1. 项目背景
随着人们生活水平的提高,旅游已成为大众休闲娱乐的重要方式。然而,面对海量的旅游景点信息,用户往往难以快速找到符合个人兴趣的目的地。传统的旅游信息网站多采用静态展示或简单的关键词搜索,缺乏针对用户的个性化服务。
本项目旨在构建一个基于Web的旅游推荐系统 ,利用Python Django框架作为后端开发基础,结合大数据处理与深度学习(机器学习)算法,对旅游景点数据进行深度挖掘与分析,实现个性化的景点推荐,提升用户体验,帮助用户更高效地制定出行计划。
演示视频及代码资料下载:https://www.bilibili.com/video/BV1nXzKBUEcP

配套论文
配套PPT
2. 技术架构
本系统采用 B/S(Browser/Server)架构,前后端分离或模板渲染模式开发。
- 后端开发框架:Python + Django 2.0
- 数据存储:MySQL (业务数据)
- 数据爬取:Scrapy / Requests + Lxml
- 数据分析与推荐:实现KMeans聚类、逻辑回归等
- 前端技术:HTML, CSS, JavaScript, Vue.js (或JQuery), ECharts (可视化)
- 开发环境:Windows/Linux, PyCharm, Navicat
系统架构图
- 数据层:Scrapy爬虫抓取各大旅游网站数据(如携程、去哪儿),清洗后存入MySQL数据库。
- 处理层:读取MySQL数据,进行特征提取、模型训练(如聚类分析用户偏好、景点相似度计算),将结果回写至数据库或生成JSON文件。
- 应用层:Django处理HTTP请求,包括用户管理、景点展示、评论互动、推荐接口调用等。
- 展示层:前端页面展示景点列表、详情、推荐结果及数据可视化大屏。
3. 数据库设计
系统核心数据表包括用户表、景点表、旅游路线表等。以下是主要表的简要设计:
3.1 用户表 (yonghu)
用于存储注册用户的信息。
| 字段名 | 类型 | 描述 |
|---|---|---|
| id | BigInteger | 主键 |
| zhanghao | Varchar | 账号 |
| mima | Varchar | 密码 |
| xingming | Varchar | 姓名 |
| shouji | Varchar | 手机号 |
| touxiang | Text | 头像URL |
| addtime | DateTime | 注册时间 |
3.2 景点表 (jiangxijingdian)
存储爬取或录入的景点详细信息。
| 字段名 | 类型 | 描述 |
|---|---|---|
| id | BigInteger | 主键 |
