上一个题用到了这个知识点,我决定默写一遍,嗯,我应该能默得下来。
一、概述
1、正则表达式是一个特殊的字符序列,它能帮助我们更加简便地检查一个字符串是否与某种模式匹配。正则表达式是一个很强大的字符串处理工具,几乎任何关于字符串的操作都可以使用正则表达式来完成。在Python中需要通过正则表达式对字符串进行匹配时,需要用到re模块。
2、正则表达式的应用场景
表单验证、爬虫、文本数据处理
(1)导入re模块
python
import re(2)使用match方法进行匹配操作
python
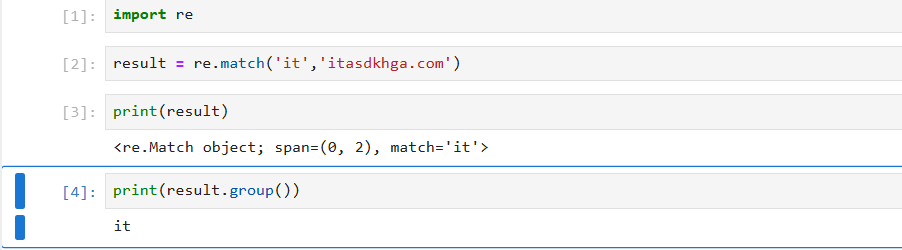
result = re.match()re.match能够匹配出以xxx开头的字符串,如果起始位置没有匹配成功,就会返回None。
(3)如果上一步匹配到了数据,可以使用group()方法来提取数据
