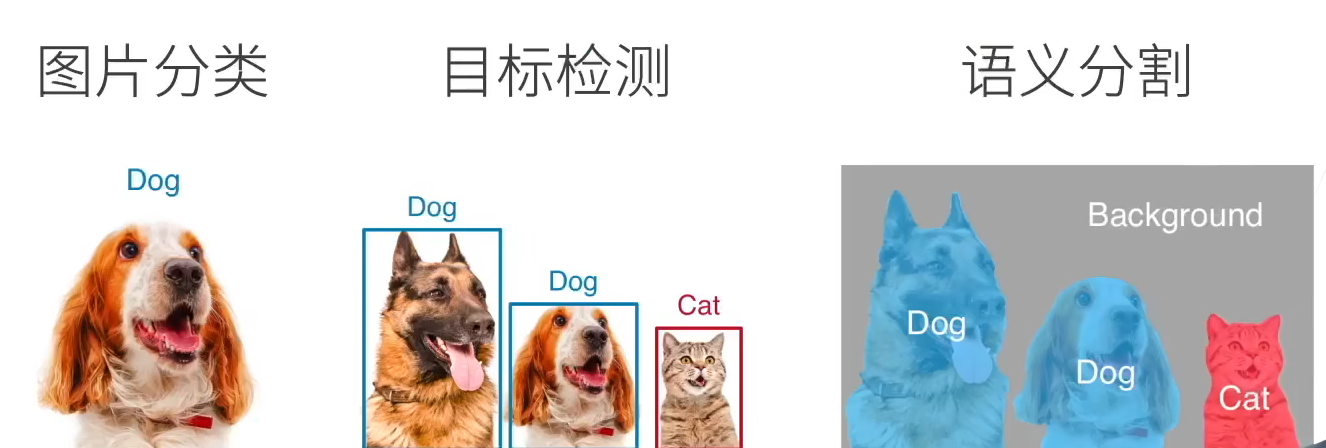
1. 语义分割
- 语义分割将图片中的像素 分类到对应的类别
- 锚框太糙了
- 精细到像素的归属的labels
应用:路面分割
应用:背景虚化

VS实例分割(Instance Segmentation)
- 语义分割只针对类
- 实例分割针对每一个类的实例
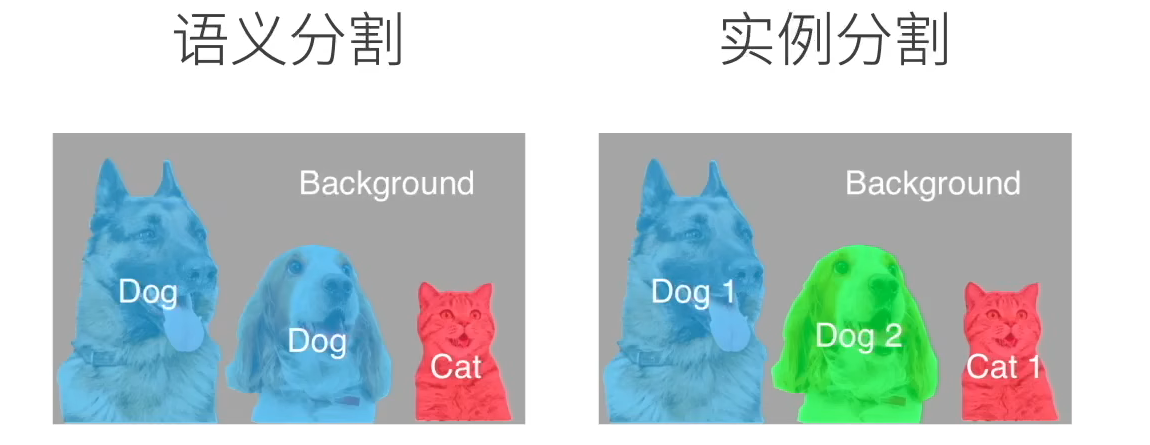
| 对比点 | 语义分割(Semantic) | 实例分割(Instance) |
|---|---|---|
| 分割单位 | 像素 | 像素 |
| 是否区分个体 | ❌ 不区分 | ✅ 区分 |
| 同一类多个目标 | 合成一片 | 分成多个实例 |
| 输出 | 类别 mask | 每个实例一个 mask |
| 问题在回答 | "这是什么" | "这是哪个" |
代码实现
下载/读数据集
python
%matplotlib inline
import os
import torch
import torchvision
from d2l import torch as d2l
d2l.DATA_HUB['voc2012'] = (d2l.DATA_URL + 'VOCtrainval_11-May-2012.tar',
'4e443f8a2eca6b1dac8a6c57641b67dd40621a49')
voc_dir = d2l.download_extract('voc2012','VOCdevkit/VOC2012')
# 定义函数read_voc_images,用于读取VOC图像和标签。voc_dir是数据集的路径,is_train是一个布尔值,指示我们是读取训练集(True)还是验证集(False)
def read_voc_images(voc_dir, is_train=True):
"""读取所有VOC图像并标注"""
# 定义txt_fname,这是我们将读取的文件的路径。如果is_train为True,我们读取的是'train.txt',否则是'val.txt'。这些文件中包含了我们需要读取的图像的文件名
txt_fname = os.path.join(voc_dir, 'ImageSets', 'Segmentation',
'train.txt' if is_train else 'val.txt')
# 设定图像的读取模式为RGB
mode = torchvision.io.image.ImageReadMode.RGB
# 读取txt_fname文件,并将文件中的内容分割成一个个的文件名,然后存储在images列表中
with open(txt_fname,'r') as f:
images = f.read().split()
# 创建两个空列表,分别用于存储特征和标签
features, labels = [],[]
# 对于images中的每个文件名
for i, fname in enumerate(images):
# 使用torchvision.io.read_image读取对应的图像文件,然后添加到features列表中
features.append(torchvision.io.read_image(os.path.join(voc_dir,'JPEGImages',f'{fname}.jpg')))
# 使用torchvision.io.read_image读取对应的标签图像文件,然后添加到labels列表中
labels.append(torchvision.io.read_image(os.path.join(voc_dir,'SegmentationClass',f'{fname}.png'),mode))
# 返回特征和标签列表
return features, labels
# 调用read_voc_images函数,读取训练数据集的图像和标签,然后存储在train_features和train_labels中
train_features, train_labels = read_voc_images(voc_dir, True)
# 绘制前5个输入图像及其标签
# 设置要展示的图像的数量,这里是5
n = 5
# 创建一个新的列表,该列表包含前5个图像特征和对应的标签图像
imgs = train_features[0:n] + train_labels[0:n] # 读的时候channel是在前面
