前言:RAG 时代的"垃圾进,垃圾出"
在生成式 AI 的浪潮中,RAG(Retrieval-Augmented Generation,检索增强生成)已经成为了企业级大模型应用的"标配"。它像是在大模型(LLM)这个天才大脑旁边放了一座实时更新的图书馆,让模型能够突破预训练数据的时空限制,回答私有领域或最新发生的专业问题。
然而,很多开发者在搭建 RAG 系统时,往往将精力全部投入到大模型的参数微调或 Prompt Engineering(提示词工程)上,却忽视了系统底层的"基本功"。
什么是"垃圾进,垃圾出"?
在计算机科学领域,有一个经典的格言叫作 "Garbage In, Garbage Out"(简称 GIGO)。它的意思是:如果输入的数据是错误的、无序的或低质量的,那么无论你的处理算法(在这里是大模型)多么先进,最终得到的结果也必然是误导性的、无意义的"垃圾"。
在 RAG 的语境下,GIGO 现象表现得尤为明显:
- 如果你的文档切割(Chunking)极其粗糙,导致语义被生硬截断,模型就会读到一段"没头没脑"的文字;
- 如果你的向量数据库(Vector DB)索引配置不当,导致最相关的知识没能被召回,模型就会开始胡编乱造(幻觉)。
简而言之:检索的质量,直接决定了生成的质量。
RAG 的胜负手:切割策略与向量底座
要把 RAG 做好,必须处理好"数据加工"与"数据存储检索"的配合。
- 文档切割(Chunking)是前哨战: 它决定了知识被拆解的粒度。太粗(块太大)会导致干扰信息多,模型抓不住重点;太细(块太小)会导致丢失上下文,语义支离破碎。
- 向量数据库(以 Milvus 为例)是主战场: 它不仅是存储向量的容器,更是高性能检索的引擎。如何通过索引优化(Indexing)、标量过滤(Filtering)以及混合搜索(Hybrid Search)在毫秒级时间内从海量碎片的"知识海"中精准捞出那一枚"针",是技术落地的核心挑战。
本文核心内容预告
本文将深度结合 文档处理理论 与 Milvus 生产实践,为你揭开构建工业级 RAG 系统的技术细节。文章将涵盖以下核心章节:
- 深度解析切割原理: 从固定窗口到语义分块,探讨如何保留文档的"灵魂"。
- Milvus 实战指南: 如何设计高性能的 Collection Schema,并根据场景选择最佳索引。
- 工程化最佳实践: 针对 RAG 常见的痛点(如上下文丢失、检索不准),提供可落地的优化方案。
- 进阶架构: 探讨混合搜索(Hybrid Search)与重排(Reranking)如何进一步终结 GIGO 噩梦。
无论你是正在苦恼于 RAG 准确率不达标的算法工程师,还是希望了解 AI 基础设施架构的开发者,相信这篇博文都能为你提供系统性的启发。
第一章:文档切割(Chunking)的底层逻辑
在构建 RAG 系统时,初学者最容易犯的错误就是将整篇文档(如一个 50MB 的 PDF)直接一股脑儿地塞进数据库。然而,这种"暴力"的处理方式往往会导致系统性能低下甚至完全不可用。文档切割(Chunking)并不是一种无奈的妥协,而是一种为了优化检索效率和生成质量的必然选择。
1.1 为什么一定要切割?
1.1.1 LLM 上下文窗口的物理限制(Context Window)
尽管现代大语言模型(如 GPT-4, Claude 3, Gemini 1.5)的上下文窗口正在不断扩大,从早期的 8K、32K 演进到了现在的 128K 甚至 1M Tokens,但我们仍然不能忽视其物理限制:
- Token 溢出风险: 即使窗口很大,如果你有数千份长文档,也无法在一次 Prompt 中全部喂给模型。
- "迷失在中部"(Lost in the Middle)现象: 研究表明,模型对于长文本开头和结尾的信息提取效果最好,而位于文本中间的信息极易被忽略。通过精细切割,我们可以将最相关的知识片段精准地放置在 Prompt 的显著位置。
1.1.2 语义密度的稀释与"降噪"需求
Embedding(嵌入)的过程本质上是将一段文本压缩成一个固定维度的向量(例如 768 维或 1536 维)。
- 向量特征稀释: 当文本长度过长时(比如一万字),Embedding 模型会试图概括整篇文章的大意,从而导致局部的重要细节被"平均化"或淡化。就像将一整瓶浓缩果汁倒入一桶水中,味道会变得极其平淡。
- 语义精准度: 切割后的短小片段(Chunk)具有更高的语义密度。一个专门探讨"Milvus 索引算法"的片段,在向量空间中会比一篇涵盖了"数据库发展史、硬件演进、Milvus 架构、未来展望"的长文具有更清晰的坐标定位,从而更容易被检索算法命中。
1.1.3 显著降低计算成本与响应延迟
在生产环境中,RAG 的成本和性能(Latency)是核心指标:
- 推理成本: LLM 的计费通常基于 Token 数量。如果检索召回的内容过于冗长,每次对话都会消耗大量的 Token 费用。
- 检索速度: 处理极长文本的 Embedding 计算非常耗时。将文档预先切割并存入 Milvus,在查询时只需要对用户的一句提问(通常很短)进行向量化,这能将系统响应时间控制在毫秒级。
- 精度效率比: 较小的分块允许我们召回多个不同的知识片段(Top-K),这些片段可能来自不同的文档,从而拼凑出问题的完整答案,这比读取单一长文档的效率要高得多。
1.2 四种主流切割策略深度对比
不同的算法决定了数据进入向量数据库后的"形状"。以下是当前工业界最常用的四种方案:
1.2.1 固定大小切割(Fixed-size Chunking)
这是最简单、最原始的方法,即设定一个固定的字符数或 Token 数(如每 500 个字符一切)。
- 优点: 实现简单,计算成本极低,不依赖任何复杂的 NLP 模型。
- 缺点: 极度缺乏灵活性。它经常会在一句话的中途、一个专有名词的中间,甚至一个公式的中间强行截断,导致语义严重受损。
- 适用场景: 对性能要求极高、数据规范性极差且对语义要求不敏感的初步处理。
1.2.2 基于重叠的切割(Sliding Window / Overlap)
为了弥补固定大小切割带来的语义断裂,引入了 Overlap(重叠度) 的概念。例如,块大小为 500,重叠度为 50。这意味着块 2 会包含块 1 的最后 50 个字符。
- 为什么需要 Overlap?