python
result.group()举个例子吧
二、匹配单个字符
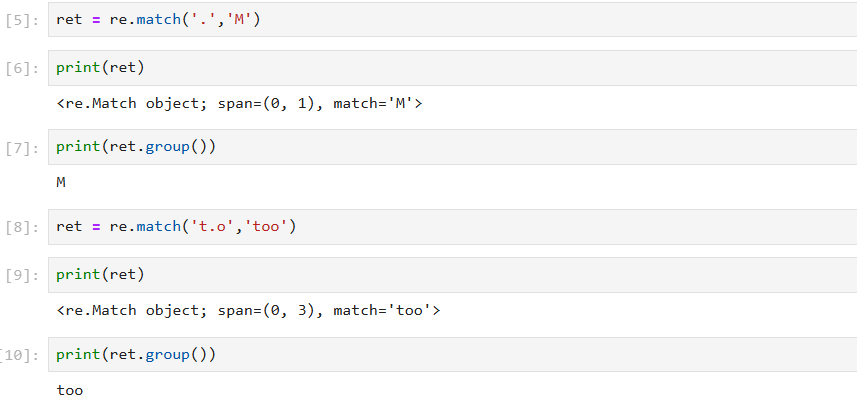
. 匹配任意一个字符(处理\n)
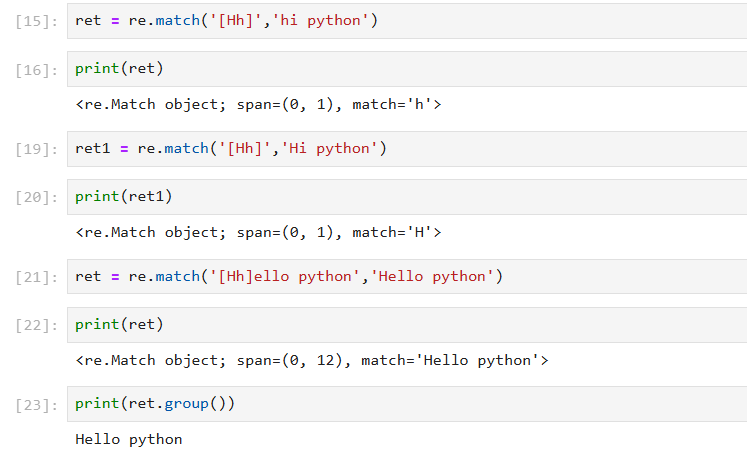
匹配 中列举的字符
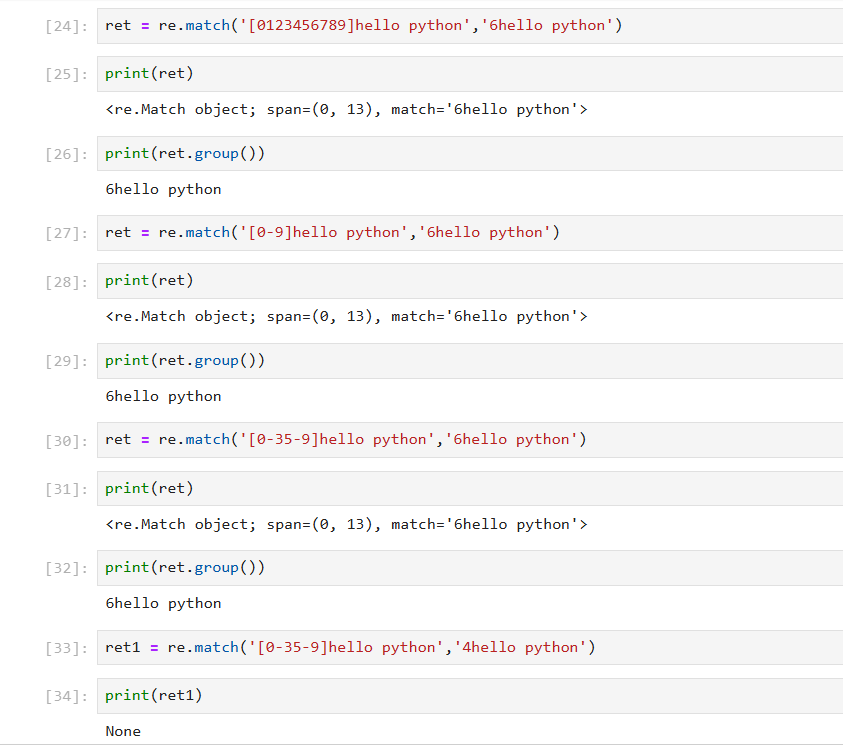
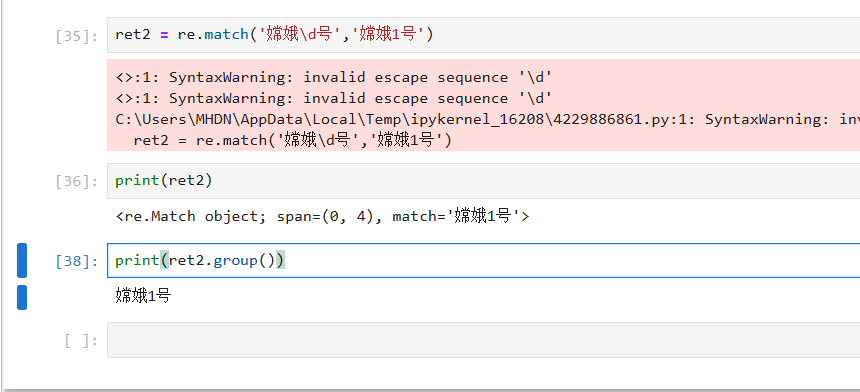
\d 匹配数字,数字范围0~9
\D 匹配非数字,即匹配非数字的字符
\s 匹配空白,即匹配空格,也就是tab键
\S 匹配非空白
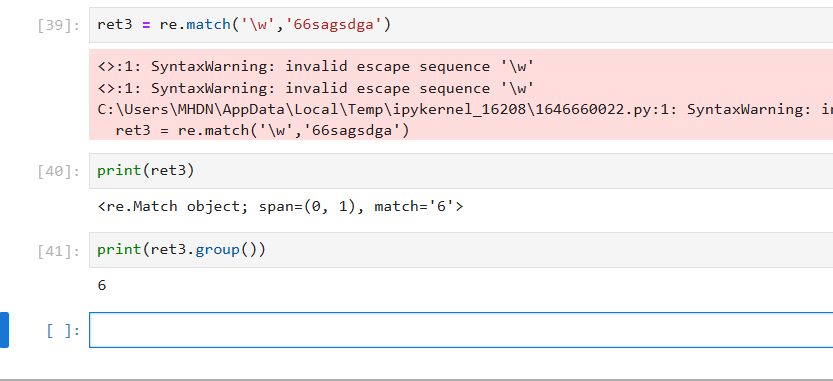
\w 匹配单词字符,即匹配a~z,A~Z,0~9,_
\W 匹配非单词字符
