目录
[1、原码的计算示例(8 位)](#1、原码的计算示例(8 位))
[1、反码的计算规则(8 位)](#1、反码的计算规则(8 位))
[2. 反码的计算示例(8 位)](#2. 反码的计算示例(8 位))
[2、补码的计算规则(8 位)](#2、补码的计算规则(8 位))
[3、补码的计算示例(8 位)](#3、补码的计算示例(8 位))
[(二)浮点数的存储规则:IEEE 754 标准](#(二)浮点数的存储规则:IEEE 754 标准)
[1、阶码(E)为全 0](#1、阶码(E)为全 0)
[2、阶码(E)为全 1](#2、阶码(E)为全 1)
一、原码、反码、补码
在计算机系统中,数值的存储和运算并非直接使用我们熟悉的十进制,而是采用二进制。
由于需要表示正负数,科学家设计了原码、反码、补码 三种编码方式,其中补码是现代计算机的标准编码,解决了原码 / 反码的运算缺陷。
要理解三者的关系,需先明确 "符号位" 的概念 ------ 二进制数的最高位用于表示正负:0 表示正数,1 表示负数,其余位为 "数值位"(表示绝对值的二进制)。
(一)基础前提:机器数与真值
1、真值:人类可读的实际数值,如 +5、-3。
2、机器数:计算机中存储的二进制数,包含**"符号位 + 数值位"**。例如,若用 8 位二进制表示:
(1) 真值 +5 的机器数(原码):00000101(最高位 0 为正,后 7 位是 5 的二进制);
(2)真值 -5 的机器数(原码):10000101(最高位 1 为负,后 7 位是 5 的二进制)。
下文默认以8 位二进制为例(1 位符号位 + 7 位数值位),若未特殊说明,均遵循此规则。
(二)原码
原码是最直观的编码方式,直接对 **"符号位 + 真值的二进制绝对值"**进行组合,规则如下:
**①正数原码:**符号位为 0,数值位为真值的二进制绝对值。
**②负数原码:**符号位为 1,数值位为真值的二进制绝对值。
1、原码的计算示例(8 位)
| 真值 | 符号位 | 数值位(绝对值的二进制) | 8 位原码 |
|---|---|---|---|
| +3 | 0 | 0000011(3 的 7 位二进制) | 00000011 |
| -3 | 1 | 0000011(3 的 7 位二进制) | 10000011 |
| +127 | 0 | 1111111(127 的 7 位二进制) | 01111111 |
| -127 | 1 | 1111111(127 的 7 位二进制) | 11111111 |
| 0 | 0/1 | 0000000(0 的绝对值为 0) | 00000000(+0)、10000000(-0) |
2、原码的缺陷(为何被淘汰)
原码的优点是直观,但存在两个致命问题,导致无法直接用于计算机运算:
(1)" 0 " 的表示不唯一: 存在 +0(00000000)和 -0(10000000),但逻辑上 0 没有正负,浪费了一个存储位。
(2)减法运算异常:计算机本质上只有加法器,减法需转化为 "加负数"(如 3-2 = 3 + (-2)),但原码计算会出错:
**示例:**3-2 = 3 + (-2),原码分别为 00000011 和 10000010,相加得 10000101(对应真值 -5),显然错误。
(三)反码:原码的过渡改进
反码是为解决原码减法问题设计的过渡编码,规则与原码不同,核心是 "负数反码 = 正数原码按位取反"(符号位也取反)。
1、反码的计算规则(8 位)
(1)正数反码: 与正数原码完全相同(符号位 0,数值位为绝对值二进制)。
(2)负数反码: 符号位为 1,数值位为**"对应正数的数值位按位取反"**(0 变 1,1 变 0)。
2. 反码的计算示例(8 位)
|------------|------------------|-----------------------------------|---------------------------|