# 将列表中的每个图像的通道维度从第一维(0开始计数)移到最后一维,因为matplotlib等绘图库需要将通道维度放在最后才能正常显示图像
imgs = [img.permute(1,2,0) for img in imgs] # 画的时候把channel放到后面
# 使用d2l库的show_images函数显示图像,这里第一个参数是图像列表,第二个参数是行数(这里是2行,分别对应图像和标签),第三个参数是每行的图像数量(这里是n,即5)
d2l.show_images(imgs,2,n) # 第一行显示的是图片,第二行显示的是标号
建立RGB映射
python
# 列举RGB颜色值和类名
# 每一种RGB颜色对应的标号
# 定义VOC_COLORMAP,这是一个列表,包含了PASCAL VOC数据集中每种类别的RGB颜色值。每种类别在标签图像中由一种特定的颜色表示,颜色的RGB值就是这里定义的。
VOC_COLORMAP = [[0,0,0],[128,0,0],[0,128,0],[128,128,0],
[0,0,128],[128,0,128],[0,128,128],[128,128,128],
[64,0,0],[192,0,0],[64,128,0],[192,128,0],
[64,0,128],[192,0,128],[64,128,128],[192,128,128],
[0,64,0],[128,64,0],[0,192,0],[128,192,0],
[0,64,128]]
# 定义VOC_CLASSES,这是一个列表,包含了PASCAL VOC数据集中每种类别的名字。列表中的类别名顺序与VOC_COLORMAP中的颜色值顺序相对应。
VOC_CLASSES = ['background','aeroplane','bicycle','bird','boat','bottle','bus',
'car','cat','chair','cow','diningtable','dog','horse','motorbike',
'person','potted plant','sheep','sofa','train','tv/monitor']
# 查找标签中每个像素的类索引
# 定义函数voc_colormap2label,这个函数用于建立一个映射,将RGB颜色值映射为对应的类别索引
def voc_colormap2label():
"""构建从RGB到VOC类别索引的映射"""
# 创建一个全零的张量,大小为256的三次方,因为RGB颜色的每个通道有256种可能的值,所以总共有256^3种可能的颜色组合。数据类型设为long
colormap2label = torch.zeros(256**3, dtype=torch.long)
# 对于VOC_COLORMAP中的每个颜色值(colormap)
for i, colormap in enumerate(VOC_COLORMAP):
# 计算颜色值的一维索引,并将这个索引对应的位置设为i。这样,给定一个颜色值,我们就可以通过这个映射找到对应的类别索引
colormap2label[(colormap[0] * 256 + colormap[1]) * 256 + colormap[2]] = i
# 返回映射
return colormap2label
# 定义函数voc_label_indices,这个函数用于将一张标签图像中的每个像素的颜色值映射为对应的类别索引
def voc_label_indices(colormap, colormap2label):
"""将VOC标签中的RGB值映射到它们的类别索引"""
# 将输入的colormap的通道维度移到最后一维,并将其转换为numpy数组,然后转换为int32类型。这是因为我们需要使用numpy的高级索引功能
colormap = colormap.permute(1,2,0).numpy().astype('int32')
# 计算colormap中每个像素的颜色值对应的一维索引。这里的索引计算方式和上一个函数中的是一致的
idx = ((colormap[:,:,0] * 256 + colormap[:,:,1]) * 256 + colormap[:,:,2])
# 使用colormap2label这个映射将索引映射为对应的类别索引,并返回
return colormap2label[idx]