| poiname | Varchar | 景点名称 |
| cover | Text | 封面图片 |
| jiage | Float | 门票价格 |
| heatscore | Float | 热度评分 |
| commentscore | Float | 评论评分 |
| tags | Varchar | 标签(如:山水、人文) |
| clicknum | Integer | 点击/浏览次数 |
| storeupnum | Integer | 收藏数 |
| clicktime | DateTime | 最近点击时间(用于推荐) |
3.3 收藏表 (storeup)
记录用户的收藏行为,用于后续的兴趣分析。
| 字段名 | 类型 | 描述 |
|---|---|---|
| userid | BigInteger | 用户ID |
| refid | BigInteger | 关联商品/景点ID |
| type | Varchar | 类型(1:收藏, 21:赞, 22:踩等) |
4. 系统实现
本系统采用了Python和Mysql相结合的结构,以及基于客户端管理模式即B/S模式,设计开发了这款基于DJANGO框架的旅游推荐系统。在配置文件中添加了编码方式来解决代码中中文的问题,本系统的设计开发,将CSS代码写在一个文件夹中,这样每个网页设计时,可以直接调用,既省时又省力。编写代码时,可以一边看着设计界面,一边编写CSS样式,为设计开发过程减轻了负担。
5.1系统前台功能实现
系统首页为用户提供江西旅游的核心信息与便捷入口。其中,"江西景点"模块集中展示江西的热门景点,如庐山、滕王阁等,方便用户快速了解;"江西旅游"提供旅游攻略、推荐线路等综合信息,助力用户规划行程;"个人中心"则是用户管理个人资料、收藏及偏好设置的专属空间,提升个性化体验。系统首页页面如图5-1所示:
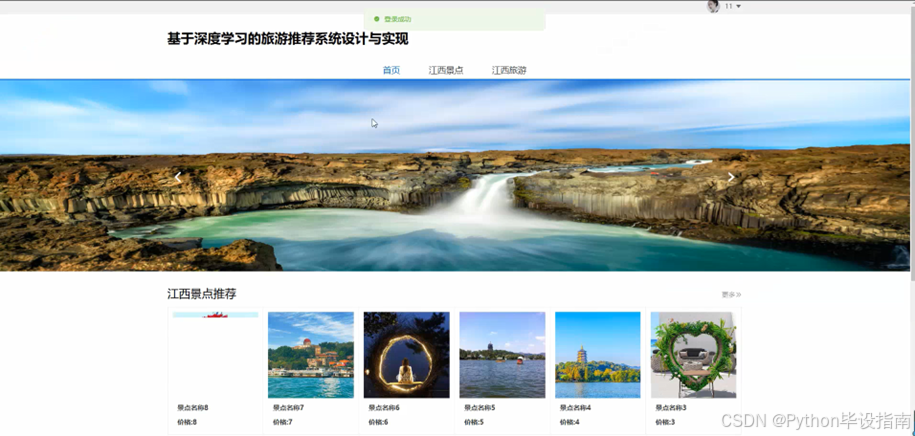
图5-1系统首页页面
在基于深度学习的旅游推荐系统中,个人中心功能为用户提供便捷的个性化服务。用户可以在此修改密码,确保账户安全。旅游路线规划功能根据用户偏好和历史行为,利用深度学习算法生成定制化路线。我的收藏则方便用户保存心仪的旅游景点、酒店或攻略,方便随时查看,提升用户体验。个人中心页面如图5-2所示:
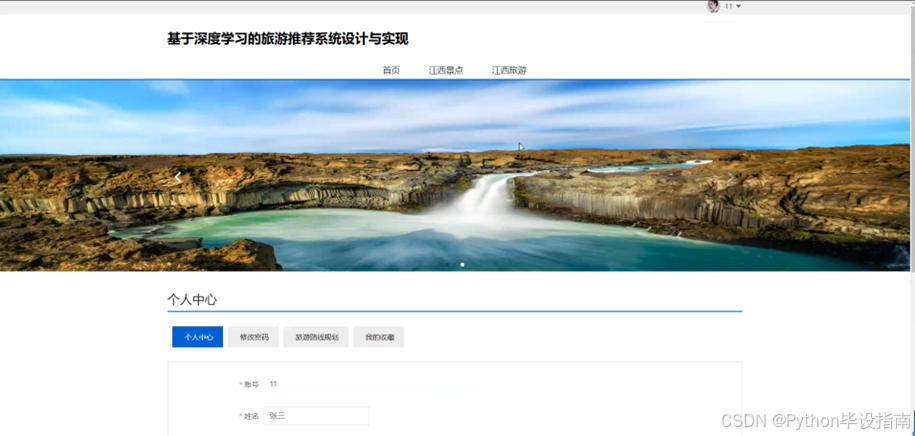
图5-2个人中心页面
5.2后台管理员功能实现
管理员主页面作为系统控制中心,提供全面的管理功能。页面通常详细列出所有管理模块,包括用户、江西景点、江西旅游、旅游路线规划、轮播图管理、个人中心等,确保管理员能够高效地进行日常管理工作。整个页面布局清晰,功能模块化,便于管理员快速定位和操作。管理员主界面如图5-3所示:

图5-3 管理员主界面
在旅游推荐系统中,管理员点击"用户管理"功能后,可输入用户姓名或性别进行精准查询。查询结果以列表形式展示用户信息,管理员可在此基础上查看用户详情、修改用户信息或删除用户记录。管理员还可通过此功能添加新用户,完善用户信息,确保用户数据的完整性和准确性,从而高效管理用户信息,提升系统管理效率。如图5-4所示:
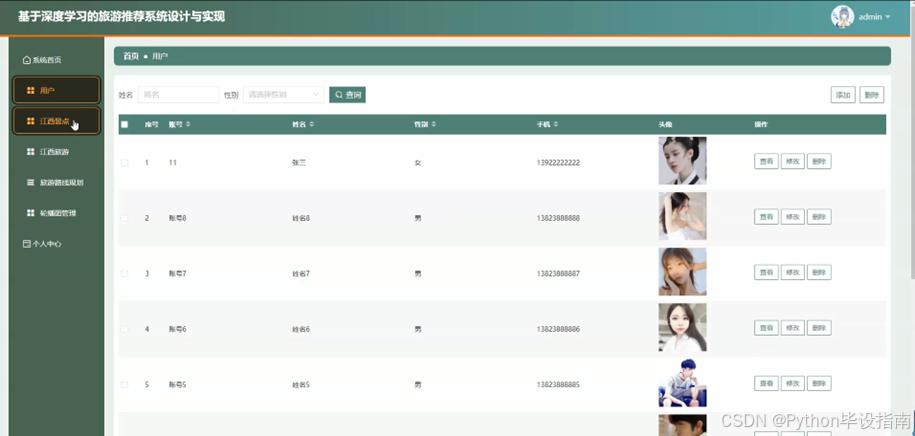
图5-4 用户界面
管理员点击"江西景点"功能后,可输入景点名称进行查询,系统会快速返回相关景点信息列表。管理员可在列表中查看景点详情,包括介绍、门票价格、开放时间等。管理员还可以添加新的景点信息,通过爬取数据功能从外部网站自动获取景点数据,或删除不再需要的景点记录。管理员能够修改景点信息,确保数据的准确性和时效性,为用户提供最新的旅游参考。如图5-5所示:
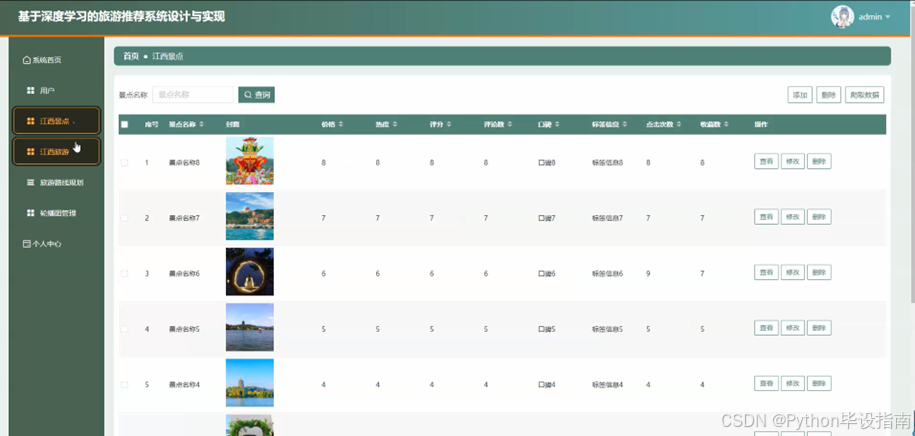
图5-5 江西景点界面
在旅游推荐系统中,管理员点击"江西旅游"功能后,可输入标题进行查询,系统会快速返回相关的江西旅游信息列表,包括旅游攻略、景点介绍、特色活动等内容。管理员可以查看详细信息,对现有内容进行修改或删除,以确保信息的准确性和时效性。管理员还可以通过系统添加新的江西旅游信息,或利用爬取数据功能从外部权威渠道获取最新的旅游资讯,丰富平台内容。如图5-6所示:
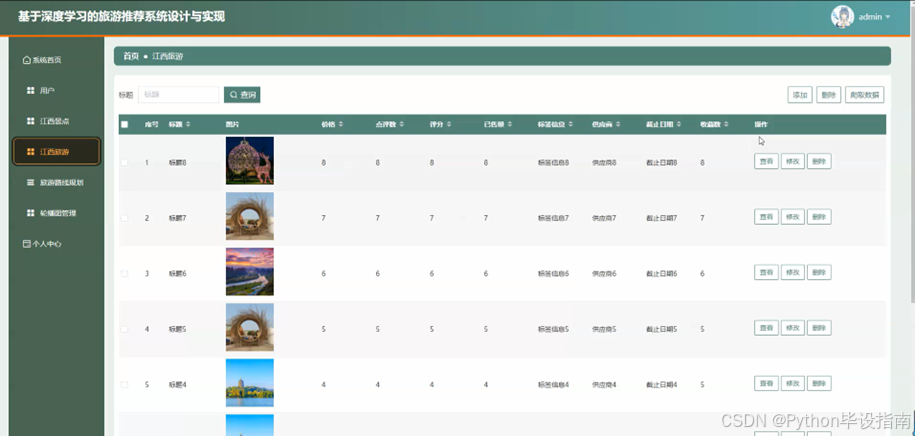
图5-6 江西旅游界面
管理员点击"旅游路线规划"功能后,可输入标题进行查询,系统会快速返回相关的旅游路线规划信息列表。管理员能够查看每条路线的详细内容,包括行程安排、景点顺序、预计时间等。管理员可以添加新的路线规划,通过爬取数据功能从外部获取热门路线信息,丰富系统内容。管理员还可以修改现有路线信息或删除不再适用的路线,确保旅游路线规划的实用性和时效性。如图5-7所示:
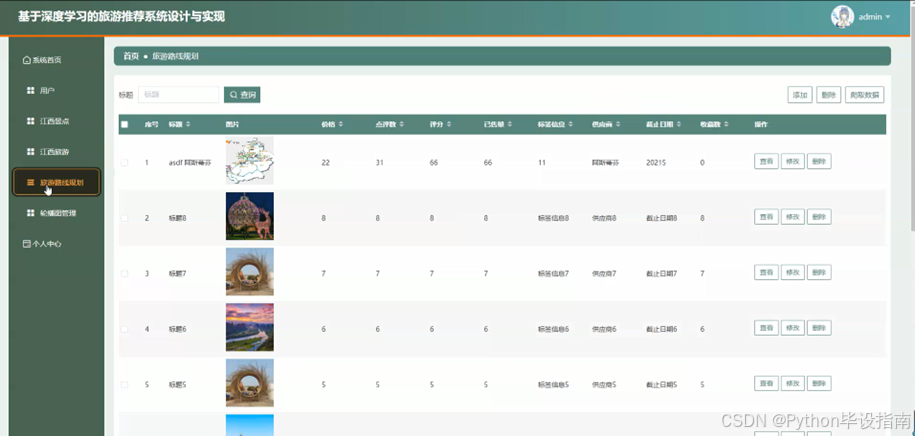
图5-7 旅游路线规划界面
管理员点击"看板"功能后,将进入一个数据可视化界面,直观展示江西旅游的核心业务数据。看板上可查看团游价格、江西景点总数、各景点门票价格、景点热度排名、景点评论数量与趋势、江西旅游攻略总数、热门旅游路线、团游评论情况以及团游的销售数据等。这些数据以图表和数字形式呈现,帮助管理员快速掌握业务动态,为决策提供数据支持。如图5-8所示:
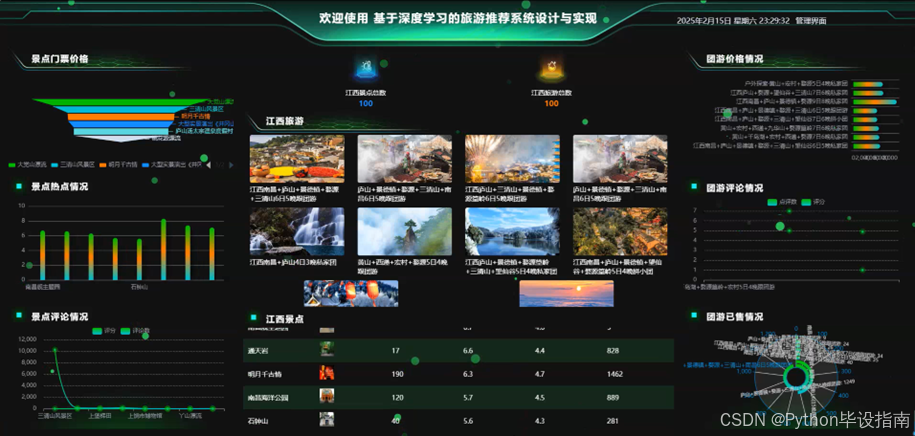
图5-8看板界面
5. 关键代码
5.1 聚类分析