- 防止关键信息丢失: 如果一个核心论点恰好在切分点上,重叠机制可以确保这个信息在两个相邻的块中都能保持相对完整。
- 维持上下文连贯: 给 Embedding 模型提供少量的上下文缓存,有助于生成更准确的向量表示。
- 适用场景: 绝大多数 RAG 系统的默认通用策略。
1.2.3 基于结构的切割(Recursive / Markdown Chunking)
这种方法会识别文档的层级结构(如 Markdown 的 #、##,或者是 HTML 的 <p>、<div> 标签)。
- 核心逻辑: 它会优先尝试在最大的层级(如章节)处切割,如果章节太大,再尝试在段落处切割,最后才是句子。
- 优点: 极大程度上保留了作者的逻辑思路。段落内部的紧密关系不会被破坏。
- 工具推荐: LangChain 中的
RecursiveCharacterTextSplitter是该方案的典型实现。 - 适用场景: 法律条文、技术文档、书籍等逻辑结构明显的文本。
1.2.4 语义分块(Semantic Chunking)
这是目前最智能也最"昂贵"的方法。它不再依赖于字符数,而是通过 AI 来寻找语义的边界。
- 工作原理:
- 将文档拆分为单句。
- 为每句话生成 Embedding。
- 计算相邻句子之间的余弦相似度。
- 当相似度低于某个阈值(表示话题发生了跳跃)时,进行切割。
- 优点: 每个 Chunk 在语义上都是高度自洽的,检索极其精准。
- 缺点: 切割过程本身就需要调用 Embedding 模型,大幅增加了数据清洗阶段的成本和时间。
- 适用场景: 对召回准确率有极致要求的专家系统或科研检索。
1.3 切割最佳实践(Tips)
在实战中,切割策略的选择往往比模型微调更能提升 RAG 的效果。
1.3.1 寻找场景的"黄金比例"
虽然没有放之四海而皆准的参数,但经过大量工程实践,以下配置通常是良好的起点:
- 通用场景: 512 个 Tokens + 10% ~ 20% 的 Overlap。这个尺寸兼顾了 Embedding 模型的处理上限(通常是 512 或 768)和语义的完整性。
- 短文本/问答对: 100-200 Tokens,适合 FAQ 库。
- 法律/代码: 需要更大的块(1000+ Tokens)以保证逻辑不被拆散。
1.3.2 多粒度分块策略(Small-to-Big / Parent-Document Retrieval)
这是一种进阶的高级技巧,在 Milvus 的应用中非常流行:
- 操作方法:
- 我们将文档切成极小的 子块(Small Chunk),比如每句一词或 100 字。
- 同时保留这些子块所属的 父块(Parent Chunk),比如 1000 字的段落。
- 检索时: 匹配子块(因为短,所以向量特征极其明显,搜索精度高)。
- 生成时: 将命中子块对应的"父块"整体喂给大模型。
- 价值: 这种"小块检索、大块读"的方法完美解决了"检索精度"与"生成上下文充足度"之间的矛盾。
在深入讨论 Milvus 之前,我们必须先理解 RAG 的灵魂------Embedding(嵌入)。如果说切割是将文档"拆成零件",那么 Embedding 就是为这些零件制作"数字身份证"。
博主总结: 切割是 RAG 的"第一工程"。在 Milvus 中存储这些分块时,我们不仅要存向量,还建议存入 chunk_id、parent_id 和 source_link 等元数据,为后续的精准溯源打下基础。
第二章:向量嵌入(Embedding)------沟通现实与多维空间的桥梁
在大模型的世界里,计算机并不认识"猫"或"数据库"这些词,它只认识数字。Embedding 技术的核心任务,就是将人类的语言(非结构化数据)转化为一串高维数字向量(结构化数字)。
2.1 什么是 Embedding:语义的几何化
Embedding 是一种将离散变量(如单词、句子、图片)映射到连续向量空间的技术。
- 从文字到坐标: 你可以将 Embedding 想象成一个巨大的、拥有成百上千维度的坐标系。在这个坐标系里,每一个词或每一个分块(Chunk)都有一个精准的坐标点。