# 例如
# 调用上面定义的两个函数,将训练数据集中的第一个标签图像的RGB颜色值转换为对应的类别索引,并将结果保存在变量y中
y = voc_label_indices(train_labels[0], voc_colormap2label())
# 打印变量y中的一小部分,即第105行到115行,第130列到140列的部分。这里是为了查看转换后的类别索引是否正确
print(y[105:115,130:140])
# 打印VOC_CLASSES列表中的第二个类别名(索引为1)。这里是为了查看第二个类别名是什么
print(VOC_CLASSES[1]) # 标签类别
基于剪裁的图像增广
python
# 使用图像增广中的随即裁剪,裁剪输入图像和标签的相同区域
# 定义函数voc_rand_crop,用于对输入的特征图像和标签图像进行随机裁剪。height和width是裁剪的高度和宽度
def voc_rand_crop(feature, label, height, width):
"""随即裁剪特征和标签图像"""
# 调用RandomCrop的get_params方法,随机生成一个裁剪框。裁剪框的大小是(height, width)
# rect拿到特征的框
rect = torchvision.transforms.RandomCrop.get_params(feature,(height,width))
# 根据生成的裁剪框,对特征图像进行裁剪
# 拿到框中的特征和标号
feature = torchvision.transforms.functional.crop(feature, *rect)
# 根据生成的裁剪框,对标签图像进行裁剪。注意,我们是在同一个裁剪框下裁剪特征图像和标签图像,以保证它们对应的位置仍然是对齐的
label = torchvision.transforms.functional.crop(label,*rect)
# 返回裁剪后的特征图像和标签图像
return feature, label
imgs = []
# 对于每个数字i,在0到n-1的范围内
for _ in range(n):
# 调用上面定义的voc_rand_crop函数,对训练集中的第一个特征图像和标签图像进行随机裁剪,然后将裁剪后的图像添加到imgs列表中
imgs += voc_rand_crop(train_features[0],train_labels[0],200,300)
# 将imgs中的每个图像的通道维度移到最后一维,以方便绘图
imgs = [img.permute(1,2,0) for img in imgs]
# 使用d2l库的show_images函数展示图像。这里首先将imgs列表中的图像分为两部分,一部分是特征图像,一部分是标签图像。然后将这两部分拼接在一起,使得特征图像和标签图像能够按对应的顺序展示
d2l.show_images(imgs[::2] + imgs[1::2],2,n)
定制类,把大部分功能都整合进类里
python
# 自定义语义分割数据集类
# 定义一个自定义的数据集类,用于加载VOC数据集。这个类继承了torch.utils.data.Dataset
class VOCSegDataset(torch.utils.data.Dataset):
"""一个用于加载VOC数据集的自定义数据集"""
# 初始化方法,输入参数:is_train表示是否是训练集,crop_size是裁剪后的图像尺寸,voc_dir是VOC数据集的路径
def __init__(self, is_train, crop_size, voc_dir):
# 定义一个归一化变换,用于对输入图像进行归一化。这里使用了ImageNet数据集的均值和标准差
self.transform = torchvision.transforms.Normalize(mean=[0.485,0.456,0.406],std=[0.229,0.224,0.225])
# 保存裁剪尺寸到self.crop_size
self.crop_size = crop_size
# 调用之前定义的read_voc_images函数,读取VOC数据集的特征图像和标签图像
features, labels = read_voc_images(voc_dir, is_train = is_train)
# 对读取到的特征图像进行筛选和归一化处理,并保存到self.features中
self.features = [self.normalize_image(feature) for feature in self.filter(features)]
