配合github里面的
自注意力
python
import torch
import math
def attention(query,key,value,dropout=None):
query:查询
key:健值
value:真值矩阵
d_k = query.size(-1)
#obtain matrix dimensions
#calculate the score
scores = torch.matmul(query,key.transpose(-2,-1))/math.sqrt(d_k)
#calculate attention scores
### transpose(-2,-1) for transposition #用于转置
pat_h = scores.softmax(dim=-1)
if dropout is not None:
pat_h = dropout(pat_h)
return torch.matmul(pat_h,value),pat_h
###最后这个操作是进行加权求和,权重越大的 value,对最终输出的贡献越大
#为什么矩阵相乘就成了加权求和???
#后面举例
import torch
# 简化的2维例子
p_attn_2d = torch.tensor([[0.1, 0.7, 0.2], [0.8, 0.1, 0.1]]) # [2,3]
value_2d = torch.tensor([[1,2,3,4], [5,6,7,8], [9,10,11,12]]) # [3,4]
output_2d = torch.matmul(p_attn_2d, value_2d)
print(output_2d)
#后面为输出结果
#tensor([[0.1×1+0.7×5+0.2×9, 0.1×2+0.7×6+0.2×10, 0.1×3+0.7×7+0.2×11, 0.1×4+0.7×8+0.2×12],
[0.8×1+0.1×5+0.1×9, 0.8×2+0.1×6+0.1×10, 0.8×3+0.1×7+0.1×11, 0.8×4+0.1×8+0.1×12]])
# 计算后具体值:
#tensor([[5.0000, 6.0000, 7.0000, 8.0000],
[2.2000, 3.2000, 4.2000, 5.2000]])
这就是加权求和:每个 query 位置的输出,是所有 key 对应的 value 向量,按注意力权重(p_attn)的比例 "加权相加" 的结果 ------ 权重越大的 value,对最终输出的贡献越大(比如第一个 query 的 0.7 权重对应第二个 value,所以输出几乎贴近第二个 value 的 [5,6,7,8])例如:
在 Transformer 的 Decoder 结构中,Q 来自于 Decoder 的输入 ,K 与 V 来自于 Encoder 的输出,从而拟合了编码信息与历史信息之间的关系,便于综合这两种信息实现未来的预测。
Q:(来自 Decoder 输入):代表 "目标序列的历史生成信息"
Q 的物理意义:"当前需要生成下一个词时,我(Decoder)的'查询依据'是已生成的历史词"------ 比如要生成 "coding",Q 是 "I love" 的语义表示,代表 "我现在要找和'I love'匹配的源语言信息"。
K/V(来自 Encoder 输出):代表 "源序列的完整编码信息"
K 的物理意义:"源序列中每个词的'索引键'"------ 比如 "我""爱""编程" 各自的语义索引,供 Decoder 的 Q 来匹配
V 的物理意义:"源序列中每个词的'价值信息'"------ 比如 "我" 对应 "I"、"爱" 对应 "love"、"编程" 对应 "coding" 的核心语义。
- Encoder-Decoder Attention 层中,Q 来自 Decoder(目标序列历史信息),K/V 来自 Encoder(源序列编码信息),计算逻辑仍是缩放点积注意力;
- 这种设计的核心是动态融合两种信息:用历史生成的目标序列查询源序列的语义,保证生成的词既符合目标语法,又匹配源语义;
注:图并不匹配
掩码自注意力
注意力掩码的核心动机是让模型只能使用历史信息进行预测而不能看到未来信息。
一起并行 地输入到模型中,模型只需要每一个样本根据未被遮蔽的 token 来预测下一个 token 即可,从而实现了并行的语言模型
模型输入为
python
<BOS> 【MASK】【MASK】【MASK】【MASK】
<BOS> I 【MASK】 【MASK】【MASK】
<BOS> I like 【MASK】【MASK】
<BOS> I like you 【MASK】
<BOS> I like you </EOS>可以发现其实则是一个和文本序列等长的上三角矩阵
python
mask = torch.full((1,args.max_seq_len,args.max_seq_len),float("-inf"))
#把所有元素转化为负无穷的元素
'''full函数创建张量的函数,torch.full(shape,full_value)
创建指定shape形状的矩阵,并且将所有元素填充为full_value
fill_value=float("-inf"),填充为负无穷
'''