| 真值 | 正数原码(参考) | 反码计算过程 | 8 位反码 |
| +3 | 00000011 | 正数反码 = 原码 | 00000011 |
| -3 | 00000011 | 符号位 1 + 数值位取反(1111100) | 11111100 |
| +127 | 01111111 | 正数反码 = 原码 | 01111111 |
| -127 | 01111111 | 符号位 1 + 数值位取反(0000000) | 10000000 |
| 0 | 00000000 | +0 反码 = 00000000;-0 反码 = 11111111 | 00000000(+0)、11111111(-0) |
3、反码的改进与残留问题
(1)改进
**减法运算更合理。**例如 3-2 = 3 + (-2):3 的反码为00000011,-2 的反码为11111101;相加得 00000000(反码,对应真值 + 0),结果正确(逻辑上 0 即 3-2 的结果)。
(2)残留问题
仍未解决**"0 的表示不唯一"**(+0和-0并存)。
且运算后若有**"进位"**(超出 8 位),需额外处理 "循环进位"(将进位位加到结果的最低位),增加了硬件复杂度。因此反码仅作为补码的 "计算桥梁",未被实际采用。
(四)补码:现代计算机的标准编码
补码彻底解决了原码 / 反码的缺陷,是当前所有计算机存储和运算的标准编码。
其核心思想源于 "模运算"(类似时钟:13 点 = 1 点,模为 12)------ 通过 "补数" 将减法转化为加法,且不存在 "-0"。
1、补码的核心原理:模运算
以 8 位二进制为例,其 "模"(可表示的所有数的范围)为 = 256(即 0~255)。
对于负数 (- x),其补码等价于**"模 - x"**(即 256 - x),因此:
x + (-x) = x + (256 - x) = 256,而 256 在 8 位二进制中是 100000000,超出 8 位的进位被舍弃,结果为 00000000(即 0),符合 "正负相加为 0" 的逻辑。
2、补码的计算规则(8 位)
补码的计算分 "正数" 和 "负数",规则简单且易硬件实现:
**(1)正数补码:**与正数原码、正数反码完全相同(符号位 0,数值位为绝对值二进制)。
**(2)负数补码:**有两种等价计算方式:
**① 公式法:**负数补码 = 模 - 数值绝对值(8 位模为 256,16 位模为 65536);
② 快捷法:负数补码 = 对应正数的反码 + 1(符号位不变,其余位 取反再+1,常用)。
3、补码的计算示例(8 位)
以真值 -3 和 -128 为例,验证两种计算方式:
示例 1:计算 -3 的补码
方式 1(公式法)
① 模 = 256,绝对值 3 → ②256 - 3 = 253 → ③253 的二进制为 11111101;
方式 2(快捷法)
**① -**3 的原码是 10000011 → ② 取反得 11111100(-3 的反码)→ ③加 1 得 11111101;
结论:-3 的 8 位补码为 11111101。
示例 2:计算 -128 的补码(特殊值)
8 位二进制的数值位只有 7 位,最大正数是 +127(01111111),而 -128 是 8 位补码的 "特殊值",无对应的原码 / 反码,所以只可以用公式法:
方式 1(公式法)
①模 = 256,绝对值 128 → ②256 - 128 = 128 → ③128 的二进制为 10000000;
结论:-128 的 8 位补码为 10000000(唯一表示,无歧义)。
示例3:补码完整对照表(8 位)
| 真值 | 原码 | 反码 | 补码 |
|---|---|---|---|
| +127 | 01111111 | 01111111 | 01111111 |
| +3 | 00000011 | 00000011 | 00000011 |
| +0/-0 | 00000000/10000000 | 00000000/11111111 | 00000000(唯一) |