# 对读取到的标签图像进行筛选处理,并保存到self.labels中
self.labels = self.filter(labels)
# 创建一个从颜色映射到类别索引的映射表,并保存到self.colormap2label中
self.colormap2label = voc_colormap2label()
# 打印出读取到的图像数量
print('read ' + str(len(self.features)) + ' examples')
# 定义一个方法,用于对输入图像进行归一化处理
def normalize_image(self, img):
# 将输入图像转换为浮点数类型,并调用归一化变换对其进行处理,最后返回处理后的图像
return self.transform(img.float())
# 定义一个方法,用于筛选符合要求的图像。筛选条件是图像的高度和宽度都大于等于裁剪尺寸
def filter(self, imgs):
# 返回筛选后的图像列表
return [img
for img in imgs
if (img.shape[1] >= self.crop_size[0] and img.shape[2] >= self.crop_size[1] ) ]
# 每一次返回的样本做一次rand_crop
# 定义一个方法,用于根据索引获取一个样本。这是一个实现Dataset接口所必须的方法
def __getitem__(self, idx):
# 调用之前定义的voc_rand_crop函数,对指定索引的特征图像和标签图像进行随机裁剪
feature, label = voc_rand_crop(self.features[idx],self.labels[idx],*self.crop_size)
# 调用voc_label_indices函数,将裁剪后的标签图像转换为类别索引,并返回裁剪和转换后的特征图像和标签图像
return (feature, voc_label_indices(label,self.colormap2label))
# 定义一个方法,用于获取数据集的长度。这是一个实现Dataset接口所必须的方法
def __len__(self):
# 返回特征图像列表的长度,即数据集的长度
return len(self.features)
# 读取数据集
# 定义裁剪尺寸,即将图像裁剪成320x480像素大小
crop_size = (320, 480)
# 创建训练数据集实例,输入参数分别为:True表示这是一个训练数据集,crop_size是裁剪尺寸,voc_dir是VOC数据集的路径
voc_train = VOCSegDataset(True, crop_size, voc_dir)
# 创建测试数据集实例,输入参数分别为:False表示这不是一个训练数据集,crop_size是裁剪尺寸,voc_dir是VOC数据集的路径
voc_test = VOCSegDataset(False, crop_size, voc_dir)
创建数据集和整合
python
# 定义批次大小,即每个批次包含的样本数量
batch_size = 64
# 创建一个数据加载器实例,输入参数分别为:voc_train是待加载的数据集,batch_size是批次大小,shuffle=True表示在每个迭代周期中随机打乱数据,drop_last=True表示如果最后一个批次的样本数量小于batch_size,则丢弃该批次,num_workers=0表示数据加载不使用额外的进程或线程
train_iter = torch.utils.data.DataLoader(voc_train,batch_size,shuffle=True,drop_last=True,
num_workers=0)
# 对数据加载器进行迭代,每次迭代都返回一个批次的数据,其中X是特征,Y是标签
for X,Y in train_iter:
# 打印特征的形状,它应该是一个四维张量,其形状为(batch_size, channels, height, width)
print(X.shape)
# 打印标签的形状,它应该是一个三维张量,其形状为(batch_size, height, width),其中每个元素是一个像素的类别索引
print(Y.shape) # Y也为每一个像素对应的值
# 只迭代一次,所以立即跳出循环
break
python