- 语义近义 = 空间近邻: Embedding 模型最神奇的地方在于,它能捕捉语义。在向量空间中,"国王"和"女王"的坐标距离会非常近,而"国王"和"香蕉"的距离就会非常远。
- 捕捉隐含关系: 优秀的 Embedding 模型甚至能处理逻辑类比,比如:
向量("国王") - 向量("男人") + 向量("女人") ≈ 向量("女王")。
2.2 维度(Dimension):信息量的容器
当你查阅 Embedding 模型(如 OpenAI 的 text-embedding-3-small 或开源的 BGE-M3)时,总会看到一个参数:维度。
- 维度越高越好吗? 常见的维度有 384、768、1536 等。维度越高,模型能捕捉到的细微语义特征就越多,但同时也会占用更多的存储空间,并降低 Milvus 的检索速度。
- 对齐的重要性: 在使用 Milvus 建表(Collection)时,必须提前定义向量维数。如果你用 768 维的模型生成向量,却存入一个 1536 维的集合中,系统会直接报错。这就像插头与插座必须匹配一样。
2.3 相似度算法:衡量"多近"的标准
既然内容变成了坐标,我们要如何判断两个 Chunk 是否相关呢?这通常依赖于数学上的距离计算,Milvus 常用以下几种:
- 余弦相似度 (Cosine Similarity): 最主流的选择。它衡量两个向量之间夹角的余弦值,只关心方向而不关心长度。适合评估文本语义的相似性。
- 欧式距离 (L2 Distance): 衡量两个点之间的直线距离。距离越小,越相似。
- 内积 (IP): 衡量向量在同一方向上的重合程度,常用于某些特定的推荐算法。
2.4 在 RAG 中的关键角色:连接 Query 与 Knowledge
Embedding 是 RAG 检索流程的"翻译官":
- 入库阶段: 将切好的文档块全部转化为向量,存入 Milvus。
- 查询阶段: 用户提问"如何安装 Milvus?",系统先将这句提问也转化成向量。
- 检索阶段: Milvus 在向量空间中寻找离"提问向量"最近的那几个"文档块向量"。
- 生成阶段: 找到最相似的块后,将它们还原成文字,喂给 LLM。
2.5 向量化底座的选型:Embedding 模型的博弈
注:此处选型指负责生成向量的模型,而非最终回答问题的生成大模型。
- API 阵营(如 OpenAI
text-embedding-3系列):- 优点: 语义处理能力极强,省去了维护服务器的麻烦。
- 缺点: 每一千个 Token 都要计费;大规模入库时,数据隐私(如公司内部财务报表)需要上传至云端,存在安全隐患。
- 开源阵营(如 BAAI 的 BGE 系列、华为 BCE、Jina):
- 优点: 私有化部署的首选。 针对中文垂直领域(法律、医疗、金融)有更好的微调空间。最重要的是,数据处理完全在本地,符合企业级安全要求。
- 性能: 在 Milvus 的配合下,本地 Embedding + 本地索引可以实现极高的响应速度。
易混淆点:Embedding 模型 vs. 生成式大模型 (LLM)
很多开发者会问:"我已经买了 GPT-4 的 API,为什么还要选 Embedding 模型?"
- 分工不同: GPT-4 擅长逻辑推理(写文章、改代码),但它并不直接参与向量数据库的"坐标计算"。你需要一个专门的 Embedding 模型来为 Milvus 提供坐标信息。
- 成本解耦: 这是一个非常实用的策略------"本地 Embedding + 云端 LLM" 。
- 你可以使用开源的 BGE-M3 模型在本地服务器进行文档向量化(免费且保护隐私,数据不出库)。
- 只有在最后生成答案时,才将检索到的文字发给 GPT-4 或 DeepSeek。
- 性能匹配: Embedding 模型非常轻量。在生产环境下,为了追求毫秒级检索,我们通常会选择将 Embedding 模型部署在靠近 Milvus 的地方,以减少网络延迟。
2.6 RAG 全流程实战解析 ------ 从内网文档到智能问答
检索与生成阶段 - 在线实时
知识入库阶段 - 离线预处理
策略: 固定/语义/层级
生成高维向量
保存原始文字作为元数据