使用 PySpark 进行 KMeans 聚类,这可用于发现相似类型的景点,用于"看了又看"等推荐功能。
from pyspark.ml.clustering import KMeans
from pyspark.sql import SparkSession
def cluster(table_name):
'''
Spark KMeans 聚类分析
:param table_name: 数据表名
:return: 聚类中心
'''
spark = SparkSession.builder.appName("flask").getOrCreate()
# 读取数据(假设已格式化为libsvm或向量格式)
dataset = spark.read.format("libsvm").table(table_name)
# 训练 KMeans 模型,K=2
kmeans = KMeans().setK(2).setSeed(1)
model = kmeans.fit(dataset)
# 获取聚类中心
centers = model.clusterCenters()
for center in centers:
print(center)
return centers5.2 推荐排序接口 (main/Jiangxijingdian_v.py)
Django 视图函数,处理前端的推荐请求。这里展示了基于点击量 (clicknum) 和浏览时间 (clicktime) 的混合推荐逻辑。
def jiangxijingdian_autoSort(request):
'''
智能推荐功能:
如果有 web 浏览数据,根据 clicknum (点击次数) 或 clicktime (最近点击) 进行排序推荐。
'''
if request.method in ["POST", "GET"]:
msg = {"code": normal_code, "msg": "success", "data":{"list":[]}}
req_dict = request.session.get("req_dict")
# 获取所有列名
columns = jiangxijingdian.getallcolumn(jiangxijingdian, jiangxijingdian)
# 优先按点击次数倒序,其次按最近浏览时间
if "clicknum" in columns:
req_dict['sort'] = 'clicknum'
elif "browseduration" in columns:
req_dict['sort'] = 'browseduration'
else:
req_dict['sort'] = 'clicktime'