# 整合所有组件
# 定义一个函数来加载VOC语义分割数据集,输入参数是批次大小和裁剪尺寸
def load_data_voc(batch_size, crop_size):
"""加载VOC语义分割数据集"""
# 下载并提取VOC2012数据集,获取数据集的路径
voc_dir = d2l.download_extract('voc2012',os.path.join('VOCdevkit','VOC2012'))
# 获取数据加载器的工作进程数量
num_workers = d2l.get_dataloader_workers()
# 创建一个训练数据加载器实例,输入参数分别为:VOCSegDataset是待加载的数据集,batch_size是批次大小,shuffle=True表示在每个迭代周期中随机打乱数据,drop_last=True表示如果最后一个批次的样本数量小于batch_size,则丢弃该批次,num_workers是数据加载器的工作进程数量
train_iter = torch.utils.data.DataLoader(VOCSegDataset(True, crop_size, voc_dir), batch_size,shuffle=True,
drop_last = True, num_workers=num_workers)
# 创建一个测试数据加载器实例,输入参数分别为:VOCSegDataset是待加载的数据集,batch_size是批次大小,drop_last=True表示如果最后一个批次的样本数量小于batch_size,则丢弃该批次,num_workers是数据加载器的工作进程数量
test_iter = torch.utils.data.DataLoader(VOCSegDataset(False, crop_size, voce_dir), batch_size, drop_last=True,
num_workers=num_workers)
# 返回训练数据加载器和测试数据加载器
return train_iter, test_iter心得体会
写了这么多代码,发现面向对象的方式可以很方便地实现集成功能,把所需要的函数、属性定义在类里,通过创造实例来简化程序。并且在定义类时,可以把与程序输入输出无关的中间变量都内置化,实现输入------输出的简单逻辑关系,方便程序的运行。
2. 转置卷积
转置卷积(Transposed Convolution)
- 卷积不会增大输入的高宽,通常要么不变、要么减半
- 语义分割需要在像素级别评估
- 转置卷积则可以用来增大输入高宽
Yi:i+h,j:j+w+=Xi,j⋅KYi:i+h,j:j+w+=Xi,j\cdot KYi:i+h,j:j+w+=Xi,j⋅K
为什么称之为"转置"
- 对于卷积 Y=X⋆WY=X\star WY=X⋆W
- 可以对 WWW 构造一个 VVV ,使得卷积等价于矩阵乘法 Y′=VX′Y\prime=VX\primeY′=VX′
- 这里 Y′, X′Y\prime,\ X\primeY′, X′ 是 Y, XY,\ XY, X 对应的向量版本
- m=(m,n)×nm = (m, n) \times nm=(m,n)×n
- 早期就是这么做的
- 转置卷积则等价于 Y′=VTX′Y\prime=V^TX\primeY′=VTX′
- 如果卷积将输入从 (h,w)(h, w)(h,w) 变成了 (h′,w′)(h\prime, w\prime)(h′,w′)
- 同样超参数的转置卷积则从 (h′,w′)(h\prime, w\prime)(h′,w′) 变回 (h,w)(h, w)(h,w),逆变换关系
- n=(n,m)×mn = (n, m) \times mn=(n,m)×m
- 交换了维度,原本的卷积维度减小变成了转置维度增加
代码实现
对于一个张量 XXX,转置卷积的输出
hY=hk+(hX−1)×stride−2×paddingwY=wk+(wX−1)×stride−2×paddingh_Y=h_k+(h_X-1)\times stride - 2\times padding\\ w_Y=w_k+(w_X-1)\times stride - 2\times paddinghY=hk+(hX−1)×stride−2×paddingwY=wk+(wX−1)×stride−2×padding
python
import torch
from torch import nn
from d2l import torch as d2l