1.生成提问向量
2.向量距离计算
3.召回 Top-100 粗选块
4.原始提问与候选块深度比对
5.精选 Top-5 精排块
6.最终提示词
原始文档: PDF/Doc/Wiki
文档切割 Chunking
文本分块 Chunks
Embedding 模型
Milvus 向量数据库
用户提问 Query
Embedding 模型
Milvus 向量检索
候选分块 Candidates
Rerank 模型/重排器
Context 核心上下文
Prompt 提示词模板
GPT-4 / LLM
最终回答 Answer
我们将构建一套企业级 RAG 系统的过程分为"预处理"和"检索生成"两大部分。
2.6.1 阶段一:知识入库流程(离线预处理)
这是系统的"备课"阶段。目的是将分散在公司内网(如 Wiki、钉钉文档、PDF 报表)中的非结构化数据转化为计算机可理解的结构化索引。
- 数据采集 (Data Sourcing):
从公司内网提取原始文档(PDF、Word、Markdown 等)。这些文档包含了公司特有的业务逻辑、产品手册或财务规章。 - 文档切割 (Chunking):
由于原始文档可能长达万字,我们通过切割策略(如前文提到的递归切割或语义切割)将其拆分为短小的 文本分块 (Chunks)。 - 向量化 (Embedding):
每一个文本分块被送入 Embedding 模型 (如 BGE-M3)。模型会将文字转化为一串固定维度的浮点数(向量)。- 注意:此时语义相近的文字在数学空间里的距离也会很近。
- 存储与索引 (Milvus Storage):
将生成的向量存入 Milvus 向量数据库。同时,Milvus 会将原始文字片段作为"元数据 (Metadata)"一同关联存储。Milvus 会针对这些向量构建高性能索引(如 HNSW),以便在数亿条数据中实现毫秒级搜索。
2.6.2 阶段二:查询与生成流程(在线实时)
这是系统的"闭卷考试"阶段,用户提出问题,系统在瞬间完成查书和回答的过程。
- 提问向量化 (Query Embedding):
用户在界面输入提问(如:"我们公司 2026 年的年假政策是什么?")。系统立即使用同一个 Embedding 模型将问题转化为向量。 - 向量检索 (Milvus Retrieval):
系统将提问向量发给 Milvus 。Milvus 在海量库中进行"向量距离计算",执行粗选 。- 输出: 快速召回相关度最高的 Top-100 个候选分块(Candidates)。
- 精排重排 (Reranking):
由于向量搜索主要基于语义近似度,有时会召回一些"语义接近但逻辑无关"的内容。此时引入 Rerank 模型 (重排器)。- 操作: Rerank 模型会对这 100 个候选块与原始提问进行深度语义比对。
- 结果: 筛选出质量最高、最精准的 Top-5 个分块作为核心上下文(Context)。
- Prompt 拼接 (Prompt Engineering):
系统将这 5 个核心分块与用户的原始问题填入预设的 Prompt 模板 中。- 模板示例:"你是公司助理。已知公司政策如下:Top-5 文本。请根据以上内容回答:用户问题。"
- 大模型生成 (LLM Generation):
将拼接好的最终提示词发送给 GPT-4 。- GPT-4 此时不再是靠"记忆"瞎猜,而是像在做阅读理解题一样,根据你提供的证据组织语言。
- 结果返回 (Final Answer):
GPT-4 生成准确、有据可查的回答,返回给用户。
博主结语: Embedding 的质量直接决定了检索的"天花板"。如果你选用的模型无法区分"苹果公司"和"红富士苹果",那么后续的 RAG 流程无论怎么优化都无济于事。有了这些高质量的向量,我们接下来的任务就是:如何在一个亿级规模的向量池里,瞬间找到最接近的那几个坐标? 这就是 Milvus 大显身手的时候了。
第三章:Milvus 在 RAG 中的核心角色与架构
在 RAG 的世界里,如果说 Embedding 模型是"翻译官",那么 Milvus 就是那座存放万亿级卷宗的"超级图书馆"。它不仅要存得下海量向量,更要在用户提问的瞬间,从无限的信息海洋中精准地抽取出那几页纸。