| -3 | 10000011 | 11111100 | 11111101 |
| -127 | 11111111 | 10000000 | 10000001 |
| -128 | 无(超出 7 位数值位) | 无 | 10000000(特殊的补码) |
4、补码的优势(为何成为标准)
补码解决了原码 / 反码的所有缺陷,是计算机的最优选择。
**(1)"0" 的表示唯一:**仅 00000000,无 -0,避免存储位浪费。
**(2)减法运算自然:**无需额外处理进位,直接 "加负数补码" 即可:
示例 :3-2 = 3 + (-2)
3 的补码:00000011,-2 的补码:11111110,相加得 100000001 → 舍弃进位位 1,结果为 00000001(补码,对应真值 + 1),正确。
**(3)表示范围更大:**8 位补码可表示 -128 ~ +127(共 256 个数),而原码 / 反码仅能表示 -127 ~ +127(因 -128 无原码 / 反码)。
(五)三种编码的核心区别与总结
1、核心区别
| 对比维度 | 原码 | 反码 | 补码 |
|---|---|---|---|
| 正数编码 | 符号位 0 + 数值位绝对值 | 同原码(符号位 0 + 数值位) | 同原码 / 反码 |
| 负数编码 | 符号位 1 + 数值位绝对值 | 符号位 1 + 数值位取反 | 符号位 1+(反码 + 1) |
| 0 的表示 | 2 种(+0:00000000/-0:10000000) | 2 种(+0:00000000/-0:11111111) | 1 种(00000000) |
| 8位表示范围 | -127 ~ +127 | -127 ~ +127 | -128 ~ +127 |
| 运算支持 | 加法 / 减法均异常 | 减法需处理循环进位 | 加法 / 减法直接运算,无异常 |
| 计算机应用 | 仅用于直观表示,无实际应用 | 过渡编码,无实际应用 | 标准编码,所有计算机采用 |
2、最终结论
**(1)原码:**最直观,但缺陷多,仅用于理解正负,无实际运算价值;
(2)反码: 解决原码的部分减法问题,但仍有"双 0"和进位问题,仅作为补码计算的中间步骤;
**(3)补码:**兼顾直观性、运算效率和存储效率,是现代计算机表示和运算整数的唯一标准。
二、整数在内存中的存储
(一)存储方式
1、存储方式
整型数据在内存中实际存储二进制补码,调试窗口显示的 16 进制仅为 "方便人类查看",并非内存真实存储形式。(本文的数据以x86环境下32位的数据为例)
正数:原码、反码、补码完全相同。
如 int a = 5,补码为 00000000 00000000 00000000 00000101。
负数:补码 = 反码 + 1,反码 = 原码符号位不变、其他位按位取反。
如int b = -5,原码 10000000 00000000 00000000 00000101,反码 11111111 11111111 11111111 11111010,补码 11111111 11111111 11111111 11111011。
2、存储单位
数据以字节为基本单位存储,一个字节大小为8个比特,即八位二进制数字,如上述例子中的int 类型就是占据了4个字节。
当数据占用多个字节(如int占 4 字节、short占 2 字节)时,需确定字节在内存中的存储顺序,即 "字节序"(大端存储模式与小端存储模式)。
(二)大端存储与小端存储
1、定义与示例
以 int a = 0x11223344 为例
(1)大端字节序(大端存储)
① 定义:数值的高位字节 存储在内存低地址 ,低位字节 存储在内存高地址
**② 存储形式:**内存地址由低到高,****依次为 11 → 22 → 33 → 44(正序存储)
③ 特点:符合人类阅读习惯,如网络传输协议(TCP/IP)通常采用
(2)小端字节序(小段存储)
