目录
- [1. MCTS](#1. MCTS)
- [2. AlphaZero](#2. AlphaZero)
-
- [Value Head 价值头](#Value Head 价值头)
- [Policy Head 策略头](#Policy Head 策略头)
- [3. 训练](#3. 训练)
好吧,训了几轮,发现结果不是很理想。
失败案例:
- 黑棋学会开局连五后,白棋不会堵,直接放弃
- 一直训某一种开局,换个开局就不会下了
- (重要)训练效率低下,啥都没学到
所以还是好好准备一下,搞一个优秀的架构和训练体系。
新代码还没开始写,就纯讲讲思路。
1. MCTS
对抗搜索中比较优秀的方法就是 MCTS 蒙特卡洛树搜索。
首先 MCTS 搜索树上每个节点要存:
- Q Q Q:平均胜率
- N N N:访问次数
一开始搜索树是空的,怎么办呢,这时候就需要进行 Playout,模拟一些对局。
假装现在我们拿到了一个搜索树的叶子节点,且这个点对于的局面还没结束,我们就需要进行拓展 Expand ,那问题来了,怎么知道新的叶子节点的胜率是多少呢?一种方法就是直接随机下几百盘即可,这个叫 Rollout。
那问题又来了,我们要扩展哪些叶子呢,扩展所有的叶子就会指数爆炸,怎么办呢。
然后就是 MCTS 的精髓,每个点会有一个分数 Score 表示这个子树值不值得探索,计算公式:
- Exploitation 利用:即为已有的胜率 Q Q Q。
- Exploration 探索:有些点都没搜过几次, Q Q Q 值也很低,但是可能只是探索过少了,其实胜率很大,所以分数要加上这个值,这个探索值叫 U U U,计算公式:
U = ∑ N N + 1 U = \frac{\sqrt{\sum N}}{N + 1} U=N+1∑N
最后的分数即为 S c o r e = Q + U ⋅ C Score = Q+U \cdot C Score=Q+U⋅C,其中 C C C 为探索因子, C C C 越大 MCTS 就越倾向于探索未知子树。
然后每次 Playout 就从根开始,在一个非叶节点上,贪心选 Score 最大的儿子进行探索,然后扩展叶子,最后别忘了返回根,更新 Q Q Q 和 N N N。
在 Playout 了几千次后,就改选出下一步下什么了,注意现在不是选择 Score 最大的儿子了,而是选择探索次数 N N N 最大的儿子。
此时已经可以解决一些简单博弈。
但是随机 Rollout 的效率其实很低,每次要探索的点非常多,需要引入更强的方法!
2. AlphaZero
AlphaZero 和 AlphaGo 都是 Deepmind 研发的,这里简单讲讲历史:
- AlphaGo Lee (2016) 以 4:1 的比分战胜李世石。
- AlphaGo Master (2017) 以 3:0 的比分战胜柯洁。
- AlphaGo Zero (2017) 此 AI 不再需要任何人类棋谱,仅靠自对弈 Self-play 进行自博弈。
今天这里讲的就是不需要人类棋谱,仅靠自对弈训练的 AI。
Value Head 价值头
Rollout 效率和正确率比较感人,考虑直接把棋盘信息丢给深度神经网络,得到新叶子的胜率。
为了方便,其中这里的胜率是 − 1 , 1 -1, 1 −1,1 的。
但是这样还不够......