# 实现基本的转置卷积运算
# 定义转置卷积运算
def trans_conv(X, K):
# 获取卷积核的宽度和高度
h, w = K.shape # 卷积核的宽、高
# 创建一个新的张量Y,其尺寸为输入X的尺寸加上卷积核K的尺寸减去1。在常规卷积中,输出尺寸通常是输入尺寸减去卷积核尺寸加1
Y = torch.zeros((X.shape[0] + h -1, X.shape[1] + w - 1)) # 正常的卷积后尺寸为(X.shape[0] - h + 1, X.shape[1] - w + 1)
# 遍历输入张量X的每一行
for i in range(X.shape[0]):
# 遍历输入张量X的每一列
for j in range(X.shape[1]):
# 对于输入X的每一个元素,我们将其与卷积核K进行元素级别的乘法,然后将结果加到输出张量Y的相应位置上
Y[i:i + h, j:j + w] += X[i, j] * K # 按元素乘法,加回到自己矩阵
# 返回转置卷积的结果
return Y
# 验证上述实现输出
# 定义输入张量X,这是一个2x2的矩阵
X = torch.tensor([[0.0,1.0],[2.0,3.0]])
# 定义卷积核K,也是一个2x2的矩阵
K = torch.tensor([[0.0,1.0],[2.0,3.0]])
# 调用上面定义的trans_conv函数,对输入张量X和卷积核K进行转置卷积操作,并打印结果
trans_conv(X,K) 
填充和步幅
python
# 使用高级API获得相同的结果
# 将输入张量X和卷积核K进行形状变换,原来是2x2的二维张量,现在变成了1x1x2x2的四维张量
# 第一个1表示批量大小,第二个1表示通道数,2x2是卷积核的高和宽
X, K = X.reshape(1,1,2,2), K.reshape(1,1,2,2)
# 创建一个转置卷积层对象tconv,其中输入通道数为1,输出通道数为1,卷积核的大小为2,没有偏置项
tconv = nn.ConvTranspose2d(1,1,kernel_size=2,bias=False) # 输入通道数为1,输出通道数为1
# 将创建的转置卷积层对象tconv的权重设置为我们的卷积核K
tconv.weight.data = K
# 使用创建的转置卷积层tconv对输入张量X进行转置卷积操作,并返回结果
tconv(X)
python
# 填充、步幅和多通道
# 填充在输出上,padding=1,之前输出3x3,现在上下左右都填充了1,那就剩下中心那个元素了
# 填充为1,就是把输出最外面的一圈当作填充
# 创建一个转置卷积层对象tconv,其中输入通道数为1,输出通道数为1,卷积核的大小为2,没有偏置项,同时设置填充大小为1
# 填充(padding)操作在输出上执行,原本输出为3x3,由于填充了大小为1的边框,结果就只剩下中心的元素
# 所以填充大小为1就相当于将输出矩阵最外面的一圈当作填充并剔除
tconv = nn.ConvTranspose2d(1,1,kernel_size=2,padding=1,bias=False)
# 将创建的转置卷积层对象tconv的权重设置为我们的卷积核K
tconv.weight.data = K
# 使用创建的转置卷积层tconv对输入张量X进行转置卷积操作,并返回结果
tconv(X)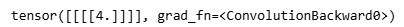
python
# 创建一个转置卷积层对象tconv,其中输入通道数为1,输出通道数为1,卷积核的大小为2,步幅(stride)为2,没有偏置项
# 步幅为2表示在进行卷积时,每次移动2个单位,相较于步幅为1,这样会使得输出尺寸增大
tconv = nn.ConvTranspose2d(1,1,kernel_size=2,stride=2,bias=False)
# 将创建的转置卷积层对象tconv的权重设置为我们的卷积核K
tconv.weight.data = K
# 使用创建的转置卷积层tconv对输入张量X进行转置卷积操作,并返回结果
tconv(X)
python
# 多通道
# 创建一个四维张量X,批量大小为1,通道数为10,高和宽都为16
X = torch.rand(size=(1,10,16,16))
# 创建一个二维卷积层对象conv,其中输入通道数为10,输出通道数为20,卷积核大小为5,填充为2,步幅为3
# 这会将输入的10个通道的图像转换为20个通道的特征图
conv = nn.Conv2d(10,20,kernel_size=5,padding=2,stride=3)