3.1 什么是 Milvus?
简单来说,Milvus 是一款开源的、针对海量向量数据设计的分布式向量数据库。
传统数据库(如 MySQL)擅长处理"姓名、订单号"这类结构化数据 的精确匹配;而 Milvus 是为了处理由非结构化数据(文本、图片、音视频)转化而来的向量而生的。它通过数学计算(如余弦相似度),能在毫秒级时间内帮你找出"语义最接近"的内容。
3.2 高屋建瓴:深度拆解 Milvus 架构
要用好 Milvus,必须理解它极具前瞻性的"存算分离"架构。这种设计让它能够像积木一样根据业务需求自由伸缩。
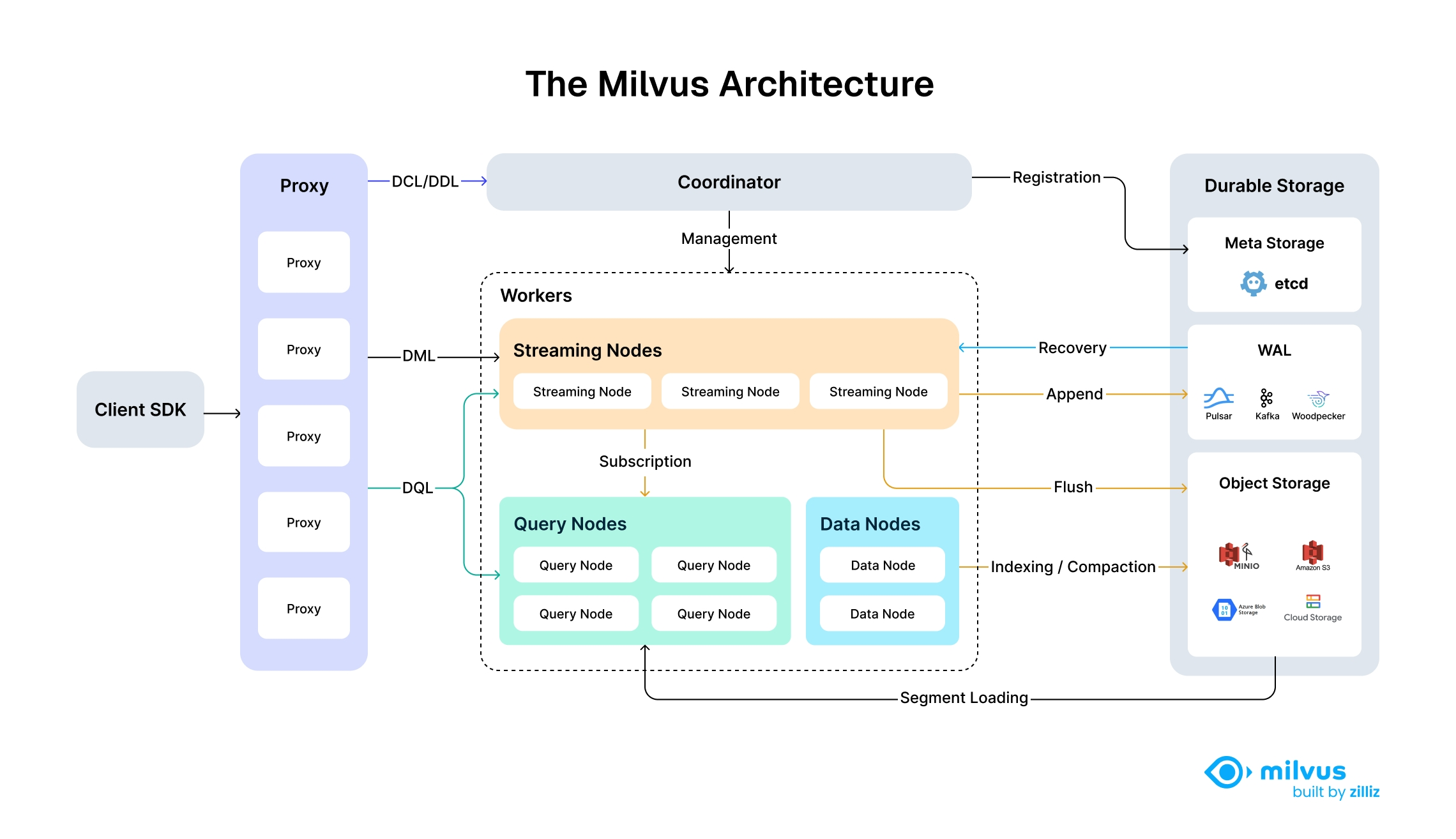
我们将架构简化为四个关键层级:
- 接入层 (Access Layer - Proxy): 系统的"门面"。负责接收请求、校验权限,并将任务下发给后端的"小弟"们。
- 协调服务 (Coordinator Service - Brain): 系统的"大脑"。负责分配任务、管理集群状态(比如哪张表存放在哪个节点上)。
- 执行节点 (Worker Nodes - Muscle):
- Query Node(查询节点): 专门负责搜索,决定了 RAG 的响应速度。
- Data Node(数据节点): 负责把数据刷入磁盘。
- Index Node(索引节点): 负责构建"目录"(索引),让搜索变快。
- 底层存储 (Durable Storage - Foundation):
- 使用 etcd 存元数据(表结构等),使用 S3/MinIO 存放真正的海量向量数据。
3.3 由浅入深:核心对象概念对照表
初学者可以通过对比传统 SQL 数据库来快速理解 Milvus 的逻辑模型:
| Milvus 概念 | SQL 对应概念 | 详细描述 |
|---|---|---|
| Database | 数据库 | 最大的逻辑隔离单位。 |
| Collection | 表 (Table) | 存放同类数据的集合,如"公司制度表"。 |
| Schema | 表结构 | 定义字段、数据类型及最重要的向量维度。 |
| Entity | 行 (Row) | 每一行代表一个切割后的文档片段(Chunk)。 |
| Field | 列 (Column) | 字段,如 id、vector(向量)、text(原文)。 |
| Index | 索引 | 书的"目录"。如 HNSW 索引,是极速检索的关键。 |
3.4 动手实战:5 分钟实现"真"向量检索
为了让大家零门槛上手,我们使用 Milvus Lite。它直接运行在 Python 环境中,无需安装 Docker,像使用 SQLite 一样简单。
3.4.1 环境准备
在终端执行以下命令。注意:必须安装 [milvus_lite] 额外组件,否则无法连接本地数据库。
bash
# 安装 Milvus 客户端(带本地引擎)及向量生成工具
pip install -U "pymilvus[milvus_lite]" sentence-transformers3.4.2 完整可运行代码
这段代码展示了如何加载 Embedding 模型、将文字转为向量、存入 Milvus 并完成语义检索。
python
import warnings
# 忽略特定的 DeprecationWarning 和 UserWarning
warnings.filterwarnings("ignore", category=UserWarning)
warnings.filterwarnings("ignore", category=DeprecationWarning)
from pymilvus import MilvusClient
from sentence_transformers import SentenceTransformer
# 1. 初始化"翻译官":加载 Embedding 模型
# 这个模型会将文字转化成一个包含 384 个数字的列表(向量)
print("正在加载 Embedding 模型...")