① 定义:数值的低位字节 存储在内存低地址 ,高位字节 存储在内存高地址
**② 存储形式:**内存地址由低到高,****依次为 44 → 33 → 22 → 11(逆序存储)
③ 特点:便于硬件设计,x86 架构处理器默认采用
(3)关键原则
存储与读取需遵循同一字节序,否则会导致数据解析错误,如小端存储的0x11223344按大端读取会得到0x44332211。
2、两个问题的回答
**第一个问题:**为什么需要区分大小端?
根本原因是内存单元以 "字节" 为最小分配单位,但多字节数据(如 int 、float 、short )需按 "整体" 存储,必然涉及字节顺序排列问题。
**第二个问题:**为什么会出现小端存储和大端存储两种分歧?
根本原因是" 早期硬件设计路径分歧 + 无绝对优劣的技术选择 ",导致两种模式并存至今。
硬件设计起点不同:早期 CPU 架构(如 x86、PowerPC)设计时,对 "多字节数据如何存更高效" 有不同判断 。
**小端(x86 等):**按 **"低位字节存低地址"**设计,契合 CPU 从低位开始的运算逻辑,硬件实现更简单;
**大端(PowerPC、早期网络设备等):**按 **"高位字节存低地址"**设计,契合人类读写数字的习惯(先读高位),早期在数据传输场景更直观。
两者无绝对技术优劣,只是不同团队的设计选择,且都形成了成熟生态。
最后便是生态惯性难以统一。两种模式分别绑定了主流硬件架构(如 小端占个人 PC / 服务器主流,大端占部分嵌入式 / 网络设备),并围绕其发展出操作系统、软件工具链。后期虽有统一需求,但更换模式需重构大量硬件和软件,成本极高,因此一直维持 "两种模式并存" 的状态。
(三)练习详解
**1、**设计一个小程序来判断当前机器的字节序
cpp
#define _CRT_SECURE_NO_WARNINGS
#include <stdio.h>
//方式1
int check_sys1()
{
int i = 1;
return (*(char*)&i);
}
//方式2
int check_sys2()
{
union
{
int i;
char c;
}un;
un.i = 1;
return un.c;
}
int main()
{
int ret = check_sys1();
//int ret = check_sys2();
if (ret == 1)
printf("小端\n");
else
printf("⼤端\n");
return 0;
}向一个 4 字节的 int 类型变量存入值 1,调试窗口显示为 00 00 00 01。通过不同方式获取该变量的第一个字节。
如果第一个字节是 1,说明是小端模式(低位字节存放在低地址);如果第一个字节是 0,说明是大端模式(高位字节存放在低地址)
第一段代码:通过指针强制转换,将 int 转为 char,获取第一个字节。
第二段代码:利用联合体(union)的特性(所有成员共享同一块内存),通过 char 类型成员获取第一个字节。
即指针类型转换 和联合体特性 都可以限制访问范围,让其只能读取到多字节数据的第一个字节,从而完成验证操作。
**2、**请问下面代码的输出结果是什么
cpp
#define _CRT_SECURE_NO_WARNINGS
#include <stdio.h>
int main()
{
char a= -1;
signed char b=-1;
unsigned char c=-1;
printf("a=%d,b=%d,c=%d",a,b,c);
return 0;
}
代码分析:
**前提:**大部分编译器中,char 默认等同于signed char (有符号字符型) ,占 1 字节。
(1)赋值阶段
-1的 32 位int补码为11111111 11111111 11111111 11111111。
-1 赋值给 char 类型时,会截断为 8 位二进制11111111(补码形式),这一步对有符号和无符号 char 都是一样的,区别在于后续的解释方式。
(2)整型提升阶段
%d 要求对应的参数必须是 int 类型,而 char 类型小于 int,因此会先通过整型提升补成 32 位的 int,再传递给 printf。
有符号 char(a 和 b)提升时进行**"符号扩展"**,高位补符号位(1),最终得到 32 位的11111111 11111111 11111111 11111111
无符号 char(c)提升时进行 "零扩展",高位补 0,最终得到 32 位的00000000 00000000 00000000 11111111
(3)输出阶段
① %d格式符将内存中的二进制按有符号整数解析,所以前两个是 - 1
② 同样是%d,但第三个的二进制按有符号解析就是 255(因为最高位是 0)
关键点总结:
① signed 与 unsigned 只是在创造了一块空间后,决定最高位是不是符号位。【赋值阶段】