mask = torch.triu(mask,diagonal=1)
#生成上三角掩码
'''
torch.triu(input,diagonal=0)
input是输入的矩阵,
diagonal=0,就是保留主对角线及以上的元素,就是i=j也要保留
diagonal=1,保留主对角线上方及以上元素
'''多头注意力机制
多头注意力机制其实就是将原始的输入序列进行多组的自注意力处理;然后再将每一组得到的自注意力结果拼接起来,再通过一个线性层进行处理,得到最终的输出
代码原理:
n 个头就有 n 组3个参数矩阵,每一组进行同样的注意力计算 ,但由于是不同的参数矩阵从而通过反向传播实现了不同的注意力结果,然后将 n 个结果拼接起来输出即可。
功能实现:
支持两种模式:
- 无因果掩码(
is_causal=False):用于 Transformer Encoder 的自注意力(可关注所有位置); - 有因果掩码(
is_causal=True):用于 Transformer Decoder 的 Masked Self-Attention(仅关注当前 / 历史位置,遮蔽未来位置)。
将输入映射为 Q/K/V → 拆分为多个注意力头并行计算注意力 → 合并所有头的结果 → 投影回原模型维度,同时加入 Dropout 正则化保证鲁棒性。
第一模块:初始化(init)
"配置参数+定义可训练层+预生成因果掩码"
python
def __init__(self,args: ModelArgs,is_causal=False):
super().__init__()
'''
继承 PyTorch 的nn.Module
super().__init__()就是调用父类的构造函数(__init__方法)
nn.Module的构造函数里封装了大量 PyTorch 神经网络模块的核心功能,比如:
注册模型的可训练参数(nn.Linear、nn.Conv2d等层的权重);
管理模块的设备(CPU/GPU)映射(比如model.to(device)的底层支持);
初始化钩子函数(Hook)、训练 / 评估模式切换(model.train()/model.eval());
管理子模块(比如你的self.wq、self.wk等层会被自动注册为子模块);
支持模型参数的保存 / 加载(torch.save(model.state_dict()))
'''
assert args.dim % args.n_heads == 0
#这句话就是去判断模型维度必须是头数的整数倍(否则无法均分拆分为多个头)
self.head_dim = args.dim //args.n_heads
self.n_heads = args.n_heads
self.wq = nn.Linear(args.n_embd, self.n_heads * self.head_dim, bias=False)
self.wk = nn.Linear(args.n_embd, self.n_heads * self.head_dim, bias=False)
self.wv = nn.Linear(args.n_embd, self.n_heads * self.head_dim, bias=False)
#这是投影层,将合并后的多头结果映射回原模型维度(dim)
self.wo = nn.Linear(self.n_heads * self.head_dim, args.dim, bias=False)
# Dropout层:分别作用于注意力权重和最终输出(残差连接前)
self.attn_dropout = nn.Dropout(args.dropout) # 注意力权重的Dropout
self.resid_dropout = nn.Dropout(args.dropout) # 最终输出的Dropout
self.is_causal = is_causal # 标记是否需要因果掩码
#生成因果掩码
if is_causal:
mask = torch.full((1,1,args.max_seq_len,args.max_seq_len),float("-inf"))
mask = torch.triu(mask,diagonal=1)
self.register_buffer("mask",mask)
'''
self.register_buffer():PyTorch 中 nn.Module 提供的核心方法,专门用于注册「非可训练但需要和模型绑定」的张量
第一个参数 "mask":给缓冲区命名,后续可通过 self.mask 直接访问这个掩码张量
'''第二模块:前向传播
python
def forward(self , q:torch.Tensor , k:torch.Tensor , v:torch.Tensor):
#步骤一:获取基础维度
bsz, seqlen, _ = q.shape
#步骤 2:映射为 Q/K/V
xq, xk, xv = self.wq(q), self.wk(k), self.wv(v)
#步骤 3:拆分多头(核心维度变换)
# 第一步:拆分为「批次×序列长度×头数×每个头维度」
xq = xq.view(bsz, seqlen, self.n_heads, self.head_dim) # [32,10,8,64]
