摘要:本篇围绕 Java 并发容器核心,详细解析了 ConcurrentHashMap 在 JDK 1.7 和 JDK 1.8 版本中的实现原理与演进,并对比了其与 HashMap、Hashtable 的核心差异。


第6章 Java 并发容器
6.1 ConcurrentHashMap的实现原理与使用
6.1.1 为什么要使用ConcurrentHashMap

-
JDK1.7中的 HashMap 使用头插法插入元素,在多线程的环境下,扩容的时候有可能导致环形链表的出现,形成死循环。因此,JDK1.8使用尾插法插入元素,在扩容时会保持链表元素原本的顺序,不会出现环形链表问题。
-
多线程同时执行 put 操作,如果计算出来的索引位置是相同的,那会造成前一个 key 被后一个 key 覆盖,从而导致元素的丢失。此问题在JDK 1.7和 JDK 1.8 中都存在。

常见的线程安全Map集合:
-
Hashtable是早期 Java 提供的线程安全的Map实现,它的实现方式与HashMap类似,但是在每个可能修改Hashtable状态的方法上加上synchronized关键字。 -
ConcurrentHashMap在 JDK 1.8 以前采用了分段锁等技术来提高并发性能。在ConcurrentHashMap中,将数据分成多个段(Segment),每个段都有自己的锁。在进行插入、删除等操作时,只需要获取相应段的锁,而不是整个Map的锁,这样可以允许多个线程同时访问不同的段,提高了并发访问的效率。在 JDK 1.8 以后是通过 volatile + CAS 或者 synchronized 来保证线程安全的。
6.1.2 ConcurrentHashMap 的结构