② 而内存中存的是什么,有时候这个类型说了不算,而是你怎么用它,以什么视角看待它,用%d,或者是%u,也就是格式符决定了解析方式,与变量本身的类型无关。【整型提升阶段】
③ 但是我们要按照规则来写代码,无符号的就用无符号的占位符,有符号的就用有符号的占位符。【详见下面例题】
3、关于数据存与取的理解
我们也可以从存与取的角度去理解。数据有两个基本操作,一个是存,一个是取。
(1)先说存
数据类型定义了 "存储格式规则" 和"存储空间大小" ,只有符合该规则的数据才能被正确存储和解析。
首先是存储格式规则,无法就是两种。
一种是整数,以二进制形式存储;一种是浮点数,以 "IEEE 754 标准" 规定的格式存储。
也就是说无论是字符型、整型、布尔型,其实它们本质上都是整数,我们可以统称为整数类型。所以即便是整型类型存储字符型数据,它在存储格式规则上,也完全是合法的,因为大家的存储规则都是二进制。
但是浮点数(小数)就绝对不能用整数类型里面的数据类型去存储。也就是说,以数据的存储格式规则划分,其实数据类型就两种:整数类型与浮点类型。
接着便是存储空间大小。
在符合存储格式规则的前提下,如果一个小空间的数据类型,接收了大空间的数据,我们对大空间数据进行截断处理。【截断是针对补码的操作!】
就好比上面的char 类型,接收了int类型的数据 "-1",那么我们就是对这个32位的数据进行截断,只留下后 8 位。然后 signed 与 unsigned 决定最前面一位是不是符号位。
如果一个大空间的数据类型,接收了小空间数据,会先将小空间数据的二进制按规则 "补全" 到大空间的位数,再存入大空间变量中,即扩展操作。下面以赋值给 int 类型为例:
当小空间数据是有符号类型 (如 signed char、short),扩展时会用其最高位(符号位) 填充大空间新增的高位,确保数值的正负和大小不变。【符号扩展】
当小空间数据是无符号类型 (如 unsigned char、unsigned short),扩展时会用0填充大空间新增的高位,因为无符号类型没有符号位,所有位都是数值位。【零拓展】
(2)再说取
第一种是计算的时候:
当两个不同大小的数据类型进行相加(或其他算术运算)时,C 语言会自动将 "较小的类型" 提升为 "较大的类型",然后再执行运算。
然后存的时候,再遵循存的规则。这体现了 C 语言的类型转换规则:运算优先保证精度(扩展),存储则严格适配目标类型(可能截断)。
第二种是使用格式符输出的时候:
格式符会根据自身要求,对数据进行 "适配性处理" ------ 如果数据位数与格式符要求的位数不匹配,会自动进行**"截断"**或 **"扩展"**以满足格式符的解析需求。
cpp
#define _CRT_SECURE_NO_WARNINGS
#include <stdio.h>
int main() {
char a = 10; // 8位有符号,值为10
int b = 20; // 32位有符号,值为20
// 运算时,a会先自动扩展为32位int(符号扩展,高位补0)
int c = a + b; // 相当于 (int)a + b = 10 + 20 = 30
printf("%d\n", c); // 输出30
unsigned char d = 2; // 8位无符号,值为255
long e = -3; // 64位有符号,值为1
// 运算时,d先扩展为64位(零扩展),再与e相加
unsigned char f = d + e; // 相当于 (long)d + e = 2 + (-3) = -1
printf("%ld\n", f); // 输出255
return 0;
}(3)存与取
其实上面无非就是两种操作,扩展与截断。
小数据存进大数据类型的时候要扩展,小数据与大数据计算的时候也要扩展,小数据被大数据的格式符解读的时候也要扩展。
大数据存进小数据类型的时候要截断,大数据被小数据的格式符解读的时候也要截断。
学这些内容并不是说,我们要常常要用这些内容进行操作,反倒是少出现最好。
存的时候,符合**"存储格式规则" 和"存储空间大小"** ;取的时候,格式符与数据的类型也要匹配。对这些内容的学习,目的还是为了,帮助我们建立良好的数据存取习惯,以及提升对于数据存取代码中的错误的修改能力。
4、练习3(求输出的结果)
cpp
#define _CRT_SECURE_NO_WARNINGS
#include <stdio.h>
int main()
{
char a = -128;
printf("%u\n", a);
return 0;
}
cpp
#define _CRT_SECURE_NO_WARNINGS
#include <stdio.h>
int main()
{
char a = 128;
//如果是%d,那么将解读为-128
//%d的情况下,a为127时,则为127
printf("%d\n", a);