xk = xk.view(bsz, seqlen, self.n_heads, self.head_dim) # [32,10,8,64]
xv = xv.view(bsz, seqlen, self.n_heads, self.head_dim) # [32,10,8,64]
# 第二步:交换「序列长度」和「头数」维度(让每个头独立计算注意力)
xq = xq.transpose(1, 2) # [32,8,10,64]
xk = xk.transpose(1, 2) # [32,8,10,64]
xv = xv.transpose(1, 2) # [32,8,10,64]
#步骤 4:计算注意力分数(缩放点积)
# Q @ K^T:[32,8,10,64] × [32,8,64,10] → [32,8,10,10]
scores = torch.matmul(xq, xk.transpose(2, 3)) / math.sqrt(self.head_dim)
# 应用因果掩码(仅当is_causal=True时)
if self.is_causal:
assert hasattr(self, 'mask')
# 截取掩码到当前序列长度(避免序列比max_seq_len短时维度不匹配)
scores = scores + self.mask[:, :, :seqlen, :seqlen]
#步骤5:注意力权重归一化 + Dropout
scores = F.softmax(scores.float(), dim=-1).type_as(xq)
scores = self.attn_dropout(scores)
#步骤6:加权求和(注意力核心输出)
output = torch.matmul(scores, xv)
#步骤7:合并多头(核心维度变换)
output = output.transpose(1, 2)
output = output.contiguous()
output = output.view(bsz, seqlen, -1)
#步骤8:最终投影 + Dropout
output = self.wo(output)
output = self.resid_dropout(output)
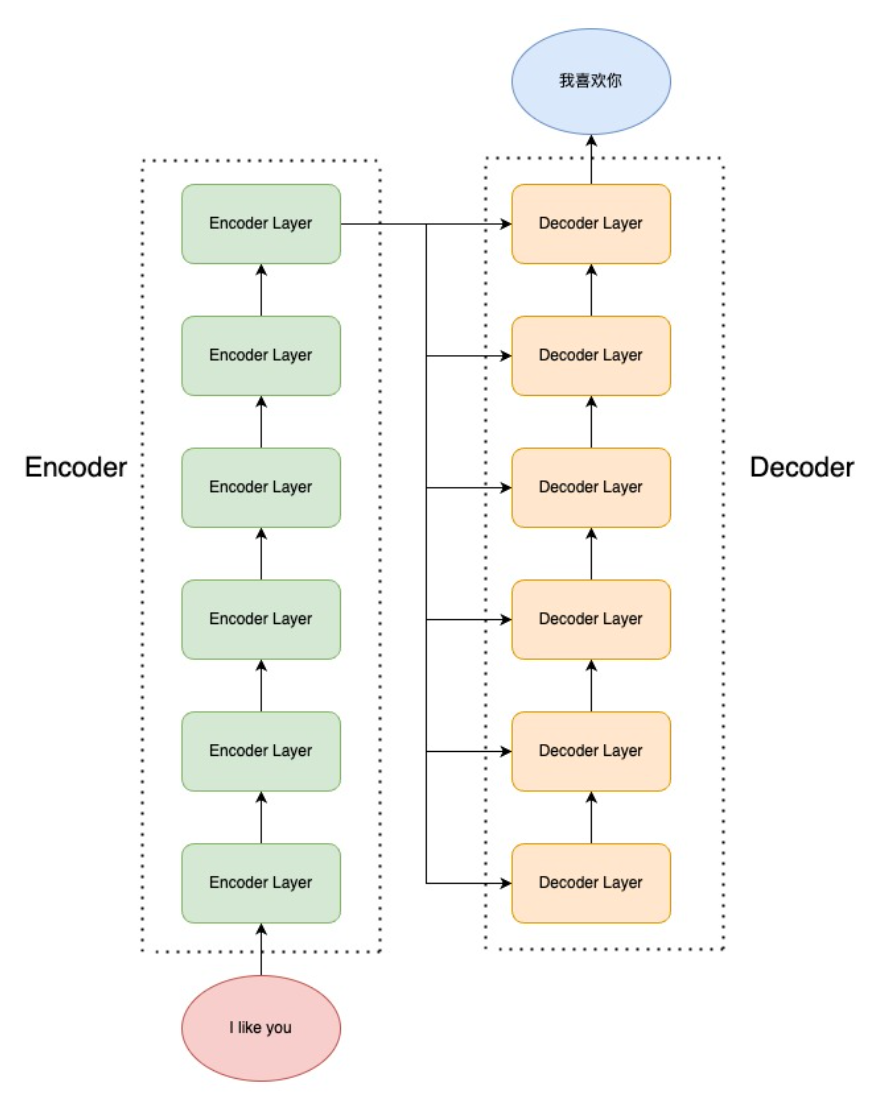
return outputEncoder-Decoder
Seq2Seq
Transformer 是一个经典的 Seq2Seq 模型,即模型的输入为文本序列,输出为另一个文本序列。
Encoder 由 N 个 Encoder Layer 组成,每一个 Encoder Layer 包括一个注意力层和一个前馈神经网络。
整体流程
- 初始化阶段:构建词嵌入、位置编码、Encoder、Decoder、Dropout、输出层等核心组件,统一初始化权重,统计参数数量;
- 前向传播阶段:
- 输入处理:将输入序列(token 索引)转为词嵌入 + 位置编码;
- 特征编码:通过 Encoder 编码源序列,再通过 Decoder 融合 Encoder 输出和目标序列信息;
- 输出层:将 Decoder 输出映射到词表维度,得到 logits;
- 分支逻辑:训练时计算交叉熵损失,推理时仅输出最后一个 token 的 logits(自回归生成);
- 辅助能力:统计模型参数数量、自定义权重初始化策略,保证模型训练的稳定性。
初始化详解
python
class Transformer(nn.Module):
def__init__(self,args):
assert args.vocab_size is not None
assert args.block_size is not None
self.args = args
'''
nn.ModuleDict 是 PyTorch 专为管理 nn.Module 子类设计的有序字典
'''
self.transformer = nn.ModuleDict(dict(
# 1. 词嵌入层(Word Token Embedding):将token索引转为稠密向量
wte = nn.Embedding(args.vocab_size, args.n_embd),
# 2. 位置编码层(Positional Encoding):注入序列位置信息(自定义PositionalEncoding类)
wpe = PositionalEncoding(args),
# 3. Dropout层:对嵌入+位置编码的结果做正则化,防止过拟合
drop = nn.Dropout(args.dropout),
# 4. Encoder模块(自定义的Encoder类,由多个EncoderLayer堆叠而成)
encoder = Encoder(args),
# 5. Decoder模块(自定义的Decoder类,由多个DecoderLayer堆叠而成)
decoder = Decoder(args),
))
# 6. 输出层(Language Model Head):将模型维度映射到词表维度,用于预测下一个token
self.lm_head = nn.Linear(args.n_embd, args.vocab_size, bias=False)