req_dict['order'] = 'desc'
# 调用分页查询方法获取推荐列表
msg['data']['list'], _, _, _, _ = jiangxijingdian.page(
jiangxijingdian, jiangxijingdian, req_dict
)
return JsonResponse(msg, encoder=CustomJsonEncoder)5.3 线性回归预测 (util/spark_func.py)
利用线性回归算法对数据进行拟合预测。
from pyspark.ml.regression import LinearRegression
def linear(table_name):
'''
线性回归分析
'''
spark = SparkSession.builder.appName("flask").getOrCreate()
training = spark.read.format("libsvm").table(table_name)
lr = LinearRegression(maxIter=20, regParam=0.01, elasticNetParam=0.6)
lrModel = lr.fit(training)
trainingSummary = lrModel.summary
print(f"RMSE: {trainingSummary.rootMeanSquaredError}")
print(f"r2: {trainingSummary.r2}")
return trainingSummary.residuals.toJSON()6. 总结与展望
本项目成功设计并实现了一个基于 Django 和 旅游推荐系统。
- 整合了大数据的能力:系统具备了处理大规模旅游数据的潜力,不再局限于简单的 CRUD 操作,引入了机器学习算法(聚类、回归)来挖掘数据价值。
- 全栈开发实践:涵盖了从爬虫数据采集、数据库设计、后端 API 开发到前端展示的完整流程。
- 实用性:推荐算法虽然基础,但结合了用户的点击和收藏行为,能够有效解决"信息过载"问题,提供热门和个性化的景点建议。
未来展望:
- 算法优化:目前主要依赖统计和基础 ML 算法,未来可以引入协同过滤 (Collaborative Filtering, ALS) 或基于内容的深度神经网络推荐 (DNN),进一步提高推荐准确率。
- 实时性:实现实时的用户行为分析与推荐。
- 界面交互:引入更丰富的前端交互框架(如 Vue3 + Vite),提升用户体验。
演示视频及代码资料下载:https://www.bilibili.com/video/BV1nXzKBUEcP****