model = SentenceTransformer('all-MiniLM-L6-v2')
def get_embedding(text):
return model.encode(text).tolist()
# 2. 初始化"图书馆":连接本地 Milvus 数据库文件
client = MilvusClient("./milvus_demo.db")
# 创建集合 (Collection),维度必须与模型的 384 维对齐
if client.has_collection("company_docs"):
client.drop_collection("company_docs")
client.create_collection(
collection_name="company_docs",
dimension=384
)
# 3. 知识入库:将内网文档向量化
docs = [
"公司年假规定:入职满一年可享有 5 天带薪年假。",
"RAG 架构通过检索私有知识解决模型幻觉问题。",
"Milvus 是 AI 时代的长期记忆体。"
]
print("正在将文档块转化为向量并入库...")
data = [
{"id": i, "vector": get_embedding(doc), "text": doc, "source": "员工手册"}
for i, doc in enumerate(docs)
]
client.insert(collection_name="company_docs", data=data)
# 4. 语义检索:用"提问"搜"答案"
question = "我工作两年了,能休几天假?"
print(f"\n用户提问: {question}")
# 搜索最相关的 Top-1 结果
results = client.search(
collection_name="company_docs",
data=[get_embedding(question)],
limit=1,
output_fields=["text", "source"]
)
# 5. 展示结果
print("\n--- 检索到的最匹配知识 ---")
for res in results[0]:
print(f"内容: {res['entity']['text']}")
print(f"来源: {res['entity']['source']} (相似度分值: {res['distance']:.4f})")运行结果为

3.5 避坑指南:常见报错处理
Q: 报错 ConnectionConfigException: milvus-lite is required...?
A: 这是因为你只安装了客户端,没安装本地引擎。请务必执行 pip install "pymilvus[milvus_lite]"。
Q: 什么是 vector?0.1, 0.2, ... 里面到底是什么?
A: 它是由 Embedding 模型生成的坐标。你不需要理解每个数字的含义,只需要知道:在数学空间里,意思相近的两段文字,它们生成的向量距离就越近。Milvus 做的就是帮你在数亿个坐标中,秒找"邻居"。
博主总结:
到这里,你已经亲手完成了一个 RAG 系统的核心------语义检索。Milvus 帮你完成了从"大海捞针"到"按图索骥"的进化。
第四章:实战------构建"分块 + 检索"的高性能链路
在第三章中,我们已经跑通了一个基础的向量检索流程。但在实际的企业级生产环境中,当你的文档从 3 篇变成 300 万篇时,简单的搜索就会面临性能下降和结果"似是而非"的问题。本章将深入探讨如何通过 索引优化 和 标量过滤,把 Milvus 的性能榨干到极致。
4.1 索引优化:让搜索快、准、稳
向量索引就像是图书馆的"分类目录"。如果不建立索引,Milvus 就必须对全表进行暴力扫描(类似于逐行翻书),数据量大时会极慢。在 RAG 场景中,HNSW 是公认的"王者索引"。
4.1.1 HNSW 索引参数调优
HNSW(分层导航小世界图)通过构建一个多层的图结构来实现极速检索。要调优它,你需要理解三个关键参数:
- M (Maximum Degree):
- 含义: 每个节点在图中连接的最大邻居数。
- 调优: 常用值 16~64。
M越大,检索准确率(召回率)越高,但索引文件也会越大,占用的内存更多。
- efConstruction (Search Scope during Indexing):
- 含义: 构建索引时的搜索范围。
- 调优: 常用值 40~300。值越高,构建出来的图质量越高,但建索引的速度会变慢。
- ef (Search Scope during Query):
- 含义: 实际搜索时的范围。
- 调优: 这个值可以在搜索时动态调整。如果你发现搜出来的结果不够准,可以调大
ef。值越大,准确度越高,但响应耗时(Latency)会增加。
4.1.2 内存映射(MMap)技术:穷人的"扩容神器"
向量数据非常吃内存。如果公司服务器的内存不足以装下数亿条向量,搜索就会崩溃。
- 什么是 MMap? 它是 Milvus 提供的一种将索引文件映射到磁盘的技术。
- 核心优势: 系统会将磁盘空间当作"虚拟内存"使用。这样你可以用较低的内存成本,处理远超物理内存容量的数据量。
- 适用场景: 对成本敏感,或者数据量巨大、但对检索延迟(毫秒级 vs 微秒级)要求没那么极端的场景。
4.2 标量过滤(Scalar Filtering):精准打击
在真实的 RAG 业务中,用户很少进行"纯语义"搜索。他们通常会带有业务条件的限制,例如:
"搜索 2025 年以后的技术文档,告诉我如何配置 Milvus 索引。"
如果只靠向量检索,可能会搜出 2022 年的陈旧文档。这时就需要 标量过滤 出马。
4.2.1 什么是标量过滤?
标量过滤是指在进行向量检索(Vector Search)的同时,利用传统的结构化字段(如日期、分类、部门 ID)进行布尔表达式过滤。
4.2.2 示例:如何实现"精准筛选"
假设你在创建 Collection 时,在 Schema 中加入了 release_year(年份)和 doc_type(文档类型)字段。在搜索时,你可以这样写:
python
# 复杂的混合检索:向量相似度 + 布尔过滤
results = client.search(
collection_name="my_docs",
data=[query_vector],
# 这里的 filter 就是标量过滤的关键
filter="release_year >= 2023 and doc_type == 'tech_spec'",
limit=5,
output_fields=["text"]
)4.2.3 Milvus 的性能优势:先过滤还是后过滤?