# 7. 初始化所有子模块的权重(调用自定义的_init_weights方法)
self.apply(self._init_weights)
# 8. 打印模型参数数量(方便监控模型规模,比如"12.34M"表示1234万参数)
print("number of parameters: %.2fM" % (self.get_num_params()/1e6,))统计模型参数数量
python
def get_num_params(self, non_embedding=False):
# non_embedding: 是否统计 embedding 的参数
n_params = sum(p.numel() for p in self.parameters()) # 统计所有可训练参数的总数
# 如果不统计 embedding 的参数,就减去词嵌入层的参数数量
if non_embedding:
n_params -= self.transformer.wte.weight.numel()
return n_params自定义权重初始化
python
def _init_weights(self, module):
# 线性层和 Embedding 层初始化为正态分布
if isinstance(module, nn.Linear):
torch.nn.init.normal_(module.weight, mean=0.0, std=0.02) # 均值0,标准差0.02
if module.bias is not None: # 仅当有偏置时初始化(lm_head无偏置,不会执行)
torch.nn.init.zeros_(module.bias) # 偏置初始化为0
elif isinstance(module, nn.Embedding):
torch.nn.init.normal_(module.weight, mean=0.0, std=0.02) # 嵌入层权重同线性层前向传播
python
def forward(self, idx, targets=None):
# 输入为 idx,维度为 (batch size, sequence length);targets 为目标序列,用于计算 loss
device = idx.device # 获取输入所在设备(CPU/GPU)
b, t = idx.size() # b=32(批次),t=10(序列长度)
# 断言:输入序列长度不能超过模型最大序列长度(防止位置编码/掩码越界)
assert t <= self.args.block_size, f"不能计算该序列,该序列长度为 {t}, 最大序列长度只有 {self.args.block_size}"
# ========== 步骤1:词嵌入 + 位置编码 ==========
# 词嵌入:[32,10] → [32,10,512](将token索引转为512维向量)
tok_emb = self.transformer.wte(idx)
# 位置编码:输入tok_emb,输出同维度的位置编码向量 [32,10,512]
pos_emb = self.transformer.wpe(tok_emb)
# 词嵌入+位置编码(逐元素相加)→ Dropout:[32,10,512]
x = self.transformer.drop(tok_emb + pos_emb) # 注:原代码写的是pos_emb,应为tok_emb+pos_emb,是笔误!
# ========== 步骤2:Encoder编码 ==========
enc_out = self.transformer.encoder(x) # [32,10,512] → [32,10,512](Encoder输出维度不变)
# ========== 步骤3:Decoder解码 ==========
x = self.transformer.decoder(x, enc_out) # 输入:目标序列特征x + Encoder输出enc_out → [32,10,512]
# ========== 步骤4:训练/推理分支 ==========
if targets is not None:
# 训练阶段:计算logits和loss
# logits:[32,10,512] → [32,10,10000](映射到词表维度)
logits = self.lm_head(x)
# 计算交叉熵损失:
# 1. logits.view(-1, 10000):展平为 [320, 10000](32×10=320)
# 2. targets.view(-1):展平为 [320]
# 3. ignore_index=-1:忽略targets中值为-1的位置(比如padding token)
loss = F.cross_entropy(logits.view(-1, logits.size(-1)), targets.view(-1), ignore_index=-1)
else:
# 推理阶段:仅输出最后一个token的logits(自回归生成)
# x[:, [-1], :]:取每个批次的最后一个token → [32,1,512](保留时间维度)
logits = self.lm_head(x[:, [-1], :])
loss = None
return logits, loss