只适用于YOLO26 目标检测,比较简略,我认为有问题可以直接问GPT,可以给出完美答案
截至2026年1月23日的最新版本,并不感觉YOLO26比YOLO11强
K230用的是嘉立创的,屏幕也是嘉立创的,经我研究好像幻尔的也能用
推荐阅读以下官方网址
使用 Ultralytics YOLO 进行模型训练 - Ultralytics YOLO 文档
立创·庐山派K230-CanMV开发板【介绍】 | 立创开发板技术文档中心
Hiwonder-课程-CanMV K230 AI开发板 提取码:un33
1.训练
没有任何需要教的,如果你连这都不会你。。。。
from ultralytics import YOLO
# Load a model
model = YOLO("yolo26n.pt") # load a pretrained model (recommended for training)
if __name__ == '__main__':
# Train the model
results = model.train(data="mydata.yaml",batch=0.9 ,epochs=100, imgsz=320)上述代码和官方的没有本质上的区别,mydata.yaml换成你自己的
2.模型转换
2.1先转换成ONNX
from ultralytics import YOLO
# 加载模型
model = YOLO('runs/detect/train26/weights/best.pt')
# 导出为ONNX格式
model.export(format='onnx', imgsz=(320, 320),dynamic=False,simplify=True,nms=False)
# 可选:验证导出是否成功
import onnx
onnx_model = onnx.load('runs/detect/train26/weights/best.onnx')
onnx.checker.check_model(onnx_model)
print(f"模型已成功导出为ONNX格式: best.onnx")上面训练运行完之后会告诉你模型的地址,加载模型的地址自己换。
2.2kmodel转换
你会发现在官方转换示例里面,YOLOV8和YOLO11一的完全一样,所以你看哪一个都一样,仅限于目标检测!!!但其实你会发现8和11检测的代码通用
K230 YOLO 大作战 --- CanMV K230请直接参考这里面的步骤
此处有一个特别大的雷点,ONNX的版本要足够的低,直接pip install onnx安装是不行的!!! 推荐ONNX=1.12.0,在运行模型转换的时候会有一个警告(warming)你可以直接无视掉

还有一个大雷点,这个test文件夹,建议放点你训练模型的验证集照片进去,放上个四五十张,不然好像会导致是不出的结果置信度偏低(实测),会直接影响置信度最大数值。我指的test文件夹是下载脚本工具,将模型转换脚本工具。。。。里面的
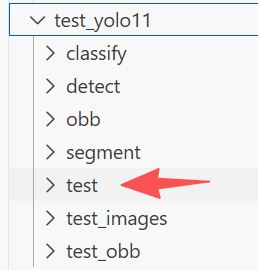
当然我选择与众不同,不用官方的命令行,我就用Python文件,请注意文件路径
import subprocess
import sys
# =======================
# 配置区
# =======================
TARGET = "k230"
MODEL = "runs/detect/train26/weights/best.onnx"
DATASET = "test_yolo11/test"
INPUT_WIDTH = 320
INPUT_HEIGHT = 320
PTQ_OPTION = 0
def run_to_kmodel():
cmd = [
sys.executable,
"test_yolo11/detect/to_kmodel.py",
"--target", TARGET,
"--model", MODEL,
"--dataset", DATASET,
"--input_width", str(INPUT_WIDTH),
"--input_height", str(INPUT_HEIGHT),
"--ptq_option", str(PTQ_OPTION),
]
print("Running command:")
print(" ".join(cmd))
print("=" * 60)
result = subprocess.run(cmd)
if result.returncode != 0:
print("❌ to_kmodel.py 执行失败")
else:
print("✅ to_kmodel.py 执行成功")
if __name__ == "__main__":
run_to_kmodel()3.用
问了一大堆AI终于整出来了它的重点是在于它没有nms,
main.py代码如下,代码是根据幻尔的YOLOV8的魔改,kmodel_path和labels自己改
"""
YOLO26 目标检测应用 --- 适配 K230 + nncase_runtime + LCD 显示
功能:
1. 使用摄像头捕获图像
2. 使用 YOLO26 kmodel 推理检测目标
3. 在 LCD OSD 层上绘制检测结果
4. 显示处理后图像并打印 FPS
"""
from libs.PipeLine import PipeLine, ScopedTiming
from libs.AIBase import AIBase
from libs.AI2D import Ai2d
from media.media import *
from media.sensor import *
from media.display import Display
import nncase_runtime as nn
import ulab.numpy as np
import time
import gc
# ===================== 显示管理 =====================
def deinit_display():
"""显示资源释放"""
Display.deinit()
print("Display deinitialized")
# ===================== YOLO26推理类 =====================
class ObjectDetectionApp(AIBase):
"""
YOLO26目标检测应用类
负责:模型推理 + 后处理 + 显示绘制
"""
def __init__(self, kmodel_path, labels, model_input_size,
max_boxes_num=50, confidence_threshold=0.25,
nms_threshold=0.45,
rgb888p_size=[320,320],
display_size=[800,480],
debug_mode=0):
# 父类初始化,负责 AI 运行时加载模型
super().__init__(kmodel_path, model_input_size, rgb888p_size, debug_mode)
# ----------------- 参数存储 -----------------
self.labels = labels # 类别标签
self.confidence_threshold = confidence_threshold
self.nms_threshold = nms_threshold
self.max_boxes_num = max_boxes_num
self.rgb888p_size = rgb888p_size # AI 输入图像大小
self.display_size = display_size # 显示屏大小
self.debug_mode = debug_mode
# 原图 -> 模型输入 缩放系数
self.x_factor = float(rgb888p_size[0]) / model_input_size[0]
