply(lambda x:tokenizer.encode(x,128))
train_data.to_json('train_data.jsonl',orient='records',lines=True)
test_data.to_json('test_data.jsonl',orient='records',lines=True)
# 根据Dataloader
class CommentDataset(Dataset):
def __init__(self, path):
self.data = pd.read_json(path, orient='records', lines=True).to_dict(orient='records')
def __len__(self):
return len(self.data)
def __getitem__(self, index):
input_rensor = torch.tensor(self.data[index]['review'], dtype=torch.long)
target_rensor = torch.tensor(self.data[index]['label'], dtype=torch.float32)
return input_rensor, target_rensor
train_dataset=CommentDataset('train_data.jsonl')
test_dataset=CommentDataset('test_data.jsonl')
train_dataloader=DataLoader(dataset=train_dataset,batch_size=16,drop_last=True)
test_dataloader=DataLoader(dataset=test_dataset,batch_size=16,drop_last=True)
# 构建LSTM模型
class Network(nn.Module):
def __init__(self,vocab_size,padding_idx):
super(Network,self).__init__()
self.embeding=nn.Embedding(
num_embeddings=vocab_size,
embedding_dim=128,
padding_idx=padding_idx
)
self.lstm=nn.LSTM(
input_size=128,
hidden_size=256,
num_layers=2,
batch_first=True,
bidirectional=False,
)
self.linear = nn.Linear(in_features=256,out_features=1)
def forward(self,x:torch.Tensor):
embedding=self.embeding(x)
output,(_hn,_cn)=self.lstm(embedding)
#获取每个样本最后一个token真实的隐藏状态
batch_indexs=torch.arange(0,output.shape[0])
length=(x!=self.embeding.padding_idx).sum(dim=1)
output=self.linear(output[batch_indexs,length-1]).squeeze(-1)
return output
writer=SummaryWriter('./logs')
device='cuda' if torch.cuda.is_available() else 'cpu'
model=Network(vocab_size=tokenizer.vocab_size,padding_idx=0).to(device)
# 训练配置
epochs=5
loss_fn=nn.BCEWithLogitsLoss()
optimizer=optim.Adam(model.parameters(),lr=0.001)
# 模型训练
best_loss=float('inf')
for epoch in range(epochs):
print(f'==========第{epoch+1}轮============')
model.train()
train_total_loss=0
train_total_count=0
train_correct_count=0
for train_x, train_y in tqdm(train_dataloader,desc='训练'):
train_x, train_y = train_x.to(device), train_y.to(device)
pred_y = model(train_x)
loss = loss_fn(pred_y, train_y)
optimizer.zero_grad()
loss.backward()
optimizer.step()
train_total_loss += loss.item()
batch_value=torch.sigmoid(pred_y)
pred_label = (batch_value > 0.5)
correct = (pred_label == train_y).sum().item()
train_correct_count += correct
train_total_count+=train_y.size(0)
model.eval()
test_total_loss = 0
test_total_count=0
test_correct_count=0
with torch.no_grad():
for test_x, test_y in tqdm(test_dataloader,desc='验证'):
test_x, test_y = test_x.to(device), test_y.to(device)
pred_y = model(test_x)
loss = loss_fn(pred_y, test_y)
test_total_loss += loss.item()
batch_value=torch.sigmoid(pred_y)
pred_label = (batch_value > 0.5)
correct=(pred_label==test_y).sum().item()
test_correct_count += correct
test_total_count+=test_y.size(0)
train_avg_loss=train_total_loss/len(train_dataloader)
test_avg_loss=test_total_loss/len(test_dataloader)
train_acc=train_correct_count/train_total_count
test_acc=test_correct_count/test_total_count
print(f'训练集损失为:{train_avg_loss:.4f},训练集准确率为:{train_acc:.4f},验证集损失为:{test_avg_loss:.4f},验证集准确率为:{test_acc:.4f}')
writer.add_scalar('loss/train', train_avg_loss, epoch)
writer.add_scalar('loss/val', test_avg_loss, epoch)
if test_avg_loss < best_loss:
best_loss=test_avg_loss
torch.save(model,'best_model.pt')
# 模型测试
def predict(model,text):
text=tokenizer.encode(text,128)
text_tensor=torch.tensor(text,dtype=torch.long).unsqueeze(0).to('cuda')
model.eval()
with torch.no_grad():
pred_y=model(text_tensor)
pred_label=torch.sigmoid(pred_y)
return pred_label[0]
model=torch.load('best_model.pt').to('cuda')
while True:
input_text=input('请输入你的评论:')
if input_text=='q':
break
pred=predict(model,input_text)
if pred>0.5:
print(f'正向:{pred}')
else:
print(f'负向:{pred}')