引言:当业务突遇流量洪峰,弹性伸缩(Auto Scaling)本应是救星,但配置不当可能导致扩容失败 ------ 轻则服务降级,重则宕机损失订单。据阿里云官方统计,80% 的扩容失败源于资源不足或规则设置缺陷。本文通过实战经验,拆解三步提升成功率的核心策略。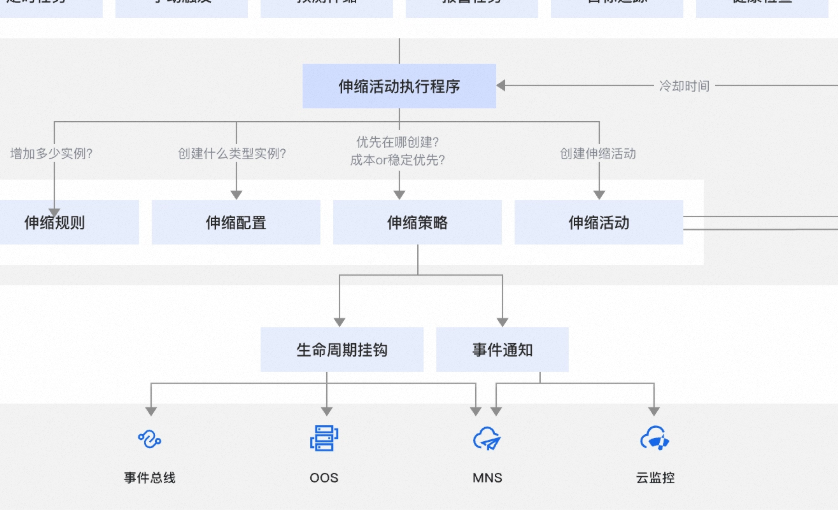
一、智能配置:精准定义伸缩规则
痛点:盲目扩容或阈值设置不合理导致资源浪费 / 不足
解决方案:
动态阈值设定
根据业务历史负载(如电商大促 / 在线教育高峰),设置弹性扩容触发条件:
CPU 利用率 ≥ 75%(非固定值,需参考业务基线)
内存占用 ≥ 70%
网络带宽 ≥ 80%
技巧:通过阿里云 "定时伸缩" 功能,提前预加载资源(如每日 19:00 预扩容应对直播高峰)
多可用区容灾部署
在伸缩组中配置至少 2 个可用区(例如华东 1 的 Zone A+B),避免单一区域资源售罄导致扩容失败
验证方法:执行 aliyun ess DescribeRegions 查看可用区状态
二、资源护航:双保险策略保成功率
核心原理:预留资源 + 快速弹性容器补充
预留实例(Reserved Instances)锁定资源池
提前购买预留型 ECS 实例(比按量付费低 30% 成本),确保高峰时段必有资源
配置路径:阿里云控制台 → 弹性伸缩 → 伸缩组 → 启用 "预留实例策略"
弹性容器实例(ECI)兜底扩容
当 ECS 资源不足时,自动切换至ECI 容器实例(秒级启动,按秒计费)
适用场景:突发流量、临时任务处理
配置示例:
ScalingConfig:
SpotStrategy: SpotAsPriceGo # 使用抢占式实例降低成本
EciInstanceType: ecs.c6.large
三、闭环监控:自动化运维闭环
关键工具链:云监控 + 日志服务 + 自动化重试
智能告警联动
通过云监控设置多级触发:
初级告警(CPU>70%):发送钉钉通知
高级告警(CPU>85%):自动触发扩容 + OOS 运维编排重试
配置代码片段:
aliyun cms PutMetricAlarm --RuleName "HighCPU" --MetricName CPUUtilization --Threshold 85
失败自动重试机制
在伸缩规则中开启 "失败重试" 选项(默认 3 次重试)
结合日志服务 SLS 分析失败原因(常见:资源不足、镜像启动超时)
总结:通过 "智能配置 + 资源双保险 + 监控闭环" 三步策略,可将扩容成功率提升至99%+。实测某跨境电商平台应用后,大促期间扩容耗时从 15 分钟降至 2 分钟,资源浪费减少 40%。