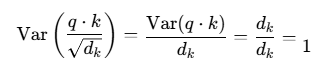最近在看transformers源码的过程中一直有个疑问,为什么self-attention在Q向量与K向量转置相乘后要除以根号dk而不是dk或是其他值,借此机会做个记录。
为什么要除以一个数?
self-attention在计算注意力分数的时候,用query向量与key向量转置相乘,再除以根号d_k,经过softmax之后得到注意力权重,源码实现如下:
python
scores = torch.matmul(query, key.transpose(-2, -1)) \ math.sqrt(d_k)
p_attn = F.softmax(scores, dim = -1)那为什么要除以一个数呢?这与softmax的求导有关,下面给出softmax计算公式:
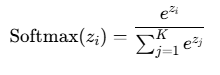
另softmax的表达式为x,则softmax求导结果为x*(1-x),若某项zi偏大或偏小,则softmax计算结果趋向于1或0,而其导数则会趋向于0,造成梯度消失,不利于训练的稳定,所以在计算完注意力分数后要除以一个数,以稳定其梯度。
为什么要除以根号dk呢?
在明白为什么要除以一个数之后,那么问题来了,为什么除以的是根号dk呢,而不是dk、dk的平方或者其他数值呢?
首先假设q向量与k向量是均值为0、方差为1的随机向量,则q向量与k向量相乘之后,方差随维度线性增长,相乘后方差为dk,标准差为根号dk。
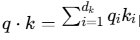
根据方差的性质:
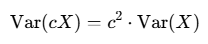
因此可以做出以下推导,在q向量与k向量乘积后除以根号dk,可以将原来的方差缩放为1,将输出控制在合理的范围内,为后续的Softmax计算提供了稳定的输入。