传统的方案往往是"先向量搜索,后手动过滤",但这会导致召回结果不足。
- Milvus 的实现: 它在底层的向量搜索算法中直接嵌入了标量过滤。在遍历图(HNSW)的过程中,如果发现某个节点不符合标量条件(比如年份不对),会直接跳过。
- 结果: 这种"深度耦合"的过滤方式不仅速度极快,而且能确保最终返回的 Top-K 个结果全部满足你的业务条件。
4.3 架构师的技术贴士(Tips)
- 字段冗余不可怕: 在 Milvus 的 Schema 设计中,尽量多存一些可能用于过滤的字段(如
department_id、is_public)。这些标量字段占用的空间远小于向量,但能让你的搜索变得异常灵活。 - 动态字段的坑: 虽然 Milvus 支持动态字段,但如果你频繁针对某个字段进行
filter过滤,建议将其显式定义为 标量字段(Scalar Field) 并建立索引,这样速度会快得多。 - 索引预热: 在大规模生产环境下,建议在用户查询前先调用
load_collection,将索引预加载进内存,避免首名用户遭遇明显的"首查延迟"。
博主总结:
高性能的 RAG 链路,是"高质量切割 + 精准索引 + 业务过滤"的结合体。Milvus 不仅仅通过向量坐标帮你定位语义,更通过强大的索引和标量引擎,帮你实现了业务层面的精准打击。
第五章:进阶 RAG------混合搜索(Hybrid Search)与重排(Rerank)
在前面的章节中,我们已经实现了基于向量的语义检索。但在实际业务中,你会发现一个尴尬的现象:用户搜索具体的产品型号、缩写词或特定工号(如"X100-Pro")时,向量检索可能会因为语义太泛,召回了一堆不相关的"Pro"产品,却偏偏漏掉了那条最精确的记录。
为了解决这个问题,我们需要引入 RAG 的高级形态:混合搜索 与重排。
5.1 混合搜索(Hybrid Search):语义与关键词的协同优化
向量检索虽然聪明,但它有时会产生"语义漂移"。混合搜索通过将密集向量(Dense Vector )与稀疏向量(Sparse Vector / BM25)结合,实现了"理解意思"与"精准匹配"的互补。
5.1.1 密集向量 (Dense) vs. 稀疏向量 (Sparse)
- 密集向量 (Dense Vector): 就是我们前文生成的 384 维或 768 维数组。它擅长捕捉"意思"。比如搜索"水果",它能帮你找到"苹果、香蕉"。
- 稀疏向量 (Sparse Vector / BM25): 类似于传统的关键词搜索。它擅长捕捉"字面匹配"。比如搜索"X100-Pro",它会精准锁定包含这 8 个字符的片段,而不会被语义带跑。
5.1.2 互补方案:解决检索盲区
- 解决语义漂移: 当用户提问非常具体(包含特定术语)时,稀疏向量确保关键词命中。
- 解决关键词缺失: 当用户提问非常模糊(如"那个圆圆的红色的东西")时,密集向量确保语义命中。
- Milvus 的支持: Milvus 目前原生支持多向量(Multi-Vector)搜索。你可以同时存储这两类向量,并在搜索时通过 RRF(Reciprocal Rank Fusion) 算法,将两份搜索结果自动加权合并,给出一个综合排名最高的列表。
5.2 重排(Reranking):最后的一公里优化
即便有了混合搜索,我们从 Milvus 捞出来的 Top-K 个片段(比如前 50 条)中,仍然可能混入了一些"噪音"。这就是为什么我们需要在"检索"与"生成"之间,加一个"精算师"------重排模型(Reranker)。
5.2.1 为什么需要重排?(Bi-Encoder vs. Cross-Encoder)
- 初选靠向量(Bi-Encoder): Embedding 模型(如 BGE-M3)属于 Bi-Encoder。它在检索时速度极快,但它对"提问"和"文档"的理解是分开的,无法进行极其深度的对比。
- 精排靠重排(Cross-Encoder): Rerank 模型会将"用户问题"和"候选文档"放在一起进行两两对比。它计算量大、速度慢,但准确度极高。
- 黄金法则: 在生产环境中,我们通常先用 Milvus 快速召回 100 条候选数据(粗选),再把这 100 条交给 Reranker 选出最精排的 5 条(精选)喂给 GPT-4。
5.2.2 实战:接入 BGE-Reranker 模型
以目前最流行的 BGE-Reranker 为例,它的工作流程如下:
- 输入:
(提问, 候选片段 1),(提问, 候选片段 2)... - 输出: 每一个组合都会得到一个 0~1 之间的分值。
- 动作: 重新按照分值排序,剔除低分片段。
伪代码示例:
python
# 假设从 Milvus 检索到了 100 条结果
candidates = client.search(..., limit=100)
# 接入 Reranker 模型进行"精挑细选"
reranker_model = CrossEncoder('BAAI/bge-reranker-base')
pairs = [[question, cand['text']] for cand in candidates]