self.y_factor = float(rgb888p_size[1]) / model_input_size[1]
# ----------------- Ai2D预处理配置 -----------------
self.ai2d = Ai2d(debug_mode)
self.ai2d.set_ai2d_dtype(nn.ai2d_format.NCHW_FMT,
nn.ai2d_format.NCHW_FMT,
np.uint8,
np.uint8)
self.ai2d.resize(nn.interp_method.tf_bilinear,
nn.interp_mode.half_pixel)
self.ai2d.build([1,3,rgb888p_size[1],rgb888p_size[0]],
[1,3,model_input_size[1],model_input_size[0]])
# 检测框颜色表(循环使用)
self.color_table = [
(255,0,0,255), (255,0,255,0), (255,255,0,0),
(255,255,255,0), (255,0,255,255)
]
# ===================== 后处理 =====================
def postprocess(self, results):
"""
YOLO26 后处理
功能:解析模型输出预测框 -> 转换为绝对坐标列表,不做 NMS
"""
with ScopedTiming("postprocess", self.debug_mode > 0):
# 模型输出取第0个张量
output = results[0]
# 将输出 reshape 为 2 维矩阵 [num_preds, features]
try:
total_elems = output.size
last_dim = output.shape[-1]
new_rows = total_elems // last_dim
out = output.reshape((new_rows, last_dim))
except Exception as e:
print("postprocess reshape 失败:", e)
return []
# 输出必须至少包含 6维:x1,y1,x2,y2,score,class
if out.shape[-1] < 6:
print("模型输出 shape 不符合要求:", out.shape)
return []
dets = []
for det in out:
score = float(det[4])
# 置信度过滤
if score < self.confidence_threshold:
continue
# 原始框坐标
x1, y1, x2, y2 = float(det[0]), float(det[1]), float(det[2]), float(det[3])
class_id = int(det[5])
# 如果是归一化坐标 (0~1),需要映射回 RGB 图像尺寸
if 0.0 <= x1 <= 1.0 and 0.0 <= y1 <= 1.0 and \
0.0 <= x2 <= 1.0 and 0.0 <= y2 <= 1.0:
x1 = int(x1 * self.rgb888p_size[0])
y1 = int(y1 * self.rgb888p_size[1])
x2 = int(x2 * self.rgb888p_size[0])
y2 = int(y2 * self.rgb888p_size[1])
else:
# 否则假设已是绝对像素坐标
x1, y1, x2, y2 = int(x1), int(y1), int(x2), int(y2)
# 存入列表
dets.append([x1, y1, x2, y2, score, class_id])
# 若无检测结果则返回空
if len(dets) == 0:
return []
return np.array(dets)
# ===================== 绘制检测结果 =====================
def draw_result(self, pl, dets):
"""
在 OSD 图层绘制检测框 + 标签
参数:
pl: Pipeline 对象
dets: 后处理返回的检测列表
"""
pl.osd_img.clear()
for det in dets:
x1,y1,x2,y2,score,cls = det
color = self.color_table[int(cls) % len(self.color_table)]
# 坐标映射到显示屏尺寸
x = int(x1 * self.display_size[0] / self.rgb888p_size[0])
y = int(y1 * self.display_size[1] / self.rgb888p_size[1])
w = int((x2 - x1) * self.display_size[0] / self.rgb888p_size[0])
h = int((y2 - y1) * self.display_size[1] / self.rgb888p_size[1])
# 绘制矩形框
pl.osd_img.draw_rectangle(x, y, w, h, color=color, thickness=6)#thickness可以修改这个框的粗细
# 绘制文字标签:类别 + 置信度
label = "%s %.2f" % (self.labels[int(cls)], score)
pl.osd_img.draw_string_advanced(x, y - 50, # 文本位置(框上方)
32, # 字体大小
label, # 文本内容
color=color) # 文本颜色
# ===================== 主程序入口 =====================
if __name__ == "__main__":
try:
# 初始化 LCD 显示
Display.init(Display.ST7701, width=800, height=480, to_ide=False)
display_size = [800,480]
rgb888p_size = [320,320]
# 构建处理管线:RGB 图像 → 模型输入 → 显示
pl = PipeLine(rgb888p_size=rgb888p_size,
display_size=display_size,
display_mode="st7701")
pl.create(Sensor(width=1920, height=1080))
# 模型路径 & 类别标签 (请替换为你的实际类别)
kmodel_path = "/sdcard/best.kmodel"
labels = ["relay","openmv","dcdc","motor","stm32","oled","ultrasound","servo"]
# 创建 YOLO26 对象
ob = ObjectDetectionApp(kmodel_path,
labels=labels,
model_input_size=[320,320],
max_boxes_num=50,
confidence_threshold=0.25,
nms_threshold=0.45,
rgb888p_size=rgb888p_size,
display_size=display_size)
clock = time.clock()
# 主循环:持续检测 + 显示
while True:
clock.tick()
img = pl.get_frame() # 获取当前帧
res = ob.run(img) # 模型推理 + 后处理
ob.draw_result(pl, res) # 绘制检测结果
pl.show_image() # 显示画面
print("FPS:",clock.fps())
gc.collect()
finally:
deinit_display()