printf("%u\n", a); // 4294967168
return 0;
}
第一个代码 ,-128 在经过赋值时的截取与格式符识别时的扩展后,得到的二进制数据为11111111 11111111 11111111 10000000,此时以无符号整数%u 的方式去识别,没有符号位,那这个就是原码,所以得到结果为 4294967168。
第二个代码,128,经过截取之后得到10000000这个数据,实际上变成了-128,所以再经过格式符识别的扩展后,得到二进制数据11111111 11111111 11111111 10000000,此时同理可得,结果为 4294967168。
但是**如果用%d去识别,因为有符号位,**而且还是负数,此时就要取反再+1 得到原码,所以,此时得到的结果就为 -128。
5、练习4(求代码的输出结果)
cpp
#define _CRT_SECURE_NO_WARNINGS
#include <stdio.h>
int main()
{
char a[1000];
int i;
for (i = 0; i < 1000; i++)
{
a[i] = -1 - i;
}
printf("%d", strlen(a));
return 0;
}
详细分析:
(1)char 类型的循环特性
char 是 8 位有符号类型,取值范围是 -128 ~ 127(共 256 个值)。当赋值超出这个范围时,会发生循环溢出。
初始值:i=0 时,a0 = -1 - 0 = -1;
随着 i 增加,ai 的值依次为 -2, -3, ..., -128
当 i=128 时,a128 = -1 - 128 = -129,溢出后循环为 127;因为-129 的补码为11111111 11111111 11111111 01111111,当存入 8 位 char 时,**仅保留最低 8 位:**01111111。
继续增加 i,值会从 127 逐渐减小到 0,当 i=255 时,a255 = -1 - 255 = -256,溢出后为 0
(2)strlen 函数的计数规则
strlen 用于计算字符串长度,它从起始位置开始计数,直到遇到第一个值为 0 的字符('\0')时停止,且不包含这个 0 字符。
(3)后续元素不影响结果
虽然数组 a 有 1000 个元素,但 strlen 一旦遇到 a255 的 0 就会停止计数,后面的元素不会被统计。
6、练习5(求代码输出的结果)
cpp
#define _CRT_SECURE_NO_WARNINGS
#include <stdio.h>
unsigned char i = 0;
int main()
{
for (i = 0; i <= 255; i++)
{
printf("hello world\n");
}
return 0;
}
cpp
#define _CRT_SECURE_NO_WARNINGS
#include <stdio.h>
int main()
{
unsigned int i;
for (i = 9; i >= 0; i--)
{
printf("%u\n", i);
}
return 0;
}第一个代码,因为unsigned char 的取值范围为 0~ 255,最大值无法突破 255,所以一到 256,就会面临数据位的溢出。256的二进制是100000000,unsigned char 只保留后8 位,就是 0 ,所以代码会一直无限循环下去。
第二个代码,因 为unsigned int 的取值范围为 0 ~ 4294967295,最小值不可能为负数,所以循环不可能停止,-1的补码是11111111 11111111 11111111 11111111,如果是被%u 无符号整型的格式符解析,那么就会变成 4294967295,最后就会轮回一般输出。

7、练习6(求代码输出的结果)
cpp
#define _CRT_SECURE_NO_WARNINGS
//X86环境 ⼩端字节序
#include <stdio.h>
int main()
{
int a[4] = { 1, 2, 3, 4 };
int* ptr1 = (int*)(&a + 1);
int* ptr2 = (int*)((int)a + 1);
// 或者写成(int*)((char*)a + 1)会更规范一点,这样x64环境也可以运行
printf("%x\n%x", ptr1[-1], *ptr2);
return 0;
} 输出结果分析(小端字节序下):
输出结果分析(小端字节序下):
(1)ptr1-1 的值
&a 是数组的地址,类型为 int(*)4,&a + 1 会跳过整个数组,指向数组末尾的下一个位置。此时将它强转为 int* 类型,赋值给指针变量 ptr 。
ptr1 是指向该位置的 int* 指针,ptr1-1 等价于 *(ptr1 - 1),即数组的最后一个元素 4。
(2)*ptr2 的值
先解释一下,为什么一定要在x86环境下运行。