scores = reranker_model.predict(pairs)
# 结合分数重新排序,只取前 5 条
final_context = sorted(zip(candidates, scores), key=lambda x: x[1], reverse=True)[:5]5.3 进阶建议:从"能用"到"好用"
- 权重的艺术: 在混合搜索中,密集向量和稀疏向量的权重分配(比如 0.7 vs 0.3)需要根据你的数据特征进行微调。如果你的文档全是技术代码,调高稀疏向量的权重会更准。
- Rerank 是必须的吗? 如果你的数据量很小(几千条),可能感觉不到 Rerank 的威力;但当数据量达到百万级,Rerank 几乎是解决"模型胡说八道"的唯一解药。
- 性能平衡: Rerank 会增加约 100ms-500ms 的延迟。如果你的应用追求极致响应速度,可以考虑使用更轻量级的重排模型或并行计算。
博主总结:
RAG 的进化是一个不断"去噪"的过程。
- 分块 (Chunking) 决定了信息的纯度;
- 向量化 (Embedding) 决定了搜索的深度;
- 混合搜索 (Hybrid Search) 兼顾了广度与精度;
- 重排 (Reranking) 则是最后的"质检员"。
只有这一套组合拳打下来,你交给 GPT-4 的才是一份真正能解决问题的"真知识"。
第六章:典型坑点与避坑指南
在纸面上谈论 RAG 总是完美的,但在实际工程落地中,开发者往往会被各种细节绊倒。以下是我们在构建大规模 RAG 系统时总结出的三个"深水区"坑点及解决方案。
6.1 坑点 1:忽视特殊符号(LaTeX、代码块)的切割处理
现象: 用户搜索一个公式或一段代码,召回的结果不仅格式全乱,LLM 也无法理解。
- 原因: 传统的字符分割器会将
E=mc^2从中间切开,或者把一段 Python 代码的缩进完全抹去。对于 Embedding 模型来说,支离破碎的符号序列是无法产生有效语义向量的。 - 避坑指南:
- 结构感知的分割: 使用针对 Markdown 或 LaTeX 优化的分割器。例如,遇到代码块(```)时,强制将其作为一个整体对待,不进行内部切割。
- 保留格式: 在存储到 Milvus 的
raw_text字段时,务必保留原始的换行符和特殊符号,这对 LLM 生成准确的答案至关重要。
6.2 坑点 2:索引构建太慢?(批处理与并行化)
现象: 当你有百万级文档需要入库时,发现进度条像蜗牛一样移动,甚至数据库连接超时。
- 原因: 频繁的小批量(甚至是单条)插入(Insert)会导致网络 IO 和索引重构压力巨大。
- 避坑指南:
- 批处理写入: 每次插入 500-1000 条数据。Milvus 的性能在批处理模式下能得到数倍提升。
- 先入库,后索引: 对于海量历史数据,最佳方案是先将数据全部导入(Insert),最后统一创建索引。
- 并行构建: 充分利用 Milvus 的分布式特性,通过增加 Index Node 来并行加速索引构建。
6.3 坑点 3:召回了不相关的块?(Top-K 与 Score 阈值)
现象: 用户问了一个数据库里根本没有的问题,系统却强行从 Milvus 里捞出 5 个不相关的块,导致 GPT-4 煞有介事地胡说八道。
- 原因: 向量搜索永远会返回结果,即使相关度极低。默认的 Top-K 检索(如取前 5 名)是"矮子里面拔将军"。
- 避坑指南:
- 设定分数阈值(Distance Threshold): 设定一个硬性门槛(例如余弦相似度必须 > 0.7)。低于此分数的内容,宁可不给 GPT-4 看。
- 动态 Top-K: 结合 Rerank 模型的分数,如果第一名和第二名分数差距过大,说明后面都是噪音,应果断舍弃。
结语:从检索增强迈向智能代理式 RAG
经过这六章的深度探讨,我们完成了从"文档如何切片"到"Milvus 如何极速索引",再到"重排与避坑"的全链路梳理。
长期收益:数据是 AI 时代的护城河
文档切割策略与 Milvus 的深度配合,其本质是在为公司构建"私有知识资产的结构化视图"。
- 切割决定了知识的颗粒度;
- Milvus 决定了知识的访问效率。
当这两者稳定运行后,你的企业就拥有了一个可以不断自我迭代、永不遗忘的"云端大脑"。
展望:迈向具有反思能力的 Agentic RAG
目前我们讨论的大多数是"单向 RAG":用户问 -> 系统搜 -> 模型答。
未来的趋势是 Agentic RAG(智能体化检索):
- 反思(Reflection): AI 会先思考"用户的问题是否清晰?如果不清晰,我应该先追问,而不是盲目搜索"。
- 多步检索(Multi-hop): 如果一个复杂问题需要跨越两份文档,AI 会先搜 A,根据 A 的结果再去搜 B。
- 自评估: AI 在生成答案后,会对照 Milvus 召回的原件进行自我质检:"我的回答是否有原文支撑?"
写在最后:
RAG 不是一个简单的技术插件,它是一场关于"如何让 AI 真正落地"的工程实践。希望这篇博文能帮你少走弯路,在 Milvus 的助力下,构建出真正聪明、严谨且强大的 AI 应用。