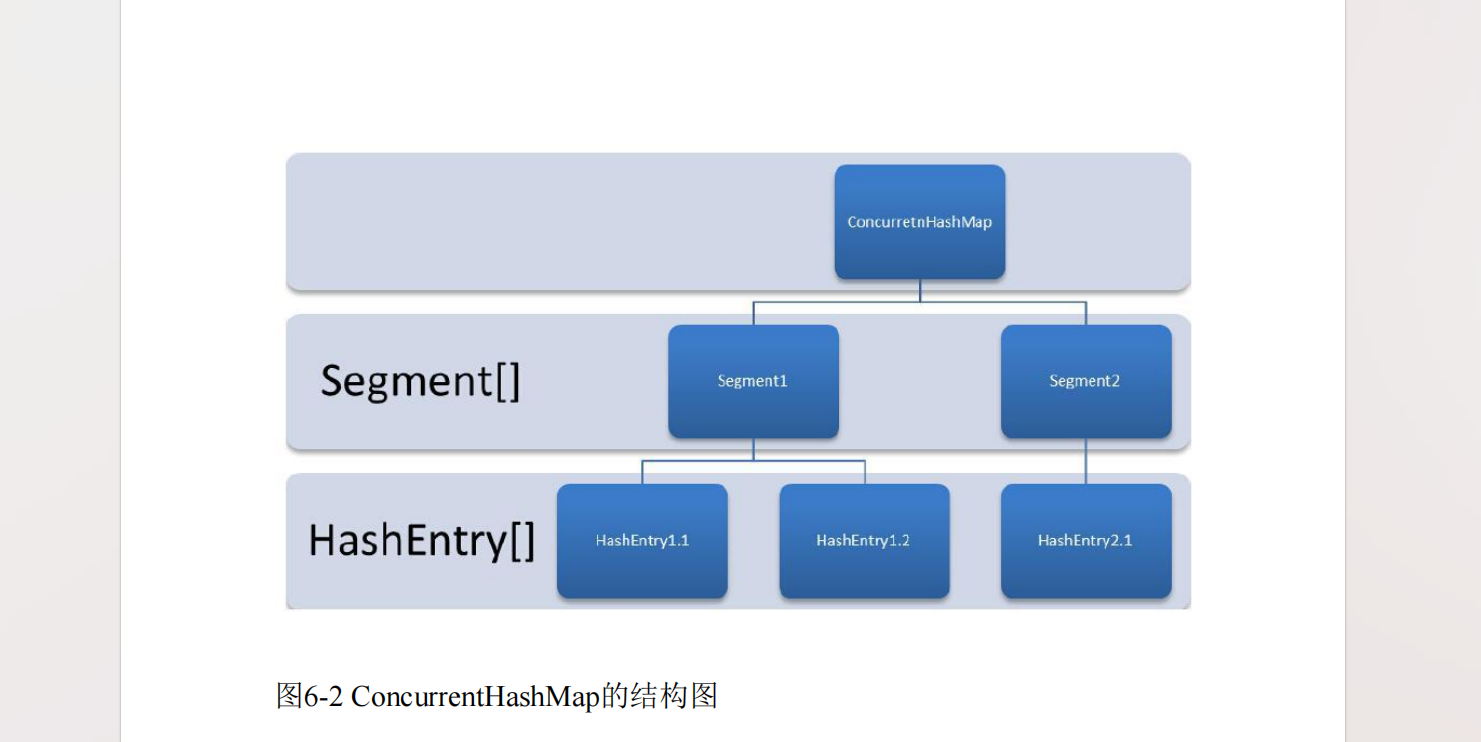
ConcurrentHashMap是由Segment和HashEntry组成。 Segment是一种可重入锁(ReentrantLock),在ConcurrentHashMap里扮演锁的角色;HashEntry则用于存储键值对数据。一个ConcurrentHashMap里包含一个Segment数组。Segment的结构和 HashMap类似,是一种数组和链表结构。一个Segment里包含一个HashEntry数组,每个HashEntry是一个链表结构的元素,每个Segment守护着一个HashEntry数组里的元素,当对HashEntry数组的数据进行修改时,必须首先获得与它对应的Segment锁。
这组图展示的是 JDK 1.7 版本 ConcurrentHashMap 的核心设计,它是为了解决 HashMap 线程不安全和 Hashtable 效率低下的问题而诞生的。
++分层结构与原理++
-
ConcurrentHashMap 层(顶层容器)
-
内部维护一个
Segment数组,相当于把整个哈希表拆分成了多个 "小 HashMap"。 -
这种 "分段锁" 设计,让不同 Segment 上的操作可以并发执行,大大提升了并发效率。
-
-
Segment 层(分段锁实现)
-
Segment本身继承了ReentrantLock,扮演锁的角色。 -
每个
Segment++守护着一个++ ++HashEntry++ ++数组++,修改该数组中的元素前必须先获取对应的 Segment 锁。 -
它的结构和
HashMap类似,也是数组 + 链表的结构。
-
-
HashEntry 层(数据存储单元)
-
用于存储具体的键值对(Key-Value)。
-
++每个++ ++
HashEntry++ ++是++ ++链表++ ++结构的节点,当发生哈希碰撞时,会以链表形式追加在对应位置++。
-
通俗来讲:
ConcurrentHashMap = 多个
Segment组成的数组 | Segment = HashEntry数组 +ReentrantLock锁Segment = HashEntry+ HashEntry ... | HashEntry(元素) = key + value + next 指针 + 哈希值
ConcurrentHashMap 怎么实现的? ⭐
JDK 1.7 ConcurrentHashMap
JDK 1.7 中 ConcurrentHashMap 的底层结构是 Segment[] 数组(默认长度 16,不可扩容) + 每个 Segment 内部的 HashEntry[] 数组 + 链表;每个 Segment 继承自 ReentrantLock,持有独立的分段锁,相当于一个"小 HashMap"(HashEntry[] 数组),各自管理一个 HashEntry \[\] 数组(存储该分段下的键值对);HashEntry 数组的每个元素是单向链表的头节点,哈希冲突的键值对以链表形式存储在同一个桶中。
JDK 1.8 ConcurrentHashMap
在 JDK 1.7 中,ConcurrentHashMap 虽然是线程安全的,但因为它的底层实现是数组 + 链表的形式,所以在数据比较多的情况下访问是很慢的,因为要遍历整个链表,而 JDK 1.8 则使用了数组 + 链表/红黑树的方式优化了 ConcurrentHashMap 的实现,具体实现结构如下:
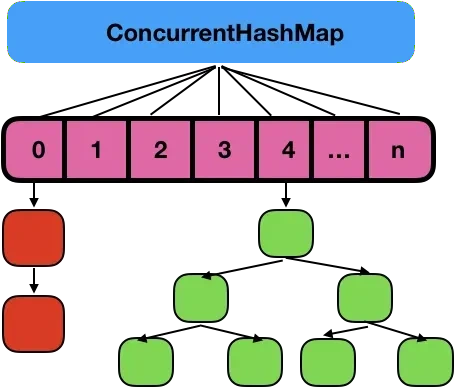
JDK 1.8 ConcurrentHashMap JDK 1.8 ConcurrentHashMap 主要通过 volatile + CAS 或者 synchronized 来实现的线程安全的。
添加元素时首先会判断容器是否为空:
如果为空则使用 volatile 加 CAS 来初始化Node[] 数组
如果容器不为空,定位元素位置并处理。
分两种情况处理:
-
目标位置为空 :直接通过 CAS 操作 将新节点放入该位置(无需加锁,高效)。
-
目标位置不为空(存在哈希冲突,已有链表或红黑树):
-
用 synchronized 锁定该位置的头节点(只锁链表 / 红黑树,而非数组,粒度更细)。
-
遍历该位置的链表 / 红黑树,判断是否存在相同的键:若存在则替换值,否则新增节点。
-
操作完成后,判断链表长度是否超过阈值,若超过则转为红黑树(优化查询性能)。
-
如果把上面的执行用一句话归纳的话,就相当于是ConcurrentHashMap通过对头结点加锁来保证线程安全的,锁的粒度相比 Segment 来说更小了,发生冲突和加锁的频率降低了,操作性能提高。
而且 JDK 1.8 使用的是红黑树优化了之前的固定链表,那么当数据量比较大的时候,查询性能也得到了很大的提升,从之前的 O(n) 优化到了 O(logn) 的时间复杂度。
ConcurrentHashMap用了悲观锁还是乐观锁?
悲观锁和乐观锁都有用到。
添加元素时首先会判断容器是否为空:
-
如果为空则使用 volatile 加 CAS (乐观锁) 来初始化。
-
如果容器不为空,则根据存储的元素计算该位置是否为空。
-
如果根据存储的元素计算结果为空,则利用 CAS(乐观锁) 设置该节点;
-
如果根据存储的元素计算结果不为空,则使用 synchronized(悲观锁) ,然后,遍历桶中的数据,并替换或新增节点到桶中,最后再判断是否需要转为红黑树,这样就能保证并发访问时的线程安全了。
恭喜你学习完本节内容!✿