(int)a + 1 的逻辑是:先把数组首地址(如 0x12345678)转成 int 类型的 12345678,再加 1 得到 12345679,最后强转回 int* 指向地址 0x12345679
这和 (char*)a + 1 的 "跳过 1 字节" 效果在 32 位系统下完全一致 ,所以看似 "能成功运行"。
如果在x64环境下,也就是64位的环境下,int 依然是 4 字节(32 位),但指针(int*)是 8 字节(64 位)。此时 (int)a 会发生数据截断。
假设数组首地址是 0x12345678 9abcdef0(64 位地址),转成 int 后会丢失高 32 位,变成 0x9abcdef0(仅保留低 32 位),编译器会直接报错。
a 是数组首地址(int*),转换为 int 后加 1,指向数组第一个元素的第二个字节。
小端字节序中,1 的存储形式是 01 00 00 00(十六进制),从第二个字节开始取 4 个字节是 00 00 00 02(结合第二个元素 2 的首字节)。
这 4 个字节作为 int 解析是 0x2000000(十六进制)。
但是还是不建议((int)a + 1);这种写法,即便 C 语言标准允许指针与整数的强制转换,但有一个前提:整数类型的宽度必须能容纳指针的所有位。在64位环境下容纳不了,所以它就是编译失败了,更通用的写法,还是((char*)a+1)
三、浮点数在内存中的存储
(一)浮点数与整数的存储差异(直观示例)
1、示例代码
cpp
#define _CRT_SECURE_NO_WARNINGS
#include <stdio.h>
int main()
{
int n = 9;
float* pFloat = (float*)&n;
printf("n的值为:%d\n", n);
printf("*pFloat的值为:%f\n", *pFloat);
*pFloat = 9.0;
printf("num的值为:%d\n", n);
printf("*pFloat的值为:%f\n", *pFloat);
return 0;
}
2、差异结论
浮点数与整数的存储规则完全不同:整数用 "二进制补码" 存储,浮点数用 "IEEE 754 标准" 存储,即使内存中二进制序列相同,按不同类型解析会得到完全不同的结果。
关键是不要进行跨类型存取,如果整数地址用浮点数指针读,会导致数据解析错误,仅同类型存取(如float存→float读)结果正确。
**(二)**浮点数的存储规则:IEEE 754 标准
1、浮点数的二进制表示(核心公式)
IEEE 754 标准规定,任意二进制浮点数 V 可表示为:

2、存储结构
| 浮点数类型 | 总比特数 | 符号位(S) | 指数位 (E) (阶码) | 有效数字位 (M) (尾数) | 偏置值 |
|---|---|---|---|---|---|
| float(单精度) | 32 | 1(第 31 位) | 8(第 30~23 位) | 23(第 22~0 位) | 127 |
| double(双精度) | 64 | 1(第 63 位) | 11(第 62~52 位) | 52(第 51~0 位) | 1023 |

3、将二进制数据转化位浮点数的形式(存)

(1)规格化
将转换过来的二进制数字,转化为 **" M × ",**其中保证 M 大于1,同时小于 2。
初始的E为0,E成为阶码真值,M小数点后的数字称为尾数。尾数向右移动一位,阶码真值就加1;尾数向左移动一位,阶码真值就减一。
(2)计算阶码
首先确定偏置值,以32位浮点数为例,有8位阶码,那么它的偏置值就是 01111111;64位的浮点数有11位阶码,那它的偏置值就是 01111111111。
阶码真值就是 E 的值,将偏置值与阶码真值相加,那么最后得到的就是阶码。
(3)对该数进行存储
如果是一个正数,则符号位为0;如果是一个负数,则符号位为1;阶码由第二步得到;第一步得到的尾数,如果不符合尾数的尾数,则在右边补 0 即可。
4、将浮点数转化为真实数据(取)
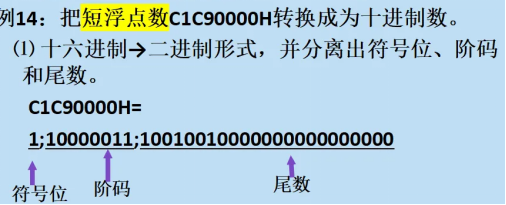

(三)取浮点数的两种特殊情况
1、阶码(E)为全 0
此时不表示常规的规格化浮点数,而是非规格化数(denormalized number),用于表示接近 0 的极小值,规则如下:
**(1)阶码真值:**固定为 "1 - 偏置值"(单精度偏置值 127,因此真值 = 1 - 127 = -126);
**(2)尾数(M):**不再隐含整数位 "1",而是直接表示 "0.M"
(3)整体值: × ( 0.M ) ×
(S 为符号位)。

2、阶码(E)为全 1
此时用于表示无穷大(∞) 或非数值(NaN),规则如下:

(四)浮点数应用案例
1、第一个环节
下面,让我们回到一开始的练习。
先看第一个环节,为什么 9 还原成浮点数,就成了 0.000000?