Policy Head 策略头
人类下五子棋的时候,经常注重三连四连,要不要堵,之后的变化。而刚刚的 MCTS 会探索所有的位置,这明显不太优秀,所以引入一个策略头,告诉 MCTS 倾向于探索哪些位置。
神经网络还会丢出一个数组 P P P,表示先验概率,然后需要更新一下分数计算公式:
U = P ⋅ ∑ N N + 1 U = P \cdot \frac{\sqrt{\sum N}}{N + 1} U=P⋅N+1∑N
可以参考一下我自己画的一张图:
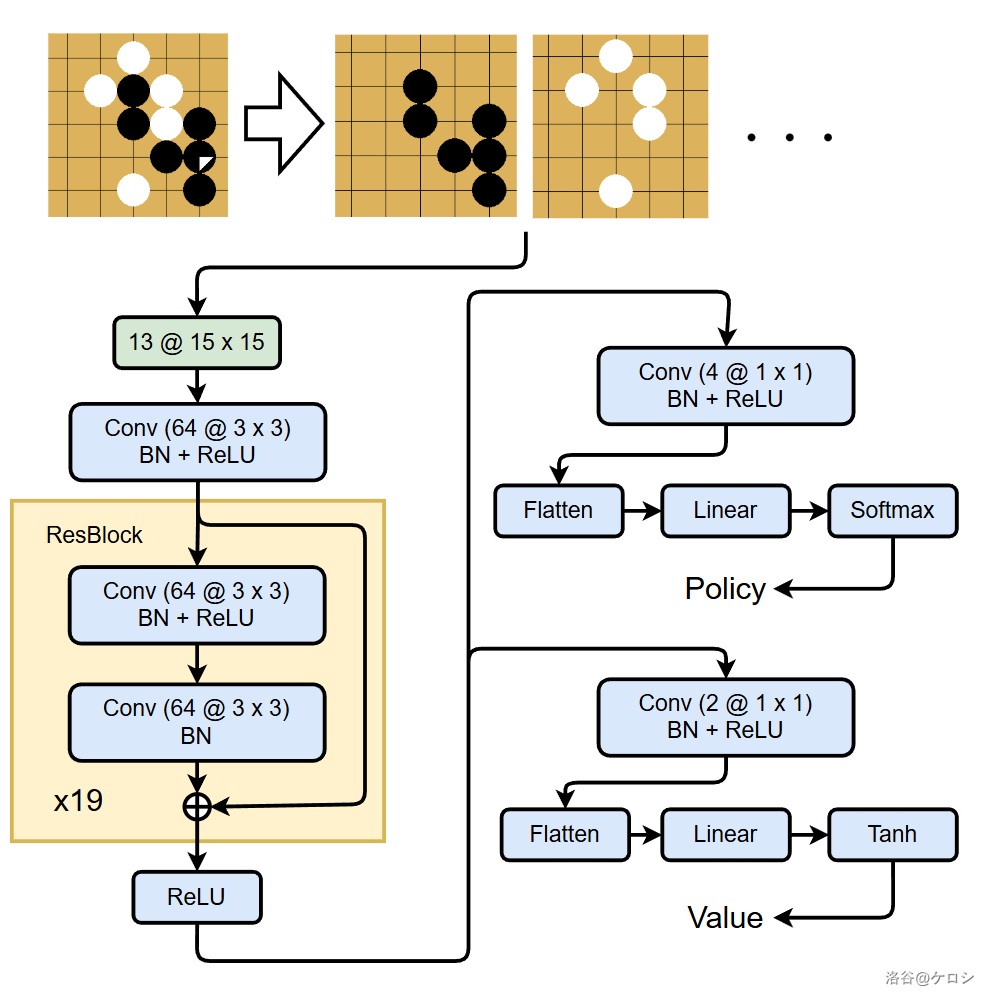
3. 训练
最重要的部分。
首先进行自博弈,获得一个对局。此时能获得局面的输赢,搞进神经网络里训练。
同时利用 MCTS 搜出来的 N N N,去训练策略,还要把 N N N 转化为动作概率:
π ( a ∣ s ) = N ( s , a ) 1 / τ ∑ b N ( s , b ) 1 / τ \pi(a|s) = \frac{N(s, a)^{1/\tau}}{\sum_{b} N(s, b)^{1/\tau}} π(a∣s)=∑bN(s,b)1/τN(s,a)1/τ
其中 τ \tau τ 是温度 Temperature。
然后策略头采用交叉熵,价值头采用平均方差。
然后是训练细节。
我们需要维护一个大概 1GB 的 dq?来存储一个叫做经验池 Replay Buffer 的东西,即一个新鲜的对局不要立马去训练,而是丢经经验池,训练更平稳且不会忘记过去的经验。这个过程叫经验回放。
然后我们还可以把一个棋盘进行八方向对称,获取八倍的数据集。
然后是我准备搞两个经验池,分别维护白赢和黑赢的局面,因为五子棋 freestyle 是黑棋必胜,为了让白棋也学会防守,两者赢的样本数要平均。
然后是高效率 Self-play ,我准备同时进行 128 个对局,把一个 128 的 Batch 丢进 GPU 里。
然后就是这些了,代码还没写,不知道能不能成功。。