# 创建一个转置卷积层对象tconv,其中输入通道数为20,输出通道数为10,卷积核大小为5,填充为2,步幅为3
# 这会将输入的20个通道的特征图转换回10个通道的图像
tconv = nn.ConvTranspose2d(20,10,kernel_size=5,padding=2,stride=3)
# 首先对输入张量X进行卷积操作,然后再对卷积的结果进行转置卷积操作
# 然后检查这个结果的形状是否和原始输入张量X的形状相同
# 如果相同,说明转置卷积操作成功地还原了原始输入的形状
tconv(conv(X)).shape == X.shape #True
python
# 与矩阵变换的联系
# 创建一个一维张量,其中包含从0.0到8.0的连续数字
# 然后将这个一维张量重塑为3x3的二维张量
X = torch.arange(9.0).reshape(3,3)
# 创建一个2x2的卷积核K,其中包含四个元素:1.0,2.0,3.0,4.0
K = torch.tensor([[1.0,2.0],[3.0,4.0]])
# 使用自定义的二维卷积函数corr2d对输入张量X和卷积核K进行卷积操作
# corr2d函数需要在引入d2l(深度学习库)之后才能使用
Y = d2l.corr2d(X,K) # 卷积
# 打印卷积操作的结果
Y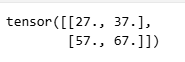
python
# 定义一个函数kernel2matrix,用于将给定的卷积核K转换为一个稀疏矩阵W
def kernel2matrix(K):
# 创建长度为5的零向量k和4x9的零矩阵W
k, W = torch.zeros(5), torch.zeros((4,9))
# 打印初始状态的k
print(k)
# 打印初始状态的W
print(W)
# 打印输入的卷积核K
print(K)
# 将卷积核K的元素填充到向量k中的适当位置,形成一个稀疏向量
k[:2], k[3:5] = K[0, :], K[1,:]
# 打印填充后的向量k
print(k)
# 将稀疏向量k填充到矩阵W中的适当位置,形成一个稀疏矩阵
W[0,:5], W[1,1:6], W[2,3:8], W[3,4:] = k, k, k, k
# 返回转换后的稀疏矩阵W
return W
# 每一行向量表示在一个位置的卷积操作,0填充表示卷积核未覆盖到的区域。
# 输入大小为 3 * 3 的图片,拉长一维向量后变成 1 * 9 的向量
# 输入大小为 3 * 3 的图片,卷积核为 2 * 2,则输出图片为 2 * 2,拉长后变为 4 * 1 的向量
# kernel2matrix函数将卷积核改为稀疏矩阵C后矩阵情况
# 使用kernel2matrix函数将卷积核K转换为一个稀疏矩阵W
# 这个矩阵的每一行表示在一个特定位置进行的卷积操作,其中的0表示卷积核没有覆盖的区域
# 如果输入是一个3x3的图像,并被拉平为一个1x9的向量
# 而卷积核是2x2的,那么输出图像的大小为2x2,拉平后变为一个4x1的向量
# kernel2matrix函数实际上就是在构建这种转换关系
W = kernel2matrix(K)
W
python
# 打印输入张量X的内容
print(X)
# 使用reshape函数将输入张量X拉平为一个一维向量,并打印结果
# 这是为了将X与稀疏矩阵W进行矩阵乘法操作
print(X.reshape(-1))
# 判断卷积操作的结果Y是否等于稀疏矩阵W与拉平的输入张量X的矩阵乘法的结果,并将结果重塑为2x2的形状
# 这是一种检查卷积操作是否等价于某种矩阵变换的方式
Y == torch.matmul(W, X.reshape(-1)).reshape(2,2)
python
# 使用自定义的转置卷积函数trans_conv对卷积操作的结果Y和卷积核K进行转置卷积操作
Z = trans_conv(Y, K)
# 判断转置卷积操作的结果Z是否等于稀疏矩阵W的转置与拉平的卷积结果Y的矩阵乘法的结果,并将结果重塑为3x3的形状
# 这是一种检查转置卷积操作是否等价于某种特定的矩阵变换的方式
# 注意这里得到的结果并不是原图像,尽管它们的尺寸是一样的
Z == torch.matmul(W.T, Y.reshape(-1)).reshape(3,3) # 由卷积后的图像乘以转置卷积后,得到的并不是原图像,而是尺寸一样 