首先 9 以整型的形式存储在内存中,得到如下二进制序列:
0000 0000 0000 0000 0000 0000 0000 1001
接着,将 9 的二进制序列按照浮点数的形式拆分,得到第⼀位符号位 s=0,后面8位的阶码为
E = 00000000。
最后 23 位的尾数为M=000 0000 0000 0000 0000 1001。由于指数 E 全为 0 ,所以符合 E 为全 0 的情况。因此,浮点数V就写成:
×0.000 0000 0000 0000 0000 1001 ×
= 1.001 ×
2、第二个环节
再看第二个环节,浮点数为9.0,为什么整数打印得到的是 1091567616?
我们将浮点数 9.0 存储到内存中,得到的二进制数据为:0 10000010 001 0000 0000 0000 0000 0000。这个32位的⼆进制数据,被当做整数来解析的时候,正是 1091567616 。
(五)浮点数的精度问题与比较规范
1、精度问题现象
**代码:**float f = 38.8; printf("f = %.6f \n", f); → 输出 f = 38.799999(非38.8)。
**原因:**38.8 的十进制小数无法精确转换为二进制小数。二进制38.8 = 100110.1100110011... (循环小数),float 的 M 仅 23 位,截断后存在误差。
2、浮点数比较规范
禁止直接用 **" == "**判断相等:因精度误差,38.8f == 38.8可能返回false。
**38.8f:**后缀 f 明确指定它是单精度浮点数(float 类型),在内存中占用 4 个字节。
**38.8:**未加后缀时,在大多数编程语言(如 Java、C++、Python 等)中默认是双精度浮点数(double 类型),占用 8 个字节。
当执行 == 比较时,先会进行类型转换,通常是将占字节更少的 float 转换为 double,再比较转换后的二进制值 ------ 而问题就出在 "转换" 和 "二进制表示" 上。
由于 float 本身的精度有限,转换为 double 时,它的 "近似误差" 会被 保留,相当于在 float 近似值的后面补 0,无法恢复被截断的二进制位。而原生 38.8(double)的误差更小,两者的二进制值因此出现微小差异,最终 == 比较判定为 false。
我们可以通过绝对误差法来避免这个问题,即判断两数差值的绝对值是否小于 "可接受误差"(如1e-4,即1 × ,为0.0001)。
cpp
#define _CRT_SECURE_NO_WARNINGS
#include <math.h>
#include <stdio.h>
int main() {
float f = 38.8f;
// 若差值绝对值 < 1e-4,认为相等
if (fabs(f - 38.8) < 1e-4) {
printf("f == 38.8\n");
} else {
printf("f != 38.8\n");
}
return 0;
}
**函数说明:**fabs(x) 用于计算浮点数 x 的绝对值(abs(x)用于整数),需包含 math.h 头文件。
以上即为 数据在内存中的存储 的全部内容,麻烦三连支持一下呗~