(1). 匹配任意一个字符(处理\n)
(2) 匹配 中列举的字符
(3)\d 匹配数字,数字范围0~9
(4)\w 匹配单词字符,即匹配a~z,A~Z,0~9,_
三、匹配多个字符
* 匹配前一个字符出现0次或者无数次,即可有可无
- 匹配前一个字符出现1次或者无数次,即至少有1次
? 匹配前一个字符出现1次或者0次,即要么有1次要么没有
{m} 匹配前一个字符出现m次
{m,n} 匹配前一个字符出现从m次到n次
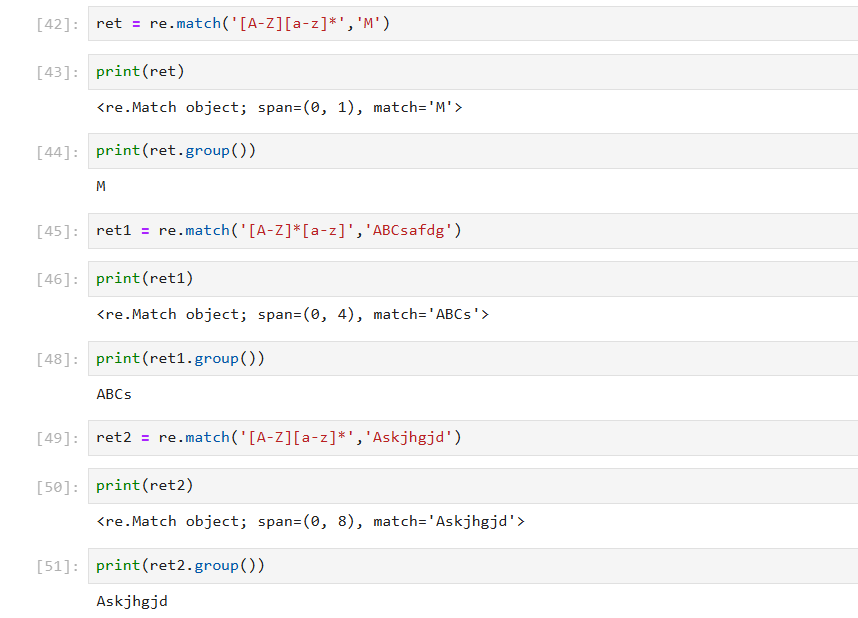
(1)* 匹配出,一个字符串第一个字母为大小字符,后面都是小写字母并且这些小写字母可有可无。
re.match():从字符串开头开始匹配,会尽可能多地匹配符合规则的字符(贪心匹配),直到无法匹配为止。
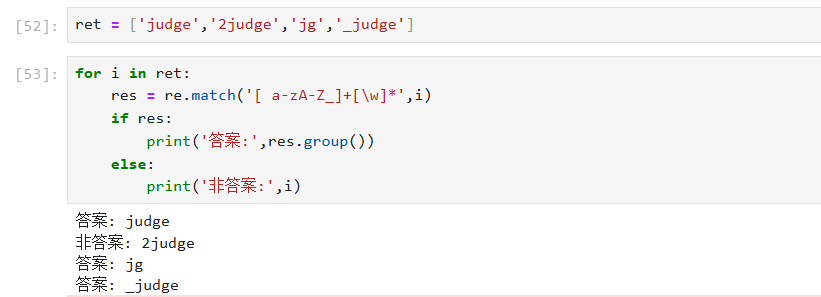
(2)+:匹配出,变量名是否有效
(从字符串开头 开始,先匹配至少 1 个 "空格 / 字母 / 下划线",紧接着匹配任意个 "字母 / 数字 / 下划线",直到遇到不符合的字符为止(re.match 是贪心匹配))
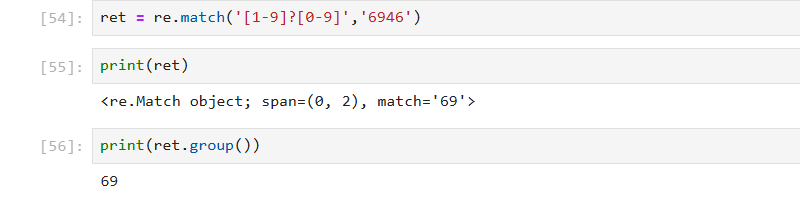
(3)? 匹配数字 匹配前一个字符出现1次或者0次,即要么有1次,要么没有
从字符串开头开始,匹配 "可选的 1-9 数字" + "必选的 0-9 数字",总共匹配 1 位或 2 位数字 ([1-9]? 是 0/1 次,[0-9] 是 1 次,合计 1 或 2 位)。
接下来再举几个例子:
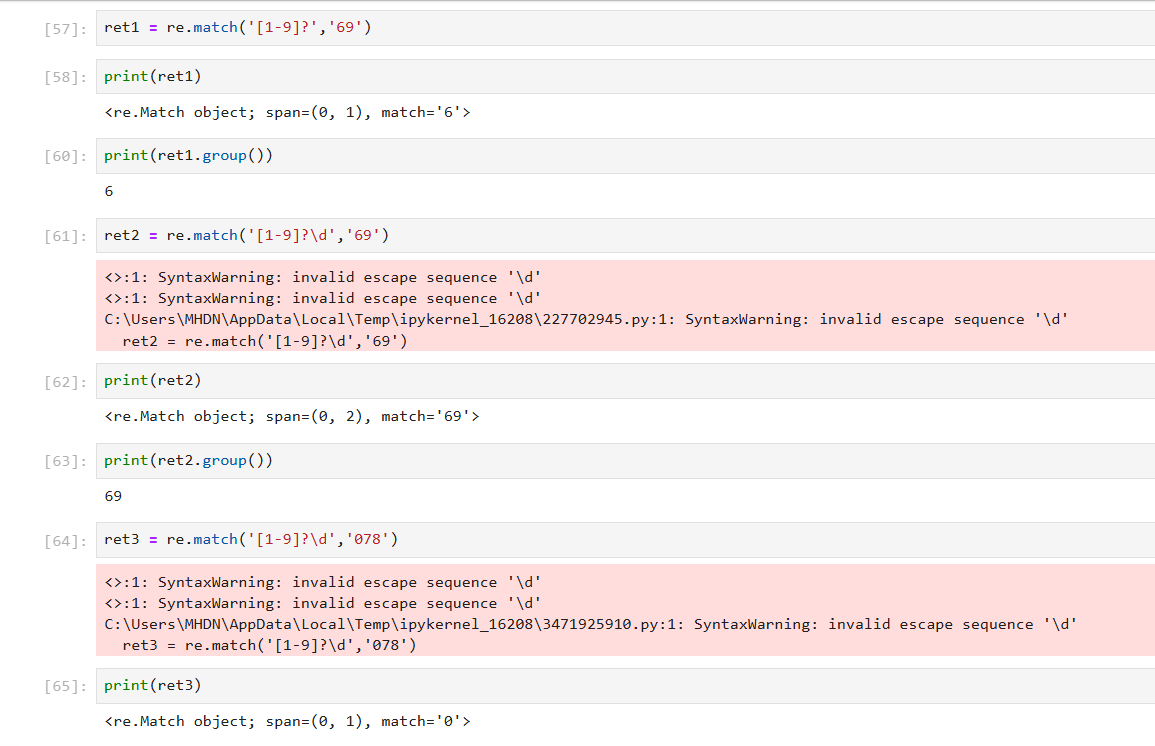
ok,默写完毕,我只记得这些,继续做题去了。